DBMS-Benchmarker
DBMS-Benchmarker: Benchmark and Evaluate DBMS in Python - Published in JOSS (2022)
Science Score: 95.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
✓DOI references
Found 13 DOI reference(s) in README and JOSS metadata -
✓Academic publication links
Links to: joss.theoj.org, zenodo.org -
✓Committers with academic emails
1 of 5 committers (20.0%) from academic institutions -
○Institutional organization owner
-
✓JOSS paper metadata
Published in Journal of Open Source Software
Keywords
Keywords from Contributors
Scientific Fields
Repository
DBMS-Benchmarker is a Python-based application-level blackbox benchmark tool for Database Management Systems (DBMS). It connects to a given list of DBMS (via JDBC) and runs a given list of parametrized and randomized (SQL) benchmark queries. Evaluations are available via a Python interface and on an interactive multi-dimensional dashboard.
Basic Info
Statistics
- Stars: 14
- Watchers: 3
- Forks: 3
- Open Issues: 14
- Releases: 59
Topics
Metadata Files
README.md
![]()

![]()
![]()

![]()
DBMS-Benchmarker
DBMS-Benchmarker is a Python-based application-level blackbox benchmark tool for Database Management Systems (DBMS). It aims at reproducible measuring and easy evaluation of the performance the user receives even in complex benchmark situations. It connects to a given list of DBMS (via JDBC) and runs a given list of (SQL) benchmark queries. Queries can be parametrized and randomized. Results and evaluations are available via a Python interface and can be inspected with standard Python tools like pandas DataFrames. An interactive visual dashboard assists in multi-dimensional analysis of the results.
See the homepage and the documentation.
If you encounter any issues, please report them to our Github issue tracker.
Key Features
DBMS-Benchmarker
- is Python3-based
- helps to benchmark DBMS
- connects to all DBMS having a JDBC interface - including GPU-enhanced DBMS
- requires only JDBC - no vendor specific supplements are used
- benchmarks arbitrary SQL queries - in all dialects
- allows planning of complex test scenarios - to simulate realistic or revealing use cases
- allows easy repetition of benchmarks in varying settings - different hardware, DBMS, DBMS configurations, DB settings etc
- investigates a number of timing aspects - connection, execution, data transfer, in total, per session etc
- investigates a number of other aspects - received result sets, precision, number of clients
- collects hardware metrics from a Prometheus server - hardware utilization, energy consumption etc
- helps to evaluate results - by providing
- metrics that can be analyzed by aggregation in multi-dimensions, like maximum throughput per DBMS, average CPU utilization per query or geometric mean of run latency per workload
- predefined evaluations like statistics
- in standard Python data structures
- in Jupyter notebooks
see rendered example
- in an interactive dashboard
For more informations, see a basic example or take a look in the documentation for a full list of options.
The code uses several Python modules, in particular jaydebeapi for handling DBMS. This module has been tested with Citus Data (Hyperscale), Clickhouse, CockroachDB, Exasol, IBM DB2, MariaDB, MariaDB Columnstore, MemSQL (SingleStore), MonetDB, MySQL, OmniSci (HEAVY.AI), Oracle DB, PostgreSQL, SQL Server, SAP HANA, TimescaleDB, and Vertica.
Installation
Run pip install dbmsbenchmarker to install the package.
You will also need to have
* Java installed (we tested with Java 8)
* JAVA_HOME set correctly
* a JDBC driver suitable for the DBMS you want to connect to (optionally located in your CLASSPATH)
Basic Usage
The following very simple use case runs the query SELECT COUNT(*) FROM test 10 times against one local MySQL installation.
As a result we obtain an interactive dashboard to inspect timing aspects.
