Recent Releases of optuna
optuna - v4.5.0
This is the release note of v4.5.0.
Highlights
GPSampler for constrained multi-objective optimization
GPSampler is now able to handle multiple objective and constraints simultaneously using the newly introduced constrained LogEHVI acquisition function.
The figures below show the difference between GPSampler (LogEHVI, unconstrained) vs GPSampler (constrained LogEHVI, new feature). The 3-dimensional version of the C2DTLZ2 benchmark problem we used is a problem where some areas of the Pareto front of the original DTLZ2 problem are made infeasible by constraints. Therefore, even if constraints are not taken into account, it is possible to obtain the Pareto front. Experimental results show that both LogEHVI and constrained LogEHVI can approximate the Pareto front, but the latter has significantly fewer infeasible solutions, demonstrating its efficiency.
| Optuna v4.4 (LogEHVI) | Optuna v4.5 (Constrained LogEHVI) |
|:--:|:--:|
||
|
Significant speedup of TPESampler
TPESampler is significantly (about 5x as listed in the table below) faster! It enables a larger number of trials in each study. The speedup was achieved through a series of enhancements in constant factors.
The following table shows the speed comparison of TPESampler between v4.4.0 and v4.5.0. The experiments were conducted using multivariate=True on a search space with 3 continuous parameters and 3 numerical discrete parameters. Each row shows the runtime for each number of objectives and each column shows each number of trials to be evaluated. Each runtime is shown along with the standard error over 3 random seeds. The numbers in parentheses represent the speedup factor in comparison to v4.4.0. For example, (5.1x) means the runtime of v4.5.0 is 5.1 times faster than that of v4.4.0.
|n_objectives/n_trials|500|1000|1500|2000|
|:--:|:--:|:--:|:--:|:--:|
|1|1.4 $\pm$ 0.03 (5.1x)|3.9 $\pm$ 0.07 (5.3x)|7.3 $\pm$ 0.09 (5.4x)|11.9 $\pm$ 0.10 (5.4x)|
|2|1.8 $\pm$ 0.01 (4.7x)|4.7 $\pm$ 0.02 (4.8x)|8.7 $\pm$ 0.03 (4.8x)|13.9 $\pm$ 0.04 (4.9x)|
|3|2.0 $\pm$ 0.01 (4.2x)|5.4 $\pm$ 0.03 (4.4x)|10.0 $\pm$ 0.03 (4.6x)|15.9 $\pm$ 0.03 (4.7x)|
|4|4.2 $\pm$ 0.11 (3.2x)|12.1 $\pm$ 0.14 (3.9x)|20.9 $\pm$ 0.23 (4.2x)|31.3 $\pm$ 0.05 (4.4x)|
|5|12.1 $\pm$ 0.59 (4.7x)|30.8 $\pm$ 0.16 (5.8x)|50.7 $\pm$ 0.46 (6.5x)|72.8 $\pm$ 1.13 (7.1x)|
Significant speedup of plot_hypervolume_history
plot_hypervolume_history is essential to assess the performance of multi-objective optimization, but it was unbearably slow when a large number of trials are evaluated on a many-objective (The number of objectives > 3) problem. v4.5.0 addressed this issue by incrementally updating the hypervolume instead of calculating each hypervolume from scratch.
The following figure shows the elapsed times of hypervolume history plot in Optuna v4.4.0 and v4.5.0 using a four-objective problem. The x-axis represents the number of trials and the y-axis represents the elapsed times for each setup. The blue and red lines are the results of v4.4.0 and v4.5.0, respectively.
CmaEsSampler now supports 1D search space
Up until Optuna v4.4, CmaEsSampler could not handle one-dimensional space and fell back to random search. Optuna v4.5 now allows the CMA-ES algorithm to be used for one-dimensional space.
The optunahub library is available on conda-forge
Now, you can install the optunahub library via conda-forge as follows.
sh
conda install conda-forge::optunahub
New Features
- Add
ConstrainedLogEHVI(#6198) - Add support for constrained multi-objective optimization in
GPSampler(#6224) - Support 1D Search Spaces in
CmaEsSampler(#6228)
Enhancements
- Move
optuna._lightgbm_tunermodule (https://github.com/optuna/optuna-integration/pull/233, thanks @milkcoffeen!) - Fix numerical issue warning on
qehvi_candidates_func(https://github.com/optuna/optuna-integration/pull/242, thanks @LukeGT!) - Calculate hypervolume in HSSP using sum of contributions (#6130)
- Use hypervolume difference as upperbound of contribs in HSSP (#6131)
- Refactor
tell_with_warningto avoid unnecessaryget_trialcall (#6133) - Print fully qualified name of experimental function by default (#6162, thanks @ktns!)
- Include
scipy-stubsin the type-check dependencies (#6174, thanks @jorenham!) - Warn when
GPSamplerfalls back toRandomSampler(#6179, thanks @sisird864!) - Handle slowdown of
GPSamplerdue to L-BFGS in SciPy v1.15 (#6191) - Use the Newton method instead of bisect in
ndtri_exp(#6194) - Speed up erf for
TPESampler(#6200) - Avoid duplications in
_log_gauss_massevaluations (#6202) - Remove unnecessary NumPy usage (#6215)
- Use subset comparator to judge if trials are included in search space (#6218)
- Speed up log pdf in
_BatchedTruncNormDistributionsby vectorization (#6220) - Speed up WFG by skipping
is_pareto_frontand using simple Python loops (#6223) - Vectorize
ndtri_exp(#6229) - Speed up
plot_hypervolume_history(#6232) - Speed up HSSP 4D+ by using a decremental approach (#6234)
- Use
lru_cacheto skip HSSP (#6240, thanks @fusawa-yugo!) - Add hypervolume computation for a zero size array (#6245)
Bug Fixes
- Fix: Resolve PG17 incompatibility for ENUMS in CASE statements (#6099, thanks @vcovo!)
- Fix ill-combination of journal and gRPC (#6175)
- Fix a bug in constrained
GPSampler(#6181) - Fix
TPESamplerwithmultivariateandconstant_liar(#6189)
Installation
- Remove version constraint for torch with Python 3.13 (#6233)
Documentation
- Add missing spaces in error message about inconsistent intermediate values (https://github.com/optuna/optuna-integration/pull/239, thanks @Greesb!)
- Improve parallelization document (#6123)
- Add FAQ for case sensitivity problem with MySQL (#6127, thanks @fusawa-yugo!)
- Add an FAQ entry about specifying optimization parameters (#6157)
- Update link to survey (#6169)
- Add introduction of OptunaHub in docs (#6171, thanks @fusawa-yugo!)
- Add
GPSampleras a sampler that supports constraints (#6176, thanks @1kastner!) - Remove optuna-fast-fanova references from documentation (#6178)
- Fix stale docs in GP-related modules (#6184)
- Embed link to OptunaHub in documentation (#6192, thanks @fusawa-yugo!)
- Update
README.md(#6222, thanks @muhammadibrahim313!) - Add a note about unrelated changes in PR (#6226)
- Document the default evaluator in Optuna Dashboard (#6238)
Examples
- Add Spark example using ask-and-tell interface (https://github.com/optuna/optuna-examples/pull/328, thanks @dhyeyinf!)
Tests
- Fix
test_log_completed_trial_skip_storage_access(#6208)
Code Fixes
- Clean up GP-related docs (#6125)
- Refactor return style #6136 (#6151, thanks @unKnownNG!)
- Refactor
KernelParamsTensortowards cleaner GP-related modules (#6152) - Rename
KernelParamsTensortoGPRegressor(#6153) - Refactor returns in
v3.0.0.d.py(#6154, thanks @dross20!) - Refactor acquisition function minimally (#6166)
- Implement Type-Checking for
optuna/_imports.py(#6167, thanks @AdrianStrymer!) - Fix type checking in
optuna.artifacts._download.py(#6177, thanks @dross20!) - Integrate
is_categoricalto search space (#6182) - Fix type checking in
optuna.artifacts._list_artifact_meta.py(#6187, thanks @dross20!) - Introduce the independent sampling warning template (#6188)
- Use warning template for independent sampling in
GPSampler(#6195) - Refactor
SearchSpacein GP (#6197) - Refactor
_truncnorm(#6201) - Use
TYPE_CHECKINGinoptuna/_gp/acqf.pyto avoid circular imports (#6204, thanks @CarvedCoder!) - Use
TYPE_CHECKINGinoptuna/_gp/optim_mixed.pyto avoid circular imports (#6205, thanks @Subodh-12!) - Flip the sign of constraints in
GPSampler(#6213) - Implement NSGA-III using
BaseGASampler(#6219) - Replace
torch.newaxiswithNonefor old PyTorch (#6237)
Continuous Integration
- Fix CI (https://github.com/optuna/optuna-integration/pull/238)
- Add sklearn version constraint (https://github.com/optuna/optuna-integration/pull/243)
- Fix
READMEforblackdoc==0.3.10(#6150) - Fix CI (#6161)
- Add
pytest-xdistto speed up the CI (#6170) - Delete
test_get_timeline_plot_with_killed_running_trials(#6210) - Fix fragile test
test_experimental(#6211) - Mark fragile test as
xfail(#6217) - Add unit tests for constrained multi-objective
GPSampler(#6235) - Fix CI (#6246)
Other
- Update the example list in the
README(https://github.com/optuna/optuna-integration/pull/234, thanks @ParagEkbote!) - Bump up version number to
4.5.0.dev(https://github.com/optuna/optuna-integration/pull/237) - Bump up the version number to 4.5.0 (https://github.com/optuna/optuna-integration/pull/244)
- Bump up version number to v4.5.0.dev (#6149)
- Update News section in
README(#6159) - Bump up version to v4.5.0 (#6251)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@1kastner, @AdrianStrymer, @CarvedCoder, @Greesb, @HideakiImamura, @LukeGT, @ParagEkbote, @Subodh-12, @c-bata, @contramundum53, @dhyeyinf, @dross20, @fusawa-yugo, @gen740, @hvy, @jorenham, @kAIto47802, @ktns, @milkcoffeen, @muhammadibrahim313, @nabenabe0928, @not522, @nzw0301, @sawa3030, @sisird864, @toshihikoyanase, @unKnownNG, @vcovo, @y0z
- Python
Published by y0z 10 months ago
optuna - v4.4.0
This is the release note of v4.4.0.
Highlights
In addition to new features, bug fixes, and improvements in documentation and testing, version 4.4 introduces a new tool called the Optuna MCP Server.
