metaquantus
MetaQuantus is an XAI performance tool to identify reliable evaluation metrics
Science Score: 46.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
○.zenodo.json file
-
✓DOI references
Found 1 DOI reference(s) in README -
✓Academic publication links
Links to: plos.org, ieee.org -
✓Committers with academic emails
1 of 1 committers (100.0%) from academic institutions -
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (15.2%) to scientific vocabulary
Repository
MetaQuantus is an XAI performance tool to identify reliable evaluation metrics
Basic Info
Statistics
- Stars: 38
- Watchers: 3
- Forks: 1
- Open Issues: 1
- Releases: 4
Metadata Files
README.md
![]()
An XAI performance tool for the identification of reliable metrics
PyTorch
This repository contains the code and experimental results for the paper The Meta-Evaluation Problem in Explainable AI: Identifying Reliable Estimators with MetaQuantus by Hedström et al., 2023.
![]()
![]()
![]()
![]() <!--
<!--![]()
![]() -->
-->
MetaQuantus is currently under active development. Carefully note the release version to ensure reproducibility of your work.
Citation
If you find this toolkit or its companion paper interesting or useful in your research, use the following Bibtex annotation to cite us:
bibtex
@article{hedstrom2023metaquantus,
author = {Hedström, Anna and Bommer, Philine and Wickstrøm, Kristoffer K. and Samek, Wojciech and Lapuschkin, Sebastian and Höhne, Marina M. -C.},
title = {The Meta-Evaluation Problem in Explainable AI: Identifying Reliable Estimators with MetaQuantus},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2023},
url={https://openreview.net/forum?id=j3FK00HyfU},
note={}
}
Table of Contents
Motivation
The Evaluation Disagreement Problem. In Explainable AI (XAI), the need of meta-evaluation (i.e., the process of evaluating the evaluation method) arises as we select and quantitatively compare explanation methods for a given model, dataset and task---where the use of multiple metrics or evaluation techniques oftentimes lead to conflicting results. For example, scores from different metrics vary, both in range and direction, with lower or higher scores indicating higher quality explanations, making it difficult for practitioners to interpret the scores and select the best explanation method.
As illustrated in the Figure below, the two metrics, Faithfulness Correlation (FC) (Bhatt et al., 2020) and Pixel-Flipping (PF) (Bach et al., 2015) rank the same explanation methods differently. For example, the Gradient method (Mørch et al., 1995) (Baehrens et al., 2010) is both ranked the highest (R=1) and the lowest (R=3) depending on the metric used. From a practitioner's perspective, this causes confusion.
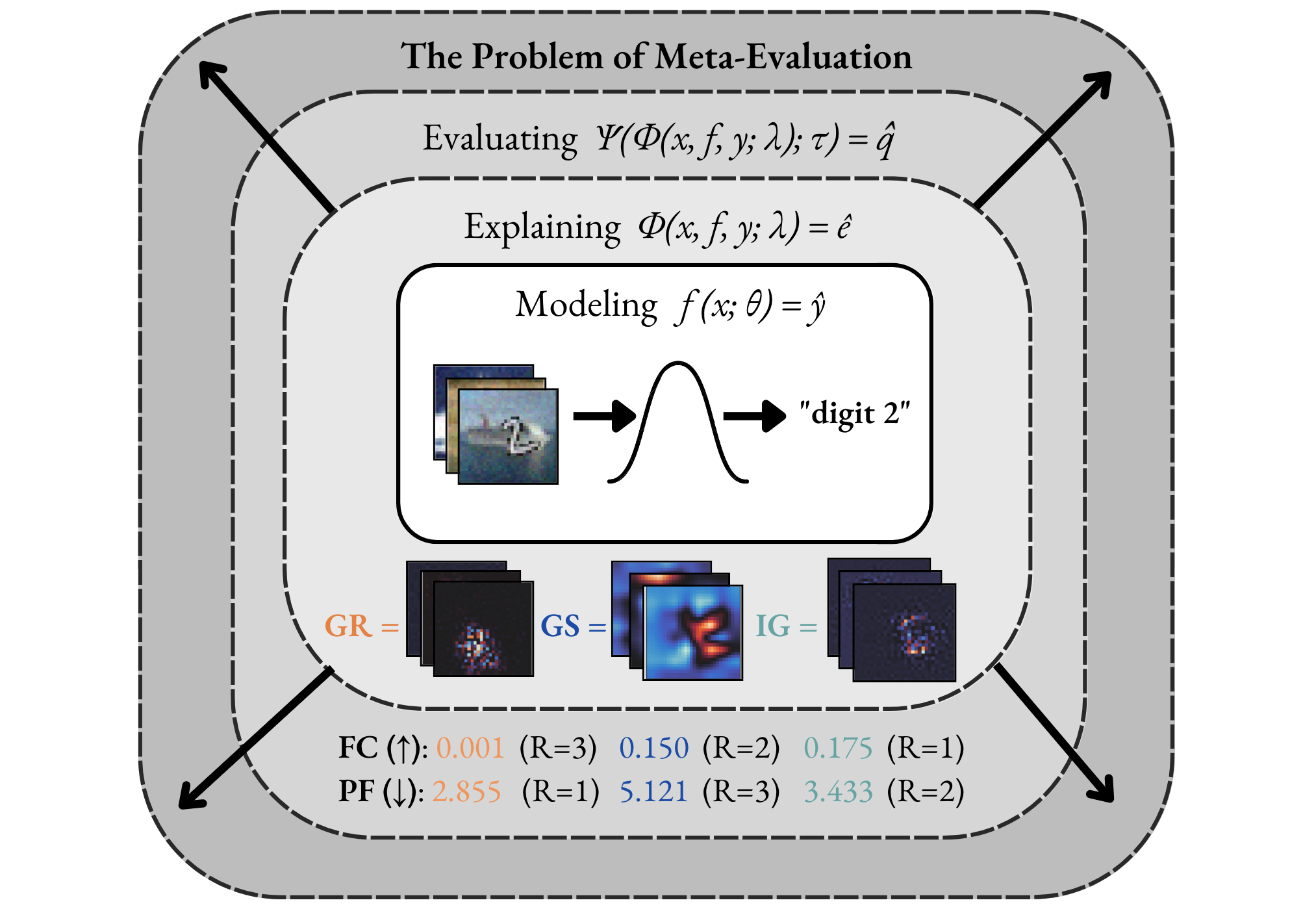
Our Meta-Evaluation Approach. With MetaQuantus, we address the problem of meta-evaluation by providing a simple yet comprehensive framework that evaluates metrics against two failure modes: resilience to noise (NR) and reactivity to adversaries (AR). In a similar way that software systems undergo vulnerability and penetration tests before deployment, this open-sourced tool is designed to stress test evaluation methods (e.g., as provided by Quantus).
Library
