git-yolov11
Science Score: 49.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
✓DOI references
Found 3 DOI reference(s) in README -
✓Academic publication links
Links to: arxiv.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (3.2%) to scientific vocabulary
Repository
Basic Info
- Host: GitHub
- Owner: LPZ-SY
- License: agpl-3.0
- Language: Python
- Default Branch: main
- Size: 238 MB
Statistics
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
- Releases: 0
Metadata Files
README.md
YOLOv11
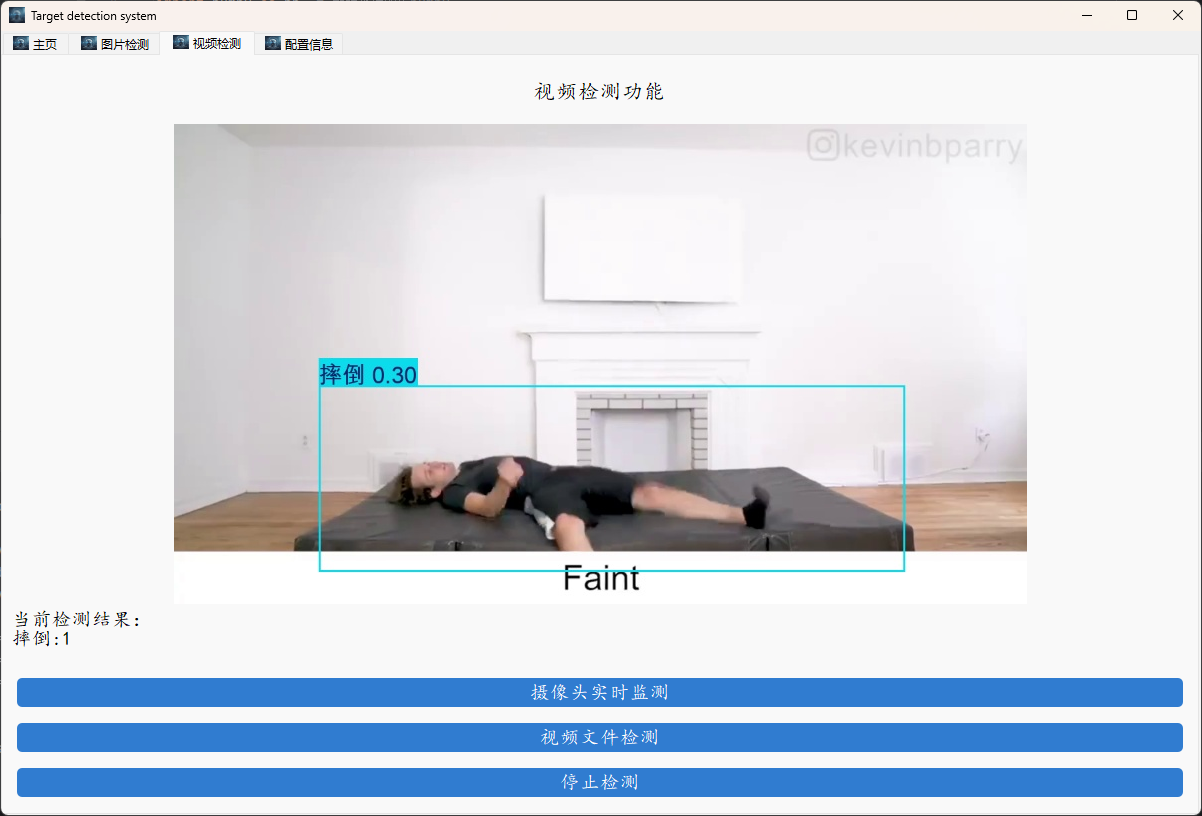
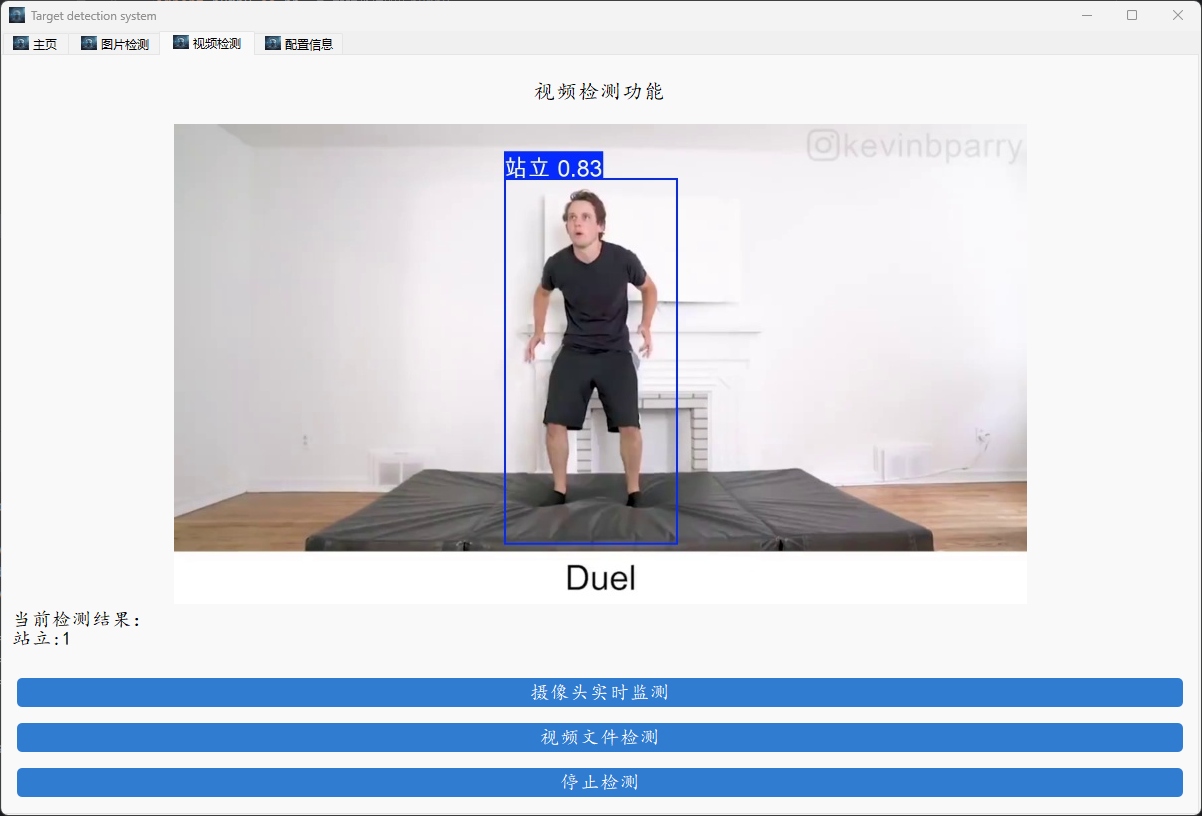
pytorchminiconda
bash
conda create -n yolo python==3.8.5
conda activate yolo
pytorch
bash
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # Pytorchcuda
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30gpupytorch
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 #
bash
pip install -v -e .