Optuna MCP Server
The Optuna MCP server can be accessed by any MCP client via uv — for instance, with Claude Desktop, simply add the following configuration to your MCP server settings file. Of course, other LLM clients like VSCode or Cline can also be used similarly. You can also access it via Docker. If you want to persist the results, you can use the — storage option. For details, please refer to the repository.
{
"mcpServers": {
… (Other MCP Servers' settings)
"Optuna": {
"command": "uvx",
"args": [
"optuna-mcp"
]
}
}
}
Gaussian Process-Based Multi-objective Optimization
Optuna’s GPSampler, introduced in version 3.6, offers superior speed and performance compared to existing Bayesian optimization frameworks, particularly when handling objective functions with discrete variables. In Optuna v4.4, we have extended this GPSampler to support multi-objective optimization problems. The applications of multi-objective optimization are broad, and the new multi-objective capabilities introduced in this GPSampler are expected to find applications in fields such as material design, experimental design problems, and high-cost hyperparameter optimization.
GPSampler can be easily integrated into your program and performs well against the existing BoTorchSampler. We encourage you to try it out with your multi-objective optimization problems.
python
sampler = optuna.samplers.GPSampler()
study = optuna.create_study(directions=["minimize", "minimize"], sampler=sampler)
New Features in OptunaHub
During the development period of Optuna v4.4, several new features were also introduced to OptunaHub, the feature-sharing platform for Optuna:
- A sampler utilizing Google Vizier is now newly available.
- The CMA-ES-based sampler with restart strategy, which was previously part of the Optuna core, has been migrated to OptunaHub, making it simpler and more user-friendly.
- A benchmark problem solving aircraft design as a black-box optimization task has been added, further enhancing the convenience of algorithm development using OptunaHub.
- A visualization feature has also been added, allowing users to see how the acquisition function of the default TPESampler evolves as trials progress.
- A novel mutation operation has been added to the MOEA/D evolutionary computation algorithm for multi-objective optimization.
| Vizier sampler performance |
| --- |
| |
| TPE acquisition visualizer |
| --- |
| |
Breaking Changes
- Update
consider_priorBehavior and Remove Support forFalse(#6007) - Remove
restart_strategyandinc_popsizeto simplifyCmaEsSampler(#6025) - Make all arguments of
TPESamplerkeyword-only (#6041)
New Features
- Add a module to preprocess solutions for hypervolume improvement calculation (#6039)
- Add
AcquisitionFuncParamsfor LogEHVI (#6052) - Support Multi-Objective Optimization
GPSampler(#6069) - Add
n_recent_trialstoplot_timeline(#6110, thanks @msdsm!)
Enhancements
- Adapt
TYPE_CHECKINGofsamplers/_gp/sampler.py(#6059) - Avoid deepcopy in
_tell_with_warning(#6079) - Add
_compute_3dfor hypervolume computation (#6112, thanks @shmurai!) - Improve performance of
plot_hypervolume_history(#6115, thanks @shmurai!) - add deprecated/removed version specification to calls of
convert_positional_args(#6117, thanks @shmurai!) - Optimize
Study.best_trialperformance by avoiding unnecessary deep copy (#6119, thanks @msdsm!) - Refactor and speed up HV3D (#6124)
- Add
assume_paretofor hv calculation in_calculate_weights_below_for_multi_objective(#6129)
Bug Fixes
- Update vsbx (#6033, thanks @hrntsm!)
- Fix
request.valuesinOptunaStorageProxyService(#6044, thanks @hitsgub!) - Fix a bug in distributed optimization using NSGA-II/III (#6066, thanks @leevers!)
- Fix: fetch all trials in
BruteForceSamplerforHyperbandPruner(#6107)
Documentation
- Add Pycma Example (https://github.com/optuna/optuna-integration/pull/226, thanks @ParagEkbote!)
- Add SHAP Example (https://github.com/optuna/optuna-integration/pull/227, thanks @ParagEkbote!)
- Document Behavior of
optuna.pruners.MedianPrunerandoptuna.pruners.PatientPruner(#6055, thanks @ParagEkbote!) - Change the link of tutorial docs of optunahub (#6063, thanks @fusawa-yugo!)
- Update the documentation string of
GPSampler(#6081) - Add a warning about the combination of gRPC Proxy and Journal Storage (#6097)
- Cosmetic fix to the terminator documents (#6100)
- Note in docstring that heartbeat mechanism is experimental (#6111, thanks @lan496!)
- Update docstrings of
_get_best_trialto follow coding conventions (#6122)
Examples
- Add Example for Comet (https://github.com/optuna/optuna-examples/pull/305, thanks @ParagEkbote!)
- Adding an OpenML example (https://github.com/optuna/optuna-examples/pull/310, thanks @SubhadityaMukherjee!)
- Add workflow dispatch (https://github.com/optuna/optuna-examples/pull/311)
- Update PyTorch Checkpoint Example using tempfile (https://github.com/optuna/optuna-examples/pull/313, thanks @ParagEkbote!)
- [hotfix] Fix Dask-ML example by adding the version constraint on numpy (https://github.com/optuna/optuna-examples/pull/315)
- Setup Pre-Commit (https://github.com/optuna/optuna-examples/pull/316, thanks @ParagEkbote!)
- Remove Python 3.9 from haiku CI (https://github.com/optuna/optuna-examples/pull/318)
- Add a transformers example (https://github.com/optuna/optuna-examples/pull/322, thanks @ParagEkbote!)
- Add transformer item to
RAEDME.md(https://github.com/optuna/optuna-examples/pull/323) - Remove version constraints of
tensorflowandnumpy(https://github.com/optuna/optuna-examples/pull/324) - Update pre-commit hooks (https://github.com/optuna/optuna-examples/pull/326, thanks @lan496!)
- Add preferential optimization picture (https://github.com/optuna/optuna-examples/pull/327, thanks @milkcoffeen!)
Tests
- Add float precision tests for storages (#6040)
- Refactor
test_base_gasampler.py(#6104) - chore: run tests for importance only with in-memory (#6109)
- Improve test cases for
n_recent_trialsofplot_timeline(follow-up #6110) (#6116) - Performance optimization for
test_study.pyby removing redundancy (#6120)
Code Fixes
- Optional mypy check (#6028)
- Update Type-Checking for
optuna/_experimental.py(#6045, thanks @ParagEkbote!) - Update Type-Checking for
optuna/importance/_base.py(#6046, thanks @ParagEkbote!) - Update Type-Checking for
optuna/_convert_positional_args.py(#6050, thanks @ParagEkbote!) - Update Type-Checking for
optuna/_deprecated.py(#6051, thanks @ParagEkbote!) - Update Type-Checking for
optuna/_gp/gp.py(#6053, thanks @ParagEkbote!) - Add validate
etain sbx (#6056, thanks @hrntsm!) - Remove
CmaEsAttrKeysand_attr_keysfor Simplification (#6068) - Replace
np.isnanwithmath.isnan(#6080) - Refactor warning handling of
_tell_with_warning(#6082) - Implement Type-Checking for
optuna/distributions.py(#6086, thanks @AdrianStrymer!) - Update TYPECHECKING for `optuna/gp/gp.py` (#6090, thanks @Samarthi!)
- Support mypy 1.16.0 (#6102)
- Emit
ExperimentalWarningif heartbeat is enabled (#6106, thanks @lan496!) - Simplify tuple return in
optuna/visualization/_terminator_improvement.py(#6139, thanks @Prashantdhaka23!) - Refactor return standardization in
optim_mixed.py(#6140, thanks @Ajay-Satish-01!) - Simplify tuple return in
test_trial.py(#6141, thanks @saishreyakumar!) - Refactor return statement style in
optuna/storages/_rdb/models.pyfor consistency among the codebase (#6143, thanks @Shubham05122002!)
Continuous Integration
- Add type ignore in
wandb(https://github.com/optuna/optuna-integration/pull/228) - Fix to prevent daily
checks-optionalCI on the fork repositories (#6103) - Fix CI (#6137)
- [hotfix] Add version constraint on
blackdoc(#6145)
Other
- Bump up version number to v4.4.0.dev (https://github.com/optuna/optuna-integration/pull/220)
- Add pre commit config (https://github.com/optuna/optuna-integration/pull/231, thanks @milkcoffeen!)
- Bump up version number to 4.4.0 (https://github.com/optuna/optuna-integration/pull/236)
- Bump up version to 4.4.0dev (#6038)
- Update the news section in README.md (#6049)
- Fix README for v5 roadmap (#6094)
- Update pre-commit hooks (#6108, thanks @lan496!)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@AdrianStrymer, @Ajay-Satish-01, @Alnusjaponica, @Copilot, @HideakiImamura, @ParagEkbote, @Prashantdhaka23, @Samarthi, @Shubham05122002, @SubhadityaMukherjee, @c-bata, @contramundum53, @copilot-pull-request-reviewer[bot], @fusawa-yugo, @gen740, @himkt, @hitsgub, @hrntsm, @kAIto47802, @lan496, @leevers, @milkcoffeen, @msdsm, @nabenabe0928, @not522, @nzw0301, @saishreyakumar, @sawa3030, @shmurai, @toshihikoyanase, @y0z
- Python
Published by HideakiImamura about 1 year ago
optuna - v4.3.0
This is the release note of v4.3.0.
Highlights
This has various bug fixes and improvements to the documentation and more.
Breaking Changes
- [fix] lgbm 4.6.0 compatibility (https://github.com/optuna/optuna-integration/pull/207, thanks @ffineis!)
Enhancements
- Accept custom objective in
LightGBMTuner(https://github.com/optuna/optuna-integration/pull/203, thanks @sawa3030!) - Improve time complexity of
IntersectionSearchSpace(#5982, thanks @GittyHarsha!) - Add
_prev_waiting_trial_numberinInMemoryStorageto improve the efficiency of_pop_waiting_trial_id(#5993, thanks @sawa3030!) - Add arguments of versions to
convert_positional_args(#6009, thanks @fusawa-yugo!) - Add
wait_server_readymethod in GrpcStorageProxy (#6010, thanks @hitsgub!) - Remove warning messages for Matplotlib-based
plot_contourandplot_rank(#6011) - Fix type checking in
optuna._callbacks.py(#6030) - Enhance
SBXCrossover(#6008, thanks @hrntsm!)