MetaQuantus is an open-source, development tool for XAI researchers and Machine Learning (ML) practitioners to verify and benchmark newly constructed metrics (i.e., ``quality estimators''). It offers an easy-to-use API that simplifies metric selection such that the explanation method selection in XAI can be performed more reliably, with minimal code. MetaQuantus includes:
- A series of pre-built tests such as
ModelPerturbationTestandInputPertubrationTestthat can be applied to various metrics - Supporting source code such as for plotting and analysis
- Various tutorials e.g., Getting-Started-with-MetaQuantus and Reproduce-Paper-Experiments
Installation
If you already have PyTorch installed on your machine, the most light-weight version of MetaQuantus can be obtained from PyPI:
setup
pip install metaquantus
Alternatively, you can download a local copy (and then, access the folder):
setup
git clone https://github.com/annahedstroem/MetaQuantus.git
cd MetaQuantus
And then install it locally:
setup
pip install -e .
Alternatively, you can simply install MetaQuantus with requirements.txt.
setup
pip install -r requirements.txt
Note that these installation options require that PyTorch is already installed on your machine.
Package requirements
The package requirements are as follows:
python>=3.7.1
pytorch>=1.10.1
quantus>=0.3.2
captum>=0.4.1
Getting started
Please see
Tutorial-Getting-Started-with-MetaQuantus.ipynb under tutorials/ folder to get started. Note that PyTorch framework and the XAI evalaution library Quantus is needed to run MetaQuantus.
Reproduce the paper experiments
To reproduce the results of this paper, you will need to follow these three steps:
- Generate the dataset. Run the notebook
Tutorial-Data-Generation-Experiments.ipynb to generate the necessary data for the experiments. This notebook will guide you through the process of downloading and preprocessing the data in order to save it to appropriate test sets. Please store the models in a folder called
assets/models/and the tests sets underassets/test_sets/. - Run the experiments. To obtain the results for the respective experiments, you have to run the respective Python experiments which are detailed below. All these Python files are located in the
experiments/folder. If you want to run the experiments on other explanation methods, datasets or models, feel free to change the hyperparameters. - Analyse the results. Once the results are obtained for your chosen experiments, run the Tutorial-Reproduce-Paper-Experiments.ipynb to analyse the results. (In the notebook itself, we have also listed which specific Python experiments that need to be run in order to obtain the results for this analysis step.)
Additional details on step 2 (Run the Experiments)
**Test**: Go to the root folder and run a simple test that meta-evaluation work.
```bash
python3 experiments/run_test.py --K=5 --iters=10 --dataset=MNIST
```
**Application**: Run the benchmarking experiments (also used for category convergence analysis).
```bash
python3 experiments/run_benchmarking.py --dataset=MNIST --fname=f --K=5 --iters=3
python3 experiments/run_benchmarking.py --dataset=fMNIST --fname=f --K=5 --iters=3
python3 experiments/run_benchmarking.py --dataset=cMNIST --fname=f --K=5 --iters=3
python3 experiments/run_benchmarking.py --dataset=ImageNet --fname=ResNet18 --K=5 --iters=3 --batch_size=50 --start_idx_fixed=100 --end_idx_fixed=150 --reverse_order=False --folder=benchmarks_imagenet/ --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