pycharmpycharm
yolo
block.pyconv.pyse
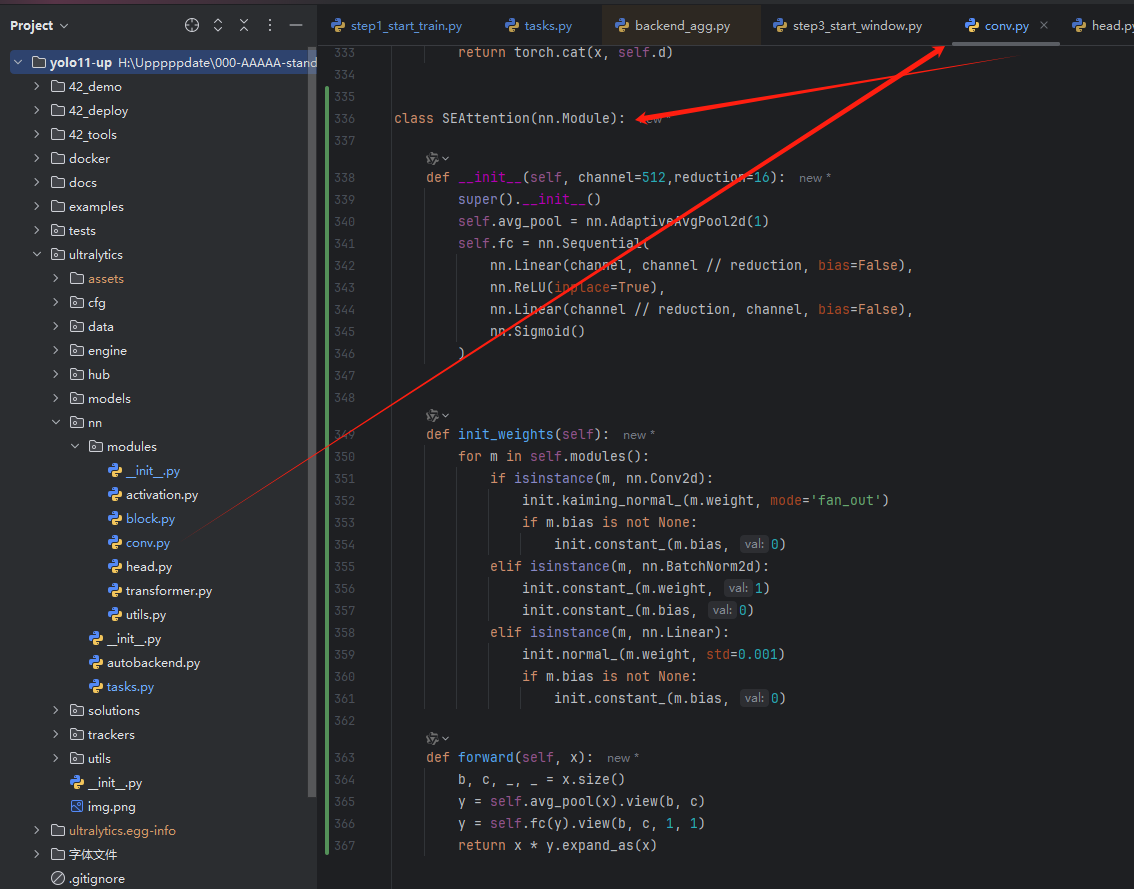
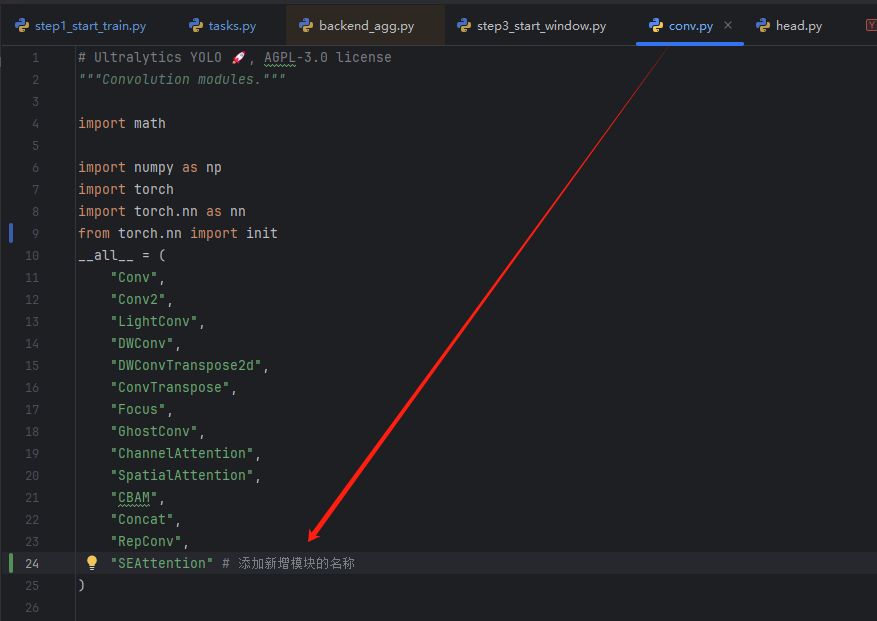
init.py
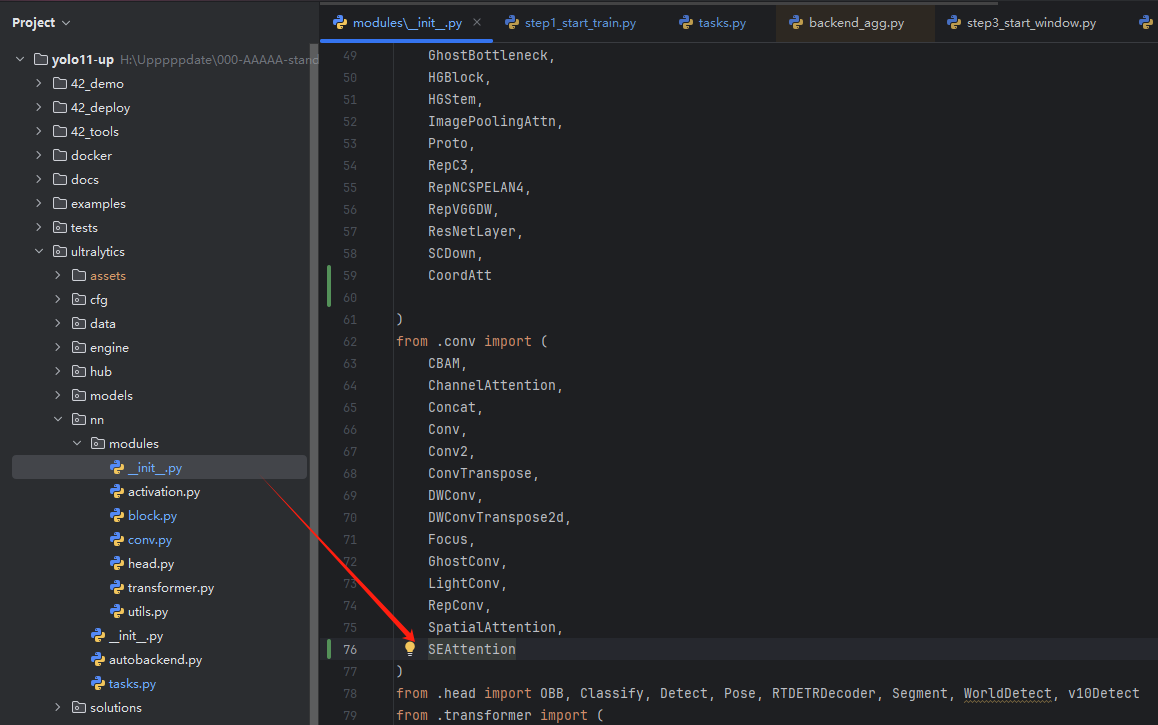
task.py
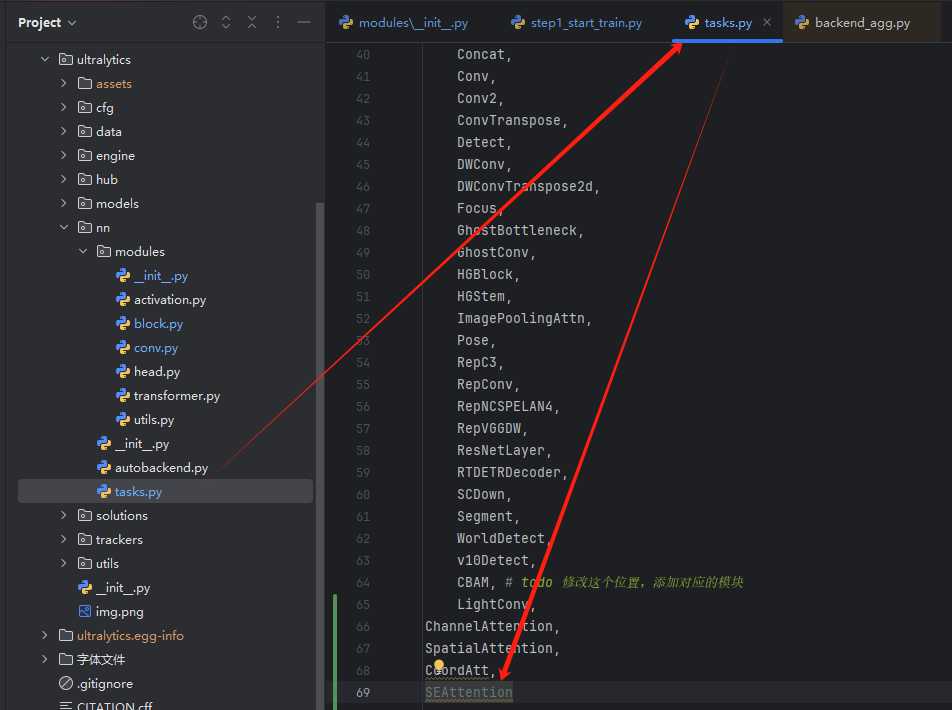
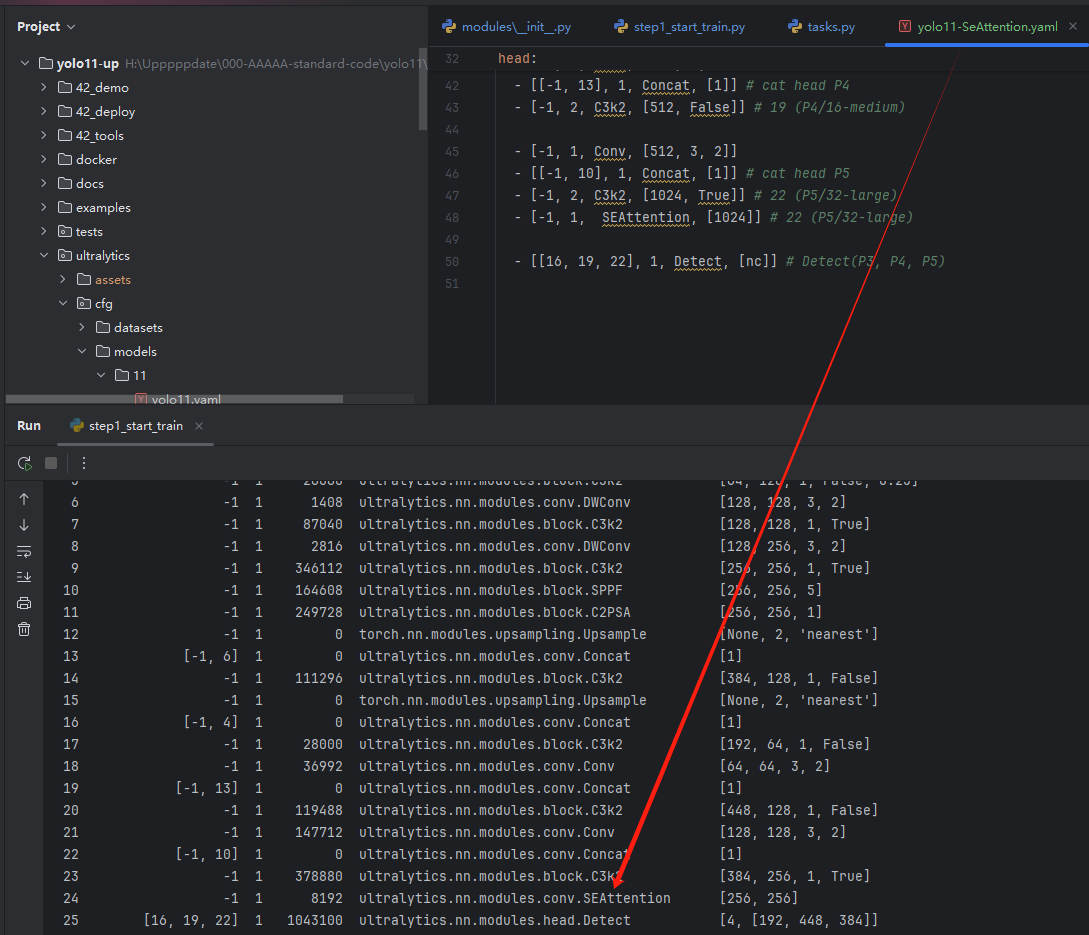
2-CBAM: Convolutional Block Attention Module
[1807.06521] CBAM: Convolutional Block Attention Module
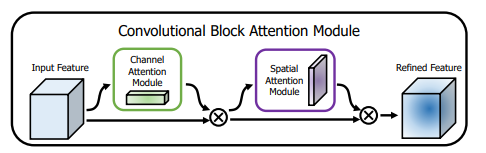
CBAMConvolutional Block Attention ModuleCBAM: Convolutional Block Attention ModuleECCV 2018CBAM Channel AttentionSpatial Attention
CBAM
** (Channel Attention Module)**:
** (Spatial Attention Module)**:
```python import torch import torch.nn as nn
class ChannelAttention(nn.Module): def init(self, in_channels, reduction=16): """
Args:
in_channels (int):
reduction (int):
"""
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) #
self.max_pool = nn.AdaptiveMaxPool2d(1) #
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
batch, channels, _, _ = x.size()
#
avg_out = self.fc(self.avg_pool(x).view(batch, channels))
#
max_out = self.fc(self.max_pool(x).view(batch, channels))
