https://github.com/athanasiospetsanis/diplomaclone
Diploma Thesis Code and temporary files needed for Colab notebooks
Science Score: 36.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
○.zenodo.json file
-
✓DOI references
Found 5 DOI reference(s) in README -
✓Academic publication links
Links to: arxiv.org, frontiersin.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (10.9%) to scientific vocabulary
Repository
Diploma Thesis Code and temporary files needed for Colab notebooks
Basic Info
Statistics
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
- Releases: 0
Metadata Files
README.md
General
This repository is cloned on Google's remote computer when the Main.ipynb file is run in GoogleColab. This way all prerequisites are installed remotely and anyone can easily run our code as long as you have a Google account. It is called "Diploma_Clone" because it is the work of my diploma thesis and its purpose is to get cloned.
Our method is described in the following paper: https://www.frontiersin.org/journals/robotics-and-ai/articles/10.3389/frobt.2023.1280578/full
Method Synopsis
In a synopsis, an agent is trained to execute a user-defined command in a simulation of a home environment. The simulator used is MiniGrid. Our novelty lies in using TextWorld as a high-level agent for decomposing the user-defined tasks into sub-tasks that contribute in faster convergence and better solving of the low-level MiniGrid agent. TextWorld is a text-based game, but can also be thought of and used as a conceptually more abstract simulator of home environments.
A simple diagram of this method is depicted below:
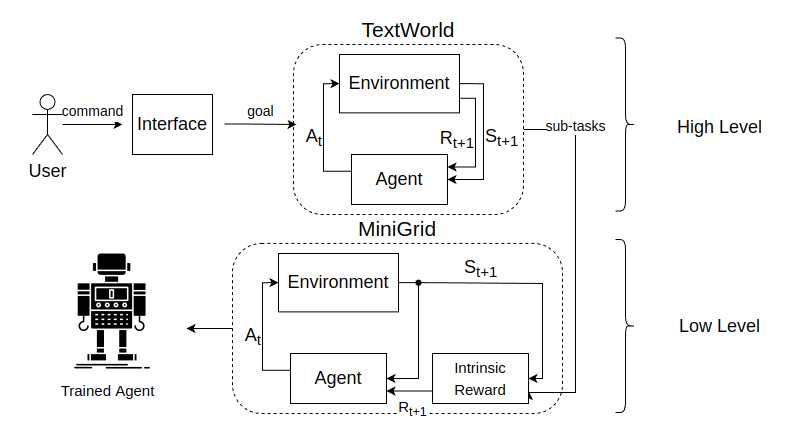
Agents
For MiniGrid, the algorithm used for training and the architecture of the agent are defined as recommended by the designers of MiniGrid, i.e. a PPO (Proximal Policy Optimization) algorithm and a neural network respectively. More details on these can be found in the designated repository: rl-torch
For TextWorld, we use a simple Q-learning algorithm and the architecture is a Q-matrix that saves a weight for every State-Action pair discovered during exploration. The code can be found here: Q-agent
Training
Training is done in preconstructed environments of increasing difficulty which we made. The user-defined command is always moving an apple and placing it on the table[^1] The environments are the following[^2]:
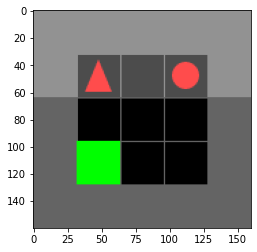
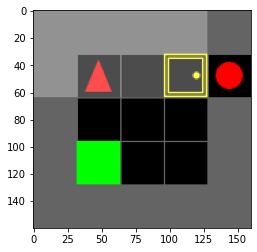
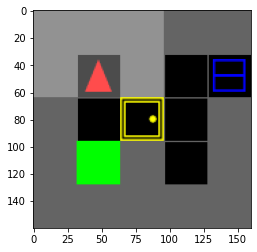
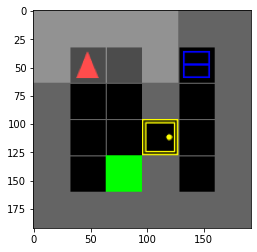
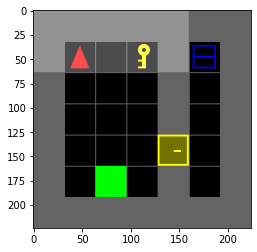
Results
TextWorld successfully decomposes the user-defined task into an optimal (i.e. shortest) sequence of sub-tasks and the comparison of average return between our method (using TextWolrd) and without it (without using TextWorld) shows increasing efficacy as the difficulty increases.
The graphs for the corresponding environments can be found in the Results folder of this repository.
Future Work
The results are encouraging, but there is still a long way to go for a practical implementation on a robotic home assistant. Firstly, we aim to generalize the learning more and broaden the possible commands as well as environments. Secondly, we want to find a more realistic low level simulator that will also include manipulation tasks (i.e. robotic-arm movements). Ultimately, we hope our method in tangem with state-of-the-art existing research will produce a more reliable and smart robotic home assistant.
Cite as:
Petsanis, T., Keroglou, C., Kapoutsis, A. C., Kosmatopoulos E. B., & Sirakoulis G. Ch. (2023). Decomposing user-defined tasks in a reinforcement learning setup using TextWorld. [Link]
```bibtex @ARTICLE{10.3389/frobt.2023.1280578,
AUTHOR={Petsanis, Thanos and Keroglou, Christoforos and Ch. Kapoutsis, Athanasios and Kosmatopoulos, Elias B. and Sirakoulis, Georgios Ch. },
TITLE={Decomposing user-defined tasks in a reinforcement learning setup using TextWorld},
JOURNAL={Frontiers in Robotics and AI},
VOLUME={10},
YEAR={2023},
URL={https://www.frontiersin.org/journals/robotics-and-ai/articles/10.3389/frobt.2023.1280578},
DOI={10.3389/frobt.2023.1280578},
ISSN={2296-9144},
ABSTRACT={
The current paper proposes a hierarchical reinforcement learning (HRL) method to decompose a complex task into simpler sub-tasks and leverage those to improve the training of an autonomous agent in a simulated environment. For practical reasons (i.e., illustrating purposes, easy implementation, user-friendly interface, and useful functionalities), we employ two Python frameworks called TextWorld and MiniGrid. MiniGrid functions as a 2D simulated representation of the real environment, while TextWorld functions as a high-level abstraction of this simulated environment. Training on this abstraction disentangles manipulation from navigation actions and allows us to design a dense reward function instead of a sparse reward function for the lower-level environment, which, as we show, improves the performance of training. Formal methods are utilized throughout the paper to establish that our algorithm is not prevented from deriving solutions.
}} }```
[^1]: It's always the same command because it helps with better comparison of the results as the diffuctly increases, but it can easily be changed. [^2]: The ones are show here are the MiniGrid environments. The ones in TextWorld are a bit different.
Owner
- Name: Athanasios Petsanis
- Login: AthanasiosPetsanis
- Kind: user
- Repositories: 2
- Profile: https://github.com/AthanasiosPetsanis
GitHub Events
Total
- Push event: 1
Last Year
- Push event: 1