https://github.com/arfon/dapper
Data Assimilation with Python: a Package for Experimental Research
Science Score: 23.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
○codemeta.json file
-
○.zenodo.json file
-
✓DOI references
Found 13 DOI reference(s) in README -
✓Academic publication links
Links to: zenodo.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (17.4%) to scientific vocabulary
Last synced: 10 months ago
·
JSON representation
Repository
Data Assimilation with Python: a Package for Experimental Research
Basic Info
- Host: GitHub
- Owner: arfon
- License: mit
- Default Branch: master
- Homepage: https://nansencenter.github.io/DAPPER
- Size: 6.34 MB
Statistics
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
- Releases: 0
Fork of nansencenter/DAPPER
Created over 2 years ago
· Last pushed over 2 years ago
https://github.com/arfon/DAPPER/blob/master/
DAPPER is a set of templates for **benchmarking** the performance of **data assimilation** (DA) methods. The numerical experiments provide support and guidance for new developments in DA. The typical set-up is a **synthetic (twin) experiment**, where you specify a dynamic model and an observational model, and use these to generate a synthetic truth (multivariate time series), and then estimate that truth given the models and noisy observations. [](https://github.com/nansencenter/DAPPER/actions) [](https://coveralls.io/github/nansencenter/DAPPER?branch=master) [](https://github.com/pre-commit/pre-commit) [](https://pypi.python.org/pypi/dapper/) [](https://pypi.org/project/dapper) ## Getting started [Install](#installation), then read, run and try to understand `examples/basic_{1,2,3}.py`. Some of the examples can also be opened in Jupyter, and thereby run in the cloud (i.e. *without installation*, but requiring Google login): [](http://colab.research.google.com/github/nansencenter/DAPPER). This [screencast](https://www.youtube.com/watch?v=YtalK0Zkzvg&t=6475s) provides an introduction. The [documentation](https://nansencenter.github.io/DAPPER) includes general guidelines and the API, but for any serious use you will want to read and adapt the code yourself. If you use it in a publication, please cite, e.g., *The experiments used (inspiration from) DAPPER [ref], version 1.6.0*, where [ref] points to [](https://doi.org/10.5281/zenodo.10710355). Lastly, for an introduction to DA theory also using Python, see these [tutorials](https://github.com/nansencenter/DA-tutorials). ## Highlights DAPPER enables the numerical investigation of [DA methods](#da-methods) through a variety of typical [test cases](#test-cases-models) and statistics. It (a) reproduces numerical benchmarks results reported in the literature, and (b) facilitates comparative studies, thus promoting the (a) reliability and (b) relevance of the results. For example, this figure is generated by `examples/basic_3.py`, making use of built-in tools for experiment and result management, reproduces figure 5.7 of [these lecture notes](http://cerea.enpc.fr/HomePages/bocquet/teaching/assim-mb-en.pdf).  DAPPER is (c) open source, written in Python, and (d) focuses on readability; this promotes the (c) reproduction and (d) dissemination of the underlying science, and makes it easy to adapt and extend. It also illustrates how to parallelise ensemble forecasts (e.g. the QG model), local analyses (e.g. the LETKF), and independent experiments (e.g. `examples/basic_3.py`). It comes with a battery of diagnostics and statistics. These all get averaged over subdomains (e..g "ocean" and "land") and then in time. Confidence intervals are computed, including correction for auto-correlations, and used for uncertainty quantification, and significant digits printing. Several diagnostics are included in the on-line "liveplotting" illustrated below, which may be paused for further interactive inspection.  