Bug Fixes
- Convert storage into
InMemoryStoragebefore copying to the local (https://github.com/optuna/optuna-integration/pull/213) - Fix contour plot of
matplotlib(#5892, thanks @fusawa-yugo!) - Fix threading lock logic (#5922)
- Use
_LazyImportfor grpcio package (#5954) - Prevent Lock Blocking by Adding Timeout to
JournalStorage(#5971, thanks @sawa3030!) - Fix a minor bug in GPSampler for objective that returns
inf(#5995) - Fix a bug that a gRPC server doesn't work with JournalStorage (#6004, thanks @fusawa-yugo!)
- Fix
_pop_waiting_trial_idfor finished trial (#6012) - Resolve the issue where
BruteForceSamplerfails to suggest all combinations (#5893)
Documentation
- Follow recent changes in
optuna/optuna's document sphinx config (https://github.com/optuna/optuna-integration/pull/197) - Fix links to external modules (https://github.com/optuna/optuna-integration/pull/198)
- Update
CONTRIBUTING.md(https://github.com/optuna/optuna-integration/pull/200, thanks @sawa3030!) - Update comment in
.readthedocs.yml(#5976) - Add comments on the reproducibility of
HyperBandPruner(#6018)
Examples
- [hotfix] Add the version constraint on
dask(https://github.com/optuna/optuna-examples/pull/296) - [hotfix] Add the version constraint on
daskfordask-ml(https://github.com/optuna/optuna-examples/pull/297) - Extends execution span of
hiplotandsklearn(https://github.com/optuna/optuna-examples/pull/298, thanks @fusawa-yugo!) - Apply black to fix CI (https://github.com/optuna/optuna-examples/pull/300)
- Bump up to 3.12 for CI (https://github.com/optuna/optuna-examples/pull/301)
- [hotfix] Add the version constraint on
lightgbm(https://github.com/optuna/optuna-examples/pull/302) - Fix Skorch Example (https://github.com/optuna/optuna-examples/pull/303, thanks @ParagEkbote!)
- Add version constraint for tensorflow-related CI (https://github.com/optuna/optuna-examples/pull/304)
- Temporarily skip Python 3.9 in fastai example (https://github.com/optuna/optuna-examples/pull/308)
- Run the
skorchexample in the CI (https://github.com/optuna/optuna-examples/pull/309) - Fix
fastaiExample (https://github.com/optuna/optuna-examples/pull/312)
Tests
- Use
JournalStorageintest_cli.py(#5990, thanks @sawa3030!)
Code Fixes
- Add
BaseGASampler(#5864) - Fix comments in
pyproject.toml(#5972) - Remove
FirstTrialOnlyRandomSampler(#5973, thanks @mehakmander11!) - Remove
_check_and_set_param_distribution(#5975, thanks @siddydutta!) - Remove
testing/distributions.py(#5977, thanks @mehakmander11!) - Remove
_StudyInfo'sparam_distributionin_cached_storage.py(#5978, thanks @tarunprabhu11!) - Introduce
UpdateFinishedTrialErrorto raise an error when attempting to modify a finished trial (#6001, thanks @sawa3030!) - Deprecate
consider_priorinTPESampler(#6005, thanks @sawa3030!) - Improve Code Readability by Following PEP8 Standards (#6006, thanks @sawa3030!)
- Made error message for
create_study's direction easier to understandoptuna.study(#6021, thanks @sinano1107!)
Continuous Integration
- Hotfix ci (https://github.com/optuna/optuna-integration/pull/199)
- Add flake8 in CI (https://github.com/optuna/optuna-integration/pull/201, thanks @sawa3030!)
- Remove test cases that uses
UnsupportedDistribution(https://github.com/optuna/optuna-integration/pull/208) - Fix a mypy error when using
numpy>=2.2.4(https://github.com/optuna/optuna-integration/pull/212) - Fix a bug of
lightgbmtuner for Python 3.8 users (https://github.com/optuna/optuna-integration/pull/214) - Add a version constraint on
xgboost(https://github.com/optuna/optuna-integration/pull/217) - Run (https://github.com/optuna/optuna-integration/pull/218)
- Ensure gRPC server readiness before proceeding to prevent test failures (#5938, thanks @sawa3030!)
- Apply black to fix CI (#5952)
- Add
workflow_dispatchtrigger to all the CI (#6019) - Fix CI (#6026)
Other
- Bump up version number to 4.3.0.dev (https://github.com/optuna/optuna-integration/pull/192)
- Bump the version up to v4.2.1 (https://github.com/optuna/optuna-integration/pull/195)
- Set repository url (https://github.com/optuna/optuna-integration/pull/196, thanks @ktns!)
- Bump up version number to v4.3.0 (https://github.com/optuna/optuna-integration/pull/221)
- Bump the version up to v4.3.0.dev (#5927)
- Add the article to the news section (#5928)
- Update news section for 4.2.0 release (#5934)
- Update News (#5936)
- Update README with the new blog entry (#5980)
- Add
GPSamplerblog to the announcement (#6014) - Add grpc blog to README (#6020)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Alnusjaponica, @GittyHarsha, @HideakiImamura, @ParagEkbote, @c-bata, @contramundum53, @ffineis, @fusawa-yugo, @gen740, @hitsgub, @hrntsm, @kAIto47802, @ktns, @mehakmander11, @nabenabe0928, @not522, @nzw0301, @porink0424, @sawa3030, @siddydutta, @sinano1107, @tarunprabhu11, @toshihikoyanase, @y0z
- Python
Published by y0z about 1 year ago
optuna - v4.2.1
This is the release note of v4.2.1. This release includes a bug fix addressing an issue where Optuna was unable to import if an older version of the grpcio package was installed.
Bug
- [backport] Use
_LazyImportfor grpcio package (#5965)
Other
- Bump up version number to v4.2.1 (#5964)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions. @c-bata @HideakiImamura @nabenabe0928
- Python
Published by c-bata over 1 year ago
optuna - v4.2.0
This is the release note of v4.2.0. In conjunction with the Optuna release, OptunaHub 0.2.0 is released. Please refer to the release note of OptunaHub 0.2.0 for more details.
Highlights of this release include:
- 🚀gRPC Storage Proxy for Scalable Hyperparameter Optimization
- 🤖 SMAC3: Support for New State-of-the-art Optimization Algorithm by AutoML.org (@automl)
- 📁 OptunaHub Now Supports Benchmark Functions
- 🧑💻 Gaussian Process-Based Bayesian Optimization with Inequality Constraints
- 🧑💻 c-TPE: Support Constrained TPESampler
Highlights
gRPC Storage Proxy for Scalable Hyperparameter Optimization
The gRPC storage proxy is a feature designed to support large-scale distributed optimization. As shown in the diagram below, gRPC storage proxy sits between the optimization workers and the database server, proxying the calls of Optuna’s storage APIs.
In large-scale distributed optimization settings where hundreds to thousands of workers are operating, placing a gRPC storage proxy for every few tens can significantly reduce the load on the RDB server which would otherwise be a single point of failure. The gRPC storage proxy enables sharing the cache about Optuna studies and trials, which can further mitigate load. Please refer to the official documentation for further details on how to utilize gRPC storage proxy.
SMAC3: Random Forest-Based Bayesian Optimization Developed by AutoML.org
SMAC3 is a hyperparameter optimization framework developed by AutoML.org, one of the most influential AutoML research groups. The Optuna-compatible SMAC3 sampler is now available thanks to the contribution to OptunaHub by Difan Deng (@dengdifan), one of the core members of AutoML.org. We can now use the method widely used in AutoML research and real-world applications from Optuna.
```python
pip install optunahub smac
import optuna import optunahub from optuna.distributions import FloatDistribution
def objective(trial: optuna.Trial) -> float: x = trial.suggestfloat("x", -10, 10) y = trial.suggestfloat("y", -10, 10) return x2 + y2
smacmod = optunahub.loadmodule("samplers/smacsampler") ntrials = 100 sampler = smacmod.SMACSampler( {"x": FloatDistribution(-10, 10), "y": FloatDistribution(-10, 10)}, ntrials=ntrials, ) study = optuna.createstudy(sampler=sampler) study.optimize(objective, ntrials=ntrials) ```
Please refer to https://hub.optuna.org/samplers/smac_sampler/ for more details.
OptunaHub Now Supports Benchmark Functions
Benchmarking the performance of optimization algorithms is an essential process indispensable to the research and development of algorithms. The newly added OptunaHub Benchmarks in the latest version v0.2.0 of optunahub is a new feature for Optuna users to conduct benchmarks conveniently.
```python
pip install optunahub>=4.2.0 scipy torch
import optuna import optunahub
bbobmod = optunahub.loadmodule("benchmarks/bbob") smacmod = optunahub.loadmodule("samplers/smacsampler") sphere2d = bbobmod.Problem(function_id=1, dimension=2)
ntrials = 100 studies = [] for studyname, sampler in [ ("random", optuna.samplers.RandomSampler(seed=1)), ("tpe", optuna.samplers.TPESampler(seed=1)), ("cmaes", optuna.samplers.CmaEsSampler(seed=1)), ("smac", smacmod.SMACSampler(sphere2d.searchspace, ntrials, seed=1)), ]: study = optuna.createstudy(directions=sphere2d.directions, sampler=sampler, studyname=studyname) study.optimize(sphere2d, ntrials=ntrials) studies.append(study)
optuna.visualization.plotoptimizationhistory(studies).show() ```
In the above sample code, we compare and display the performance of the four kinds of samplers using a two-dimensional Sphere function, which is part of a group of benchmark functions widely used in the black-box optimization research community known as Blackbox Optimization Benchmarking (BBOB).
Gaussian Process-Based Bayesian Optimization with Inequality Constraints
We worked on its extension and adapted GPSampler to constrained optimization in Optuna v4.2.0 since Gaussian process-based Bayesian optimization is a very popular method in various research fields such as aircraft engineering and materials science. We show the basic usage below.
```python
pip install optuna>=4.2.0 scipy torch
import numpy as np import optuna
def objective(trial: optuna.Trial) -> float: x = trial.suggestfloat("x", 0.0, 2 * np.pi) y = trial.suggestfloat("y", 0.0, 2 * np.pi) c = float(np.sin(x) * np.sin(y) + 0.95) trial.setuserattr("c", c) return float(np.sin(x) + y)
def constraints(trial: optuna.trial.FrozenTrial) -> tuple[float]: return (trial.user_attrs["c"],)
sampler = optuna.samplers.GPSampler(constraintsfunc=constraints) study = optuna.createstudy(sampler=sampler) study.optimize(objective, n_trials=50) ```
Please try out GPSampler for constrained optimization especially when only a small number of trials are available!
c-TPE: Support Constrained TPESampler
Although Optuna has supported constrained optimization for TPESampler, which is the default Optuna sampler, since v3.0.0, its algorithm design and performance comparison have not been verified academically. OptunaHub now supports c-TPE, which is another constrained optimization method for TPESampler. Importantly, the algorithm design and its performance comparison are publicly reviewed to be accepted to IJCAI, a top-tier AI international conference. Please refer to https://hub.optuna.org/samplers/ctpe/ for details.
