gecko-syndata
Python library for the generation and mutation of realistic personal identification data at scale
Science Score: 44.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
○Academic publication links
-
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (14.4%) to scientific vocabulary
Keywords
Repository
Python library for the generation and mutation of realistic personal identification data at scale
Basic Info
- Host: GitHub
- Owner: ul-mds
- License: mit
- Language: Python
- Default Branch: main
- Homepage: https://ul-mds.github.io/gecko/
- Size: 5.51 MB
Statistics
- Stars: 6
- Watchers: 0
- Forks: 1
- Open Issues: 1
- Releases: 14
Topics
Metadata Files
README.md
Gecko is a Python library for the bulk generation and mutation of realistic personal data. It is a spiritual successor to the GeCo framework which was initially published by Tran, Vatsalan and Christen. Gecko reimplements the most promising aspects of the original framework for modern Python with a simplified API, adds extra features and massively improves performance thanks to NumPy and Pandas.
Installation
Install with pip:
bash
pip install gecko-syndata
Install with Poetry:
bash
poetry add gecko-syndata
Basic usage
Please see the docs for an in-depth guide on how to use the library.
Writing a data generation script with Gecko is usually split into two consecutive steps. In the first step, data is generated based on information that you provide. Most commonly, Gecko pulls the information it needs from frequency tables, although other means of generating data are possible. Gecko will then output a dataset to your specifications.
In the second step, a copy of this dataset is mutated. Gecko provides functions which deliberately introduce errors into your dataset. These errors can take shape in typos, edit errors and other common data sources. By the end, you will have a generated dataset and a mutated copy thereof.
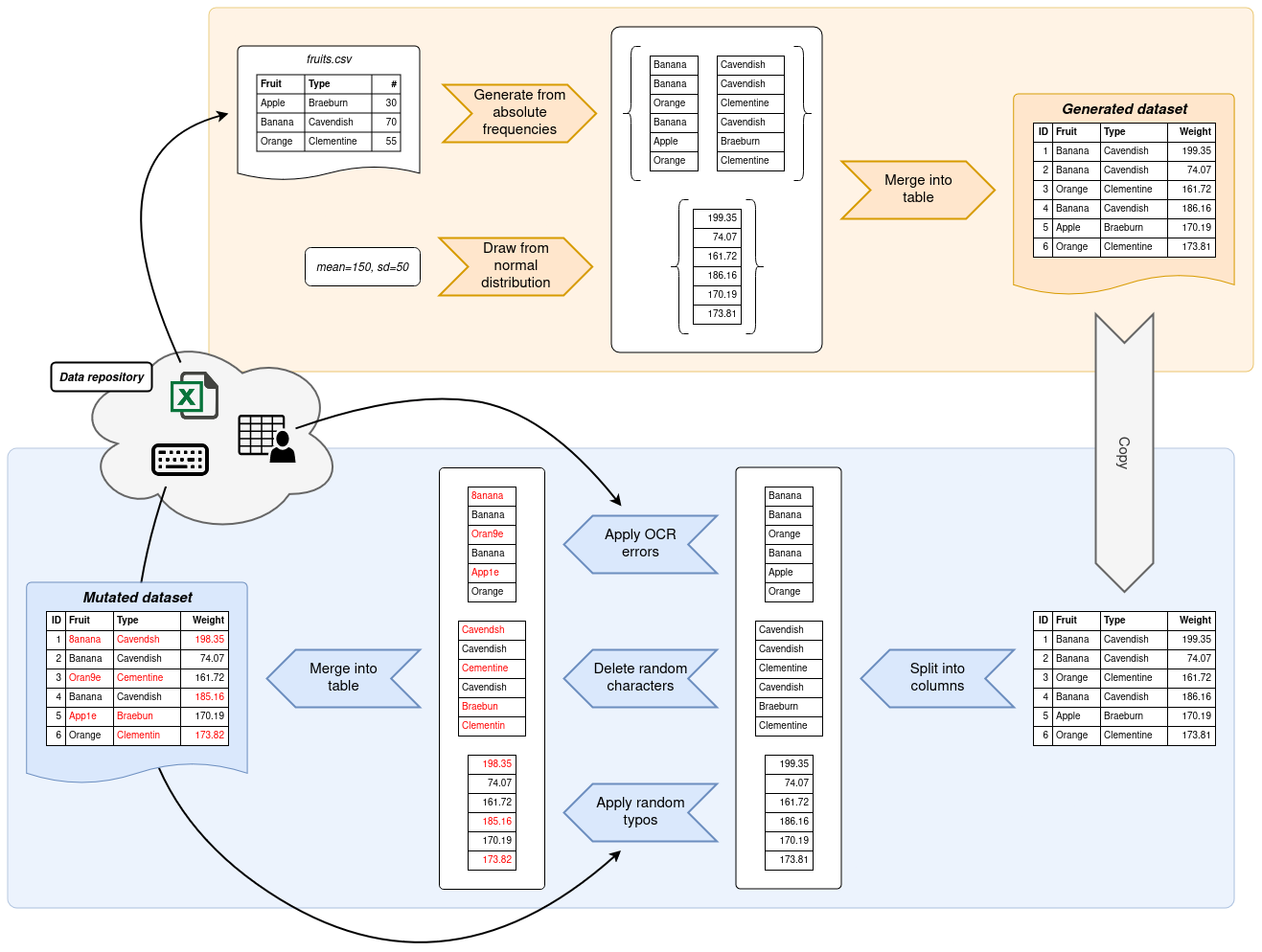
Gecko exposes two modules, generator and mutator, to help you write data generation scripts.
