Science Score: 54.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (4.3%) to scientific vocabulary
Repository
clip record
Basic Info
- Host: GitHub
- Owner: huangqj23
- License: other
- Language: Python
- Default Branch: main
- Size: 10.4 MB
Statistics
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
- Releases: 0
Metadata Files
README.md
OpenCLIP
[论文] [引用] [Clip Colab] [Coca Colab] 
欢迎来到OpenAI的CLIP(对比语言-图像预训练)的开源实现。
使用这个代码库,我们在各种数据源和计算预算上训练了多个模型,从小规模实验到包括在LAION-400M、LAION-2B和DataComp-1B等数据集上训练的模型的大规模运行。我们在论文对比语言-图像学习的可重复缩放定律中详细研究了我们的许多模型及其缩放特性。我们训练的一些最佳模型及其零样本ImageNet-1k准确率如下所示,其中包括由OpenAI训练的ViT-L模型和其他最先进的开源替代模型(所有模型均可通过OpenCLIP加载)。我们在此处提供了关于我们完整的预训练模型集合的更多细节,并在此处提供了38个数据集的零样本结果。
| 模型 | 训练数据 | 分辨率 | 看到的样本数量 | ImageNet零样本准确率 |
| -------- | ------- | ------- | ------- | ------- |
| ConvNext-Base | LAION-2B | 256px | 13B | 71.5% |
| ConvNext-Large | LAION-2B | 320px | 29B | 76.9% |
| ConvNext-XXLarge | LAION-2B | 256px | 34B | 79.5% |
| ViT-B/32 | DataComp-1B | 256px | 34B | 72.8% |
| ViT-B/16 | DataComp-1B | 224px | 13B | 73.5% |
| ViT-L/14 | LAION-2B | 224px | 32B | 75.3% |
| ViT-H/14 | LAION-2B | 224px | 32B | 78.0% |
| ViT-L/14 | DataComp-1B | 224px | 13B | 79.2% |
| ViT-G/14 | LAION-2B | 224px | 34B | 80.1% |
| | | | | |
| ViT-L/14 (原始CLIP) | WIT | 224px | 13B | 75.5% |
| ViT-SO400M/14 (SigLIP) | WebLI | 224px | 45B | 82.0% |
| ViT-SO400M-14-SigLIP-384 (SigLIP) | WebLI | 384px | 45B | 83.1% |
| ViT-H/14-quickgelu (DFN) | DFN-5B | 224px | 39B | 83.4% |
| ViT-H-14-378-quickgelu (DFN) | DFN-5B | 378px | 44B | 84.4% |
带有附加模型特定细节的模型卡片可以在Hugging Face Hub上的OpenCLIP库标签下找到:https://huggingface.co/models?library=open_clip.如果您发现此代码库有用,请考虑引用。 我们欢迎任何人提交问题或发送电子邮件,如果您有其他请求或建议。
注意,src/open_clip/中的部分建模和分词器代码是对OpenAI官方代码库的改编。
方法
|  |
|:--:|
| 图片来源: https://github.com/openai/CLIP |
|
|:--:|
| 图片来源: https://github.com/openai/CLIP |
使用方法
pip install open_clip_torch
```python import torch from PIL import Image import open_clip
model, , preprocess = openclip.createmodelandtransforms('ViT-B-32', pretrained='laion2bs34bb79k') model.eval() # 默认情况下模型处于训练模式,会影响一些使用BatchNorm或随机深度激活的模型 tokenizer = openclip.get_tokenizer('ViT-B-32')
image = preprocess(Image.open("docs/CLIP.png")).unsqueeze(0) text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.nograd(), torch.cuda.amp.autocast(): imagefeatures = model.encodeimage(image) textfeatures = model.encodetext(text) imagefeatures /= imagefeatures.norm(dim=-1, keepdim=True) textfeatures /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs) # 打印: [[1., 0., 0.]] ```
另请参阅此 [Clip Colab]。
若要高效地计算数十亿个嵌入,您可以使用具有openclip支持的clip-retrieval。
预训练模型