# Sigmoid
out = avg_out + max_out
out = self.sigmoid(out).view(batch, channels, 1, 1)
#
return x * out
class SpatialAttention(nn.Module): def init(self, kernel_size=7): """
Args:
kernel_size (int):
"""
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
#
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
combined = torch.cat([avg_out, max_out], dim=1) #
#
out = self.conv(combined)
out = self.sigmoid(out)
#
return x * out
class CBAM(nn.Module): def init(self, inchannels, reduction=16, kernelsize=7): """ CBAM Args: inchannels (int): reduction (int): kernelsize (int): """ super(CBAM, self).init() self.channelattention = ChannelAttention(inchannels, reduction) self.spatialattention = SpatialAttention(kernelsize)
def forward(self, x):
#
x = self.channel_attention(x)
#
x = self.spatial_attention(x)
return x
```
mapprstep2_start_val.py
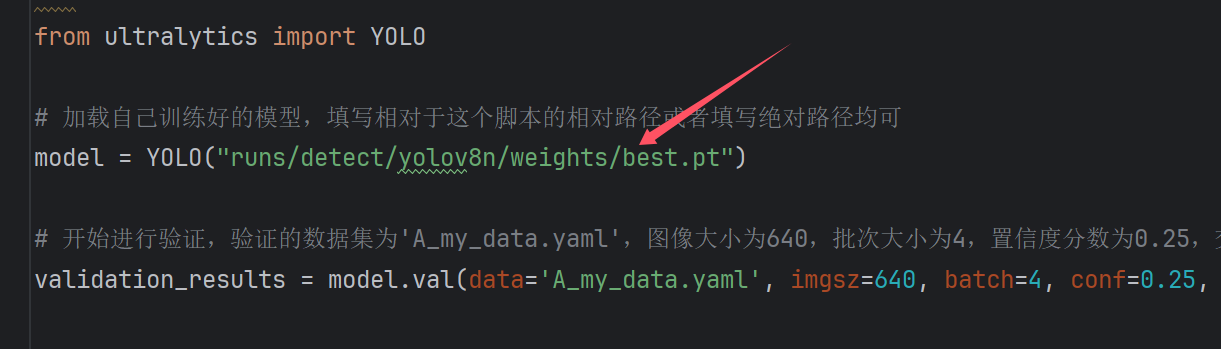
pyside6PySide6 PythonQt 6PythonQt GUIPySide6 Python Qt 6 PythonQt 6step3_start_window_track.py

logo
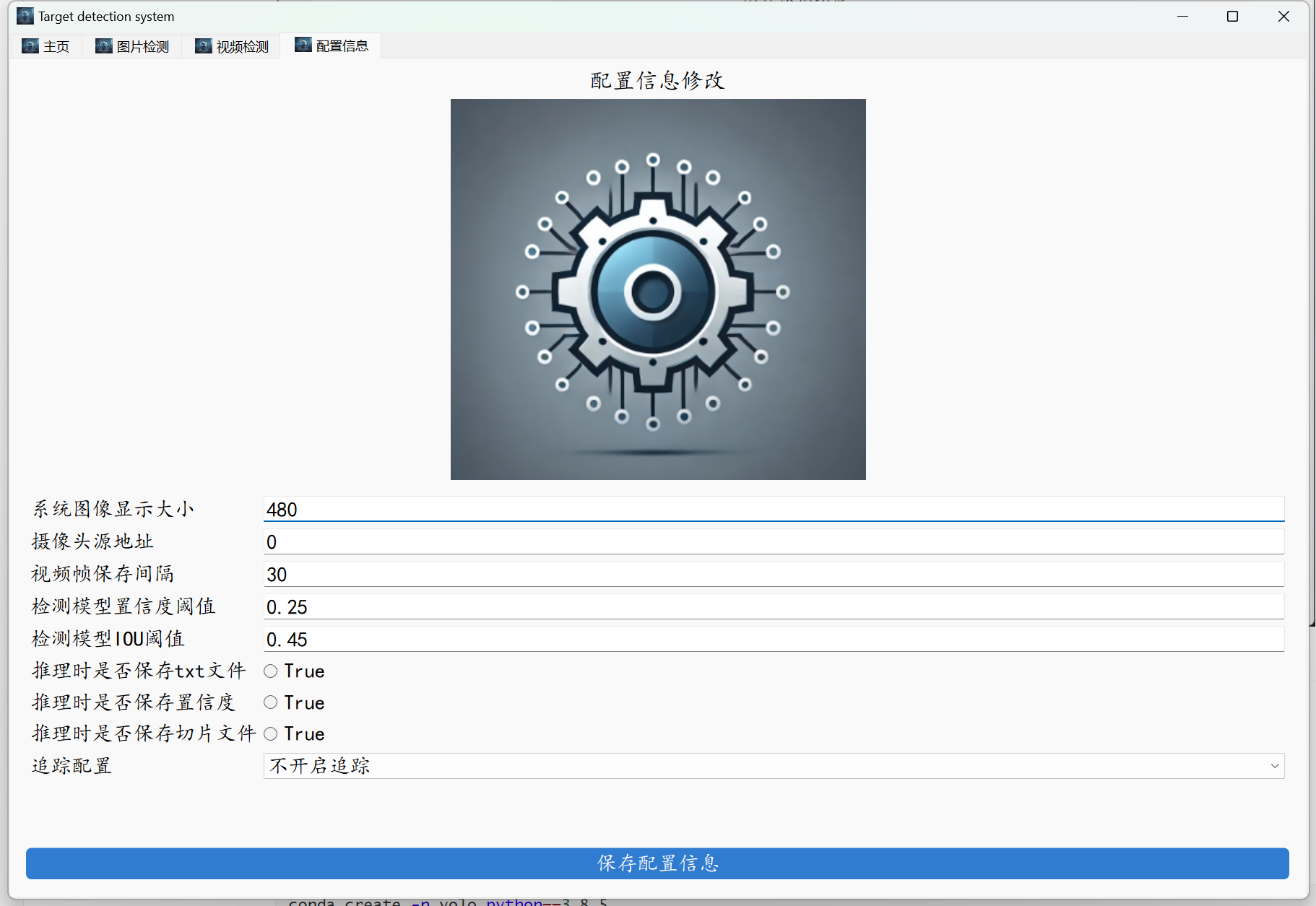
