Science Score: 54.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (5.5%) to scientific vocabulary
Repository
forked repo for salmon detection using ViTPose
Basic Info
- Host: GitHub
- Owner: jsheo96
- License: apache-2.0
- Language: Python
- Default Branch: main
- Size: 10.4 MB
Statistics
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
- Releases: 0
Metadata Files
README.md
ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
![]()
![]()
![]()
![]()
Results | Updates | Usage | Todo | Acknowledge


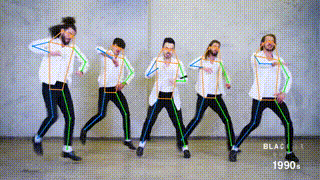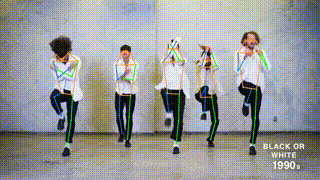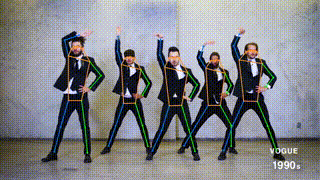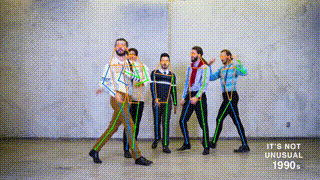
This branch contains the pytorch implementation of ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation. It obtains 81.1 AP on MS COCO Keypoint test-dev set.

Results from this repo on MS COCO val set (single-task training)
Using detection results from a detector that obtains 56 mAP on person. The configs here are for both training and test.
With classic decoder
| Model | Pretrain | Resolution | AP | AR | config | log | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | MAE | 256x192 | 75.8 | 81.1 | config | log | Onedrive | | ViTPose-L | MAE | 256x192 | 78.3 | 83.5 | config | log | Onedrive | | ViTPose-H | MAE | 256x192 | 79.1 | 84.1 | config | log | Onedrive |
With simple decoder
| Model | Pretrain | Resolution | AP | AR | config | log | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | MAE | 256x192 | 75.5 | 80.9 | config | log | Onedrive | | ViTPose-L | MAE | 256x192 | 78.2 | 83.4 | config | log | Onedrive | | ViTPose-H | MAE | 256x192 | 78.9 | 84.0 | config | log | Onedrive |
Results from this repo on MS COCO val set (multi-task training)
Using detection results from a detector that obtains 56 mAP on person. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 77.5 | 82.6 | config |Onedrive | | ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 79.1 | 84.1 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 79.8 | 84.8 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 81.0 | 85.6 | | |
Results from this repo on OCHuman test set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 88.2 | 90.0 | config |Onedrive | | ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 91.5 | 92.8 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 91.6 | 92.8 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 93.3 | 94.3 | | |
Results from this repo on CrowdPose test set (multi-task training)
Using YOLOv3 human detector. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AP(H) | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 74.7 | 63.3 | config |Onedrive | | ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 76.6 | 65.9 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 76.3 | 65.6 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 78.3 | 67.9 | | |
Results from this repo on MPII val set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation. The metric is PCKh.
| Model | Dataset | Resolution | Mean | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 93.4 | config |Onedrive | | ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 93.9 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 94.1 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 94.3 | | |
Results from this repo on AI Challenger test set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 31.9 | 36.3 | config |Onedrive | | ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 34.6 | 39.0 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 35.3 | 39.8 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 43.2 | 47.1 | | |
Updates
[2022-05-24] Upload the single-task training code, single-task pre-trained models, and multi-task pretrained models.
[2022-05-06] Upload the logs for the base, large, and huge models!
[2022-04-27] Our ViTPose with ViTAE-G obtains 81.1 AP on COCO test-dev set!
Applications of ViTAE Transformer include: image classification | object detection | semantic segmentation | animal pose segmentation | remote sensing | matting | VSA | ViTDet
Usage
We use PyTorch 1.9.0 or NGC docker 21.06, and mmcv 1.3.9 for the experiments.
bash
git clone https://github.com/open-mmlab/mmcv.git
cd mmcv
git checkout v1.3.9
MMCV_WITH_OPS=1 pip install -e .
cd ..
git clone https://github.com/ViTAE-Transformer/ViTPose.git
cd ViTPose
pip install -v -e .
After install the two repos, install timm and einops, i.e.,
bash
pip install timm==0.4.9 einops
Download the pretrained models from MAE or ViTAE, and then conduct the experiments by
```bash
for single machine
bash tools/dist_train.sh
for multiple machines
python -m torch.distributed.launch --nnodes
To test the pretrained models performance, please run
bash
bash tools/dist_test.sh <Config PATH> <Checkpoint PATH> <NUM GPUs>
Todo
This repo current contains modifications including:
[x] Upload configs and pretrained models
[x] More models with SOTA results
[ ] Upload multi-task training config
Acknowledge
We acknowledge the excellent implementation from mmpose and MAE.
Citing ViTPose
@misc{xu2022vitpose,
title={ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation},
author={Yufei Xu and Jing Zhang and Qiming Zhang and Dacheng Tao},
year={2022},
eprint={2204.12484},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
For ViTAE and ViTAEv2, please refer to: ``` @article{xu2021vitae, title={Vitae: Vision transformer advanced by exploring intrinsic inductive bias}, author={Xu, Yufei and Zhang, Qiming and Zhang, Jing and Tao, Dacheng}, journal={Advances in Neural Information Processing Systems}, volume={34}, year={2021} }
@article{zhang2022vitaev2, title={ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond}, author={Zhang, Qiming and Xu, Yufei and Zhang, Jing and Tao, Dacheng}, journal={arXiv preprint arXiv:2202.10108}, year={2022} } ```
Owner
- Name: JiseongHeo
- Login: jsheo96
- Kind: user
- Location: Daejeon, South Korea
- Company: Tidepool
- Website: linkedin.com/in/jsheo
- Repositories: 31
- Profile: https://github.com/jsheo96
CTO of TIDEPOOL #Vision #AI #ML
Citation (CITATION.cff)
cff-version: 1.2.0 message: "If you use this software, please cite it as below." authors: - name: "MMPose Contributors" title: "OpenMMLab Pose Estimation Toolbox and Benchmark" date-released: 2020-08-31 url: "https://github.com/open-mmlab/mmpose" license: Apache-2.0
GitHub Events
Total
Last Year
Dependencies
- pytorch/pytorch ${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel build
- pytorch/pytorch ${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel build
- numpy *
- torch >=1.3
- docutils ==0.16.0
- myst-parser *
- sphinx ==4.0.2
- sphinx_copybutton *
- sphinx_markdown_tables *
- mmcv-full >=1.3.8
- mmdet >=2.14.0
- mmtrack >=0.6.0
- albumentations >=0.3.2
- onnx *
- onnxruntime *
- pyrender *
- requests *
- smplx >=0.1.28
- trimesh *
- mmcv-full *
- munkres *
- regex *
- scipy *
- titlecase *
- torch *
- torchvision *
- xtcocotools >=1.8
- chumpy *
- dataclasses *
- json_tricks *
- matplotlib *
- munkres *
- numpy *
- opencv-python *
- pillow *
- scipy *
- torchvision *
- xtcocotools >=1.8
- coverage * test
- flake8 * test
- interrogate * test
- isort ==4.3.21 test
- pytest * test
- pytest-runner * test
- smplx >=0.1.28 test
- xdoctest >=0.10.0 test
- yapf * test