我们提供了一个简单的模型接口来实例化预训练和未训练的模型。 要查看哪些预训练模型可用,请使用以下代码片段。 有关我们预训练模型的更多详细信息,请查看这里。
```python
import openclip openclip.list_pretrained() ```
您可以在此表中找到我们支持的模型的更多信息(例如参数数量、FLOPs)。
注意:许多现有检查点使用原始OpenAI模型中的QuickGELU激活。实际上,这种激活在最近版本的PyTorch中不如原生torch.nn.GELU高效。模型默认现在是nn.GELU,因此应该使用带有-quickgelu后缀的模型定义来获取OpenCLIP预训练权重。所有OpenAI预训练权重将始终默认为QuickGELU。也可以使用非-quickgelu模型定义与使用QuickGELU的预训练权重,但会有准确性下降,对于长时间运行的微调,这种下降可能会消失。
未来训练的模型将使用nn.GELU。
加载模型
可以使用open_clip.create_model_and_transforms加载模型,如下例所示。模型名称和相应的pretrained键与open_clip.list_pretrained()的输出兼容。
pretrained参数也接受本地路径,例如/path/to/my/b32.pt。
您还可以通过这种方式从huggingface加载检查点。为此,请下载open_clip_pytorch_model.bin文件(例如, https://huggingface.co/laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K/tree/main),并使用pretrained=/path/to/open_clip_pytorch_model.bin。
```python
pretrained 也接受本地路径
model, , preprocess = openclip.createmodelandtransforms('ViT-B-32', pretrained='laion2bs34b_b79k') ```
在分类任务上的微调这个存储库专注于训练CLIP模型。要在下游分类任务(如ImageNet)上微调已训练的零样本模型,请参阅我们的另一个存储库:WiSE-FT。WiSE-FT存储库包含我们关于零样本模型的鲁棒微调论文的代码,在其中我们介绍了一种在保持分布偏移下鲁棒性的情况下微调零样本模型的技术。
数据
要下载作为webdataset的数据集,我们推荐使用img2dataset。
概念性字幕
YFCC和其他数据集
除了通过上面提到的CSV文件指定训练数据之外,我们的代码库还支持推荐用于大规模数据集的webdataset。预期的格式是一系列.tar文件。每个.tar文件应包含每个训练实例的两个文件,一个用于图像,一个用于对应的文本。两个文件应具有相同的名称但不同的扩展名。例如,shard_001.tar可以包含文件如abc.jpg和abc.txt。您可以在https://github.com/webdataset/webdataset了解更多关于webdataset的信息。我们使用每个包含1,000个数据点的.tar文件,并使用tarp创建它们。
您可以从Multimedia Commons下载YFCC数据集。与OpenAI相似,我们使用YFCC的一个子集来达到上述精度数值。此子集中的图像索引位于OpenAI的CLIP存储库中。
训练CLIP
安装
我们建议您首先创建一个虚拟环境:
python3 -m venv .env
source .env/bin/activate
pip install -U pip
然后您可以通过pip install 'open_clip_torch[training]'安装openclip进行训练。
开发
如果您想做出更改以贡献代码,可以克隆openclip然后在openclip文件夹中运行make install(在创建虚拟环境之后)。
根据https://pytorch.org/get-started/locally/安装pip PyTorch
您可以运行make install-training来安装训练依赖
测试
可以通过make install-test然后make test运行测试
python -m pytest -x -s -v tests -k "training" 运行特定测试
针对特定git修订或标签运行回归测试:
1. 生成测试数据
sh
python tests/util_test.py --model RN50 RN101 --save_model_list models.txt --git_revision 9d31b2ec4df6d8228f370ff20c8267ec6ba39383
警告:这将调用git并修改您的工作树,但在数据生成后会重置到当前状态!请勿在以这种方式生成测试数据时修改您的工作树。
- 运行回归测试
sh OPEN_CLIP_TEST_REG_MODELS=models.txt python -m pytest -x -s -v -m regression_test
示例单进程运行代码:
```bash python -m opencliptrain.main \ --save-frequency 1 \ --zeroshot-frequency 1 \ --report-to tensorboard \ --train-data="/path/to/traindata.csv" \ --val-data="/path/to/validationdata.csv" \ --csv-img-key filepath \ --csv-caption-key title \ --imagenet-val=/path/to/imagenet/root/val/ \ --warmup 10000 \ --batch-size=128 \ --lr=1e-3 \ --wd=0.1 \ --epochs=30 \ --workers=8 \ --model RN50
```
注意: imagenet-val 是 ImageNet 验证 集的路径,用于零样本评估,不是训练集!