New Features
- Enable
GPSamplerto support constraint functions (#5715) - Update output format options in CLI to include the
valuechoice (#5822, thanks @iamarunbrahma!) - Add gRPC storage proxy server and client (#5852)
Enhancements
- Introduce client-side cache in
GrpcStorageProxy(#5872)
Bug Fixes
- Fix CI (https://github.com/optuna/optuna-integration/pull/185)
- Fix ticks in Matplotlib contour plot (#5778, thanks @sulan!)
- Adding check in
cli.pyto handle an empty database (#5828, thanks @willdavidson05!) - Avoid the input validation fail in Wilcoxon signed ranked test for Scipy 1.15 (#5912)
- Fix the default sampler of
load_studyfunction (#5924)
Documentation
- Update OptunaHub example in README (#5763)
- Update
distributions.rstto list deprecated distribution classes (#5764) - Remove deprecation comment for
stepinIntLogUniformDistribution(#5767) - Update requirements for OptunaHub in README (#5768)
- Use inline code rather than italic for
step(#5769) - Add notes to
ask_and_telltutorial - batch optimization recommendations (#5817, thanks @SimonPop!) - Fix the explanation of returned values of
get_trial_params(#5820) - Introduce
sphinx-notfound-pagefor better 404 page (#5898) - Follow-up #5872: Update the docstring of
run_grpc_proxy_server(#5914) - Modify doc-string of gRPC-related modules (#5916)
Examples
- Adapt docker recipes to Python 3.11 (https://github.com/optuna/optuna-examples/pull/292)
- Add version constraint for
wandb(https://github.com/optuna/optuna-examples/pull/293)
Tests
- Add unit tests for
retry_historymethod inRetryFailedTrialCallback(#5865, thanks @iamarunbrahma!) - Add tests for value format in CLI (#5866)
- Import grpc lazy to fix the CI (#5878)
Code Fixes
- Fix annotations for
distributions.py(#5755, thanks @KannanShilen!) - Simplify type annotations for
tests/visualization_tests/test_pareto_front.py(#5756, thanks @boringbyte!) - Fix type annotations for
test_hypervolume_history.py(#5760, thanks @boringbyte!) - Simplify type annotations for
tests/test_cli.py(#5765, thanks @boringbyte!) - Simplify type annotations for
tests/test_distributions.py(#5773, thanks @boringbyte!) - Simplify type annotations for
tests/samplers_tests/test_qmc.py(#5775, thanks @boringbyte!) - Simplify type annotations for
tests/sampler_tests/tpe_tests/test_sampler.py(#5779, thanks @boringbyte!) - Simplify type annotations for
tests/samplers_tests/tpe_tests/test_multi_objective_sampler.py(#5781, thanks @boringbyte!) - Simplify type annotations for
tests/samplers_tests/tpe_tests/test_parzen_estimator.py(#5782, thanks @boringbyte!) - Simplify type annotations for
tests/storage_tests/journal_tests/test_journal.py(#5783, thanks @boringbyte!) - Simplify type annotations for
tests/storage_tests/rdb_tests/create_db.py(#5784, thanks @boringbyte!) - Simplify type annotations for
tests/storage_tests/rdb_tests/(#5785, thanks @boringbyte!) - Simplify type annotations for
tests/test_deprecated.py(#5786, thanks @boringbyte!) - Simplify type annotations for
tests/test_convert_positional_args.py(#5787, thanks @boringbyte!) - Simplify type annotations for
tests/importance_tests/test_init.py(#5790, thanks @boringbyte!) - Simplify type annotations for
tests/storages_tests/test_storages.py(#5791, thanks @boringbyte!) - Simplify type annotations for
tests/storages_tests/test_heartbeat.py(#5792, thanks @boringbyte!) - Simplify type annotations
optuna/cli.py(#5793, thanks @willdavidson05!) - Simplify type annotations for
tests/trial_tests/test_frozen.py(#5794, thanks @boringbyte!) - Simplify type annotations for
tests/trial_tests/test_trial.py(#5795, thanks @boringbyte!) - Simplify type annotations for
tests/trial_tests/test_trials.py(#5796, thanks @boringbyte!) - Refactor some funcs in NSGA-III (#5798)
- Simplify type annotations
optuna/_transform.py(#5799, thanks @JLX0!) - Make the assertion messages in
test_trial.pyreadable (#5800) - Simplify type annotations for
tests/pruners_tests/test_hyperband.py(#5801, thanks @boringbyte!) - Simplify type annotations for
tests/pruners_tests/test_median.py(#5802, thanks @boringbyte!) - Simplify type annotations for
tests/pruners_tests/test_patient.py(#5803, thanks @boringbyte!) - Use
study.ask()in tests instead ofcreate_new_trial(#5807, thanks @unKnownNG!) - Simplify type annotations for
tests/pruners_tests/test_percentile.py(#5808, thanks @boringbyte!) - Simplify type annotations for
tests/pruners_tests/test_successive_halving.py(#5809, thanks @boringbyte!) - Simplify type annotations for
tests/study_tests/test_optimize.py(#5810, thanks @boringbyte!) - Simplify type annotations for
tests/hypervolume_tests/test_hssp.py(#5812, thanks @boringbyte!) - Refactor the MOTPE split (#5813)
- Simplify type annotations for
optuna/_callbacks.py(#5818, thanks @boringbyte!) - Simplify type annotations for
optuna/samplers/_random.py(#5819, thanks @boringbyte!) - Simplify type annotations for
optuna/samplers/_gp/sampler.py(#5823, thanks @boringbyte!) - Simplify type annotations for
optuna/samplers/nsgaii/_crossovers/_sbx.py(#5824, thanks @boringbyte!) - Simplify type annotations for
optuna/samplers/nsgaii/_crossovers/_spx.py(#5825, thanks @boringbyte!) - Simplify type annotations for
optuna/samplers/nsgaii/_crossovers/_undx.py(#5826, thanks @boringbyte!) - Simplify type annotations for
optuna/samplers/nsgaii/_crossovers/_vsbx.py(#5827, thanks @boringbyte!) - Simplify type annotations for
optuna/samplers/nsgaii/_crossover.py(#5831, thanks @boringbyte!) - Simplify type annotations for
optuna/samplers/testing/threading.py(#5832, thanks @boringbyte!) - Simplify type annotations for
optuna/pruners/_patient.py(#5833, thanks @boringbyte!) - Use
study.ask()intests/pruners_tests/test_percentile.py(#5834, thanks @fusawa-yugo!) - Simplify type annotations for
optuna/search_space/group_decomposed.py(#5836, thanks @boringbyte!) - Simplify type annotations for
optuna/search_space/intersection.py(#5837, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/journal/_base.py(#5838, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/journal/_redis.py(#5840, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/journal/_storage.py(#5841, thanks @boringbyte!) - Simplify type annotations for
optuna/study/_dataframe.py(#5842, thanks @boringbyte!) - Fix logger.warn() deprecation warning in GP module (#5843, thanks @iamarunbrahma!)
- Simplify type annotations for
optuna/study/_optimize.py(#5844, thanks @boringbyte!) - Simplify type annotations for
optuna/study/_tell.py(#5845, thanks @boringbyte!) - Fix
mypyerrors due tonumpy2.2.0 (#5848) - Simplify type annotations for
optuna/visualization/matplotlib/_contour.py(#5851, thanks @boringbyte!) - Refactor the fix for MyPy errors due to NumPy v2.2.0 (#5853)
- Simplify type annotations for
optuna/visualization/matplotlib/_parallel_coordinate.py(#5854, thanks @boringbyte!) - Simplify type annotations for
optuna/visualization/matplotlib/_param_importances.py(#5855, thanks @boringbyte!) - Use
study.ask()intests/pruners_tests/test_successive_halving.py(#5856, thanks @willdavidson05!) - Simplify type annotations for
optuna/visualization/matplotlib/_pareto_front.py(#5857, thanks @boringbyte!) - Simplify type annotations for
optuna/visualization/matplotlib/_rank.py(#5858, thanks @boringbyte!) - Simplify type annotations for
optuna/visualization/matplotlib/_slice.py(#5859, thanks @boringbyte!) - Refactor plot contour (#5867)
- Refactor MOTPE weighting (#5871)
- Simplify type annotations for
optuna/visualization/_utils.py(#5876, thanks @boringbyte!) - Simplify type annotations for
optuna/visualization/_contour.py(#5877, thanks @boringbyte!) - Simplify type annotations for
optuna/_gp/gp.py(#5879, thanks @boringbyte!) - Simplify type annotations for
optuna/study/_tell.py(#5880, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/_heartbeat.py(#5882, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/_rdb/storage.py(#5883, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/_rdb/alembic/versions/v3.0.0.a.py(#5884, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/_rdb/alembic/versions/v3.0.0.c.py(#5885, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/_rdb/alembic/versions/v3.0.0.d.py(#5886, thanks @boringbyte!) - Simplify type annotations for
optuna/_deprecated.py(#5887, thanks @boringbyte!) - Simplify type annotations for
optuna/_experimental.py(#5888, thanks @boringbyte!) - Simplify type annotations for
optuna/_imports.py(#5889, thanks @boringbyte!) - Simplify type annotations for
optuna/visualization/_slice.py(#5894, thanks @boringbyte!) - Simplify type annotations for
optuna/visualization/_parallel_coordinate.py(#5895, thanks @boringbyte!) - Simplify type annotations for
optuna/visualization/_rank.py(#5896, thanks @boringbyte!) - Simplify type annotations for
optuna/visualization/_param_importances.py(#5897, thanks @boringbyte!) - Simplify type annotations for
optuna/_callbacks.py(#5899, thanks @boringbyte!) - Simplify type annotations for
optuna/storages/journal/_file.py(#5900, thanks @boringbyte!) - Simplify type annotations for
tests/storages_tests/test_with_server.py(#5901, thanks @boringbyte!) - Simplify type annotations for
tests/test_multi_objective.py(#5902, thanks @boringbyte!) - Simplify type annotations for
tests/artifacts_tests/test_gcs.py(#5903, thanks @boringbyte!) - Simplify type annotations for
tests/samplers_tests/test_grid.py(#5904, thanks @boringbyte!) - Simplify type annotations for
optuna/study/_dataframe.py(#5905, thanks @boringbyte!) - Simplify type annotations for
tests/visualization_tests/test_optimization_history.py(#5906, thanks @boringbyte!) - Simplify type annotations for
tests/visualization_tests/test_intermediate_plot.py(#5907, thanks @boringbyte!) - Simplify type annotations for multiple test files in
tests/visualization_tests/(#5908, thanks @boringbyte!) - Avoid the port number conflict in the copy study tests (#5913)
- Simplify annotations in
tests/study_tests/test_study.py(#5923, thanks @sawa3030!)