Configuration
We need to provide
- a DBMS configuration file, e.g. in
./config/connections.config
[ { 'name': "MySQL", 'active': True, 'JDBC': { 'driver': "com.mysql.cj.jdbc.Driver", 'url': "jdbc:mysql://localhost:3306/database", 'auth': ["username", "password"], 'jar': "mysql-connector-java-8.0.13.jar" } } ] - the required JDBC driver, e.g.
mysql-connector-java-8.0.13.jar - a Queries configuration file, e.g. in
./config/queries.config
{ 'name': 'Some simple queries', 'connectionmanagement': { 'timeout': 5 # in seconds }, 'queries': [ { 'title': "Count all rows in test", 'query': "SELECT COUNT(*) FROM test", 'numRun': 10 } ] }
Perform Benchmark
Run the CLI command: dbmsbenchmarker run -e yes -b -f ./config
-e yes: This will precompile some evaluations and generate the timer cube.-b: This will suppress some output-f: This points to a folder having the configuration files.
This is equivalent to python benchmark.py run -e yes -b -f ./config
After benchmarking has been finished we will see a message like
Experiment <code> has been finished
The script has created a result folder in the current directory containing the results. code is the name of the folder.
Evaluate Results in Dashboard
Run the command: dbmsdashboard
This will start the evaluation dashboard at localhost:8050.
Visit the address in a browser and select the experiment code.
Alternatively you may use a Jupyter notebook, see a rendered example.
Limitations
Limitations are: * strict black box perspective - may not use all tricks available for a DBMS * strict JDBC perspective - depends on a JVM and provided drivers * strict user perspective - client system, network connection and other host workloads may affect performance * not officially applicable for well known benchmark standards - partially, but not fully complying with TPC-H and TPC-DS * hardware metrics are collected from a monitoring system - not as precise as profiling * no GUI for configuration * strictly Python - a very good and widely used language, but maybe not your choice
Other comparable products you might like * Apache JMeter - Java-based performance measure tool, including a configuration GUI and reporting to HTML * HammerDB - industry accepted benchmark tool based on Tcl, but limited to some DBMS * Sysbench - a scriptable multi-threaded benchmark tool based on LuaJIT * OLTPBench - Java-based performance measure tool, using JDBC and including a lot of predefined benchmarks * BenchBase - successor of OLTPBench
Contributing, Bug Reports
If you have any question or found a bug, please report them to our Github issue tracker. In any bug report, please let us know:
- Which operating system and hardware (32 bit or 64 bit) you are using
- Python version
- DBMSBenchmarker version (or git commit/date)
- DBMS you are connecting to
