https://github.com/fgnt/sed_scores_eval
Science Score: 44.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Committers with academic emails
-
✓Institutional organization owner
Organization fgnt has institutional domain (nt.uni-paderborn.de) -
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (7.6%) to scientific vocabulary
Keywords from Contributors
Repository
Basic Info
- Host: GitHub
- Owner: fgnt
- License: mit
- Language: Python
- Default Branch: main
- Size: 608 KB
Statistics
- Stars: 38
- Watchers: 5
- Forks: 6
- Open Issues: 6
- Releases: 0
Metadata Files
README.md
sedscoreseval
![]()
sedscoreseval is a package for the efficient (threshold-independent) evaluation of Sound Event Detection (SED) systems based on the SED system's soft classification scores as described in
Threshold-Independent Evaluation of Sound Event Detection Scores
J. Ebbers, R. Serizel and R. Haeb-Umbach
in Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2022 https://arxiv.org/abs/2201.13148
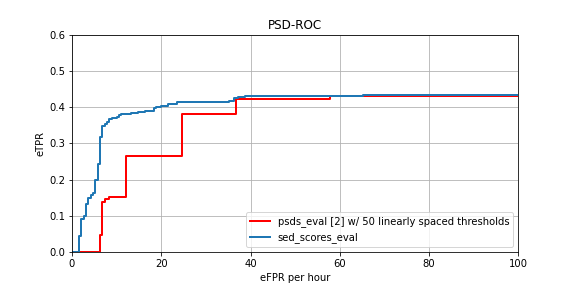
With SED systems providing soft classification scores (usually frame-wise), performance can be evaluated at different operating points (OPs) by varying the decision/discrimination threshold used for binarization of the soft scores. Other evaluation frameworks evaluate a list of detected sounds (list of event labels with corresponding event onset and offset times) for each decision threshold separately. Therefore, they can not be used to accurately evaluate performance curves over all thresholds (such as Precision-Recall curves and ROC curves) given that there are many thousands (or even millions) of thresholds (as many as there are frames in the dataset) that result in a different list of detections. Performance curves can at most be approximated using a limited subset of thresholds which, however, may result in inaccurate curves (see Figure below). sedscoreseval, in contrast, efficiently evaluates performance for all decision thresholds jointly (also for sophisticated collar-based and intersection-based evaluation criteria, see paper for details). It therefore enables the efficient and accurate computation of performance curves such as Precision-Recall Curves and ROC Curves.
If you use this package please cite our paper.
Supported Evaluation Criteria
Intermediate Statistics:
- Segment-based [1]: Classifications and targets are defined and evaluated in fixed length segments.
- Collar-based (a.k.a. event-based) [1]: Compares if detected event (onset, offset, event_label) matches a ground truth event up to a certain collar on onset and offset.
- Intersection-based [2]: Evaluates the intersections of detected and ground truth events (Please also cite [2] if you use intersection-based evaluation)
- Clip-based: Audio Tagging evaluation
Evaluation Metrics / Curves:
- Precision-Recall (PR) Curve: Precisions for arbitrary decision thresholds plotted over Recalls
- F-Score Curve: F-Scores plotted over decision thresholds
- F-Score @ OP: F-Score for a specified decision threshold
- F-Score @ Best: F-Score for the optimal decision threshold (w.r.t. to the considered dataset)
- Average Precision: weighted mean of precisions for arbitrary decision thresholds. Weights are the increase in recall compared to the prior recall.
- Error-Rate Curve: Error-Rates plotted over decision thresholds
- Error-Rate @ OP: Error-Rate for a specified decision threshold
- Error-Rate @ Best: Error-Rate for the optimal decision threshold (w.r.t. to the considered dataset)
- ROC Curve: True-Positive rates (recalls) for arbitrary decision thresholds plotted over False-Positive rates
- Area under ROC curve
- PSD-ROC Curve: effective True Positive Rates (eTPRs) plotted over effective False Positive Rates (eFPRs) as described in [2]*.
- PSD Score (PSDS): normalized Area under PSD-ROC Curve (until a certain maximum eFPR).
- Post-processing independent PSD-ROC Curve (pi-PSD-ROC): effective True Positive Rates (eTPRs) plotted over effective False Positive Rates (eFPRs) from different post-processings as described in [3].
- Post-processing independent PSDS (piPSDS): normalized Area under pi-PSD-ROC Curve (until a certain maximum eFPR).
[1] A. Mesaros, T. Heittola, and T. Virtanen, "Metrics for polyphonic sound event detection", Applied Sciences, 2016,
[2] C. Bilen, G. Ferroni, F. Tuveri, J. Azcarreta and S. Krstulovic, "A Framework for the Robust Evaluation of Sound Event Detection", in Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2020, arXiv: https://arxiv.org/abs/1910.08440
[3] J. Ebbers, R. Haeb-Umbach, and R. Serizel, "Post-Processing Independent Evaluation of Sound Event Detection Systems", submitted to Detection and Classification of Acoustic Scenes and Events (DCASE) Workshop, 2023, arXiv: https://arxiv.org/abs/2306.15440
*Please also cite [2] if you use PSD-ROC and/or PSDS
IPython Notebooks
Have a look at the provided example notebooks for usage example and for some comparisons/validations w.r.t. reference packages.
