https://github.com/chapzq77/tensorflow-cookbook
Simple Tensorflow Cookbook for easy-to-use
Science Score: 10.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
○codemeta.json file
-
○.zenodo.json file
-
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (8.9%) to scientific vocabulary
Last synced: 6 months ago
·
JSON representation
Repository
Simple Tensorflow Cookbook for easy-to-use
Basic Info
- Host: GitHub
- Owner: chapzq77
- License: mit
- Language: Python
- Default Branch: master
- Size: 553 KB
Statistics
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
- Releases: 0
Fork of taki0112/Tensorflow-Cookbook
Created about 7 years ago
· Last pushed about 7 years ago
https://github.com/chapzq77/Tensorflow-Cookbook/blob/master/
# [Web page](http://bit.ly/jhkim_tf_cookbook) ## Contributions In now, this repo contains general architectures and functions that are useful for the GAN. I will continue to add useful things to other areas. Also, your pull requests and issues are always welcome. And write what you want to implement on the issue. I'll implement it. # How to use ## Import * `ops.py` * operations * from ops import * * `utils.py` * image processing * from utils import * ## Network template ```python def network(x, is_training=True, reuse=False, scope="network"): with tf.variable_scope(scope, reuse=reuse): x = conv(...) ... return logit ``` ## Insert data to network using DatasetAPI ```python Image_Data_Class = ImageData(img_size, img_ch, augment_flag) trainA = trainA.map(Image_Data_Class.image_processing, num_parallel_calls=16) trainA = trainA.shuffle(buffer_size=10000).prefetch(buffer_size=batch_size).batch(batch_size).repeat() trainA_iterator = trainA.make_one_shot_iterator() data_A = trainA_iterator.get_next() logit = network(data_A) ``` * See [this](https://github.com/taki0112/Tensorflow-DatasetAPI) for more information. ## Option * `padding='SAME'` * pad = ceil[ (kernel - stride) / 2 ] * `pad_type` * 'zero' or 'reflect' * `sn` * use [spectral_normalization](https://arxiv.org/pdf/1802.05957.pdf) or not * `Ra` * use [relativistic gan](https://arxiv.org/pdf/1807.00734.pdf) or not * `loss_func` * gan * lsgan * hinge * wgan * wgan-gp * dragan ## Caution * If you don't want to share variable, **set all scope names differently.** --- ## Weight ```python weight_init = tf.truncated_normal_initializer(mean=0.0, stddev=0.02) weight_regularizer = tf.contrib.layers.l2_regularizer(0.0001) weight_regularizer_fully = tf.contrib.layers.l2_regularizer(0.0001) ``` ### Initialization * `Xavier` : tf.contrib.layers.xavier_initializer() * `He` : tf.contrib.layers.variance_scaling_initializer() * `Normal` : tf.random_normal_initializer(mean=0.0, stddev=0.02) * `Truncated_normal` : tf.truncated_normal_initializer(mean=0.0, stddev=0.02) * `Orthogonal` : tf.orthogonal_initializer(1.0) / # if relu = sqrt(2), the others = 1.0 ### Regularization * `l2_decay` : tf.contrib.layers.l2_regularizer(0.0001) * `orthogonal_regularizer` : orthogonal_regularizer(0.0001) & orthogonal_regularizer_fully(0.0001) ## Convolution ### basic conv ```python x = conv(x, channels=64, kernel=3, stride=2, pad=1, pad_type='reflect', use_bias=True, sn=True, scope='conv') ``` ### partial conv (NVIDIA [Partial Convolution](https://github.com/NVIDIA/partialconv)) ```python x = partial_conv(x, channels=64, kernel=3, stride=2, use_bias=True, padding='SAME', sn=True, scope='partial_conv') ```   ### dilated conv ```python x = dilate_conv(x, channels=64, kernel=3, rate=2, use_bias=True, padding='SAME', sn=True, scope='dilate_conv') ```
