pygrinder
PyGrinder: a Python toolkit for grinding data beans into the incomplete for real-world data simulation by introducing missing values with different missingness patterns, including MCAR (complete at random), MAR (at random), MNAR (not at random), sub sequence missing, and block missing
Science Score: 67.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
✓DOI references
Found 1 DOI reference(s) in README -
✓Academic publication links
Links to: arxiv.org, scholar.google -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (11.4%) to scientific vocabulary
Keywords
Repository
PyGrinder: a Python toolkit for grinding data beans into the incomplete for real-world data simulation by introducing missing values with different missingness patterns, including MCAR (complete at random), MAR (at random), MNAR (not at random), sub sequence missing, and block missing
Basic Info
- Host: GitHub
- Owner: WenjieDu
- License: bsd-3-clause
- Language: Python
- Default Branch: main
- Homepage: https://pypots.com/ecosystem/#PyGrinder
- Size: 175 KB
Statistics
- Stars: 58
- Watchers: 3
- Forks: 5
- Open Issues: 0
- Releases: 13
Topics
Metadata Files
README.md
![]()
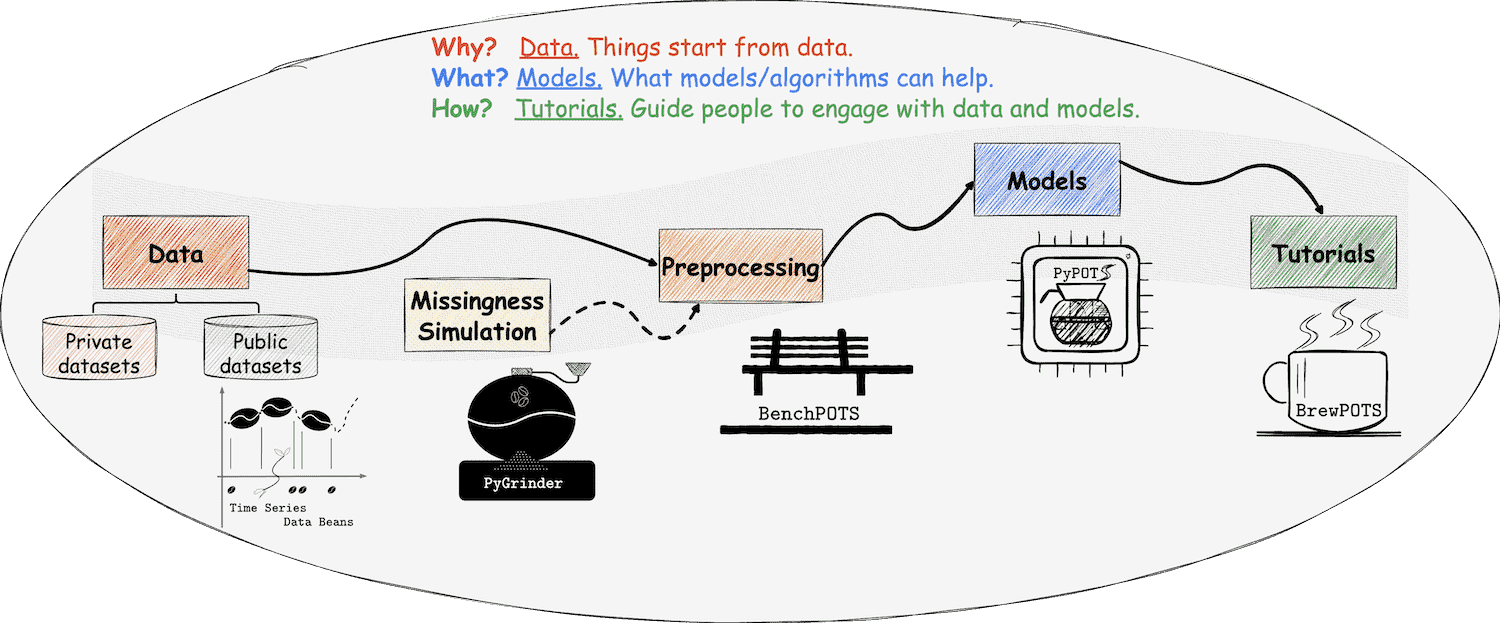
Welcome to PyGrinder
a Python toolkit for grinding data beans into the incomplete








![]() PyGrinder is a part of
PyPOTS
PyGrinder is a part of
PyPOTS 
In data analysis and modeling, sometimes we may need to corrupt the original data to achieve our goal, for instance, evaluating models' ability to reconstruct corrupted data or assessing the model's performance on only partially-observed data. PyGrinder is such a tool to help you corrupt your data, which provides several patterns to create missing values in the given data.