In summary, DAPPER is well suited for teaching and fundamental DA research. Also see its [drawbacks](#similar-projects). ## Installation Successfully tested on Linux/Mac/Windows. ### Prerequisite: Python>=3.9 If you're an expert, setup a python environment however you like. Otherwise: Install [Anaconda](https://www.anaconda.com/download), then open the [Anaconda terminal](https://docs.conda.io/projects/conda/en/latest/user-guide/getting-started.html#starting-conda) and run the following commands: ```sh conda create --yes --name dapper-env python=3.9 conda activate dapper-env python --version ``` Ensure the printed version is 3.9 or more. *Keep using the same terminal for the commands below.* ### Install #### *Either*: Install for development (recommended) *Do you want the DAPPER code available to play around with?* Then - Download and unzip (or `git clone`) DAPPER. - Move the resulting folder wherever you like, and `cd` into it *(ensure you're in the folder with a `setup.py` file)*. - `pip install -e '.'` #### *Or*: Install as library *Do you just want to run a script that requires DAPPER?* Then - If the script comes with a `requirements.txt` file that lists DAPPER, then do `pip install -r path/to/requirements.txt`. - If not, hopefully you know the version of DAPPER needed. Run `pip install dapper==1.6.0` to get version `1.6.0` (as an example). #### *Finally*: Test the installation You should now be able to do run your script with `python path/to/script.py`. For example, if you are in the DAPPER dir, python examples/basic_1.py **PS**: If you closed the terminal (or shut down your computer), you'll first need to run `conda activate dapper-env` ## DA methods Method | Literature reproduced ------------------------------------------------------ | ------------------------ EnKF 1 | [Sakov08](https://nansencenter.github.io/DAPPER/bib.html#bib.sakov2008deterministic), [Hoteit15](https://nansencenter.github.io/DAPPER/bib.html#bib.hoteit2015mitigating), [Grudzien2020](https://nansencenter.github.io/DAPPER/bib.html#bib.grudzien2020numerical) EnKF-N | [Bocquet12](https://nansencenter.github.io/DAPPER/bib.html#bib.bocquet2012combining), [Bocquet15](https://nansencenter.github.io/DAPPER/bib.html#bib.bocquet2015expanding) EnKS, EnRTS | [Raanes2016](https://nansencenter.github.io/DAPPER/bib.html#bib.raanes2016thesis) iEnKS / iEnKF / EnRML / ES-MDA 2 | [Sakov12](https://nansencenter.github.io/DAPPER/bib.html#bib.sakov2012iterative), [Bocquet12](https://nansencenter.github.io/DAPPER/bib.html#bib.Bocquet12), [Bocquet14](https://nansencenter.github.io/DAPPER/bib.html#bib.bocquet2014iterative) LETKF, local & serial EAKF | [Bocquet11](https://nansencenter.github.io/DAPPER/bib.html#bib.bocquet2011ensemble) Sqrt. model noise methods | [Raanes2014](https://nansencenter.github.io/DAPPER/bib.html#bib.raanes2014ext) Particle filter (bootstrap) 3 | [Bocquet10](https://nansencenter.github.io/DAPPER/bib.html#bib.bocquet2010beyond) Optimal/implicit Particle filter 3 | [Bocquet10](https://nansencenter.github.io/DAPPER/bib.html#bib.bocquet2010beyond) NETF | [Todter15](https://nansencenter.github.io/DAPPER/bib.html#bib.todter2015second), [Wiljes16](https://nansencenter.github.io/DAPPER/bib.html#bib.wiljes2016second) Rank histogram filter (RHF) | [Anderson10](https://nansencenter.github.io/DAPPER/bib.html#bib.anderson2010non) 4D-Var | 3D-Var | Extended KF | Optimal interpolation | Climatology | 1: Stochastic, DEnKF (i.e. half-update), ETKF (i.e. sym. sqrt.). Serial forms are also available. Tuned with inflation and "random, orthogonal rotations". 2: Also supports the bundle version, and "EnKF-N"-type inflation. 3: Resampling: multinomial (including systematic/universal and residual). The particle filter is tuned with "effective-N monitoring", "regularization/jittering" strength, and more. For a list of ready-made experiments with suitable, tuned settings for a given method (e.g. the `iEnKS`), use: ```sh grep -r "xp.