如果您不想在整个训练过程中对 ImageNet 进行零样本评估,可以删除此参数。请注意,val 文件夹应包含子文件夹。如果没有,请使用这个脚本。
多GPU及更高配置
此代码已经过多达1024个A100的实战测试,并提供多种分布式训练解决方案。我们还提供对 SLURM 集群的原生支持。
随着用于训练的设备数量的增加,logit 矩阵的空间复杂度也随之增加。使用简单的 all-gather 方案,空间复杂度将是 O(n^2)。相反,如果使用 --gather-with-grad 和 --local-loss 标志,复杂度可能会有效地变为线性。这种改变产生与简单方法一对一的数值结果。
轮次
对于较大的数据集(例如 Laion2B),我们建议将 --train-num-samples 设置为小于完整轮次的值,例如 --train-num-samples 135646078 配合 --dataset-resampled 设置为轮次的1/16进行有放回的采样。这允许更频繁地检查点以便更频繁地进行评估。
Patch Dropout
最近的研究表明,可以丢弃一半到四分之三的视觉标记,从而在不损失准确性的情况下实现高达2-3倍的训练速度。
您可以在视觉变换器配置中使用键 patch_dropout 来设置此项。
在论文中,他们还在最后进行了无 patch dropout 的微调。您可以使用命令行参数 --force-patch-dropout 0. 来实现这一点。
多数据源
OpenCLIP 支持使用多个数据源,通过用 :: 分隔不同的数据路径。例如,要在 CC12M 和 LAION 上训练,可以使用 --train-data "/data/cc12m/cc12m-train-{0000..2175}.tar::/data/LAION-400M/{00000..41455}.tar"。在这些情况下,建议使用 --dataset-resampled。
默认情况下,模型期望从每个源看到样本的次数与源的大小成正比。例如,当在一个大小为 400M 的数据源和一个大小为 10M 的数据源上训练时,期望从第一个源看到样本的可能性大 40 倍。
我们还支持不同的数据源加权,通过使用 --train-data-upsampling-factors 标志。例如,在上述情况下使用 --train-data-upsampling-factors=1::1 等同于不使用该标志,而 --train-data-upsampling-factors=1::2 等同于将第二个数据源上采样两次。如果您希望以相同的频率从数据源中采样,则上采样因子应与数据源的大小成反比。例如,如果数据集 A 有 1000 个样本,数据集 B 有 100 个样本,您可以使用 --train-data-upsampling-factors=0.001::0.01(或类似的,--train-data-upsampling-factors=1::10)。
单节点
我们使用 torchrun 启动分布式作业。以下是在一个有 4 个 GPU 的节点上启动作业:
bash
cd open_clip/src
torchrun --nproc_per_node 4 -m open_clip_train.main \
--train-data '/data/cc12m/cc12m-train-{0000..2175}.tar' \
--train-num-samples 10968539 \
--dataset-type webdataset \
--batch-size 320 \
--precision amp \
--workers 4 \
--imagenet-val /data/imagenet/validation/
多节点
上述脚本同样适用,只要用户包括节点数量和主节点的信息。
bash
cd open_clip/src
torchrun --nproc_per_node=4 \
--rdzv_endpoint=$HOSTE_NODE_ADDR \
-m open_clip_train.main \
--train-data '/data/cc12m/cc12m-train-{0000..2175}.tar' \
--train-num-samples 10968539 \
--dataset-type webdataset \
--batch-size 320 \
--precision amp \
--workers 4 \
--imagenet-val /data/imagenet/validation/
SLURM这可能是最简单的解决方案。以下脚本用于训练我们最大的模型:
```bash
!/bin/bash -x
SBATCH --nodes=32
SBATCH --gres=gpu:4
SBATCH --ntasks-per-node=4
SBATCH --cpus-per-task=6
SBATCH --wait-all-nodes=1
SBATCH --job-name=open_clip
SBATCH --account=ACCOUNT_NAME