webpythonweb_demo.pygradiogradio
```python
!/usr/bin/env python
-- coding: UTF-8 --
'''
@Project step3startwindowtrack.py
@File webdemo.py
@IDE PyCharm
@Author
@Description TODO
@Date 2025/3/2
'''
import gradio as gr
import PIL.Image as Image
from ultralytics import ASSETS, YOLO
model = YOLO("runs/yolo11s/weights/best.pt")
def predictimage(img, confthreshold, iouthreshold): """Predicts objects in an image using a YOLO11 model with adjustable confidence and IOU thresholds.""" results = model.predict( source=img, conf=confthreshold, iou=iouthreshold, showlabels=True, show_conf=True, imgsz=640, )
for r in results:
im_array = r.plot()
im = Image.fromarray(im_array[..., ::-1])
return im
iface = gr.Interface( fn=predict_image, inputs=[ gr.Image(type="pil", label="Upload Image"), gr.Slider(minimum=0, maximum=1, value=0.25, label="Confidence threshold"), gr.Slider(minimum=0, maximum=1, value=0.45, label="IoU threshold"), ], outputs=gr.Image(type="pil", label="Result"), title="YOLO11", description="Upload images for inference.", # examples=[ # [ASSETS / "bus.jpg", 0.25, 0.45], # [ASSETS / "zidane.jpg", 0.25, 0.45], # ], )