Continuous Integration
- Fix a GitHub action workflow for publishing to PyPI (https://github.com/optuna/optuna-integration/pull/181)
- Fix CI by adding a version constraint (https://github.com/optuna/optuna-integration/pull/186)
- Rename
test_cache_is_invalidatedand removeassert study._thread_local.cached_all_trials is None(#5733) - Use Python 3.12 for docs build CI (#5742)
- Fix a GitHub action workflow for publishing to PyPI (#5759)
- Install older
kaleidoto fix CI errors (#5771) - Add Python 3.12 to the Docker image CI (#5789)
- Move
mypyrelated entries in setup.cfg topyproject.toml(#5861)
Other
- Bump up version number to v4.2.0.dev (https://github.com/optuna/optuna-integration/pull/178)
- Bump up version number to 4.2.0 (https://github.com/optuna/optuna-integration/pull/191)
- Add
CITATION.cff(#5746) - Update news to add the autosampler article (#5748)
- Bump the version up to v4.2.0.dev (#5752)
- Update the news section for Optuna 4.1 release (#5758)
- Update pre-commit configuration file (#5847)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@HideakiImamura, @JLX0, @KannanShilen, @SimonPop, @boringbyte, @c-bata, @fusawa-yugo, @gen740, @himkt, @iamarunbrahma, @kAIto47802, @ktns, @mist714, @nabenabe0928, @not522, @nzw0301, @porink0424, @sawa3030, @sulan, @unKnownNG, @willdavidson05, @y0z
- Python
Published by c-bata over 1 year ago
optuna - v4.1.0
This is the release note of v4.1.0. Highlights of this release include: - 🤖 AutoSampler: Automatic Selection of Optimization Algorithms - 🚀 More scalable RDB Storage Backend - 🧑💻 Five New Algorithms in OptunaHub (MO-CMA-ES, MOEA/D, etc.) - 🐍 Support Python 3.13
The updated list of tested and supported Python releases is as follows: - Optuna 4.1: supported by Python 3.8 - 3.13 - Optuna Integration 4.1: supported by Python 3.8 - 3.12 - Optuna Dashboard 0.17.0: supported by Python 3.8 - 3.13
Highlights
AutoSampler: Automatic Selection of Optimization Algorithms
AutoSampler automatically selects a sampler from those implemented in Optuna, depending on the situation. Using AutoSampler, as in the code example below, users can achieve optimization performance equal to or better than Optuna's default without being aware of which optimization algorithm to use.
$ pip install optunahub cmaes torch scipy
```python import optuna import optunahub
autosamplermodule = optunahub.loadmodule("samplers/autosampler") study = optuna.createstudy(sampler=autosampler_module.AutoSampler()) ```
See the Medium blog post for details.
Enhanced RDB Storage Backend
This release incorporates comprehensive performance tuning on Optuna’s RDBStorage, leading to significant performance improvements. The table below shows the comparison results of execution times between versions 4.0 and 4.1.
| # trials | v4.0.0 | v4.1.0 | Diff | | --- | --- | --- | --- | | 1000 | 72.461 sec (±1.026) | 59.706 sec (±1.216) | -17.60% | | 10000 | 1153.690 sec (±91.311) | 664.830 sec (±9.951) | -42.37% | | 50000 | 12118.413 sec (±254.870) | 4435.961 sec (±190.582) | -63.39% |
For fair comparison, all experiments were repeated 10 times, and the mean execution time was compared. Additional detailed benchmark settings include the following: - Objective Function: Each trial consists of 10 parameters and 10 user attributes - Storage: MySQL 8.0 (with PyMySQL) - Sampler: RandomSampler - Execution Environment: Kubernetes Pod with 5 cpus and 8Gi RAM
Please note, due to extensive execution time, the figure for v4.0.0 with 50,000 trials represents the average of 7 runs instead of 10.
Benchmark Script
```python import optuna import time import os import numpy as np optuna.logging.set_verbosity(optuna.logging.ERROR) storage_url = "mysql+pymysql://user:password@Five New Algorithms in OptunaHub (MO-CMA-ES, MOEA/D, etc.)
The following five new algorithms were added to OptunaHub!
- Multi-objective CMA-ES (MO-CMA-ES)by @y0z
- MOEA/D sampler by @hrntsm
- MAB Epsilon-Greedy Sampler by @ryota717
- NSGAII sampler with Initial Trials by @hrntsm
- CMA-ES with User Prior by @nabenabe0928
MO-CMA-ES is an extension of CMA-ES for multi-objective optimization. Its search mechanism is based on multiple (1+1)-CMA-ES and inherits good invariance properties from CMA-ES, such as invariance against rotation of the search space.
MOEA/D solves a multi-objective optimization problem by decomposing it into multiple single-objective problems. It allows for the maintenance of a good diversity of solutions during optimization. Please take a look at the article from Hiroaki NATSUME(@hrntsm) for more details.
Enhancements
- Update sklearn.py by addind catch to OptunaSearchCV (https://github.com/optuna/optuna-integration/pull/163, thanks @muhlbach!)
- Reduce
SELECTstatements by passingstudy_idtocheck_and_addinTrialParamModel(#5702) - Introduce
UPSERTinset_trial_user_attr(#5703) - Reduce
SELECTstatements of_CachedStorage.get_all_trialsby fixing filtering conditions (#5704) - Reduce
SELECTstatements by removing unnecessary distribution compatibility check inset_trial_param()(#5709) - Introduce
UPSERTinset_trial_system_attr(#5741)
Bug Fixes
- Accept
Mappingasparam_distributionsinOptunaSearchCV(https://github.com/optuna/optuna-integration/pull/172, thanks @yu9824!) - Allow use of
OptunaSearchCVwithcross_val_predict(https://github.com/optuna/optuna-integration/pull/174, thanks @yu9824!) - Fix
GPSampler's suggestion failure withintorch.no_grad()context manager (#5671, thanks @kAIto47802!) - Fix a concurrency issue in
GPSampler(#5737) - Fix a concurrency issue in
QMCSampler(#5740)
Installation
- Drop the support for Python 3.7 and update package metadata for Python 3.13 support (#5727)
- Remove dependency specifier for installing SciPy (#5736)
Documentation
- Add badges of PyPI and Conda Forge (https://github.com/optuna/optuna-integration/pull/167)
- Update news (#5655)
- Update news section in
README.md(#5657) - Add
InMemoryStorageto document (#5672, thanks @kAIto47802!) - Add the news about blog of
JournalStoragetoREADME.md(#5674) - Fix broken link in the artifacts tutorial (#5677, thanks @kAIto47802!)
- Add
pandasinstallation guide to RDB tutorial (#5685, thanks @kAIto47802!) - Add installation guide to multi-objective tutorial (#5686, thanks @kAIto47802!)
- Update document and notice interoperability between NSGA-II and Pruners (#5688)
- Fix typo in
EMMREvaluator(#5694) - Fix
RegretBoundEvaluatordocument (#5696) - Update news section in
README.md(#5705) - Add link to related blog post in
emmr.py(#5707) - Update FAQ entry for model preservation using Optuna Artifact (#5716, thanks @chitvs!)
- Escape
\Dfor Python 3.12 with sphinx build (#5735) - Avoid using functions in
sphinx_gallery_confto remove document build error with Python 3.12 (#5738) - Remove all
generateddirectories indocs/sourcerecursively (#5739) - Add information about
AutoSamplerto the docs (#5745)
Examples
- Update CI config for
fastai(https://github.com/optuna/optuna-examples/pull/279) - Introduce
optuna.artifactsto the PyTorch checkpoint example (https://github.com/optuna/optuna-examples/pull/280, thanks @kAIto47802!) - Fix inline code in README files in
kubernetesdirectory (https://github.com/optuna/optuna-examples/pull/282) - Test ray example with Python 3.12 (https://github.com/optuna/optuna-examples/pull/284)
- Add a link to molecule LLM notebook (https://github.com/optuna/optuna-examples/pull/285)
- Fix syntax error in YAML file of rapids CI (https://github.com/optuna/optuna-examples/pull/286)
- Another fix for syntax error in YAML file of rapids CI (https://github.com/optuna/optuna-examples/pull/287)
- Add checking for Python 3.12 (https://github.com/optuna/optuna-examples/pull/288, thanks @kAIto47802!)
- Add Python 3.12 to tfkeras CI and remove warning message (https://github.com/optuna/optuna-examples/pull/289)
- Add Python 3.12 to
lightgbmCI (https://github.com/optuna/optuna-examples/pull/290) - Remove Python 3.7 from the workflow (https://github.com/optuna/optuna-examples/pull/291)
Code Fixes
- Add a comment for an unexpected bug in
CategoricalDistribution(#5683) - Add more information about the hack in
WFG(#5687) - Simplify type annotations to
_imports.py(#5692, thanks @Prabhat-Thapa45!) - Use
__future__.annotationsinoptuna/_experimental.py(#5714, thanks @Jonathan43!) - Use
__future__.annotationsintests/importance_tests/fanova_tests/test_tree.py(#5731, thanks @guisp03!) - Resolve TODO comments related to dropping Python 3.7 support (#5734)
Continuous Integration
- Fix CI for
fastaiv2(https://github.com/optuna/optuna-integration/pull/164) - Fix for mypy (https://github.com/optuna/optuna-integration/pull/166)
- Fix mlflow integration for CI (https://github.com/optuna/optuna-integration/pull/168)
- Update CI to support Python 3.12 (https://github.com/optuna/optuna-integration/pull/170, thanks @kAIto47802!)
