https://github.com/bigcode-project/selfcodealign
[NeurIPS'24] SelfCodeAlign: Self-Alignment for Code Generation
Science Score: 13.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
○.zenodo.json file
-
○DOI references
-
○Academic publication links
-
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (8.6%) to scientific vocabulary
Keywords
Repository
[NeurIPS'24] SelfCodeAlign: Self-Alignment for Code Generation
Basic Info
- Host: GitHub
- Owner: bigcode-project
- License: apache-2.0
- Language: Python
- Default Branch: main
- Homepage: https://arxiv.org/abs/2410.24198
- Size: 251 KB
Statistics
- Stars: 295
- Watchers: 6
- Forks: 21
- Open Issues: 3
- Releases: 0
Topics
Metadata Files
README-SC2INST.md
StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation
⭐️ About | 🚀 Quick start | 📚 Data generation | 🧑💻 Training | 📊 Evaluation | ⚠️ Limitations

About
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- Model: bigcode/starcoder2-15b-instruct-v0.1
- Code: bigcode-project/starcoder2-self-align
- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k
- Authors: Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Harm de Vries, Leandro von Werra, Arjun Guha, Lingming Zhang.

Quick start
Here is an example to get started with StarCoder2-15B-Instruct-v0.1 using the transformers library:
```python import transformers import torch
pipeline = transformers.pipeline( model="bigcode/starcoder2-15b-instruct-v0.1", task="text-generation", torchdtype=torch.bfloat16, devicemap="auto", )
def respond(instruction: str, responseprefix: str) -> str: messages = [{"role": "user", "content": instruction}] prompt = pipeline.tokenizer.applychattemplate(messages, tokenize=False) prompt += responseprefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'lessthan' parameter for custom sorting criteria." responseprefix = ""
print(respond(instruction, response_prefix)) ```
Data generation pipeline
Run
pip install -e .first to install the package locally. Check seed_gathering for details on how we collected the seeds.
By default, we use in-memory vLLM engine for data generation, but we also provide an option to use vLLM's OpenAI compatible server for data generation.
Set CUDA_VISIBLE_DEVICES=... to specify the GPU devices to use for the vLLM engine.
To maximize data generation efficiency, we recommend invoking the script multiple times with different seed_code_start_index and max_new_data values, each with an vLLM engine running on a separate GPU set. For example, for a 100k seed dataset on a 2-GPU machine, you can have 2 processes each generating 50k samples by setting CUDA_VISIBLE_DEVICES=0 --seed_code_start_index 0 --max_new_data 50000 and CUDA_VISIBLE_DEVICES=1 --seed_code_start_index 50000 --max_new_data 50000.
Click to see how to run with vLLM's OpenAI compatible API
To do so, make sure the vLLM server is running, and the associated `openai` environment variables are set. For example, you can start an vLLM server with `docker`: ```shell docker run --gpus '"device=0"' \ -v $HF_HOME:/root/.cache/huggingface \ -p 10000:8000 \ --ipc=host \ vllm/vllm-openai:v0.3.3 \ --model bigcode/starcoder2-15b \ --tensor-parallel-size 1 --dtype bfloat16 ``` And then set the environment variables as follows: ```shell export OPENAI_API_KEY="EMPTY" export OPENAI_BASE_URL="http://localhost:10000/v1/" ``` You will also need to set `--use_vllm_server True` in the following commands.Snippet to concepts generation