Both contain built-in functions covering the most common use cases for generating data from frequency information and
mutating data based on common error sources, such as typos, OCR errors and much more.
The following example gives a very brief overview of what a data generation script with Gecko might look like. It uses frequency tables from the Gecko data repository which has been cloned into a directory next to the script itself.
```python from pathlib import Path
import numpy as np
from gecko import generator, mutator
create a RNG with a set seed for reproducible results
rng = np.random.default_rng(727)
path to the Gecko data repository
geckodatadir = Path("gecko-data")
create a data frame with 10,000 rows and a single column called "last_name"
which sources its values from the frequency table with the same name
dfgenerated = generator.todataframe( [ ("lastname", generator.fromfrequencytable( geckodatadir / "deDE" / "last-name.csv", valuecolumn="lastname", freqcolumn="count", rng=rng, )), ], 10_000, )
mutate this data frame by randomly deleting characters in 1% of all rows
dfmutated = mutator.mutatedataframe( dfgenerated, [ ("lastname", (.01, mutator.withdelete(rng))), ], )
export both data frames using Pandas' to_csv function
dfgenerated.tocsv("german-generated.csv", indexlabel="id") dfmutated.tocsv("german-mutated.csv", indexlabel="id") ```
For a more extensive usage guide, refer to the docs.
Rationale
The GeCo framework was originally conceived to facilitate the generation and mutation of personal data to validate record linkage algorithms. In the field of record linkage, acquiring real-world personal data to test new algorithms on is hard to come by. Hence, GeCo went for a synthetic approach using statistical models from publicly available data. GeCo was built for Python 2.7 and has not seen any active development since its last publication in 2013. The general idea of providing shareable and reproducible Python scripts to generate personal data however still holds a lot of promise. This has led to the development of the Gecko library.
A lot of GeCo's weaknesses were rectified with this library.
Vectorized functions from Pandas and NumPy provide significant performance boosts and aid integration into existing
data science applications.
A simplified API allows for a much easier development of custom generators and mutators.
NumPy's random number generation routines instead of Python's built-in random module make fine-tuned reproducible
results a breeze.
Gecko therefore seeks to be GeCo's "bigger brother" and aims to provide a much more refined experience to generate
realistic personal data.
Disclaimer
Gecko is still very much in a "beta" state. As it stands, it satisfies our internal use cases within the Medical Data Science group, but we also seek wider adoption. If you find any issues or improvements with the library, do not hesitate to contact us.
Citing Gecko
If you found Gecko useful, then we highly appreciate proper citations of our work in your own publications. GitHub supports the Citation File Format (CFF) and can parse the corresponding file contained within this project. Simply click "Cite this repository" on this project's GitHub page. We also provide extensive information on how to cite Gecko in our documentation, as well as links to all of our original publications and presentations.
License
Gecko is released under the MIT License.
Owner
- Name: Medical Data Science Leipzig
- Login: ul-mds
- Kind: organization
- Location: Germany
- Website: https://www.uniklinikum-leipzig.de/einrichtungen/medical-data-science/en
- Repositories: 1
- Profile: https://github.com/ul-mds
Projects published by members of the Medical Data Science Department at the Medical Informatics Center Leipzig
Citation (CITATION.cff)
cff-version: 1.2.0
title: Gecko
message: 'If you use this software, please cite it as below.'
type: software
authors:
- given-names: Maximilian
family-names: Jugl
email: Maximilian.Jugl@medizin.uni-leipzig.de
affiliation: >-
Leipzig University Medical Center, Dept. Medical Data
Science
orcid: 'https://orcid.org/0009-0000-8479-1716'
- given-names: Toralf
family-names: Kirsten
email: Toralf.Kirsten@medizin.uni-leipzig.de
affiliation: >-
Leipzig University Medical Center, Dept. Medical Data
Science
orcid: 'https://orcid.org/0000-0001-7117-4268'
repository-code: 'https://github.com/ul-mds/gecko'
url: 'https://ul-mds.github.io/gecko/'
repository-artifact: 'https://pypi.org/project/gecko-syndata/'
license: MIT
commit: 195510411978c76999ee63a0eb37650bb976490c
version: 0.3.2
date-released: '2024-07-19'
preferred-citation:
type: article
authors:
- given-names: Maximilian
family-names: Jugl
email: Maximilian.Jugl@medizin.uni-leipzig.de
affiliation: >-
Leipzig University Medical Center, Dept. Medical Data
Science
orcid: 'https://orcid.org/0009-0000-8479-1716'
- given-names: Toralf
family-names: Kirsten
email: Toralf.Kirsten@medizin.uni-leipzig.de
affiliation: >-
Leipzig University Medical Center, Dept. Medical Data
Science
orcid: 'https://orcid.org/0000-0001-7117-4268'
doi: '10.1016/j.softx.2024.101846'
journal: 'SoftwareX'
month: 9
title: 'Gecko: A Python library for the generation and mutation of realistic personal identification data at scale'
abstract: 'Record linkage algorithms require testing on realistic personal identification data to assess their efficacy in real-world settings. Access to this kind of data is often infeasible due to rigid data privacy regulations. Open-source tools for generating realistic data are either unmaintained or lack performance to scale to the generation of millions of records. We introduce Gecko as a Python library for creating shareable scripts to generate and mutate realistic personal data. Built on top of popular data science libraries in Python, it greatly facilitates integration into existing workflows. Benchmarks are provided to prove the library’s performance and scalability claims.'