- Update artifact version to v4 (https://github.com/optuna/optuna-integration/pull/176)
- Add a tri-objective problem to speed benchmarking (#5635)
- Bump
actions/download-artifactfrom 2 to 4.1.7 in/.github/workflows(#5660) - Update MySQL version in CI from 5.7 to 8 (#5673)
- Remove performance benchmarks (#5675)
- Update PostgreSQL version in CI to latest (#5676)
- Update the version of Python used in the checks from 3.8 to 3.11 (#5684)
- Run tests with Python 3.13 (#5691)
- Fix for mypy (#5706)
- [hotfix] Add a version constraint on fakeredis (#5726)
- Update Python versions used in CI workflow (#5728)
- Update sphinx build's
upload-artifactversion (#5744)
Other
- Bump up version number to 4.1.0.dev (https://github.com/optuna/optuna-integration/pull/159)
- Update supported Python versions (https://github.com/optuna/optuna-integration/pull/175)
- Bump up to v4.1.0 (https://github.com/optuna/optuna-integration/pull/179)
- Add pre-commit config (#5408)
- Add link to MOEA/D blog post in News (#5719)
- Include all test files in
sdistby updatingMANIFEST.in(#5720)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@HideakiImamura, @Jonathan43, @Prabhat-Thapa45, @c-bata, @chitvs, @contramundum53, @eukaryo, @gen740, @guisp03, @kAIto47802, @muhlbach, @nabenabe0928, @not522, @nzw0301, @porink0424, @toshihikoyanase, @y0z, @yu9824
- Python
Published by c-bata over 1 year ago
optuna - v4.0.0
Here is the release note of v4.0.0. Please also check out the release blog post.
If you want to update the Optuna version of your existing projects to v4.0, please see the migration guide.
We have also published blog posts about the development items. Please check them out! - OptunaHub, a Feature-Sharing Platform for Optuna, Now Available in Official Release! - File Management during LLM (Large Language Model) Trainings by Optuna v4.0.0 Artifact Store - Significant Speed Up of Multi-Objective TPESampler in Optuna v4.0.0
Highlights
Official Release of Feature-Sharing Platform OptunaHub
We officially released OptunaHub, a feature-sharing platform for Optuna. A large number of optimization and visualization algorithms are available in OptunaHub. Contributors can easily register their methods and deliver them to Optuna users around the world.
Please also read the OptunaHub release blog post.
Enhanced Experiment Management Feature: Official Support of Artifact Store
Artifact Store is a file management feature for files generated during optimization, dubbed artifacts. In Optuna v4.0, we stabilized the existing file upload API and further enhanced the usability of Artifact Store by adding some APIs such as the artifact download API. We also added features to show JSONL and CSV files on Optuna Dashboard in addition to the existing support for images, audio, and video. With this official support, the API backward compatibility will be guaranteed.
For more details, please check the blog post.
JournalStorage: Official Support of Distributed Optimization via Network File System
JournalStorage is a new Optuna storage experimentally introduced in Optuna v3.1 (see the blog post for details). Optuna has JournalFileBackend, a storage backend for various file systems. It can be used on NFS, allowing Optuna to scale to multiple nodes.
In Optuna v4.0, the API for JournalStorage has been reorganized, and JournalStorage is officially supported. This official support guarantees its backward compatibility from v4.0. For details on the API changes, please refer to the Optuna v4.0 Migration Guide.
```python import optuna from optuna.storages import JournalStorage from optuna.storages.journal import JournalFileBackend
def objective(trial: optuna.Trial) -> float: ...
storage = JournalStorage(JournalFileBackend("./optunajournalstorage.log")) study = optuna.create_study(storage=storage) study.optimize(objective) ```
Significant Speedup of Multi-Objective TPESampler
Before v4.0, the multi-objective TPESampler sometimes limits the number of trials during optimization due to the sampler bottleneck after a few hundred trials. Optuna v4.0 drastically improves the sampling speed, e.g., 300 times faster for three objectives with 200 trials, and enables users to handle much more trials. Please check the blog post for details.
Introduction of a New Terminator Algorithm
Optuna Terminator was originally introduced for hyperparameter optimization of machine learning algorithms using cross-validation. To accept broader use cases, Optuna v4.0 introduced the Expected Minimum Model Regret (EMMR) algorithm. Please refer to the EMMREvaluator document for details.
Enhancements of Constrained Optimization
We have gradually expanded the support for constrained optimization. In v4.0, study.best_trial and study.best_trials start to support constraint optimization. They are guaranteed to satisfy the constraints, which was not the case previously.
Breaking Changes
Optuna removes deprecated features in major releases. To prevent users' code from suddenly breaking, we take a long interval between when a feature is deprecated and when it is removed. By default, features are removed when the major version has increased by two since the feature was deprecated. For this reason, the main target features for removal in v4.0 were deprecated at v2.x. Please refer to the migration guide for the removed features list.
- Delete deprecated three integrations,
skopt,catalyst, andfastaiv1(https://github.com/optuna/optuna-integration/pull/114) - Remove deprecated
CmaEsSamplerfrom integration (https://github.com/optuna/optuna-integration/pull/116) - Remove verbosity of
LightGBMTuner(https://github.com/optuna/optuna-integration/pull/136) - Move positional args of
LightGBMTuner(https://github.com/optuna/optuna-integration/pull/138) - Remove
multi_objective(#5390) - Delete deprecated
_askand_tell(#5398) - Delete deprecated
--direction(s)arguments in theaskcommand (#5405) - Delete deprecated three integrations,
skopt,catalyst, andfastaiv1(#5407) - Remove the default normalization of importance in f-ANOVA (#5411)
- Remove
samplers.intersection(#5414) - Drop implicit create-study in
askcommand (#5415) - Remove deprecated
study optimizeCLI command (#5416) - Remove deprecated
CmaEsSamplerfrom integration (#5417) - Support constrained optimization in
best_trial(#5426) - Drop
--studyincli.py(#5430) - Deprecate
constraints_funcinplot_pareto_frontfunction (#5455) - Rename some class names related to
JournalStorage(#5539) - Remove
optuna.samplers.MOTPESampler(#5640)
New Features
- Add Comet ML integration (https://github.com/optuna/optuna-integration/pull/63, thanks @caleb-kaiser!)
- Add Knowledge Gradient candidates functions (https://github.com/optuna/optuna-integration/pull/125, thanks @alxhslm!)
- Add
is_exhausted()function in theGridSamplerclass (#5306, thanks @aaravm!) - Remove experimental from plot (#5413)
- Implement
download_artifact(#5448) - Add a function to list linked artifact information (#5467)
- Stabilize artifact APIs (#5567)
- Stabilize
JournalStorage(#5568) - Add
EMMREvaluatorandMedianErrorEvaluator(#5602)
Enhancements
- Pass two arguments to the forward of
ConstrainedMCObjectiveto supportbotorch=0.10.0(https://github.com/optuna/optuna-integration/pull/106) - Speed up non-dominated sort (#5302)
- Make 2d hypervolume computation twice faster (#5303)
- Reduce the time complexity of HSSP 2d from
O(NK^2 log K)toO((N - K)K)(#5346) - Introduce lazy hypervolume calculations in HSSP for speedup (#5355)
- Make
plot_contourfaster (#5369) - Speed up
to_internal_reprinCategoricalDistribution(#5400) - Allow users to modify categorical distance more easily (#5404)
- Speed up
WFGby NumPy vectorization (#5424) - Check whether the study is multi-objective in
sample_independentofGPSampler(#5428) - Suppress warnings from
numpyin hypervolume computation (#5432) - Make an option to assume Pareto optimality in WFG (#5433)
- Adapt multi objective to NumPy v2.0.0 (#5493)
- Enhance the error message for integration installation (#5498)
- Reduce journal size of
JournalStorage(#5526) - Simplify a SQL query for getting the
trial_idofbest_trial(#5537) - Add import check for artifact store objects (#5565)
- Refactor
_is_categorical()inoptuna/optuna/visualization(#5587, thanks @kAIto47802!) - Speed up WFG by using a fact that hypervolume calculation does not need (second or later) duplicated Pareto solutions (#5591)
- Enhance the error message of
multi_objectivedeletion (#5641)
Bug Fixes
- Log
Noneobjective trials correctly (https://github.com/optuna/optuna-integration/pull/119, thanks @neel04!) - Pass two arguments to the forward of
ConstrainedMCObjectiveinqnei_candidates_func(https://github.com/optuna/optuna-integration/pull/124, thanks @alxhslm!) - Allow single split cv in
OptunaSearchCV(https://github.com/optuna/optuna-integration/pull/128, thanks @sgerloff!) - Update BoTorch samplers to support new constraints interface (https://github.com/optuna/optuna-integration/pull/132, thanks @alxhslm!)
- Fix
WilcoxonPrunerbug whenbest_trialhas no intermediate value (#5354) - Debug an error caused by convergence in
GPSampler(#5359) - Fix
average_is_bestimplementation inWilcoxonPruner(#5366) - Create an unique renaming filename for each release operation in lock systems of
JournalStorage(#5389) - Fix
_normalize_valuefor incomplete trials (#5422) - Fix heartbeat for race condition (#5431)
- Guarantee
weights_belowto be finite in MOTPE (#5435) - Fix
_log_complete_trialfor constrained optimization (#5462) - Convert
steptointinreport(#5488) - Use a fixed seed value when
seed=NoneinGridSampler(#5490) - Acquire session lock only for write in heartbeat (#5496)
- Fix a bug in
_create_new_trialand refactor it (#5497) - Add rdb create new trial test (#5525)
- Fix a bug in
sample_normalized_paramforGPSampler(#5543) - Fix the error caused in
plot_contour()with an impossible pair of variables (#5630, thanks @kAIto47802!) - Fix inappropriate behavior in
plot_rank()whenNonevalues exist in trial (#5634, thanks @kAIto47802!)