SBATCH --partition PARTITION_NAME
eval "$(/path/to/conda/bin/conda shell.bash hook)" # 初始化 conda conda activate openclip export CUDAVISIBLEDEVICES=0,1,2,3 export MASTERPORT=12802
masteraddr=$(scontrol show hostnames "$SLURMJOBNODELIST" | head -n 1) export MASTERADDR=$master_addr
cd /shared/openclip export PYTHONPATH="$PYTHONPATH:$PWD/src" srun --cpubind=v --accel-bind=gn python -u src/opencliptrain/main.py \ --save-frequency 1 \ --report-to tensorboard \ --train-data="/data/LAION-400M/{00000..41455}.tar" \ --warmup 2000 \ --batch-size=256 \ --epochs=32 \ --workers=8 \ --model ViT-B-32 \ --name "ViT-B-32-Vanilla" \ --seed 0 \ --local-loss \ --gather-with-grad ```
从检查点恢复:
bash
python -m open_clip_train.main \
--train-data="/path/to/train_data.csv" \
--val-data="/path/to/validation_data.csv" \
--resume /path/to/checkpoints/epoch_K.pt
训练 CoCa:
通过使用训练脚本的 --model 参数指定 CoCa 配置,可以启用CoCa模型的训练。目前可用的配置有 "cocabase"、"cocaViT-B-32" 和 "cocaroberta-ViT-B-32"(使用 RoBERTa 作为文本编码器)。CoCa 配置与 CLIP 配置不同,因为它们有一个额外的 "multimodalcfg" 组件,用于指定多模态文本解码器的参数。以下是 cocaViT-B-32 配置的示例:
```json
"multimodalcfg": {
"contextlength": 76,
"vocabsize": 49408,
"width": 512,
"heads": 8,
"layers": 12,
"latentdim": 512,
"attnpoolerheads": 8
}
```
感谢 lucidrains 提供初始代码,感谢 gpucce 使代码适配 openclip,以及感谢 iejMac 对模型进行训练。
使用 CoCa 生成文本
```python import open_clip import torch from PIL import Image
model, , transform = openclip.createmodelandtransforms( modelname="cocaViT-L-14", pretrained="mscocofinetuned_laion2B-s13B-b90k" )
im = Image.open("cat.jpg").convert("RGB") im = transform(im).unsqueeze(0)
with torch.no_grad(), torch.cuda.amp.autocast(): generated = model.generate(im)
print(openclip.decode(generated[0]).split("<endoftext>")[0].replace("<startoftext>", "")) ``` 另请参阅此 [[Coca Colab]](https://colab.research.google.com/github/mlfoundations/openclip/blob/master/docs/Interactingwithopen_coca.ipynb)
CoCa 微调
要在 mscoco 上微调 CoCa,首先创建数据集,一种方法是使用 csvdataset,也许最简单的方法是使用 CLIP_benchmark,它反过来使用 pycocotools(也可以单独使用)。
```python from clipbenchmark.datasets.builder import builddataset import pandas as pd import os