### partial conv (NVIDIA [Partial Convolution](https://github.com/NVIDIA/partialconv)) ```python x = partial_conv(x, channels=64, kernel=3, stride=2, use_bias=True, padding='SAME', sn=True, scope='partial_conv') ```   ### dilated conv ```python x = dilate_conv(x, channels=64, kernel=3, rate=2, use_bias=True, padding='SAME', sn=True, scope='dilate_conv') ``` --- ## Deconvolution ### basic deconv ```python x = deconv(x, channels=64, kernel=3, stride=2, padding='SAME', use_bias=True, sn=True, scope='deconv') ```
--- ## Deconvolution ### basic deconv ```python x = deconv(x, channels=64, kernel=3, stride=2, padding='SAME', use_bias=True, sn=True, scope='deconv') ``` --- ## Fully-connected ```python x = fully_conneted(x, units=64, use_bias=True, sn=True, scope='fully_connected') ``` --- ## Pixel shuffle ```python x = conv_pixel_shuffle_down(x, scale_factor=2, use_bias=True, sn=True, scope='pixel_shuffle_down') x = conv_pixel_shuffle_up(x, scale_factor=2, use_bias=True, sn=True, scope='pixel_shuffle_up') ``` * `down` ===> [height, width] -> [**height // scale_factor, width // scale_factor**] * `up` ===> [height, width] -> [**height \* scale_factor, width \* scale_factor**] --- ## Block ### residual block ```python x = resblock(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block') x = resblock_down(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block_down') x = resblock_up(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block_up') ``` * `down` ===> [height, width] -> [**height // 2, width // 2**] * `up` ===> [height, width] -> [**height \* 2, width \* 2**]
--- ## Fully-connected ```python x = fully_conneted(x, units=64, use_bias=True, sn=True, scope='fully_connected') ``` --- ## Pixel shuffle ```python x = conv_pixel_shuffle_down(x, scale_factor=2, use_bias=True, sn=True, scope='pixel_shuffle_down') x = conv_pixel_shuffle_up(x, scale_factor=2, use_bias=True, sn=True, scope='pixel_shuffle_up') ``` * `down` ===> [height, width] -> [**height // scale_factor, width // scale_factor**] * `up` ===> [height, width] -> [**height \* scale_factor, width \* scale_factor**] --- ## Block ### residual block ```python x = resblock(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block') x = resblock_down(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block_down') x = resblock_up(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block_up') ``` * `down` ===> [height, width] -> [**height // 2, width // 2**] * `up` ===> [height, width] -> [**height \* 2, width \* 2**] ### attention block ```python x = self_attention(x, channels=64, use_bias=True, sn=True, scope='self_attention') x = self_attention_with_pooling(x, channels=64, use_bias=True, sn=True, scope='self_attention_version_2') x = squeeze_excitation(x, channels=64, ratio=16, use_bias=True, sn=True, scope='squeeze_excitation') x = convolution_block_attention(x, channels=64, ratio=16, use_bias=True, sn=True, scope='convolution_block_attention') ```
### attention block ```python x = self_attention(x, channels=64, use_bias=True, sn=True, scope='self_attention') x = self_attention_with_pooling(x, channels=64, use_bias=True, sn=True, scope='self_attention_version_2') x = squeeze_excitation(x, channels=64, ratio=16, use_bias=True, sn=True, scope='squeeze_excitation') x = convolution_block_attention(x, channels=64, ratio=16, use_bias=True, sn=True, scope='convolution_block_attention') ```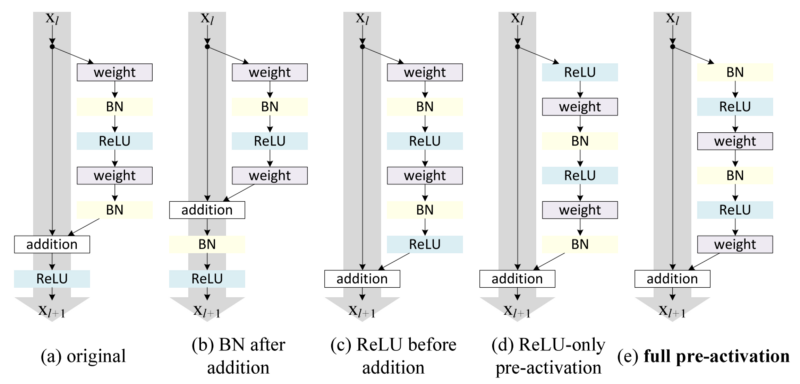 ---
--- ---
---