Usage Examples
PyGrinder now is available on
Install it with conda install pygrinder, you may need to specify the channel with option -c conda-forge
or install via PyPI:
pip install pygrinder
or install from source code:
pip install
https://github.com/WenjieDu/PyGrinder/archive/main.zip
```python import numpy as np
from pygrinder import ( mcar, marlogistic, mnarx, mnart, mnarnonuniform, rdo, seqmissing, blockmissing, calcmissingrate )
given a time-series dataset with 128 samples, each sample with 10 time steps and 36 data features
ts_dataset = np.random.randn(128, 10, 36)
grind the dataset with MCAR pattern, 10% missing probability, and using 0 to fill missing values
Xwithmcardata = mcar(tsdataset, p=0.1)
grind the dataset with MAR pattern
Xwithmardata = marlogistic(tsdataset[:, 0, :], obsrate=0.1, missing_rate=0.1)
grind the dataset with MNAR pattern
Xwithmnarxdata = mnarx(tsdataset, offset=0.1) Xwithmnartdata = mnart(tsdataset, cycle=20, pos=10, scale=3) Xwithmnarnonuniformdata = mnarnonuniform(tsdataset, p=0.5, increase_factor=0.5)
grind the dataset with RDO pattern
Xwithrdodata = rdo(tsdataset, p=0.1)
grind the dataset with Sequence-Missing pattern
Xwithseqmissingdata = seqmissing(tsdataset, p=0.1, seq_len=5)
grind the dataset with Block-Missing pattern
Xwithblockmissingdata = blockmissing(tsdataset, factor=0.1, blockwidth=3, blocklen=3)
calculate the missing rate of the dataset
missingrate = calcmissingrate(Xwithmcardata) ```
Citing PyGrinder/PyPOTS
The paper introducing PyPOTS is available on arXiv, A short version of it is accepted by the 9th SIGKDD international workshop on Mining and Learning from Time Series (MiLeTS'23)). Additionally, PyPOTS has been included as a PyTorch Ecosystem project. We are pursuing to publish it in prestigious academic venues, e.g. JMLR (track for Machine Learning Open Source Software). If you use PyPOTS in your work, please cite it as below and star this repository to make others notice this library.
There are scientific research projects using PyPOTS and referencing in their papers. Here is an incomplete list of them.
bibtex
@article{du2023pypots,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
author={Wenjie Du},
journal={arXiv preprint arXiv:2305.18811},
year={2023},
}
or
Wenjie Du. PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series. arXiv, abs/2305.18811, 2023.
Owner
- Name: Wenjie Du
- Login: WenjieDu
- Kind: user
- Location: where time series is observed & valued
- Company: @TimeSeries-AI
- Website: https://Time-Series.AI
- Repositories: 24
- Profile: https://github.com/WenjieDu
AI researcher on time series
Citation (CITATION.cff)
cff-version: 1.2.0
message: "If you use PyPOTS, please cite it as below."
authors:
- family-names: "Du"
given-names: "Wenjie"
orcid: "https://orcid.org/0000-0003-3046-7835"
title: "PyPOTS: A Python Toolbox for Data Mining on Partially-Observed Time Series"
preferred-citation:
type: article
authors:
- family-names: "Du"
given-names: "Wenjie"
orcid: "https://orcid.org/0000-0003-3046-7835"
doi: "10.48550/arXiv.2305.18811"
journal: "arXiv"
title: "PyPOTS: A Python Toolbox for Data Mining on Partially-Observed Time Series"
url: https://arxiv.org/abs/2305.18811
GitHub Events
Total
- Release event: 1
- Watch event: 23
- Delete event: 5
- Issue comment event: 9
- Push event: 13
- Pull request event: 20
- Fork event: 2
- Create event: 7
Last Year
- Release event: 1
- Watch event: 23
- Delete event: 5
- Issue comment event: 9
- Push event: 13
- Pull request event: 20
- Fork event: 2
- Create event: 7
Issues and Pull Requests
Last synced: 10 months ago
All Time
- Total issues: 0
- Total pull requests: 7
- Average time to close issues: N/A
- Average time to close pull requests: 3 days
- Total issue authors: 0
- Total pull request authors: 2
- Average comments per issue: 0
- Average comments per pull request: 0.86
- Merged pull requests: 7
- Bot issues: 0
- Bot pull requests: 5
Past Year
- Issues: 0
- Pull requests: 7
- Average time to close issues: N/A
- Average time to close pull requests: 3 days
- Issue authors: 0
- Pull request authors: 2
- Average comments per issue: 0
- Average comments per pull request: 0.86
- Merged pull requests: 7
- Bot issues: 0
- Bot pull requests: 5
Top Authors
Issue Authors
- WenjieDu (2)
- shaodaqian (1)
Pull Request Authors
- WenjieDu (16)
- dependabot[bot] (5)
- LinglongQian (2)
Top Labels
Issue Labels
Pull Request Labels
Packages
- Total packages: 1
-
Total downloads:
- pypi 88,662 last-month
- Total dependent packages: 1
- Total dependent repositories: 0
- Total versions: 12
- Total maintainers: 1
pypi.org: pygrinder
A Python toolkit for introducing missing values into datasets
- Homepage: https://pypots.com
- Documentation: https://docs.pypots.com
- License: Copyright (c) 2023-present, Wenjie Du All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. 3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
-
Latest release: 0.6.4
published almost 2 years ago
Rankings
Maintainers (1)
Dependencies
- numpy *
- pandas *
- scikit_learn *