rootpath = "path/to/data/dir" # 将其设置为有意义的路径 ds = builddataset("mscococaptions", root=rootpath, split="train", task="captioning") # 如果数据集不存在,这将下载数据集 coco = ds.coco imgs = coco.loadImgs(coco.getImgIds()) futuredf = {"filepath":[], "title":[]} for img in imgs: caps = coco.imgToAnns[img["id"]] for cap in caps: futuredf["filepath"].append(img["filename"]) futuredf["title"].append(cap["caption"]) pd.DataFrame.fromdict(futuredf).tocsv( os.path.join(rootpath, "train2014.csv"), index=False, sep="\t" ) ```
这应该创建一个可以用于使用 open_clip 微调 CoCa 的 csv 数据集
bash
python -m open_clip_train.main \
--dataset-type "csv" \
--train-data "path/to/data/dir/train2014.csv" \
--warmup 1000 \
--batch-size 128 \
--lr 1e-5 \
--wd 0.1 \
--epochs 1 \
--workers 3 \
--model "coca_ViT-L-14" \
--report-to "wandb" \
--coca-contrastive-loss-weight 0 \
--coca-caption-loss-weight 1 \
--log-every-n-steps 100
这是一种通用设置,openclip 有很多可以设置的参数,```python -m openclip_train.main --help``` 应该能显示它们。与预训练相比,唯一相关的变化是两个参数
bash
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
这使得模型仅训练生成部分。
使用预训练语言模型作为文本编码器进行训练:
如果希望使用不同的语言模型作为 CLIP 的文本编码器,可以通过使用 src/open_clip/model_configs 中的一个 Hugging Face 模型配置,并分别将其分词器传递为 --model 和 --hf-tokenizer-name 参数。目前我们仅支持 RoBERTa(“test-roberta”配置),但是添加新模型应该很简单。您还可以使用 --lock-text-unlocked-layers 参数确定从末尾开始解冻多少层。以下是一个使用 RoBERTa LM 进行 CLIP 训练的示例命令,该模型的最后 10 层未冻结:
bash
python -m open_clip_train.main \
--train-data="pipe:aws s3 cp s3://s-mas/cc3m/{00000..00329}.tar -" \
--train-num-samples 3000000 \
--val-data="pipe:aws s3 cp s3://s-mas/cc3m/{00330..00331}.tar -" \
--val-num-samples 10000 \
--dataset-type webdataset \
--batch-size 256 \
--warmup 2000 \
--epochs 10 \
--lr 5e-4 \
--precision amp \
--workers 6 \
--model "roberta-ViT-B-32" \
--lock-text \
--lock-text-unlocked-layers 10 \
--name "10_unfrozen" \
--report-to "tensorboard" \
损失曲线
在具有 8 个 GPU 的机器上运行时,该命令应该为概念性字幕生成以下训练曲线: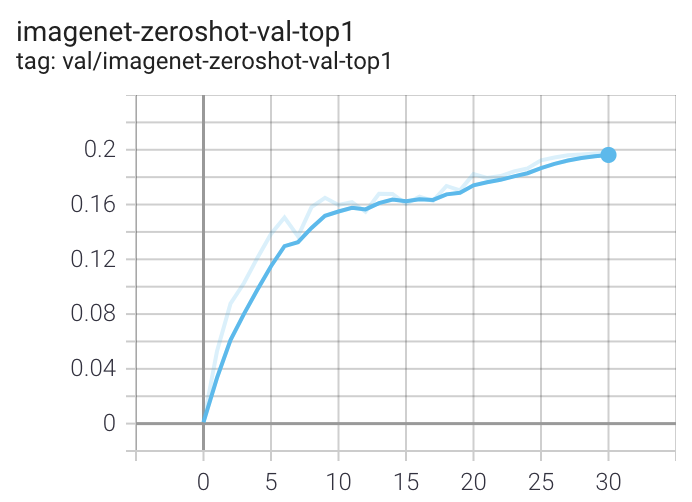
有关Conceptual Captions的更详细曲线,请参见/docs/clipconceptualcaptions.md。
在YFCC上训练RN50时,使用与上述相同的超参数,除了lr=5e-4和epochs=32。
注意,要使用其他模型,如ViT-B/32或RN50x4或RN50x16或ViT-B/16,请使用--model RN50x4指定。
日志记录
对于tensorboard日志记录,运行:
bash
tensorboard --logdir=logs/tensorboard/ --port=7777
对于wandb日志记录,我们建议查看step变量而不是Step,因为在该代码库的早期版本中,后者未正确设置。
对于在https://github.com/mlfoundations/open_clip/pull/613之前训练的旧版本模型,Step变量应被忽略。