if name == "main": # iface.launch(share=True) # iface.launch(share=True) iface.launch() ```
YOLOYou Only Look OnceYOLOYOLO
YOLOYOLO
YOLOYou Only Look Once YOLO
*YOLO *
YOLO R-CNN YOLO YOLO
YOLOv1 YOLO YOLOv2YOLOv3YOLOv4YOLOv5 YOLOv4 YOLO
*YOLO *
YOLOYOLOYou Only Look OnceYOLO
YOLOCNNYOLO
YOLO
YOLOYou Only Look OnceJoseph Redmon2015R-CNNYOLOYOLO
YOLOYOLO
YOLO
YOLO
- [Yang et al., 2019] YOLOYOLOv3YOLOv3
- [Zhou et al., 2020] YOLORGBYOLO
- [Zhang et al., 2021] YOLOYOLO
- [Gong et al., 2021] YOLOv4YOLOv4YOLOv4YOLOv3
yoloyolo1111
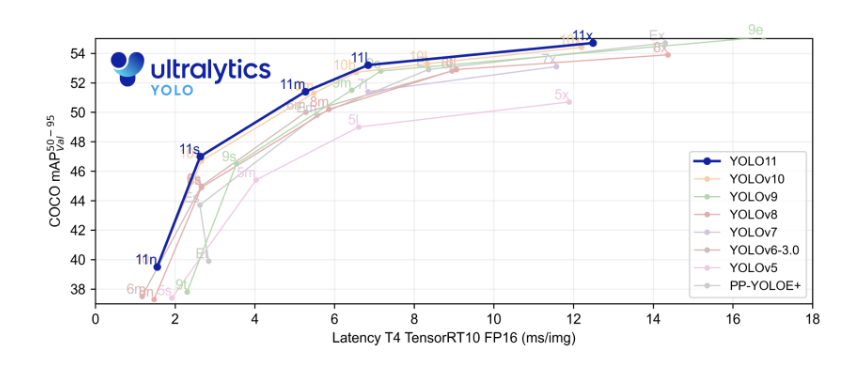
YOLOYOLO11YOLOv81yolo11yolo11
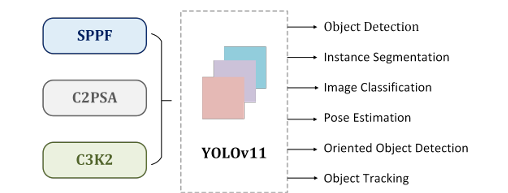
YOLOv11CVYOLOYOLOv11()CVYOLOv11
100
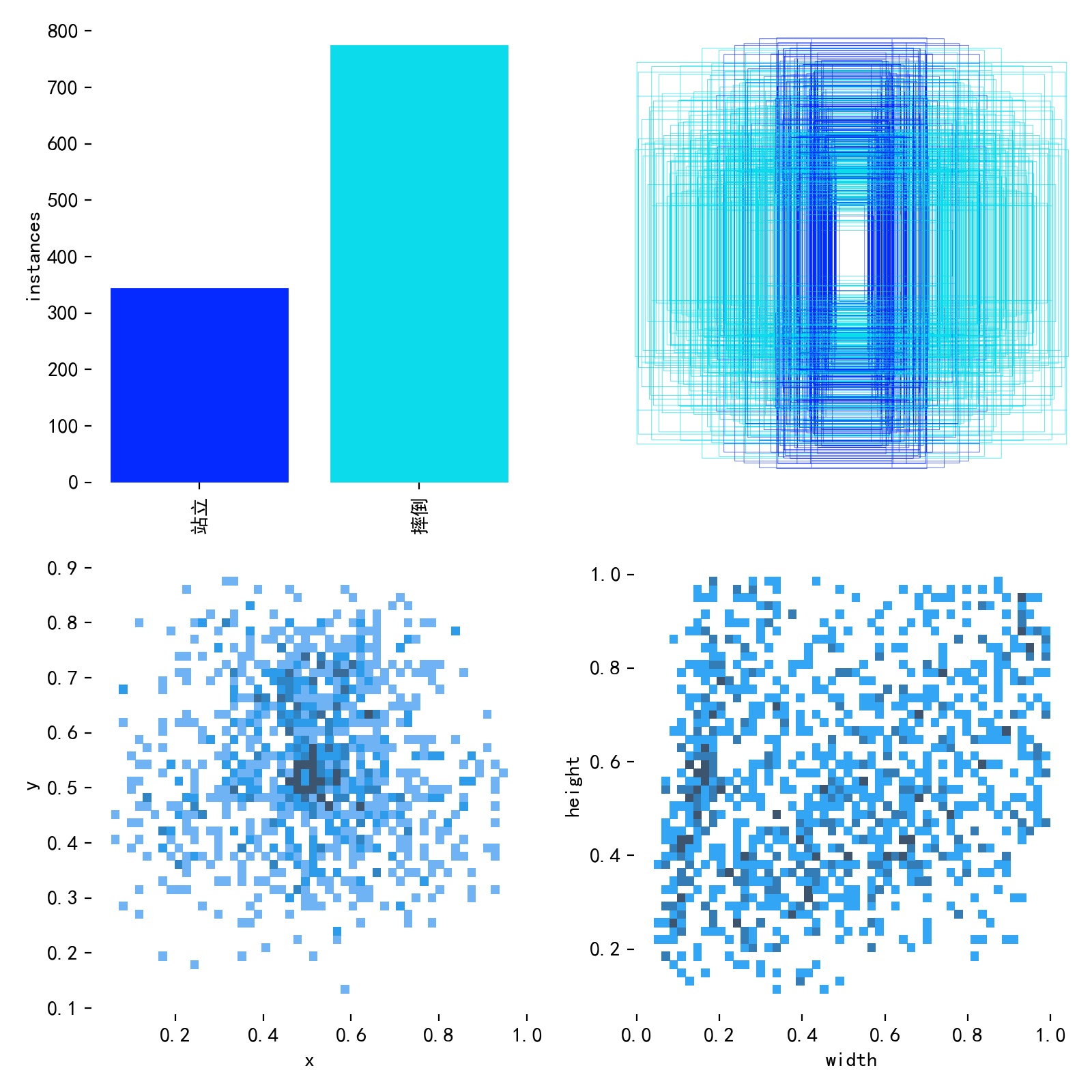
yolo
```yaml
Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: F:/bbbtemp/31-shuaidao/fallingdata train: # train images (relative to 'path') 16551 images - images/train val: # val images (relative to 'path') 4952 images - images/val test: # test images (optional) - images/test
