python-schema-matching
A python tool using XGboost and sentence-transformers to perform schema matching task on tables.
Science Score: 67.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
✓DOI references
Found 1 DOI reference(s) in README -
✓Academic publication links
Links to: springer.com, nature.com -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (13.5%) to scientific vocabulary
Keywords
Repository
A python tool using XGboost and sentence-transformers to perform schema matching task on tables.
Basic Info
Statistics
- Stars: 36
- Watchers: 3
- Forks: 12
- Open Issues: 5
- Releases: 3
Topics
Metadata Files
README.md
![]()
HXL-style tag version: https://github.com/fireindark707/Python-Schema-Matching/tree/hxl_tag
HDXSM Datasets: https://drive.google.com/file/d/1wPXFS1ZLi6Xf7aRZU1Jw-dJrggs1Ox/view?usp=sharing
SMUTF: Schema Matching Using Generative Tags and Hybrid Features
A python tool using XGboost and sentence-transformers to perform schema matching task on tables. Support multi-language column names and instances matching and can be used without column names. Both csv and json file type are supported.
What is schema matching?
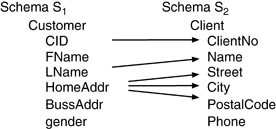
Schema matching is the problem of finding potential associations between elements (most often attributes or relations) of two schemas. source
Dependencies
- numpy==1.19.5
- pandas==1.1.5
- nltk==3.6.5
- python-dateutil==2.8.2
- sentence-transformers==2.1.0
- xgboost==1.5.2
- strsimpy==0.2.1
Package usage
Install
pip install schema-matching
Example
``` from schemamatching import schemamatching
dfpred,dfpredlabels,predictedpairs = schemamatching("Test Data/QA/Table1.json","Test Data/QA/Table2.json") print(dfpred) print(dfpredlabels) for pairtuple in predictedpairs: print(pair_tuple) ```
Return:
- df_pred: Predict value matrix, pd.DataFrame.
- dfpredlabels: Predict label matrix, pd.DataFrame.
- predicted_pairs: Predict label == 1 column pairs, in tuple format.
Parameters:
- table1_pth: Path to your first csv, json or jsonl file.
- table2_pth: Path to your second csv, json or jsonl file.
- threshold: Threshold, you can use this parameter to specify threshold value, suggest 0.9 for easy matching(column name very similar). Default value is calculated from training data, which is around 0.15-0.2. This value is used for difficult matching(column name masked or very different).
- strategy: Strategy, there are three options: "one-to-one", "one-to-many" and "many-to-many". "one-to-one" means that one column can only be matched to one column. "one-to-many" means that columns in Table1 can only be matched to one column in Table2. "many-to-many" means that there is no restrictions. Default is "many-to-many".
- model_pth: Path to trained model folder, which must contain at least one pair of ".model" file and ".threshold" file. You don't need to specify this parameter.
Raw code usage: Training
Data
See Data format in Training Data and Test Data folders. You need to put mapping.txt, Table1.csv and Table2.csv in new folders under Training Data. For Test Data, mapping.txt is not needed.
1.Construct features
python relation_features.py
2.Train xgboost models
python train.py
3.Calculate similarity matrix (inference)
Example:
python cal_column_similarity.py -p Test\ Data/self -m /model/2022-04-12-12-06-32 -s one-to-one
python cal_column_similarity.py -p Test\ Data/authors -m /model/2022-04-12-12-06-32-11 -t 0.9
Parameters:
- -p: Path to test data folder, must contain "Table1.csv" and "Table2.csv" or "Table1.json" and "Table2.json".
- -m: Path to trained model folder, which must contain at least one pair of ".model" file and ".threshold" file.
- -t: Threshold, you can use this parameter to specify threshold value, suggest 0.9 for easy matching(column name very similar). Default value is calculated from training data, which is around 0.15-0.2. This value is used for difficult matching(column name masked or very different).
- -s: Strategy, there are three options: "one-to-one", "one-to-many" and "many-to-many". "one-to-one" means that one column can only be matched to one column. "one-to-many" means that columns in Table1 can only be matched to one column in Table2. "many-to-many" means that there is no restrictions. Default is "many-to-many".
Output:
- similaritymatrixlabel.csv: Labels(0,1) for each column pairs.
- similaritymatrixvalue.csv: Average of raw values computed by all the xgboost models.