对于在该PR之后的新运行,两个变量相同。
评估/零样本
我们推荐使用https://github.com/LAION-AI/CLIP_benchmark#how-to-use在40个数据集上进行系统评估。
评估本地检查点:
bash
python -m open_clip_train.main \
--val-data="/path/to/validation_data.csv" \
--model RN101 \
--pretrained /path/to/checkpoints/epoch_K.pt
评估托管的ImageNet零样本预测的预训练检查点:
bash
python -m open_clip_train.main \
--imagenet-val /path/to/imagenet/validation \
--model ViT-B-32-quickgelu \
--pretrained laion400m_e32
模型蒸馏
您可以通过使用--distill-model和--distill-pretrained指定要蒸馏的模型来进行预训练模型的蒸馏。
例如,要从OpenAI ViT-L/14进行蒸馏,请使用--distill-model ViT-L-14 --distill-pretrained openai。
梯度累积
要模拟更大的批次,请使用--accum-freq k。如果每个GPU的批次大小--batch-size为m,则有效的批次大小将为k * m * num_gpus。
当--accum-freq从默认值1增加时,样本/秒将保持大致不变(批次大小将翻倍,批次时间也将翻倍)。建议在增加--accum-freq之前,使用其他特性来减少批次大小,如--grad-checkpointing --local-loss --gather-with-grad。这些特性可以与--accum-freq一起使用。
现在每个样本有2次前向传递,而不是1次。然而,第一次是在torch.no_grad下完成的。
需要一些额外的GPU内存——所有m批次的特性和数据都存储在内存中。
也有m次损失计算,而不是通常的1次。
更多信息请参见Cui等人(https://arxiv.org/abs/2112.09331)或Pham等人(https://arxiv.org/abs/2111.10050)。
Int8支持
我们提供了int8训练和推理的测试支持。
您可以通过--use-bnb-linear SwitchBackLinearGlobal或--use-bnb-linear SwitchBackLinearGlobalMemEfficient启用int8训练。
请参阅bitsandbytes库以了解这些层的定义。
对于CLIP VIT-Huge,目前应对应于10%的训练速度提升且无精度损失。
更多速度提升将在注意力层重构后实现,以便线性层也可以在那里替换。
请参阅教程https://github.com/mlfoundations/openclip/blob/main/tutorials/int8tutorial.ipynb或论文。
远程加载/训练支持
始终可以直接从远程文件恢复,例如,位于s3桶中的文件。只需设置--resume s3://<path-to-checkpoint>。
这将适用于fsspec支持的任何文件系统。还可以在训练 open_clip 模型时不断备份到 s3。这有助于避免本地文件系统的缓慢。
假设您的节点有一个本地 SSD /scratch,一个 s3 存储桶 s3://<path-to-bucket>。
在这种情况下,设置 --logs /scratch 和 --remote-sync s3://<path-to-bucket>。然后,一个后台进程会将 /scratch/<run-name> 同步到 s3://<path-to-bucket>/<run-name>。同步后,后台进程将休眠 --remote-sync-frequency 秒,默认是5分钟。
还有对其他远程文件系统(不仅仅是 s3)的实验性支持。要这样做,指定 --remote-sync-protocol fsspec。然而,目前这非常慢,不推荐使用。
此外,为了在使用这些功能时可选择性地避免本地保存过多的检查点,可以使用 --delete-previous-checkpoint,在保存新检查点后删除之前的检查点。
注意:如果您在使用 --resume latest 功能时,有几个警告。首先,与 --save-most-recent 一起使用是不支持的。其次,只有 s3 是支持的。最后,由于同步是在后台进行的,最近的检查点可能还没有完成同步到远程。
推送模型到 Hugging Face Hub
模块 open_clip.push_to_hf_hub 包含将模型及其权重和配置推送到 HF Hub 的助手工具。
该工具可以从命令行运行,例如:
python -m open_clip.push_to_hf_hub --model convnext_large_d_320 --pretrained /train/checkpoints/epoch_12.pt --repo-id laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft
鸣谢
我们对高斯超算中心 e.V.(www.gauss-centre.eu)通过约翰·冯·诺依曼计算研究所(NIC)在 GCS 超算 JUWELS Booster 上提供计算时间资助这项工作表示诚挚的感谢。
团队
目前该仓库的开发由 Ross Wightman,Romain Beaumont,Cade Gordon,和 Vaishaal Shankar 领导。
该仓库的原始版本来自华盛顿大学、谷歌、斯坦福、亚马逊、哥伦比亚大学和伯克利的一组研究人员。
Gabriel Ilharco*,Mitchell Wortsman*,Nicholas Carlini,Rohan Taori,Achal Dave,Vaishaal Shankar,John Miller,Hongseok Namkoong,Hannaneh Hajishirzi,Ali Farhadi,Ludwig Schmidt
特别感谢 Jong Wook Kim 和 Alec Radford 在 CLIP 的再现工作中给予的帮助!
Owner
- Name: Theron Skilton
- Login: huangqj23
- Kind: user
- Repositories: 1
- Profile: https://github.com/huangqj23
My name is Theron Skilton, I am a college student and most of the time I have to study. I enjoy rap and dancing, as well as playing basketball.
Citation (CITATION.cff)
cff-version: 1.1.0
message: If you use this software, please cite it as below.
authors:
- family-names: Ilharco
given-names: Gabriel
- family-names: Wortsman
given-names: Mitchell
- family-names: Wightman
given-names: Ross
- family-names: Gordon
given-names: Cade
- family-names: Carlini
given-names: Nicholas
- family-names: Taori
given-names: Rohan
- family-names: Dave
given-names: Achal
- family-names: Shankar
given-names: Vaishaal
- family-names: Namkoong
given-names: Hongseok
- family-names: Miller
given-names: John
- family-names: Hajishirzi
given-names: Hannaneh
- family-names: Farhadi
given-names: Ali
- family-names: Schmidt
given-names: Ludwig
title: OpenCLIP
version: v0.1
doi: 10.5281/zenodo.5143773
date-released: 2021-07-28
GitHub Events
Total
- Push event: 2
- Create event: 2
Last Year
- Push event: 2
- Create event: 2
Dependencies
- ftfy *
- huggingface-hub *
- regex *
- safetensors *
- timm *
- torch >=1.9.0
- torchvision *
- tqdm *
- pytest ==7.2.0 test
- pytest-split ==0.8.0 test
- timm >=1.0.10 test
- transformers * test
- braceexpand *
- fsspec *
- ftfy *
- huggingface_hub *
- pandas *
- regex *
- safetensors *
- timm >=1.0.10
- torch >=1.9.0
- torchvision *
- tqdm *
- transformers *
- webdataset >=0.2.5,<=0.2.86
- ftfy *
- huggingface_hub *
- regex *
- safetensors *
- timm *
- torch >=1.9.0
- torchvision *
- tqdm *