Input Format
System's Classification Scores
The system's classification scores need to be saved in a dedicated folder with a tsv score file for each audio file from the evaluation set. The score files have to be named according to the audio file names. If, e.g., the audio file is "test1.wav" the score file's name needs to be "test1.tsv". For each score window (arbitrary and also varying window lengths are allowed but windows need to be non-overlapping and gapless, i.e., the onset time of the next window must be the offset time of the current window) the onset and offset times of the window (in seconds) must be stated in the first and second column, respectively, followed by classification scores for each event class in a separate column as illustrated in the following example:
|onset|offset|class1 |class2 |class3 |... | |----:|-----:|-------:|-------:|-------:|-------:| |0.0 |0.02 |0.010535|0.057549|0.063102|... | |0.02 |0.04 |0.001196|0.167730|0.098838|... | |... |... |... |... |... |... | |4.76 |4.78 |0.015128|0.769687|0.087403|... | |4.78 |4.8 |0.002032|0.587578|0.120165|... | |... |... |... |... |... |... | |9.98 |10.0 |0.031421|0.089716|0.929873|... |
At inference time, when your system outputs a classification score array
scores_arrof shape TxK with T and K being the number of windows and event
classes, respectively, you can conveniently write the score file of above
format as follows:
python
sed_scores_eval.io.write_sed_scores(
scores_arr, '/path/to/score_dir/test1.tsv',
timestamps=timestamps, event_classes=event_classes
)
where timestamps must be a 1d list or array of length T+1 providing the
window boundary times and event_classes must be a list of length K providing
the event class names corresponding to the columns in scores_arr.
In case the output scores of the whole dataset fit into memory, you can also
provide a dict of pandas.DataFrames of above format, where dict keys must be
the file ids (e.g. "test1").
Score dataframes can be obtained from score arrays analogously to above by
python
scores["test1"] = sed_scores_eval.utils.create_score_dataframe(
scores_arr, timestamps=timestamps, event_classes=event_classes
)
Ground Truth
The ground truth events for the whole dataset must be provided either as a file of the following format
|filename |onset|offset|event_label| |----------:|----:|-----:|-----:| |test1.wav |3.98 |4.86 |class2| |test1.wav |9.05 |10.0 |class3| |test2.wav |0.0 |4.07 |class1| |test2.wav |0.0 |8.54 |class2| |test2.wav |5.43 |7.21 |class1| |... |... |... |... |
or as a dict
python
{
"test1": [(3.98, 4.86, "class2"), (9.05, 10.0, "class3")],
"test2": [(0.0, 4.07, "class1"), (0.0, 8.54, "class2"), (5.43, 7.21, "class1")],
...
}
which can be obtained from the file by
python
ground_truth_dict = sed_scores_eval.io.read_ground_truth_events(ground_truth_file)
Audio durations
If required, you either have to provide the audios' durations (in seconds) as a file of the following format:
|filename |duration| |--------:|---:| |test1.wav|10.0| |test2.wav|9.7 | |... |... |
or as a dict
python
{
"test1": 10.0,
"test2": 9.7,
...
}
which can be obtained from the file by
python
durations_dict = sed_scores_eval.io.read_audio_durations(durations_file)
Installation
Install package directly
bash
$ pip install git+https://github.com/fgnt/sed_scores_eval.git
or clone and install (editable)
bash
$ git clone https://github.com/fgnt/sed_scores_eval.git
$ cd sed_scores_eval
$ pip install --editable .
Owner
- Name: Department of Communications Engineering University of Paderborn
- Login: fgnt
- Kind: organization
- Location: Paderborn, Germany
- Website: http://nt.uni-paderborn.de
- Repositories: 37
- Profile: https://github.com/fgnt
GitHub Events
Total
- Issues event: 4
- Watch event: 8
- Issue comment event: 4
- Push event: 1
- Pull request event: 2
- Fork event: 1
Last Year
- Issues event: 4
- Watch event: 8
- Issue comment event: 4
- Push event: 1
- Pull request event: 2
- Fork event: 1
Committers
Last synced: 9 months ago
Top Committers
| Name | Commits | |
|---|---|---|
| Janek Ebbers | e****s@n****e | 82 |
| mdeegen | 8****n@u****m | 7 |
| Janek Ebbers | e****s@m****m | 6 |
| Name | m****s@g****m | 3 |
| JanekEbb | j****2@g****m | 1 |
Issues and Pull Requests
Last synced: 9 months ago
All Time
- Total issues: 10
- Total pull requests: 3
- Average time to close issues: 4 months
- Average time to close pull requests: 10 days
- Total issue authors: 10
- Total pull request authors: 2
- Average comments per issue: 0.8
- Average comments per pull request: 0.0
- Merged pull requests: 3
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 4
- Pull requests: 2
- Average time to close issues: N/A
- Average time to close pull requests: 2 days
- Issue authors: 4
- Pull request authors: 1
- Average comments per issue: 0.0
- Average comments per pull request: 0.0
- Merged pull requests: 2
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
- sshish (1)
- Ming-er (1)
- nkundiushuti (1)
- denfed (1)
- VEOjiwon (1)
- paozhuanis1 (1)
- minducky (1)
- MonolithFoundation (1)
- TioSisai (1)
- benjaminsshoffman (1)
Pull Request Authors
- nkundiushuti (2)
- mdeegen (1)
Top Labels
Issue Labels
Pull Request Labels
Packages
- Total packages: 1
-
Total downloads:
- pypi 1,466 last-month
- Total dependent packages: 0
- Total dependent repositories: 0
- Total versions: 5
- Total maintainers: 1
pypi.org: sed-scores-eval
(Threshold-Independent) Evaluation of Sound Event Detection Scores
- Homepage: https://github.com/fgnt/sed_scores_eval
- Documentation: https://sed-scores-eval.readthedocs.io/
- License: MIT
-
Latest release: 0.0.4
published about 2 years ago
Rankings
Maintainers (1)
Dependencies
- einops *
- lazy_dataset *
- numpy *
- pandas *
- pathlib *
- scipy *
- sed_eval *
- actions/checkout v3 composite
- actions/setup-python v3 composite