- Traceback that occurs (the full error message)
We are always looking for people interested in helping with code development, documentation writing, technical administration, and whatever else comes up. If you wish to contribute, please first read the contribution section or visit the documentation.
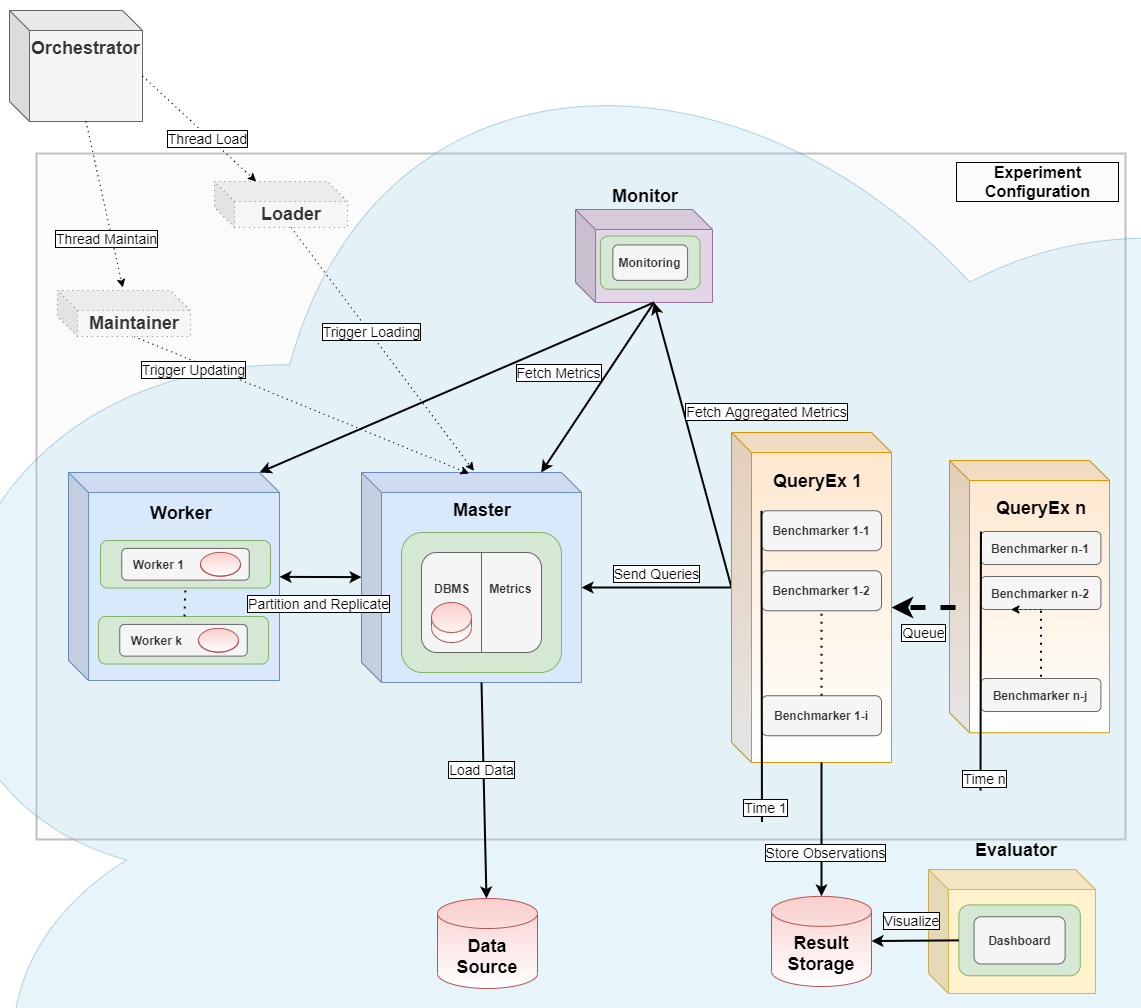
Benchmarking in a Kubernetes Cloud
This module can serve as the query executor [2] and evaluator [1] for distributed parallel benchmarking experiments in a Kubernetes Cloud, see the orchestrator for more details.
References
If you use DBMSBenchmarker in work contributing to a scientific publication, we kindly ask that you cite our application note [1] and/or [3]:
Erdelt P.K. (2021) A Framework for Supporting Repetition and Evaluation in the Process of Cloud-Based DBMS Performance Benchmarking. In: Nambiar R., Poess M. (eds) Performance Evaluation and Benchmarking. TPCTC 2020. Lecture Notes in Computer Science, vol 12752. Springer, Cham. https://doi.org/10.1007/978-3-030-84924-5_6
[2] Orchestrating DBMS Benchmarking in the Cloud with Kubernetes
Erdelt P.K. (2022) Orchestrating DBMS Benchmarking in the Cloud with Kubernetes. In: Nambiar R., Poess M. (eds) Performance Evaluation and Benchmarking. TPCTC 2021. Lecture Notes in Computer Science, vol 13169. Springer, Cham. https://doi.org/10.1007/978-3-030-94437-7_6
[3] DBMS-Benchmarker: Benchmark and Evaluate DBMS in Python
Erdelt P.K., Jestel J. (2022). DBMS-Benchmarker: Benchmark and Evaluate DBMS in Python. Journal of Open Source Software, 7(79), 4628 https://doi.org/10.21105/joss.04628
Owner
- Name: Berliner Hochschule für Technik (BHT)
- Login: Beuth-Erdelt
- Kind: organization
- Email: patrick.erdelt@bht-berlin.de
- Location: Germany
- Website: https://prof.bht-berlin.de/erdelt/
- Repositories: 2
- Profile: https://github.com/Beuth-Erdelt
Berliner Hochschule für Technik (BHT)
JOSS Publication
DBMS-Benchmarker: Benchmark and Evaluate DBMS in Python
Authors

Berliner Hochschule für Technik (BHT)
Berliner Hochschule für Technik (BHT)
Editor
George K. Thiruvathukal
Tags
DBMS JDBCGitHub Events
Total
- Create event: 19
- Issues event: 2
- Release event: 6
- Watch event: 2
- Delete event: 7
- Push event: 59
- Pull request event: 31
- Fork event: 1
Last Year
- Create event: 19
- Issues event: 2
- Release event: 6
- Watch event: 2
- Delete event: 7
- Push event: 59
- Pull request event: 31
- Fork event: 1
Committers
Last synced: 11 months ago
Top Committers
| Name | Commits | |
|---|---|---|
| Patrick Erdelt | p****t@b****e | 504 |
| snyk-bot | s****t@s****o | 4 |
| dependabot[bot] | 4****] | 2 |
| JJestel | 6****l | 1 |
| Daniel S. Katz | d****z@i****g | 1 |
Committer Domains (Top 20 + Academic)
Issues and Pull Requests
Last synced: 10 months ago
All Time
- Total issues: 67