```
**Application**: Run hyperparameter optimisation experiment.
```bash
python3 experiments/run_hp.py --dataset=MNIST --K=3 --iters=2 --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_hp.py --dataset=ImageNet --K=3 --iters=2 --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
```
**Experiment**: Run the faithfulness ranking disagreement exercise.
```bash
python3 experiments/run_ranking.py --dataset=cMNIST --fname=f --K=5 --iters=3 --category=Faithfulness --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
```
**Sanity-Check**: Run sanity-checking exercise: adversarial estimators.
```bash
python3 experiments/run_sanity_checks.py --dataset=ImageNet --K=3 --iters=2 --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
```
**Sanity-Check**: Run sanity-checking exercise: L dependency.
```bash
python3 experiments/run_l_dependency.py --dataset=MNIST --K=5 --iters=3 --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_l_dependency.py --dataset=fMNIST --K=5 --iters=3 --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_l_dependency.py --dataset=cMNIST --K=5 --iters=3 --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
```
**Benchmarking Transformers**: Run transformer benchmarking experiment.
```bash
python3 experiments/run_benchmarking_transformers.py --dataset=ImageNet --K=5 --iters=3 --start_idx=0 --end_idx=40 --category=localisation --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_benchmarking_transformers.py --dataset=ImageNet --K=5 --iters=3 --start_idx=40 --end_idx=80 --category=localisation --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_benchmarking_transformers.py --dataset=ImageNet --K=5 --iters=3 --start_idx=80 --end_idx=120 --category=localisation --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_benchmarking_transformers.py --dataset=ImageNet --K=5 --iters=3 --start_idx=120 --end_idx=160 --category=localisation --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
```
```bash
python3 experiments/run_benchmarking_transformers.py --dataset=ImageNet --K=5 --iters=3 --start_idx=40 --end_idx=80 --category=complexity --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_benchmarking_transformers.py --dataset=ImageNet --K=5 --iters=3 --start_idx=0 --end_idx=40 --category=complexity --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_benchmarking_transformers.py --dataset=ImageNet --K=5 --iters=3 --start_idx=80 --end_idx=120 --category=complexity --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
python3 experiments/run_benchmarking_transformers.py --dataset=ImageNet --K=5 --iters=3 --start_idx=120 --end_idx=160 --category=complexity --PATH_ASSETS=../assets/ --PATH_RESULTS=results/
```
Note. For all steps, please make sure to adjust any local paths so that the approriate files can be retrieved. Make sure to have all the necessary packages installed as well as ensure to have GPUs enabled throughout the computing as this will speed up the experimentation considerably. Also, note that the results may vary slightly depending on the random seed and other hyperparameters of the experiments. Nonetheless, the overall trends and conclusions should remain the same as in the paper.
Currently, the experiments are limited to the following experimental combinations:
* XAI methods: any method provided by querying quantus.AVAILABLE_XAI_METHODS_CAPTUM
* XAI metrics: any metric provided by querying quantus.AVAILABLE_METRICS
* Models: any PyTorch model (i.e., torch.nn.module)
* Datasets: MNIST, fMNSIT, cMNIST and ImageNet
Please feel free to raise an Issue if you'd like to extend these set-ups.
Owner
- Name: Anna Hedström
- Login: annahedstroem
- Kind: user
- Location: Berlin, Germany
- Twitter: anna_hedstroem
- Repositories: 29
- Profile: https://github.com/annahedstroem
ML PhD student @TU-Berlin
Citation (CITATION)
GitHub Events
Total
- Watch event: 9
Last Year
- Watch event: 9
Committers
Last synced: over 3 years ago
All Time
- Total Commits: 124
- Total Committers: 1
- Avg Commits per committer: 124.0
- Development Distribution Score (DDS): 0.0
Top Committers
| Name | Commits | |
|---|---|---|
| annahedstroem | a****m@t****e | 124 |
Committer Domains (Top 20 + Academic)
Issues and Pull Requests
Last synced: 10 months ago
All Time
- Total issues: 3
- Total pull requests: 6
- Average time to close issues: 4 months
- Average time to close pull requests: 14 days
- Total issue authors: 1
- Total pull request authors: 1
- Average comments per issue: 0.67
- Average comments per pull request: 0.33
- Merged pull requests: 4
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 0
- Pull requests: 0
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Issue authors: 0
- Pull request authors: 0
- Average comments per issue: 0
- Average comments per pull request: 0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
- annahedstroem (3)
Pull Request Authors
- annahedstroem (7)
Top Labels
Issue Labels
Pull Request Labels
Packages
- Total packages: 1
-
Total downloads:
- pypi 31 last-month
- Total dependent packages: 0
- Total dependent repositories: 0
- Total versions: 5
- Total maintainers: 1
pypi.org: metaquantus
MetaQuantus is a XAI performance tool for identifying reliable metrics.
- Homepage: https://github.com/annahedstroem/MetaQuantus
- Documentation: https://metaquantus.readthedocs.io/
- License: GNU LESSER GENERAL PUBLIC LICENSE VERSION 3
-
Latest release: 0.0.5
published almost 3 years ago