https://github.com/askexplain/interpretable-neural-net
Inspiration for a 1 layer interpretable neural net with a single linear form layer for signal extraction
Science Score: 13.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
○.zenodo.json file
-
○DOI references
-
○Academic publication links
-
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (8.6%) to scientific vocabulary
Repository
Inspiration for a 1 layer interpretable neural net with a single linear form layer for signal extraction
Basic Info
Statistics
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
- Releases: 0
Metadata Files
README.md
Interpretable-Neural-Net
Inspiration for a 1 layer interpretable neural net with a single linear form layer for signal extraction
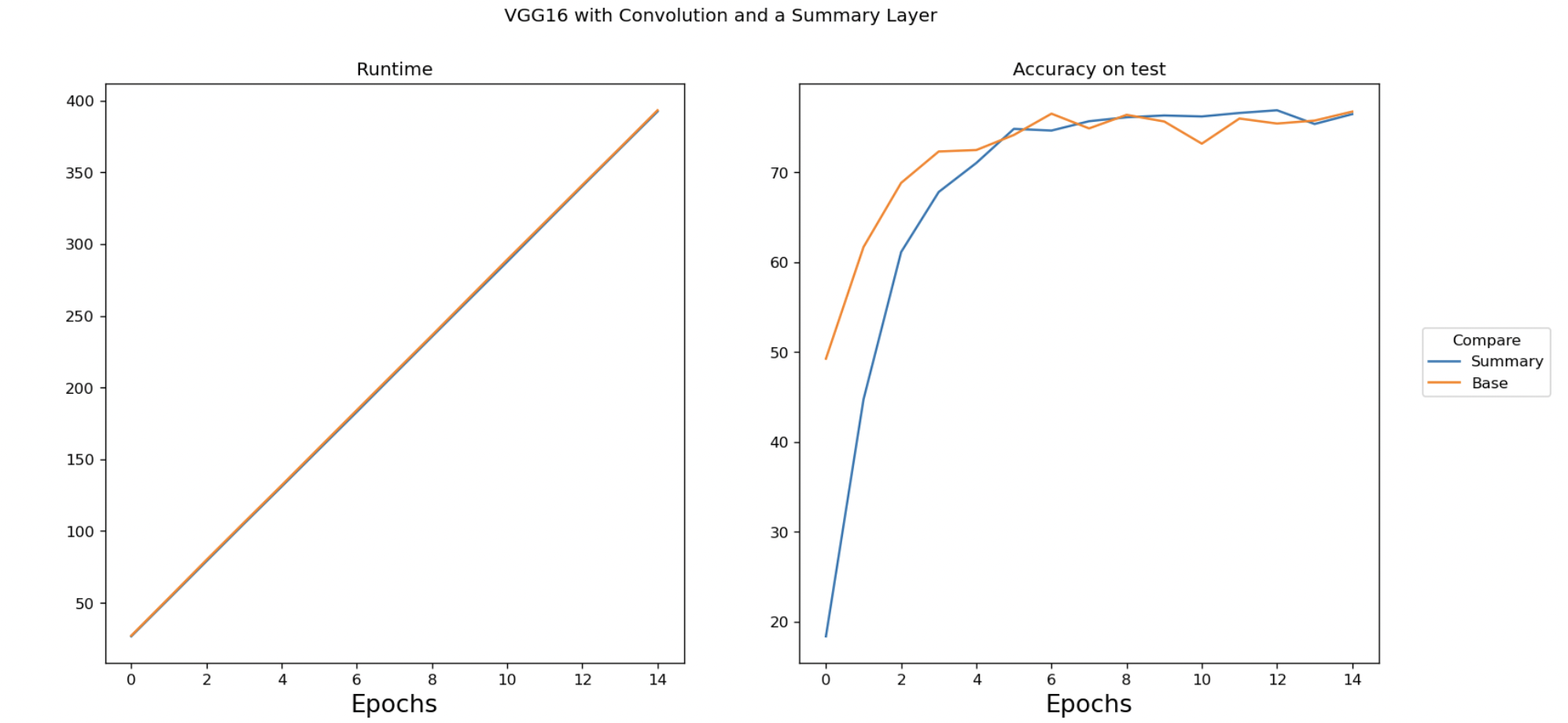
Some results
Here are two neural networks run on CIFAR10 with the VGG neural network (a traditional neural network found in the literature).
One uses the single interpretable linear "summary" layer, and the other uses the standard "base" VGG non-linear sequence of layers.
Some explanations
The model below explains more about the idea - for a single linear form layer
Where Y are the label responses to be predicted while X is the observed data (e.g. convolutions applied to images)
However, given it is a neural network layer, the "layer model" only learns a decomposition of X - in such a way that it fits the following properties:
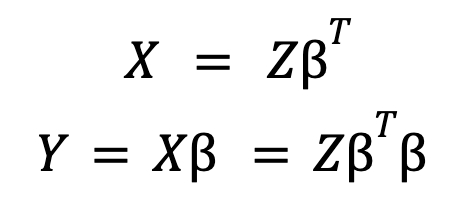
Essentially, linear forms find a latent component Z, followed by a learnable filter set b
Here, X b is equivalent to the latent component multiplied by the covariance of the filters b_transpose b
An extra property
Based on orthgonality, it is possible to reduce the total computations of the summary layer proposed above. Rather than computing an inverse operation every time the summary layer is called - neural networks can take advantage of the simple matrix mulitplication that leads to an equivalent expression ...
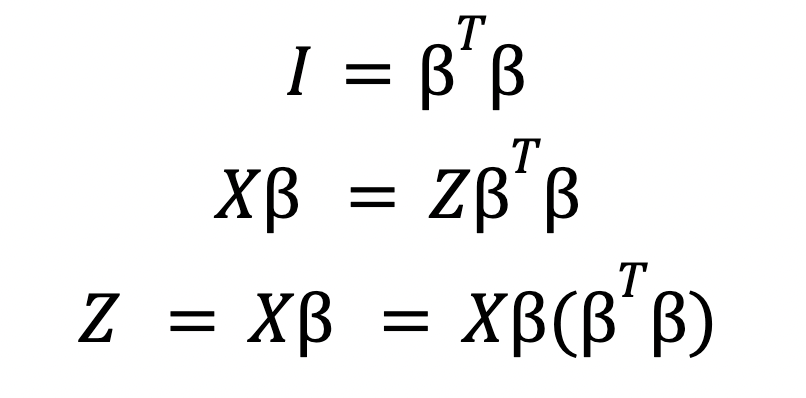
Notice that the latent components Z is now equivalent to X b which is equivalent to X b (b_transpose b).
The loss function given X, which here are the convoluted features along with the linear weights b can now be expressed along with the labels Y in the loss function:

One more property on linearity and non-linearity
There is a well and definite link between the linear expression of this model with the non-linear expression of deep neural networks.
To see how, propose the following:

Owner
- Name: AskExplain
- Login: AskExplain
- Kind: organization
- Repositories: 9
- Profile: https://github.com/AskExplain
GitHub Events
Total
- Push event: 1
Last Year
- Push event: 1