Installation
- Add an option to install integration dependencies via pip (https://github.com/optuna/optuna-integration/pull/130)
- Add version constraint to numpy (https://github.com/optuna/optuna-integration/pull/131)
Documentation
- Enhance
README.md(https://github.com/optuna/optuna-integration/pull/126) - Add document page and fix docstring and comments (https://github.com/optuna/optuna-integration/pull/134)
- Update the docstring of
PyCmaSampler(https://github.com/optuna/optuna-integration/pull/145) - Add Dashboard and OptunaHub links to the document header (https://github.com/optuna/optuna-integration/pull/155)
- Remove duplicated license definition (https://github.com/optuna/optuna-integration/pull/156)
- Use sphinx rst syntax (#5345)
- Fix typo (#5351)
- Update docs about
show_progress_bar(#5393) - Fix artifact tutorial (#5451)
- Revise docs to specify
ArtifactStoremethods as non-public (#5474) - Improve the docstring of
JournalFileStorage(#5475) - Improve
make cleanindocs(#5487) - Improve the example of chemical structures in
optuna artifact tutorial(#5491) - Add FAQ for artifact store remove API (#5501)
- Add a documentation for
ArtifactMeta(#5511) - Change docs version from latest to stable (#5518)
- Add a list of supported storage for artifact store (#5532)
- Rename filenames for
JournalFileStoragein documents and a tutorial (#5535) - Add explanation for
lock_objtoJournalFileStoragedocstring (#5540) - Fix storages document sections (#5553)
- Add
Returnsto the docstring ofload_study(#5554, thanks @kAIto47802!) - Fix paths related to
storages.journal(#5560) - Rename filename for
JournalFileBackendin examples (#5562) - Add thumbnail (#5575)
- Add link to
optunahub-registry(#5586) - Fix minor artifacts document issues (#5592)
- Add the OptunaHub link to the document header (#5595)
- Improve a docstring of
CmaEsSampler(#5603) - Fix the expired links caused by the directory name change in
optuna-examples(#5623, thanks @kAIto47802!) - Remove the use of
evaluator.evaluatefunction in the example ofPedAnovaImportanceEvaluator(#5632) - Add the news section to
README.md(#5636) - Add SNS URLs to
README.md(#5637) - Add TPE blog post link to doc (#5638)
- Add artifact store post link (#5639)
- Add installation guide for visualization tutorial (#5644, thanks @kAIto47802!)
- Remove a broken link (#5648)
- Update the
Newssection ofREADME.md(#5649)
Examples
- Support tensorflow 2.16.1 and separate CI run for tensorflow estimator (https://github.com/optuna/optuna-examples/pull/248)
- Replace deprecated jax function (https://github.com/optuna/optuna-examples/pull/250)
- Drop Python 3.7 support for wandb (https://github.com/optuna/optuna-examples/pull/252)
- Support python 3.12 in the CIs (https://github.com/optuna/optuna-examples/pull/253)
- Remove
daskversion constraint (https://github.com/optuna/optuna-examples/pull/254) - Update GitHub actions versions to
actions/checkout@v4andactions/setup-python@v5(https://github.com/optuna/optuna-examples/pull/255) - Delete an example using deprecated
fastaiv1(https://github.com/optuna/optuna-examples/pull/256) - Rename
fastaiv2tofastai(https://github.com/optuna/optuna-examples/pull/257) - Fix CI (https://github.com/optuna/optuna-examples/pull/258)
- Fix path in pruners workflow (https://github.com/optuna/optuna-examples/pull/259)
- Install
tensorflow-cpuin CIs (https://github.com/optuna/optuna-examples/pull/260) - Add python 3.12 and run terminator search cv (https://github.com/optuna/optuna-examples/pull/264)
- Enhance
README.md(https://github.com/optuna/optuna-examples/pull/265) - Organize the directory structure (https://github.com/optuna/optuna-examples/pull/266)
- Fix CI with version constraints of packages (https://github.com/optuna/optuna-examples/pull/267)
- Install
numpy<2.0.0forcatboostexample (https://github.com/optuna/optuna-examples/pull/268) - Add Python 3.12 to
aimtest python versions (https://github.com/optuna/optuna-examples/pull/270) - Add Python 3.12 to
fastaitest python versions (https://github.com/optuna/optuna-examples/pull/271) - Use auc score to unify the intermediate and objective values (https://github.com/optuna/optuna-examples/pull/272)
- Add python 3.12 for
mlflowCI python versions (https://github.com/optuna/optuna-examples/pull/274) - Add python 3.12 to CI python versions for
kerasandtensorboardexamples (https://github.com/optuna/optuna-examples/pull/275) - Add an example of artifact store (https://github.com/optuna/optuna-examples/pull/276)
- Separate basic and faq directories (https://github.com/optuna/optuna-examples/pull/277, thanks @kAIto47802!)
- Remove chainer CI (https://github.com/optuna/optuna-examples/pull/278)
Tests
- Suppress
ExperimentalWarnings (https://github.com/optuna/optuna-integration/pull/108) - Add a unit test for convergence of acquisition function in
GPSampler(#5365) - Remove unused block (#5368)
- Implement backward compatibility tests for
JournalStorage(#5486) - Add some tests for visualization functions (#5599)
Code Fixes
- Align run name strategy between
MLflowCallbackandtrack_in_mlflowmethod (https://github.com/optuna/optuna-integration/pull/111, thanks @TTRh!) - Use
TYPE_CHECKINGforObjectiveFuncType(https://github.com/optuna/optuna-integration/pull/113) - Ignore
ExperimentalWarningfortrack_in_wandb(https://github.com/optuna/optuna-integration/pull/122) - Remove unused module (https://github.com/optuna/optuna-integration/pull/127)
- Apply formatter and follow the Optuna conventions (https://github.com/optuna/optuna-integration/pull/133)
- Refactor an internal process of
BoTorchSampler(https://github.com/optuna/optuna-integration/pull/147) - Add missing experimental decorators to the comet integration (https://github.com/optuna/optuna-integration/pull/148)
- Use
__future__.annotations(https://github.com/optuna/optuna-integration/pull/150) - Fix E721 errors (https://github.com/optuna/optuna-integration/pull/151)
- Fix future annotations in
percentile.py(#5322, thanks @aaravm!) - Delete examples directory (#5329)
- Simplify annotations in
optuna/pruners/_hyperband.py(#5338, thanks @keita-sa!) - Simplify annotations in
optuna/pruners/_successive_halving.pyandoptuna/pruners/_threshold.py(#5343, thanks @keita-sa!) - Reduce test warnings (#5344)
- Simplify type annotations for
storages/_base.py(#5352, thanks @Obliquedbishop!) - Use
TYPE_CHECKINGforStudyinsamplers(#5391) - Refactor
_normalize_objective_valuesin NSGA-III to supressRuntimeWarning(#5399) - Make
ObjectiveFuncTypeavailable externally (#5401) - Replace
numpywithnp(#5412) - Bundle experimental feature warning (#5434)
- Simplify annotations in
_brute_force.py(#5441) - Add
__future__.annotationsto base sampler (#5442) - Introduce
__future__.annotationsto TPE-related modules (#5443) - Adapt to
__future__.annotationsinoptuna/storages/_rdb/models.py(#5452, thanks @aisha-partha!) - Debug an unintended assertion error in
GPSampler(#5484) - Make
WFGa function (#5504) - Enhance the comments in
create_new_trial(#5510) - Replace single trailing underscore with double trailing underscore in
.rstfiles (#5514, thanks @47aamir!) - Fix hyperlinks to use double trailing underscores (#5515, thanks @virendrapatil24!)
- Replace
_with__in the link in Sphinx (#5517) - Refactor
plot_parallel_coordinate()(#5527, thanks @karthikkurella!) - Remove an obsolete TODO comment (#5528)
- Unite the argument order of artifact APIs (#5533)
- Make
assume_unique_lexsortedinis_pareto_frontrequired (#5534) - Simplify annotations in
terminatormodule (#5536) - Simplify the type annotations in
samplers/_qmc.py(#5538, thanks @kAIto47802!) - Rename
solution_settoloss_valsin hypervolume computation (#5541) - Expand the type of
callbacksin optimize toIterable(#5542, thanks @kz4killua!) - Organize the directory structure of
JournalStorage(#5544) - Add followup of journal storage module structure organization PR (#5546)
- Move
RetryFailedTrialCallbacktooptuna.storages._callbacks(#5551) - Change
removed_versionof deprecatedJournalStorageclasses (#5552) - Reorganize a journal storage module structure (#5555)
- Remove unused private deprecated class
BaseJournalLogSnapshot(#5561) - Replace relative import to absolute path (#5569, thanks @RektPunk!)
- Simplify annotation in
importance(#5578, thanks @RektPunk!) - Simplify annotation in
trial(#5579, thanks @RektPunk!) - Fix mypy warnings in
matplotlib/_contour.pywith Python3.11 (#5580) - Remove redundant loop in
_get_rank_subplot_info(#5581, thanks @RektPunk!) - Simplify annotations in
_partial_fixed.py(#5583) - Simplify annotation in
_cmaes.py(#5584, thanks @RektPunk!) - Simplify annotations related to
GridSampler(#5588) - Reorganize names related to
search_spaceinterminator/improvement/evaluator.py(#5594) - Refactor
_bisectin_truncnorm.py(#5598) - Simplify annotation storages (#5608, thanks @RektPunk!)
- Add a note about
np.unique(#5615) - Fix ruff errors except for E731 (#5627)
Continuous Integration
- Split ci (https://github.com/optuna/optuna-integration/pull/98)
- Install
pipdeptreev2.16.2 to hotfix parse error (https://github.com/optuna/optuna-integration/pull/109) - Remove dask version constraint (https://github.com/optuna/optuna-integration/pull/112)
- Rename CI name (https://github.com/optuna/optuna-integration/pull/120)
- Add
deprecatedarg for the comet CI job (https://github.com/optuna/optuna-integration/pull/135) - Hotfix the CI in LightGBM test (https://github.com/optuna/optuna-integration/pull/142)
- Hotfix the mypy error of
test_pytorch_lightning.py(https://github.com/optuna/optuna-integration/pull/144) - Rename CI jobs (#5353, thanks @Obliquedbishop!)
- Update GitHub actions versions of
actions/setup-pythonandactions/checkout(#5367) - Add
type: ignorefor CI hotfix (#5419) - Use CPU-only PyTorch wheels on GitHub Actions (#5465)
- Add a version constraint to NumPy (#5492)
- Add the note of the Hotfix in the workflow file (#5494)
- Remove unnecessary version constraint from workflow (#5495)
- Remove skipped tests for BoTorch with Python 3.12 (#5519)
- Fix the version conflicts in the workflow for the minimum version constraints (#5523)
- Replace
sleepfunction with spin waiting to stabilize the frequent Mac test failure (#5549)
Other
- Bump up version number to 4.0.0dev (https://github.com/optuna/optuna-integration/pull/102)
- Update PyPI classifiers for Python 3.11 support (https://github.com/optuna/optuna-integration/pull/129)
- Bump up version number to 4.0.0b0 (https://github.com/optuna/optuna-integration/pull/139)
- Bump up version number to 4.0.0 (https://github.com/optuna/optuna-integration/pull/158)
- Bump up to version number v4.0.0.dev (#5319)
- Bump up to version number 4.0.0b0 (#5572)
- Split
LICENSEfile (#5597) - Add OptunaHub section in
README.md(#5601) - Remove duplicated definition of license in
pyproject.toml(#5645) - Bump up to version number 4.0.0 (#5653)
- Bump up to version number 4.1.0dev (#5654)
Thanks to All the Contributors and Sponsors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@47aamir, @Alnusjaponica, @HideakiImamura, @Obliquedbishop, @RektPunk, @TTRh, @aaravm, @aisha-partha, @alxhslm, @c-bata, @caleb-kaiser, @contramundum53, @eukaryo, @gen740, @kAIto47802, @karthikkurella, @keisuke-umezawa, @keita-sa, @kz4killua, @nabenabe0928, @neel04, @not522, @nzw0301, @porink0424, @sgerloff, @toshihikoyanase, @virendrapatil24, @y0z
Optuna is sponsored by the following sponsors on GitHub.