*iEnKS" dapper/mods ``` ## Test cases (models) Simple models facilitate the reliability, reproducibility, and interpretability of experiment results. Model | Lin | TLM** | PDE? | Phys.dim. | State len | Lyap0 | Implementer ----------- | --- | ----- | ---- | --------- | --------- | ------ | ---------- Id | Yes | Yes | No | N/A | * | 0 | Raanes Linear Advect. (LA) | Yes | Yes | Yes | 1d | 1000 * | 51 | Evensen/Raanes DoublePendulum | No | Yes | No | 0d | 4 | 2 | Matplotlib/Raanes Ikeda | No | Yes | No | 0d | 2 | 1 | Raanes LotkaVolterra | No | Yes | No | 0d | 5 * | 1 | Wikipedia/Raanes Lorenz63 | No | Yes | "Yes" | 0d | 3 | 2 | Sakov Lorenz84 | No | Yes | No | 0d | 3 | 2 | Raanes Lorenz96 | No | Yes | No | 1d | 40 * | 13 | Raanes Lorenz96s | No | Yes | No | 1d | 10 * | 4 | Grudzien LorenzUV | No | Yes | No | 2x 1d | 256 + 8 * | 60 | Raanes LorenzIII | No | No | No | 1d | 960 * | 164 | Raanes Vissio-Lucarini 20 | No | Yes | No | 1d | 36 * | 10 | Yumeng Kuramoto-Sivashinsky | No | Yes | Yes | 1d | 128 * | 11 | Kassam/Raanes Quasi-Geost (QG) | No | No | Yes | 2d | 12917k | 140 | Sakov - `*`: Flexible; set as necessary - `**`: Tangent Linear Model included? The models are found as subdirectories within `dapper/mods`. A model should be defined in a file named `__init__.py`, and illustrated by a file named `demo.py`. Most other files within a model subdirectory are usually named `authorYEAR.py` and define a `HMM` object, which holds the settings of a specific twin experiment, using that model, as detailed in the corresponding author/year's paper. A list of these files can be obtained using ```sh find dapper/mods -iname '[a-z]*[0-9]*.py' ``` Some files contain settings used by several papers. Moreover, at the bottom of each such file should be (in comments) a list of suitable, tuned settings for various DA methods, along with their expected, average `rmse.a` score for that experiment. As mentioned [above](#da-methods), DAPPER reproduces literature results. You will also find results that were not reproduced by DAPPER. ## Similar projects DAPPER is aimed at research and teaching (see discussion up top). Example of limitations: - It is not suited for very big models (>60k unknowns). - Non-uniform time sequences. The scope of DAPPER is restricted because 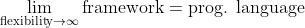 Moreover, even straying beyond basic configurability appears [unrewarding](https://en.wikipedia.org/wiki/Flexibility%E2%80%93usability_tradeoff) when already building on a high-level language such as Python. Indeed, you may freely fork and modify the code of DAPPER, which should be seen as a set of templates, and not a framework. Also, DAPPER comes with no guarantees/support. Therefore, if you have an *operational* or real-world application, such as WRF, you should look into one of the alternatives, sorted by approximate project size. Name | Developers | Purpose (approximately) ------------------ | --------------------- | ----------------------------- [DART][1] | NCAR | General [PDAF][7] | AWI | General [JEDI][21] | JCSDA (NOAA, NASA, ++)| General [OpenDA][3] | TU Delft | General [EMPIRE][4] | Reading (Met) | General [ERT][2] | Statoil | History matching (Petroleum DA) [PIPT][14] | CIPR | History matching (Petroleum DA) [MIKE][9] | DHI | Oceanographic [OAK][10] | Lige | Oceanographic [Siroco][11] | OMP | Oceanographic [Verdandi][6] | INRIA | Biophysical DA [PyOSSE][8] | Edinburgh, Reading | Earth-observation DA Below is a list of projects with a purpose more similar to DAPPER's (research *in* DA, and not so much *using* DA): Name | Developers | Notes ------------------------------------ | ---------------------- | --------------------------------- [DAPPER][22] | Raanes, Chen, Grudzien | Python [SANGOMA][5] | Conglomerate* | Fortran, Matlab [hIPPYlib][25] | Villa, Petra, Ghattas | Python, adjoint-based PDE methods [FilterPy][12] | R. Labbe | Python. Engineering oriented. [DASoftware][13] | Yue Li, Stanford | Matlab. Large inverse