volume: 27
year: 2024
GitHub Events
Total
- Create event: 27
- Release event: 8
- Issues event: 4
- Delete event: 22
- Push event: 87
- Pull request review comment event: 1
- Pull request review event: 1
- Pull request event: 45
Last Year
- Create event: 27
- Release event: 8
- Issues event: 4
- Delete event: 22
- Push event: 87
- Pull request review comment event: 1
- Pull request review event: 1
- Pull request event: 45
Issues and Pull Requests
Last synced: about 1 year ago
All Time
- Total issues: 40
- Total pull requests: 72
- Average time to close issues: 1 day
- Average time to close pull requests: about 8 hours
- Total issue authors: 1
- Total pull request authors: 1
- Average comments per issue: 0.0
- Average comments per pull request: 0.0
- Merged pull requests: 72
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 22
- Pull requests: 54
- Average time to close issues: 1 day
- Average time to close pull requests: about 11 hours
- Issue authors: 1
- Pull request authors: 1
- Average comments per issue: 0.0
- Average comments per pull request: 0.0
- Merged pull requests: 54
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
- mjugl (35)
Pull Request Authors
- mjugl (112)
Top Labels
Issue Labels
Pull Request Labels
Packages
- Total packages: 1
-
Total downloads:
- pypi 133 last-month
- Total dependent packages: 0
- Total dependent repositories: 0
- Total versions: 16
- Total maintainers: 1
pypi.org: gecko-syndata
Generation and mutation of realistic data at scale.
- Homepage: https://github.com/ul-mds/gecko
- Documentation: https://ul-mds.github.io/gecko/
- License: MIT
-
Latest release: 0.6.4
published over 1 year ago
Rankings
Maintainers (1)
Dependencies
- JamesIves/github-pages-deploy-action v4 composite
- actions/checkout v4 composite
- actions/setup-python v5 composite
- actions/checkout v4 composite
- actions/setup-python v5 composite
- actions/checkout v4 composite
- actions/setup-python v5 composite
- babel 2.14.0
- certifi 2024.2.2
- charset-normalizer 3.3.2
- click 8.1.7
- colorama 0.4.6
- exceptiongroup 1.2.0
- ghp-import 2.1.0
- gitdb 4.0.11
- gitpython 3.1.42
- griffe 0.42.1
- idna 3.6
- importlib-metadata 7.1.0
- iniconfig 2.0.0
- jinja2 3.1.3
- lxml 5.1.0
- markdown 3.6
- markupsafe 2.1.5
- mergedeep 1.3.4
- mkdocs 1.5.3
- mkdocs-autorefs 1.0.1
- mkdocs-git-revision-date-localized-plugin 1.2.4
- mkdocs-material 9.5.15
- mkdocs-material-extensions 1.3.1
- mkdocstrings 0.24.1
- mkdocstrings-python 1.8.0
- numpy 1.26.4
- packaging 24.0
- paginate 0.5.6
- pandas 2.2.1
- pathspec 0.12.1
- platformdirs 4.2.0
- pluggy 1.4.0
- pygments 2.17.2
- pymdown-extensions 10.7.1
- pytest 7.4.4
- python-dateutil 2.9.0.post0
- pytz 2024.1
- pyyaml 6.0.1
- pyyaml-env-tag 0.1
- regex 2023.12.25
- requests 2.31.0
- ruff 0.1.15
- six 1.16.0
- smmap 5.0.1
- tomli 2.0.1
- typing-extensions 4.10.0
- tzdata 2024.1
- urllib3 2.2.1
- watchdog 4.0.0
- zipp 3.18.1
- ruff ^0.1.14 develop
- mkdocs-git-revision-date-localized-plugin ^1.2.4 docs
- mkdocs-material ^9.5.13 docs
- mkdocstrings ^0.24.1 docs
- lxml >=4.9.0,<6
- numpy >=1.20.3,<2
- pandas ^2.0.0
- python >=3.9,<3.13
- typing-extensions ^4.0.0
- gitpython ^3.1.42 test
- pytest ^7.4.2 test