 --- ## Normalization ```python x = batch_norm(x, is_training=is_training, scope='batch_norm') x = instance_norm(x, scope='instance_norm') x = layer_norm(x, scope='layer_norm') x = group_norm(x, groups=32, scope='group_norm') x = pixel_norm(x) x = batch_instance_norm(x, scope='batch_instance_norm') x = condition_batch_norm(x, z, is_training=is_training, scope='condition_batch_norm'): x = adaptive_instance_norm(x, gamma, beta): ``` * See [this](https://github.com/taki0112/BigGAN-Tensorflow) for how to use `condition_batch_norm` * See [this](https://github.com/taki0112/MUNIT-Tensorflow) for how to use `adaptive_instance_norm`
--- ## Normalization ```python x = batch_norm(x, is_training=is_training, scope='batch_norm') x = instance_norm(x, scope='instance_norm') x = layer_norm(x, scope='layer_norm') x = group_norm(x, groups=32, scope='group_norm') x = pixel_norm(x) x = batch_instance_norm(x, scope='batch_instance_norm') x = condition_batch_norm(x, z, is_training=is_training, scope='condition_batch_norm'): x = adaptive_instance_norm(x, gamma, beta): ``` * See [this](https://github.com/taki0112/BigGAN-Tensorflow) for how to use `condition_batch_norm` * See [this](https://github.com/taki0112/MUNIT-Tensorflow) for how to use `adaptive_instance_norm`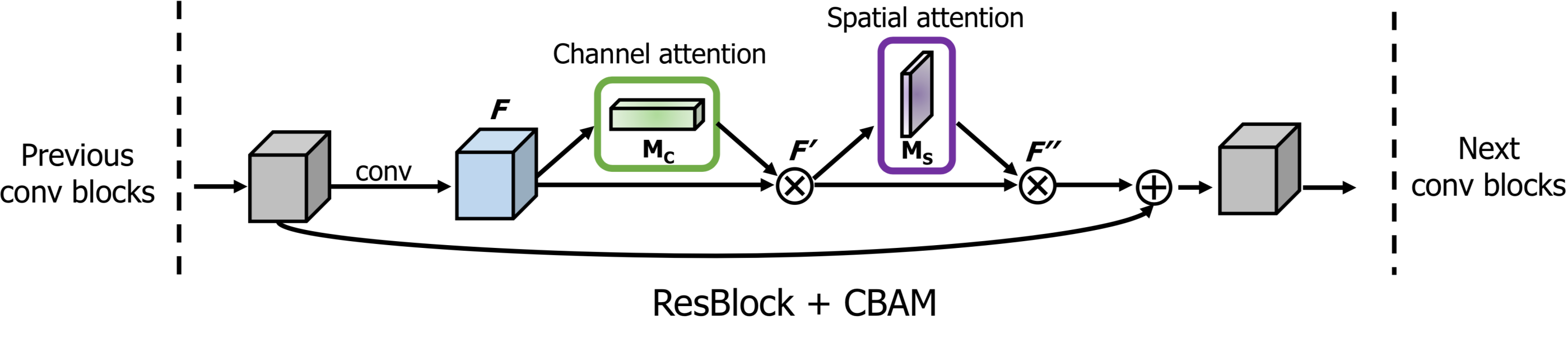
 --- ## Activation ```python x = relu(x) x = lrelu(x, alpha=0.2) x = tanh(x) x = sigmoid(x) x = swish(x) ``` --- ## Pooling & Resize ```python x = up_sample(x, scale_factor=2) x = max_pooling(x, pool_size=2) x = avg_pooling(x, pool_size=2) x = global_max_pooling(x) x = global_avg_pooling(x) x = flatten(x) x = hw_flatten(x) ``` --- ## Loss ### classification loss ```python loss, accuracy = classification_loss(logit, label) ``` ### pixel loss ```python loss = L1_loss(x, y) loss = L2_loss(x, y) loss = huber_loss(x, y) loss = histogram_loss(x, y) ``` * `histogram_loss` means the difference in the color distribution of the image pixel values. ### gan loss ```python d_loss = discriminator_loss(Ra=True, loss_func='wgan-gp', real=real_logit, fake=fake_logit) g_loss = generator_loss(Ra=True, loss_func='wgan_gp', real=real_logit, fake=fake_logit) ``` * See [this](https://github.com/taki0112/BigGAN-Tensorflow/blob/master/BigGAN_512.py#L180) for how to use `gradient_penalty` ### kl-divergence (z ~ N(0, 1)) ```python loss = kl_loss(mean, logvar) ``` --- ## Author Junho Kim
--- ## Activation ```python x = relu(x) x = lrelu(x, alpha=0.2) x = tanh(x) x = sigmoid(x) x = swish(x) ``` --- ## Pooling & Resize ```python x = up_sample(x, scale_factor=2) x = max_pooling(x, pool_size=2) x = avg_pooling(x, pool_size=2) x = global_max_pooling(x) x = global_avg_pooling(x) x = flatten(x) x = hw_flatten(x) ``` --- ## Loss ### classification loss ```python loss, accuracy = classification_loss(logit, label) ``` ### pixel loss ```python loss = L1_loss(x, y) loss = L2_loss(x, y) loss = huber_loss(x, y) loss = histogram_loss(x, y) ``` * `histogram_loss` means the difference in the color distribution of the image pixel values. ### gan loss ```python d_loss = discriminator_loss(Ra=True, loss_func='wgan-gp', real=real_logit, fake=fake_logit) g_loss = generator_loss(Ra=True, loss_func='wgan_gp', real=real_logit, fake=fake_logit) ``` * See [this](https://github.com/taki0112/BigGAN-Tensorflow/blob/master/BigGAN_512.py#L180) for how to use `gradient_penalty` ### kl-divergence (z ~ N(0, 1)) ```python loss = kl_loss(mean, logvar) ``` --- ## Author Junho Kim
Owner
- Name: 周奇
- Login: chapzq77
- Kind: user
- Repositories: 3
- Profile: https://github.com/chapzq77