https://github.com/astrogilda/keras-swa
Simple stochastic weight averaging callback for Keras
Science Score: 10.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
○codemeta.json file
-
○.zenodo.json file
-
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (9.4%) to scientific vocabulary
Last synced: 9 months ago
·
JSON representation
Repository
Simple stochastic weight averaging callback for Keras
Basic Info
Statistics
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
- Releases: 0
Fork of simon-larsson/keras-swa
Created over 6 years ago
· Last pushed over 6 years ago
https://github.com/astrogilda/keras-swa/blob/master/
# Keras SWA - Stochastic Weight Averaging
[](https://pypi.python.org/pypi/keras-swa/)
[](https://github.com/simon-larsson/keras-swa/blob/master/LICENSE)
This is an implemention of SWA for Keras and TF-Keras.
## Introduction
Stochastic weight averaging (SWA) is build upon the same principle as [snapshot ensembling](https://arxiv.org/abs/1704.00109) and [fast geometric ensembling](https://arxiv.org/abs/1802.10026). The idea is that averaging select stages of training can lead to better models. Where as the two former methods average by sampling and ensembling models, SWA instead average weights. This has been shown to give comparable improvements confined into a single model.
[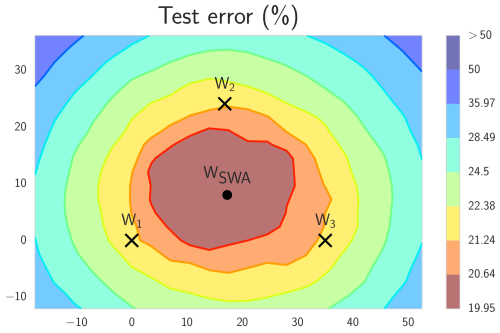](https://raw.githubusercontent.com/simon-larsson/keras-swa/master/swa_illustration.png)
## Paper
- Title: Averaging Weights Leads to Wider Optima and Better Generalization
- Link: https://arxiv.org/abs/1803.05407
- Authors: Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, Andrew Gordon Wilson
- Repo: https://github.com/timgaripov/swa (PyTorch)
## Installation
pip install keras-swa
### SWA API
Keras callback object for SWA.
### Arguments
**start_epoch** - Starting epoch for SWA.
**lr_schedule** - Learning rate schedule. `'manual'` , `'constant'` or `'cyclic'`.
**swa_lr** - Learning rate used when averaging weights.
**swa_lr2** - Upper bound of learning rate for the cyclic schedule.
**swa_freq** - Frequency of weight averagining. Used with cyclic schedules.
**batch_size** - Batch size. Only needed in the Keras API when using both batch normalization and a data generator.
**verbose** - Verbosity mode, 0 or 1.
### Batch Normalization
Last epoch will be a forward pass, i.e. have learning rate set to zero, for models with batch normalization. This is due to the fact that batch normalization uses the running mean and variance of it's preceding layer to make a normalization. SWA will offset this normalization by suddenly changing the weights in the end of training. Therefore, it is necessary for the last epoch to be used to reset and recalculate batch normalization running mean and variance for the updated weights. Batch normalization gamma and beta values are preserved.
**When using manual schedule:** The SWA callback will set learning rate to zero in the last epoch if batch normalization is used. This must not be undone by any external learning rate schedulers for SWA to work properly.
### Learning Rate Schedules
The default schedule is `'manual'`, allowing the learning rate to be controlled by an external learning rate scheduler or the optimizer. Then SWA will only affect the final weights and the learning rate of the last epoch if batch normalization is used. The schedules for the two predefined, `'constant'` or `'cyclic'` can be observed below.
[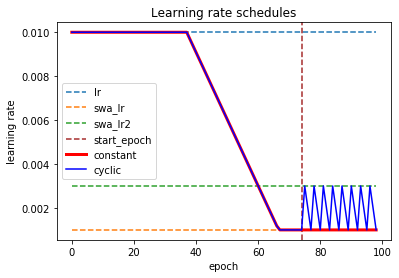](https://raw.githubusercontent.com/simon-larsson/keras-swa/master/lr_schedules.png)
#### Example
For Keras (with constant LR)
```python
from sklearn.datasets.samples_generator import make_blobs
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
from swa.keras import SWA
# make dataset
X, y = make_blobs(n_samples=1000,
centers=3,
n_features=2,
cluster_std=2,
random_state=2)
y = to_categorical(y)
# build model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=SGD(learning_rate=0.1))
epochs = 100
start_epoch = 75
# define swa callback
swa = SWA(start_epoch=start_epoch,
lr_schedule='constant',
swa_lr=0.01,
verbose=1)
# train
model.fit(X, y, epochs=epochs, verbose=1, callbacks=[swa])
```
Or for Keras in Tensorflow (with Cyclic LR)
```python
from sklearn.datasets.samples_generator import make_blobs
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from swa.tfkeras import SWA
# make dataset
X, y = make_blobs(n_samples=1000,
centers=3,
n_features=2,
cluster_std=2,
random_state=2)
y = to_categorical(y)
# build model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=SGD(learning_rate=0.1))
epochs = 100
start_epoch = 75
# define swa callback
swa = SWA(start_epoch=start_epoch,
lr_schedule='cyclic',
swa_lr=0.001,
swa_lr2=0.003,
swa_freq=3,
verbose=1)
# train
model.fit(X, y, epochs=epochs, verbose=1, callbacks=[swa])
```
Output
```
Epoch 1/100
1000/1000 [==============================] - 1s 605us/sample - loss: 0.7635
Epoch 2/100
1000/1000 [==============================] - 0s 94us/sample - loss: 0.6268
...
Epoch 74/100
1000/1000 [==============================] - 0s 92us/sample - loss: 0.3902
Epoch 00075: starting stochastic weight averaging
Epoch 75/100
1000/1000 [==============================] - 0s 94us/sample - loss: 0.3905
Epoch 76/100
1000/1000 [==============================] - 0s 94us/sample - loss: 0.3904
...
Epoch 99/100
1000/1000 [==============================] - 0s 94us/sample - loss: 0.3904
Epoch 100/100
1000/1000 [==============================] - 0s 93us/sample - loss: 0.3903
Epoch 00101: final model weights set to stochastic weight average
```
### Collaborators
- [Simon Larsson](https://github.com/simon-larsson "Github")
- [Alex Stoken](https://github.com/alexstoken "Github")
Owner
- Name: Sankalp Gilda
- Login: astrogilda
- Kind: user
- Location: Gainesville, FL
- Website: www.linkedin.com/in/sankalp-gilda/
- Twitter: astrogilda
- Repositories: 141
- Profile: https://github.com/astrogilda
Machine Learning Engineer | Ph.D., Astronomy