```shell MODEL=bigcode/starcoder2-15b MAX_NEW_DATA=1000000 python src/star_align/self_ossinstruct.py \ --use_vllm_server False \ --instruct_mode "S->C" \ --seed_data_files /path/to/seeds.jsonl \ --max_new_data $MAX_NEW_DATA \ --tag concept_gen \ --temperature 0.7 \ --seed_code_start_index 0 \ --model $MODEL \ --num_fewshots 8 \ --num_batched_requests 2000 \ --num_sample_per_request 1 ```Concepts to instruction generation
```shell MODEL=bigcode/starcoder2-15b MAX_NEW_DATA=1000000 python src/star_align/self_ossinstruct.py \ --instruct_mode "C->I" \ --seed_data_files /path/to/concepts.jsonl \ --max_new_data $MAX_NEW_DATA \ --tag instruction_gen \ --temperature 0.7 \ --seed_code_start_index 0 \ --model $MODEL \ --num_fewshots 8 \ --num_sample_per_request 1 \ --num_batched_request 2000 ```Instruction to response (with self-validation code) generation
```shell MODEL=bigcode/starcoder2-15b MAX_NEW_DATA=1000000 python src/star_align/self_ossinstruct.py \ --instruct_mode "I->R" \ --seed_data_files path/to/instructions.jsonl \ --max_new_data $MAX_NEW_DATA \ --tag response_gen \ --seed_code_start_index 0 \ --model $MODEL \ --num_fewshots 1 \ --num_batched_request 500 \ --num_sample_per_request 10 \ --temperature 0.7 ```Execution filter
> **Warning:** Though we implemented reliability guards, it is highly recommended to run execution in a sandbox environment we provided. To use the Docker container for executing code, you will first need to `git submodule update --init --recursive` to clone the server, then run: ```shell pushd ./src/star_align/code_exec_server ./pull_and_run.sh popd python src/star_align/execution_filter.py \ --response_paths /path/to/response.jsonl \ --result_path /path/to/filtered.jsonl \ --max_batched_tasks 10000 \ --container_server http://127.0.0.1:8000 ``` Execution filter will produce a flattened list of JSONL entries with a `pass` field indicating whether the execution passed or not. **It also incrementally dumps the results and can load a cached partial data file.** You can recover an execution with: ```shell python src/star_align/execution_filter.py \ --response_paths /path/to/response.jsonl* \ --cache_paths /path/to/filtered.jsonl* \ --result_path /path/to/filtered-1.jsonl \ --max_batched_tasks 10000 \ --container_server http://127.0.0.1:8000 ``` Note that sometimes execution can lead to significant slowdowns due to excessive resource consumption. To alleviate this, you can limit the docker's cpu usage (e.g., `docker run --cpuset-cpus="0-31"`). You can also do: ```shell # For example, you can set the command to be `sudo pkill -f '/tmp/codeexec'` export CLEANUP_COMMAND="the command to execute after each batch" python src/star_align/execution_filter.py... ``` Also, the container connection may be lost during execution. In this case, you can just leverage the caching mechanism described above to re-run the script.Data sanitization and selection
```shell # Uncomment to do decontamination # export MBPP_PATH="/path/to/mbpp.jsonl" # export DS1000_PATH="/path/to/ds1000_data" # export DECONTAMINATION=1 ./sanitize.sh /path/to/exec-filtered.jsonl /path/to/sanitized.jsonl ```Training Details
Run
pip install -e .first to install the package locally. And install Flash Attention to speed up the training.
Hyperparameters
- Optimizer: Adafactor
- Learning rate: 1e-5
- Epoch: 4
- Batch size: 64
- Warmup ratio: 0.05
- Scheduler: Linear
- Sequence length: 1280
- Dropout: Not applied
Hardware
1 x NVIDIA A100 80GB. Yes, you just need one A100 to finetune StarCoder2-15B!
Script
The following script finetunes StarCoder2-15B-Instruct-v0.1 from the base StarCoder2-15B model. /path/to/dataset.jsonl is the JSONL format of the 50k dataset we generated. You can dump the dataset to JSONL to fit the training script.