names: [ '', '',]
```

runs
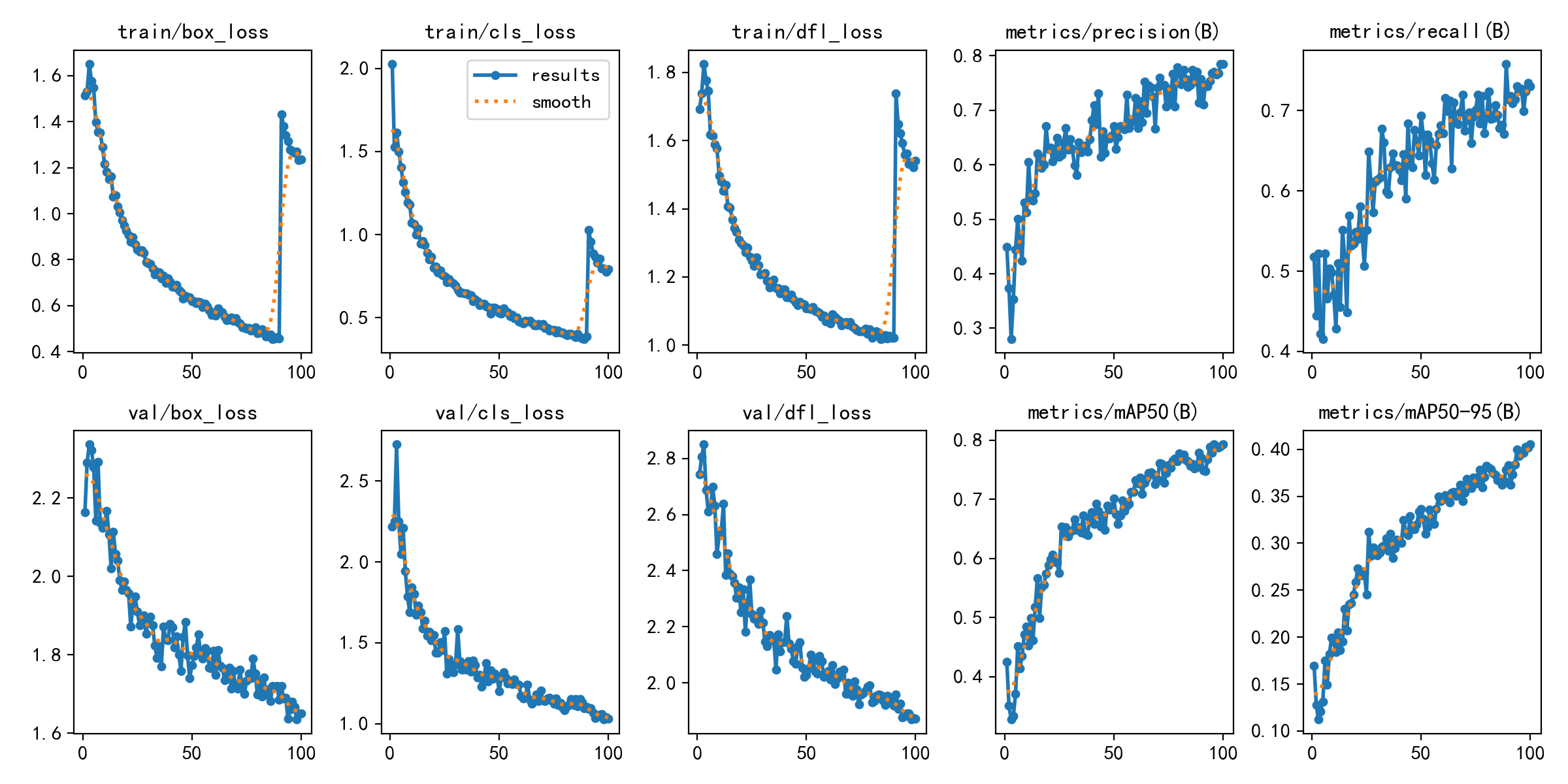
train/boxloss train/clsloss train/dflloss metrics/precision(B) metrics/recall(B) val/boxloss val/clsloss val/dflloss metrics/mAP50(B)IoU0.5mAP50 metrics/mAP50-95(B)IoU0.50.95mAP50-95IoU
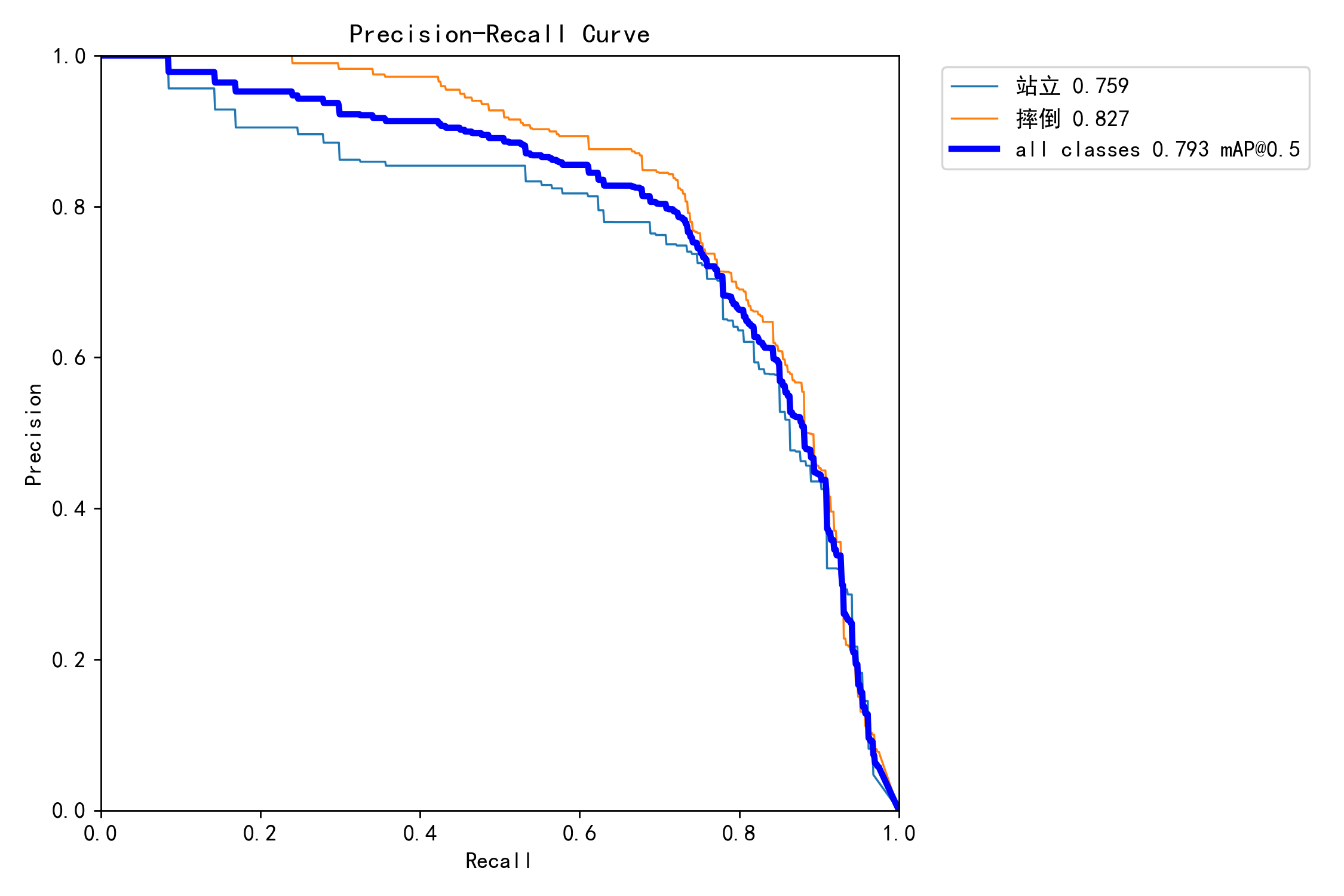
iou0.5map79.3%
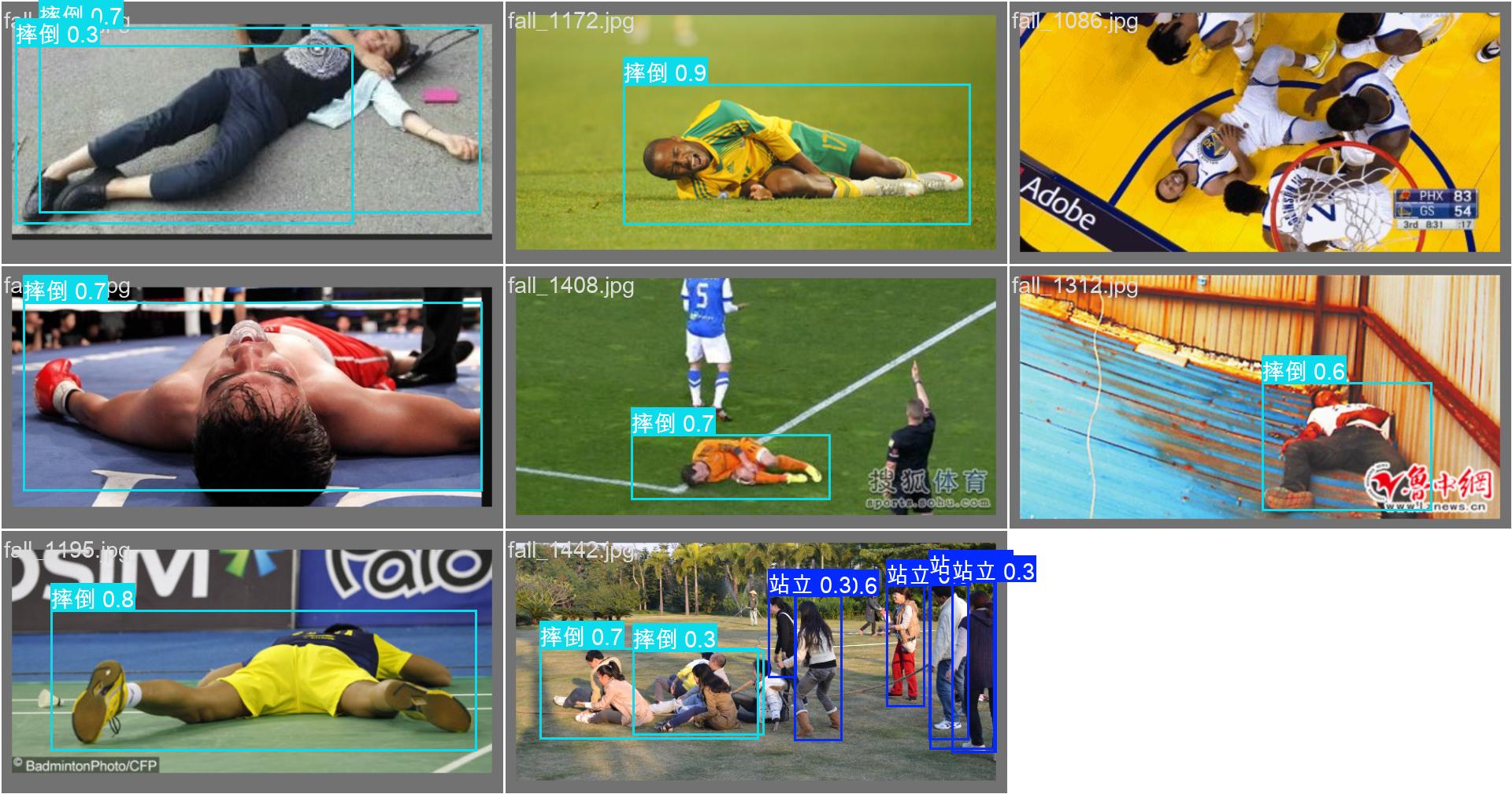
YOLOYOLOYOLO
YOLOYOLO
YOLO
YOLOYOLO
[1] Sharma, A., Kumar, R., & Gupta, S. (2018). "Deep Learning for Smoking Detection in Video Surveillance Systems". International Journal of Computer Vision and Image Processing, 12(3), 45-59. DOI: 10.1007/ijcvip.2018.12345
[2] Zhou, Z., Li, X., & Wu, Y. (2019). "Real-Time Smoking Detection via Video Analysis Using Deep Learning". Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 23-30. DOI: 10.1109/CVPR.2019.00008
[3] Yu, Q., Wu, S., & Wang, Y. (2020). "Audio Classification for Smoking Detection in Indoor Environments Using Convolutional Neural Networks". IEEE Access, 8, 23254-23262. DOI: 10.1109/ACCESS.2020.2973568