- Total pull requests: 147
- Average time to close issues: 10 months
- Average time to close pull requests: 10 days
- Total issue authors: 6
- Total pull request authors: 4
- Average comments per issue: 1.28
- Average comments per pull request: 0.09
- Merged pull requests: 108
- Bot issues: 0
- Bot pull requests: 8
Past Year
- Issues: 1
- Pull requests: 37
- Average time to close issues: 3 days
- Average time to close pull requests: 14 days
- Issue authors: 1
- Pull request authors: 1
- Average comments per issue: 0.0
- Average comments per pull request: 0.0
- Merged pull requests: 17
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
- perdelt (55)
- simon-lewis (4)
- deenar (3)
- erik-whiting (2)
- PenguinRage (2)
- AmosG (1)
Pull Request Authors
- perdelt (137)
- dependabot[bot] (8)
- JJestel (1)
- danielskatz (1)
Top Labels
Issue Labels
Pull Request Labels
Packages
- Total packages: 1
-
Total downloads:
- pypi 170 last-month
- Total docker downloads: 165
- Total dependent packages: 1
- Total dependent repositories: 1
- Total versions: 36
- Total maintainers: 1
pypi.org: dbmsbenchmarker
DBMS-Benchmarker is a Python-based application-level blackbox benchmark tool for Database Management Systems (DBMS). It connects to a given list of DBMS (via JDBC) and runs a given list of parametrized and randomized (SQL) benchmark queries. Evaluations are available via Python interface, in reports and at an interactive multi-dimensional dashboard.
- Homepage: https://github.com/Beuth-Erdelt/DBMS-Benchmarker
- Documentation: https://dbmsbenchmarker.readthedocs.io/
- License: GNU Affero General Public License v3
-
Latest release: 0.14.12
published 10 months ago
Rankings
Maintainers (1)
Dependencies
- Brotli >=1.0.7
- Flask >=1.1.2
- Flask-Caching >=1.9.0
- Flask-Compress >=1.5.0
- JPype1 >=1.2.0
- JayDeBeApi >=1.1.1
- Jinja2 ==2.11.3
- MarkupSafe >=1.1.1
- Werkzeug >=1.0.1
- certifi >=2020.4.5.2
- chardet >=3.0.4
- click >=6.7
- colour >=0.1.5
- cycler >=0.10.0
- dash ==2.3.0
- dash-auth ==1.4.1
- dash-core-components ==2.0.0
- dash-daq ==0.5.0
- dash-html-components ==2.0.0
- dash-renderer ==1.4.1
- dash-table ==5.0.0
- future >=0.18.2
- idna >=2.9
- itsdangerous >=1.1.0
- kiwisolver >=1.2.0
- m2r2 *
- markupsafe ==2.0.1
- matplotlib >=3.1.1
- myst_parser *
- numpy >=1.14.1
- pandas >=0.25.1
- plotly >=4.8.1
- pyparsing >=2.4.7
- python-dateutil >=2.8.1
- pytz >=2020.1
- requests >=2.22.0
- retrying >=1.3.3
- scipy >=1.4.1
- six >=1.14.0
- tabulate >=0.8.2
- tqdm >=4.28.1
- urllib3 ==1.26.5
- uuid >=1.30
- actions/checkout v2 composite
- actions/upload-artifact v1 composite
- openjournals/openjournals-draft-action master composite
- actions/checkout master composite
- actions/setup-python v1 composite
- pypa/gh-action-pypi-publish master composite