probs. [Pomp][18] | U of Michigan | R [EnKF-Matlab][15] | Sakov | Matlab [EnKF-C][17] | Sakov | C. Light-weight, off-line DA [pyda][16] | Hickman | Python [PyDA][19] | Shady-Ahmed | Python [DasPy][20] | Xujun Han | Python [DataAssim.jl][23] | Alexander-Barth | Julia [DataAssimilationBenchmarks.jl][24] | Grudzien | Julia, Python [EnsembleKalmanProcesses.jl][26] | Clim. Modl. Alliance | Julia, EKI (optim) Datum | Raanes | Matlab IEnKS code | Bocquet | Python The `EnKF-Matlab` and `IEnKS` codes have been inspirational in the development of DAPPER. `*`: AWI/Liege/CNRS/NERSC/Reading/Delft [1]: https://www.image.ucar.edu/DAReS/DART/ [2]: https://github.com/equinor/ert [3]: https://www.openda.org/ [4]: https://www.met.reading.ac.uk/~darc/empire/index.php [5]: https://www.data-assimilation.net/ [6]: http://verdandi.sourceforge.net/ [7]: https://pdaf.awi.de/trac/wiki [8]: https://www.geos.ed.ac.uk/~lfeng/ [9]: http://www.dhigroup.com/ [10]: https://github.com/gher-ulg/OAK [11]: https://www5.obs-mip.fr/sirocco/assimilation-tools/sequoia-data-assimilation-platform/ [12]: https://github.com/rlabbe/filterpy [13]: https://github.com/judithyueli/DASoftware [14]: http://uni.no/en/uni-cipr/ [15]: http://enkf.nersc.no/ [16]: http://hickmank.github.io/pyda/ [17]: https://github.com/sakov/enkf-c [18]: https://github.com/kingaa/pomp [19]: https://github.com/Shady-Ahmed/PyDA [20]: https://github.com/daspy/daspy [21]: https://jointcenterforsatellitedataassimilation-jedi-docs.readthedocs-hosted.com/en/latest/ [22]: https://github.com/nansencenter/DAPPER [23]: https://juliahub.com/docs/DataAssim/qCDwD/0.3.2/ [24]: https://github.com/cgrudz/DataAssimilationBenchmarks.jl [25]: https://hippylib.github.io/ [26]: https://github.com/CliMA/EnsembleKalmanProcesses.jl ## Contributing ### Issues and Pull requests Do not hesitate to open an issue, whether to report a problem or ask a question. It may take some time for us to get back to you, since DAPPER is primarily a volunteer effort. Please start by perusing the [documentation](https://nansencenter.github.io/DAPPER/dapper.html) and searching the issue tracker for similar items. Pull requests are very welcome. Examples: adding a new DA method, dynamical models, experimental configuration reproducing literature results, or improving the features and capabilities of DAPPER. Please keep in mind the intentional [limitations](https://github.com/nansencenter/DAPPER#similar-projects) and read the [developers guidelines](https://nansencenter.github.io/DAPPER/dev_guide). ### Contributors Patrick N. Raanes, Yumeng Chen, Colin Grudzien, Maxime Tondeur, Remy Dubois DAPPER is developed and maintained at NORCE (Norwegian Research Institute) and the Nansen Environmental and Remote Sensing Center (NERSC), in collaboration with the University of Reading, the UK National Centre for Earth Observation (NCEO), and the Center for Western Weather and Water Extremes (CW3E).  


## Publications - [Combining data assimilation and machine learning to emulate a dynamical model from sparse and noisy observations: A case study with the Lorenz 96 model](https://doi.org/10.1016/j.jocs.2020.101171) - [Adaptive covariance inflation in the ensemble Kalman filter by Gaussian scale mixtures](https://doi.org/10.1002/qj.3386) - [Revising the stochastic iterative ensemble smoother](https://doi.org/10.5194/npg-26-325-2019) - [p-Kernel Stein Variational Gradient Descent for Data Assimilation and History Matching](https://doi.org/10.1007/s11004-021-09937-x) - [Springer book chapter: Data Assimilation for Chaotic Dynamics](https://doi.org/10.1007/978-3-030-77722-7_1)
Owner
- Name: Arfon Smith
- Login: arfon
- Kind: user
- Location: Edinburgh
- Website: arfon.org
- Twitter: arfon
- Repositories: 86
- Profile: https://github.com/arfon
Schmidt Sciences. Previously product @github, data science @spacetelescope, @zooniverse co-founder. Editor-in-chief of the Journal of Open Source Software