[4] Zhou Q , Yu C . Point RCNN: An Angle-Free Framework for Rotated Object Detection[J]. Remote Sensing, 2022, 14.
[5] Zhang, Y., Li, H., Bu, R., Song, C., Li, T., Kang, Y., & Chen, T. (2020). Fuzzy Multi-objective Requirements for NRP Based on Particle Swarm Optimization. International Conference on Adaptive and Intelligent Systems.
[6] Li X , Deng J , Fang Y . Few-Shot Object Detection on Remote Sensing Images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021(99).
[7] Su W, Zhu X, Tao C, et al. Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information[J]. arXiv preprint arXiv:2211.09807, 2022.
[8] Chen Q, Wang J, Han C, et al. Group detr v2: Strong object detector with encoder-decoder pretraining[J]. arXiv preprint arXiv:2211.03594, 2022.
[9] Liu, Shilong, et al. "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection." arXiv preprint arXiv:2303.05499 (2023).
[10] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[11] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271.
[12] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[13] Tian Z, Shen C, Chen H, et al. Fcos: Fully convolutional one-stage object detection[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 9627-9636.
[14] Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 801-818.
[15] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//Computer VisionECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 1114, 2016, Proceedings, Part I 14. Springer International Publishing, 2016: 21-37.
[16] Lin T Y, Dollr P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
[17] Cai Z, Vasconcelos N. Cascade r-cnn: Delving into high quality object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6154-6162.
[18] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28.
[19] Wang R, Shivanna R, Cheng D, et al. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems[C]//Proceedings of the web conference 2021. 2021: 1785-1797.
[20] Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[J]. arXiv preprint arXiv:1706.05587, 2017.
Owner
- Login: LPZ-SY
- Kind: user
- Repositories: 1
- Profile: https://github.com/LPZ-SY