Feature Engineering
Features: "isurl","isnumeric","isdate","isstring","numeric:mean", "numeric:min", "numeric:max", "numeric:variance","numeric:cv", "numeric:unique/len(datalist)", "length:mean", "length:min", "length:max", "length:variance","length:cv", "length:unique/len(datalist)", "whitespaceratios:mean","punctuationratios:mean","specialcharacterratios:mean","numericratios:mean", "whitespaceratios:cv","punctuationratios:cv","specialcharacterratios:cv","numericratios:cv", "colname:bleuscore", "colname:editdistance","colname:lcs","colname:tsmcosine", "colname:oneinone", "instancesimilarity:cosine"
- tsm_cosine: Cosine similarity of column names computed by sentence-transformers using "paraphrase-multilingual-mpnet-base-v2". Support multi-language column names matching.
- instance_similarity:cosine: Select 20 instances each string column and compute its mean embedding using sentence-transformers. Cosine similarity is computed by each pairs.
Performance
Cross Validation on Training Data(Each pair to be used as test data)
- Average Precision: 0.755
- Average Recall: 0.829
- Average F1: 0.766
Average Confusion Matrix: | | Negative(Truth) | Positive(Truth) | |----------------|-----------------|-----------------| | Negative(pred) | 0.94343111 | 0.05656889 | | Positive(pred) | 0.17135417 | 0.82864583 |
Inference on Test Data (Give confusing column names)
Data: https://github.com/fireindark707/SchemaMatchingXGboost/tree/main/Test%20Data/self
| | title | text | summary | keywords | url | country | language | domain | name | timestamp | |---------|------------|------------|------------|------------|------------|------------|------------|------------|-------|------------| | col1 | 1(FN) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | col2 | 0 | 1(TP) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | col3 | 0 | 0 | 1(TP) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | words | 0 | 0 | 0 | 1(TP) | 0 | 0 | 0 | 0 | 0 | 0 | | link | 0 | 0 | 0 | 0 | 1(TP) | 0 | 0 | 0 | 0 | 0 | | col6 | 0 | 0 | 0 | 0 | 0 | 1(TP) | 0 | 0 | 0 | 0 | | lang | 0 | 0 | 0 | 0 | 0 | 0 | 1(TP) | 0 | 0 | 0 | | col8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1(TP) | 0 | 0 | | website | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0(FN) | 0 | | col10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1(TP) |
F1 score: 0.889
Cite
@software{fireinfark707_Schema_Matching_by_2022,
author = {fireinfark707},
license = {MIT},
month = {4},
title = {{Schema Matching by XGboost}},
url = {https://github.com/fireindark707/Schema_Matching_XGboost},
year = {2022}
}
Owner
- Name: fireindark707
- Login: fireindark707
- Kind: user
- Location: Xi'an
- Repositories: 5
- Profile: https://github.com/fireindark707
Citation (CITATION.cff)
# This CITATION.cff file was generated with cffinit. # Visit https://bit.ly/cffinit to generate yours today! cff-version: 1.2.0 title: Schema Matching by XGboost message: >- If you use this software, please cite it using the metadata from this file. type: software authors: - given-names: fireinfark707 repository-code: >- https://github.com/fireindark707/Schema_Matching_XGboost abstract: >- Using XGboost to perform schema matching task on tables. Support multi-language column names matching and can be used without column names. license: MIT date-released: '2022-04-10'
GitHub Events
Total
- Issues event: 1
- Watch event: 8
- Issue comment event: 1
- Push event: 2
- Pull request event: 1
- Fork event: 1
Last Year
- Issues event: 1
- Watch event: 8
- Issue comment event: 1
- Push event: 2
- Pull request event: 1
- Fork event: 1
Issues and Pull Requests
Last synced: 11 months ago
All Time
- Total issues: 6
- Total pull requests: 1
- Average time to close issues: 2 days
- Average time to close pull requests: N/A
- Total issue authors: 6
- Total pull request authors: 1
- Average comments per issue: 2.17
- Average comments per pull request: 0.0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 1
- Pull requests: 1
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Issue authors: 1
- Pull request authors: 1
- Average comments per issue: 0.0
- Average comments per pull request: 0.0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
- NielsRogge (1)
- veer77 (1)
- sagargowda88 (1)
- rsancheztaksoiai (1)
- robinzixuan (1)
- rishanshah (1)
Pull Request Authors
- robinzixuan (2)
Top Labels
Issue Labels
Pull Request Labels
Dependencies
- nltk ==3.6.5
- numpy ==1.19.5
- pandas ==1.1.5
- python-dateutil ==2.8.2
- sentence-transformers ==2.1.0
- strsimpy ==0.2.1
- xgboost ==1.5.2