Click to see the training script
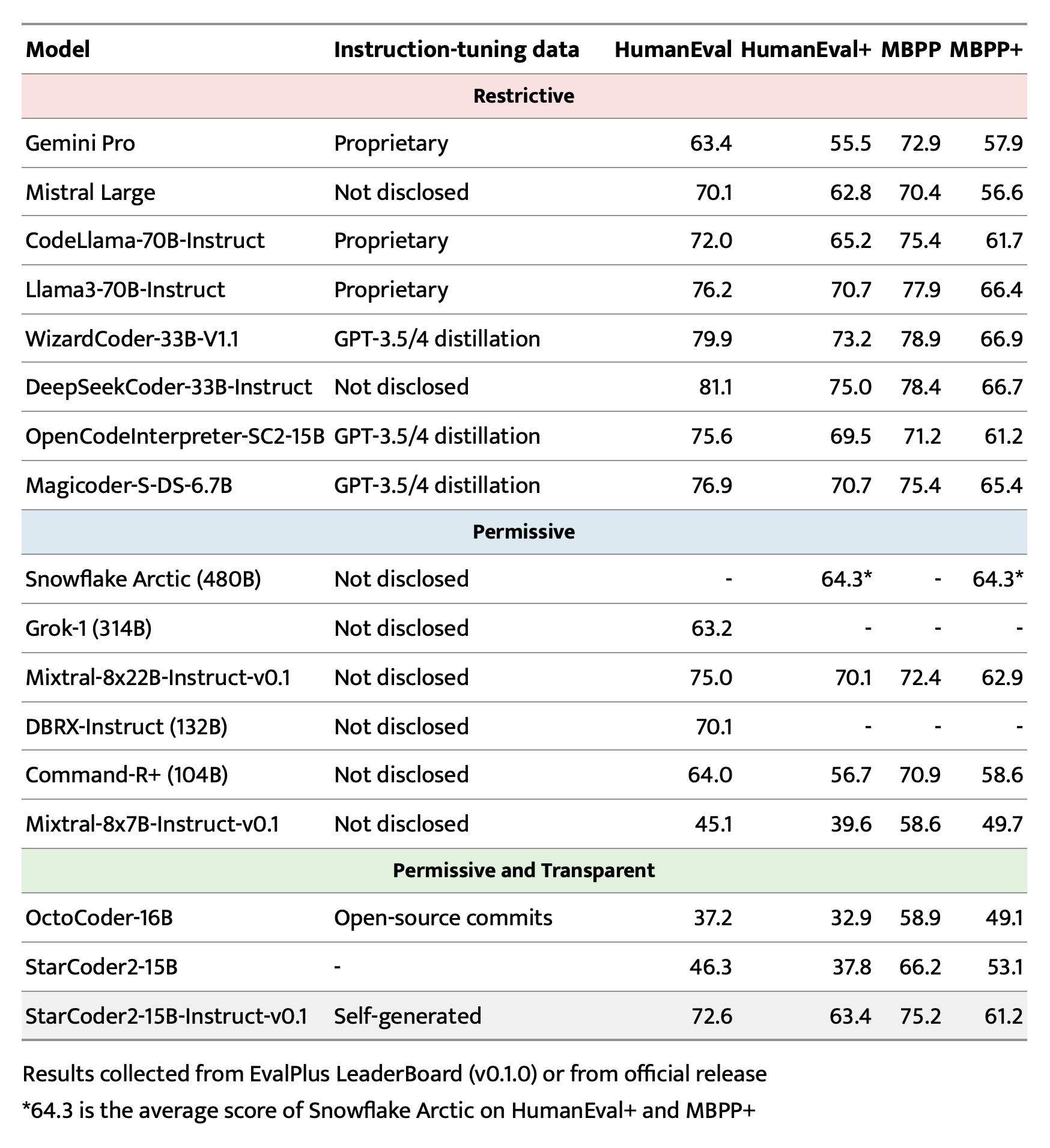
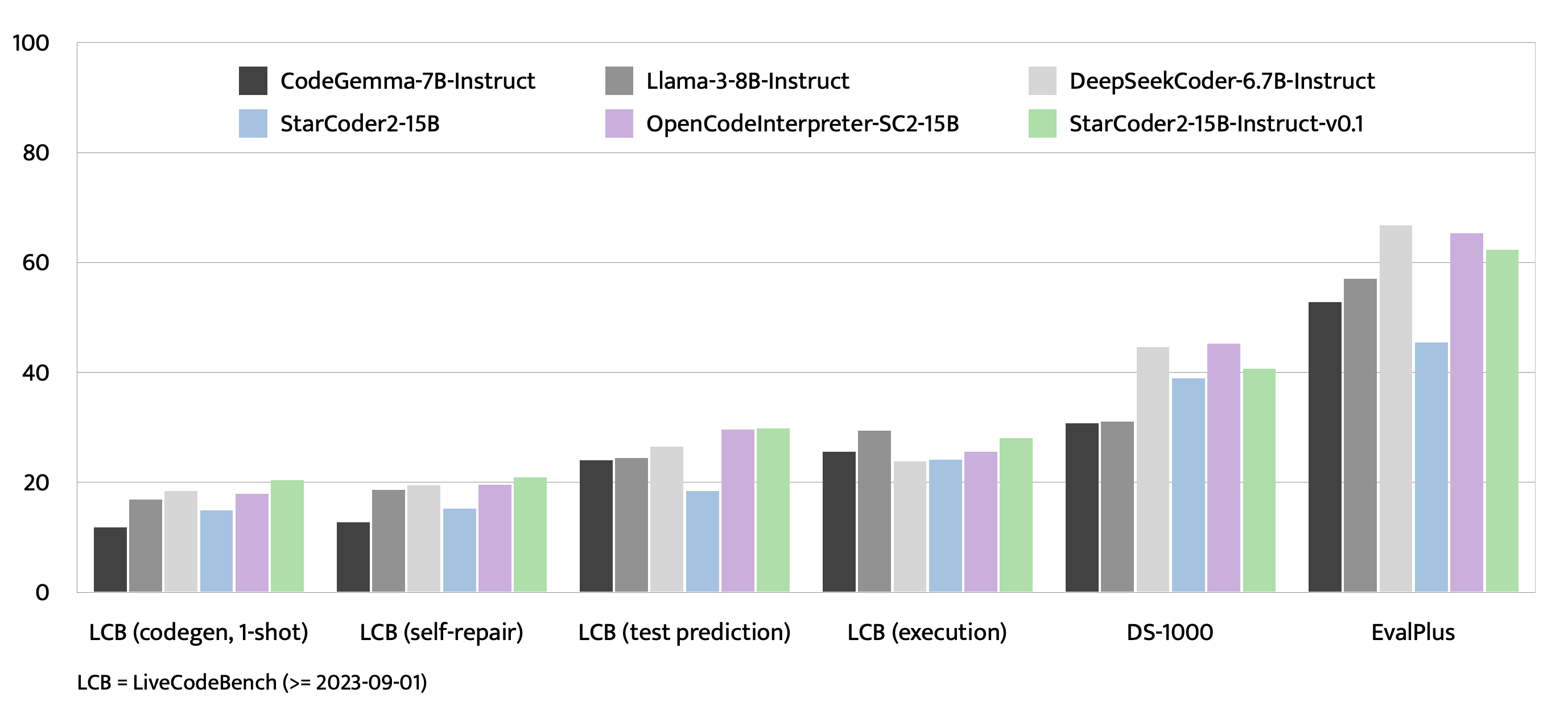
NOTE: StarCoder2-15B sets dropout values to 0.1 by default. We did not apply dropout in finetuning and thus set the them to 0.0. ```shell MODEL_KEY=bigcode/starcoder2-15b LR=1e-5 EPOCH=4 SEQ_LEN=1280 WARMUP_RATIO=0.05 OUTPUT_DIR=/path/to/output_model DATASET_FILE=/path/to/50k-dataset.jsonl accelerate launch -m star_align.train \ --model_key $MODEL_KEY \ --model_name_or_path $MODEL_KEY \ --use_flash_attention True \ --datafile_paths $DATASET_FILE \ --output_dir $OUTPUT_DIR \ --bf16 True \ --num_train_epochs $EPOCH \ --max_training_seq_length $SEQ_LEN \ --pad_to_max_length False \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 64 \ --group_by_length False \ --ddp_find_unused_parameters False \ --logging_steps 1 \ --log_level info \ --optim adafactor \ --max_grad_norm -1 \ --warmup_ratio $WARMUP_RATIO \ --learning_rate $LR \ --lr_scheduler_type linear \ --attention_dropout 0.0 \ --residual_dropout 0.0 \ --embedding_dropout 0.0 ```Evaluation on EvalPlus, LiveCodeBench, and DS-1000
Check evaluation for more details.
Bias, Risks, and Limitations
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a response prefix or a one-shot example to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the StarCoder2-15B model card.
Owner
- Name: BigCode Project
- Login: bigcode-project
- Kind: organization
- Email: contact@bigcode-project.org
- Website: https://www.bigcode-project.org/
- Twitter: BigCodeProject
- Repositories: 26
- Profile: https://github.com/bigcode-project
BigCode Project is an open scientific collaboration run by Hugging Face and ServiceNow Research, focused on open and responsible development of LLMs for code.
GitHub Events
Total
- Issues event: 6
- Watch event: 80
- Issue comment event: 4
- Push event: 4
- Pull request event: 1
- Fork event: 8
- Create event: 2
Last Year
- Issues event: 6
- Watch event: 80
- Issue comment event: 4
- Push event: 4
- Pull request event: 1
- Fork event: 8
- Create event: 2