@AlphaImpact, @dec1costello, @dubovikmaster, @shu65, @raquelhortab
- Python
Published by not522 almost 2 years ago
optuna - v4.0.0-b0
This is the release note of v4.0.0-b0.
If you want to update your existing projects from Optuna v3.x to Optuna v4, please see the migration guide and try out Optuna v4.
Highlights
OptunaHub Beta Release
The Optuna team released the beta version of OptunaHub, the feature-sharing platform for Optuna. Registered features can be easily implemented on users’ code and contributors can register the features they implement. The beta version of OptunaHub is now ready to accept contributions from all over the world. Visit hub.optuna.org!
The following code shows an example to use a sampler registered on OptunaHub.
bash
% pip install optunahub
```python import optunahub import optuna
def objective(trial): x = trial.suggest_float("x", 0, 1) return x
mod = optunahub.loadmodule("samplers/simulatedannealing")
sampler = mod.SimulatedAnnealingSampler() study = optuna.createstudy(sampler=sampler) study.optimize(objective, ntrials=20) ```
Stabilization of Artifact
The stable version of the artifact module is available, now equipped with several new APIs. This module introduces capabilities for managing the relatively large-sized data such as model snapshots in hyperparameter tuning, training/validation datasets, and etc. Compared to third-party libraries for experiment tracking, the advantage of using Optuna’s artifact module is a tight integration of Optuna Dashboard. This allows users to see artifacts (files) associated with the Optuna trial or study.
Here is a list of new APIs:
- download_artifact: Download an artifact from the artifact store.
- get_all_artifact_meta: List the associated artifact information of the provided trial or study.
Stabilization of JournalStorage
The stable version of JournalStorage is available. This implies we have decided to maintain backward compatibility of the log format in the future releases.
Please note that this release introduces the following API changes to improve the clarity of class names and the module structure.
| Deprecated APIs | Corresponding active APIs |
-|-
| optuna.storages.JournalFileStorage | optuna.storages.journal.JournalFileBackend |
| optuna.storages.JournalFileSymlinkLock | optuna.storages.journal.JournalFileSymlinkLock |
| optuna.storages.JournalFileOpenLock | optuna.storages.journal.JournalFileOpenLock |
| optuna.storages.JournalRedisStorage | optuna.storages.journal.JournalRedisBackend |
Breaking Changes
- Delete deprecated three integrations,
skopt,catalyst, andfastaiv1(https://github.com/optuna/optuna-integration/pull/114) - Remove deprecated
CmaEsSamplerfrom integration (https://github.com/optuna/optuna-integration/pull/116) - Remove verbosity of
LightGBMTuner(https://github.com/optuna/optuna-integration/pull/136) - Move positional args of LightGBM tuner (https://github.com/optuna/optuna-integration/pull/138)
- Remove
multi_objective(#5390) - Delete deprecated
_askand_tell(#5398) - Delete deprecated
--direction(s)arguments in theaskcommand (#5405) - Delete deprecated three integrations,
skopt,catalyst, andfastaiv1(#5407) - Remove the default normalization of importance in f-ANOVA (#5411)
- Remove
samplers.intersection(#5414) - Drop implicit create-study in
askcommand (#5415) - Remove deprecated
study optimizeCLI command (#5416) - Remove deprecated
CmaEsSamplerfrom integration (#5417) - Support constrained optimization in
best_trial(#5426) - Drop
--studyincli.py(#5430) - Deprecate
constraints_funcinplot_pareto_frontfunction (#5455) - Rename some classnames related to
JournalStorage(#5539)
New Features
- Add Comet ML integration (https://github.com/optuna/optuna-integration/pull/63, thanks @caleb-kaiser!)
- Add Knowledge Gradient candidates functions (https://github.com/optuna/optuna-integration/pull/125, thanks @alxhslm!)
- Add
is_exhausted()function in theGridSamplerclass (#5306, thanks @aaravm!) - Remove experimental from plot (#5413)
- Implement
download_artifact(#5448) - Add a function to list linked artifact information (#5467)
- Stabilize artifact APIs (#5567)
- Stabilize
JournalStorage(#5568)
Enhancements
- Pass two arguments to the forward of
ConstrainedMCObjectiveto supportbotorch=0.10.0(https://github.com/optuna/optuna-integration/pull/106) - Speed up non-dominated sort (#5302)
- Make 2d hypervolume computation twice faster (#5303)
- Reduce the time complexity of HSSP 2d from
O(NK^2 log K)toO((N - K)K)(#5346) - Introduce lazy hypervolume calculations in HSSP for speedup (#5355)
- Make
plot_contourfaster (#5369) - Speed up
to_internal_reprinCategoricalDistribution(#5400) - Allow users to modify categorical distance more easily (#5404)
- Speed up
WFGby NumPy vectorization (#5424) - Check whether the study is multi-objective in
sample_independentofGPSampler(#5428) - Suppress warnings from
numpyin hypervolume computation (#5432) - Make an option to assume Pareto optimality in WFG (#5433)
- Adapt multi objective to NumPy v2.0.0 (#5493)
- Enhance the error message for integration installation (#5498)
- Reduce journal size of
JournalStorage(#5526) - Simplify a SQL query for getting the
trial_idofbest_trial(#5537)
Bug Fixes
- Log
Noneobjective trials correctly (https://github.com/optuna/optuna-integration/pull/119, thanks @neel04!) - Pass two arguments to the forward of
ConstrainedMCObjectiveinqnei_candidates_func(https://github.com/optuna/optuna-integration/pull/124, thanks @alxhslm!) - Allow single split cv in
OptunaSearchCV(https://github.com/optuna/optuna-integration/pull/128, thanks @sgerloff!) - Fix
WilcoxonPrunerbug whenbest_trialhas no intermediate value (#5354) - Debug an error caused by convergence in
GPSampler(#5359) - Fix
average_is_bestimplementation inWilcoxonPruner(#5366) - Create an unique renaming filename for each release operation in lock systems of
JournalStorage(#5389) - Fix
_normalize_valuefor incomplete trials (#5422) - Fix heartbeat for race condition (#5431)
- Guarantee
weights_belowto be finite in MOTPE (#5435) - Fix
_log_complete_trialfor constrained optimization (#5462) - Convert
steptointinreport(#5488) - Use a fixed seed value when
seed=NoneinGridSampler(#5490) - Acquire session lock only for write in heartbeat (#5496)
- Fix a bug in
_create_new_trialand refactor it (#5497) - Add rdb create new trial test (#5525)
- Fix a bug in
sample_normalized_paramforGPSampler(#5543)
Installation
- Add an option to install integration dependencies via pip (https://github.com/optuna/optuna-integration/pull/130)
- Add version constraint to numpy (https://github.com/optuna/optuna-integration/pull/131)
Documentation
- Enhance
README.md(https://github.com/optuna/optuna-integration/pull/126) - Add document page and fix docstring and comments (https://github.com/optuna/optuna-integration/pull/134)
- Use sphinx rst syntax (#5345)
- Fix typo (#5351)
- Update docs about
show_progress_bar(#5393) - Fix artifact tutorial (#5451)
- Revise docs to specify
ArtifactStoremethods as non-public (#5474) - Improve the docstring of
JournalFileStorage(#5475) - Improve
make cleanindocs(#5487) - Improve the example of chemical structures in
optuna artifact tutorial(#5491) - Add FAQ for artifact store remove API (#5501)
- Add a documentation for
ArtifactMeta(#5511) - Change docs version from latest to stable (#5518)
- Add a list of supported storage for artifact store (#5532)
- Rename filenames for
JournalFileStoragein documents and a tutorial (#5535) - Add explanation for
lock_objtoJournalFileStoragedocstring (#5540) - Fix storages document sections (#5553)
- Add
Returnsto the docstring ofload_study(#5554, thanks @kAIto47802!) - Fixing paths related to
storages.journal(#5560) - Rename filename for
JournalFileBackendin examples (#5562)
Examples
- Support tensorflow 2.16.1 and separate CI run for tensorflow estimator (https://github.com/optuna/optuna-examples/pull/248)
- Replace deprecated jax function (https://github.com/optuna/optuna-examples/pull/250)
- Drop Python 3.7 support for wandb (https://github.com/optuna/optuna-examples/pull/252)
- Support python 3.12 in the CIs (https://github.com/optuna/optuna-examples/pull/253)
- Remove dask version constraint (https://github.com/optuna/optuna-examples/pull/254)
- Update GitHub actions versions to
actions/checkout@v4andactions/setup-python@v5(https://github.com/optuna/optuna-examples/pull/255) - Delete an example using deprecated
fastaiv1(https://github.com/optuna/optuna-examples/pull/256) - Rename fastai v2 to fastai (https://github.com/optuna/optuna-examples/pull/257)
- Fix CI (https://github.com/optuna/optuna-examples/pull/258)
- Fix path in pruners workflow (https://github.com/optuna/optuna-examples/pull/259)
- Install
tensorflow-cpuin CIs (https://github.com/optuna/optuna-examples/pull/260) - Add python 3.12 and run terminator search cv (https://github.com/optuna/optuna-examples/pull/264)
- Organize the directory structure (https://github.com/optuna/optuna-examples/pull/266)
- Fix CI with version constraints of packages (https://github.com/optuna/optuna-examples/pull/267)
- Install
numpy<2.0.0for catboot example (https://github.com/optuna/optuna-examples/pull/268)
Tests
- Suppress
ExperimentalWarnings (https://github.com/optuna/optuna-integration/pull/108) - Add a unit test for convergence of acquisition function in
GPSampler(#5365) - Remove unused block (#5368)
- Implement backward compatibility tests for
JournalStorage(#5486)
Code Fixes
- Align run name strategy between MLflowCallback and trackinmlflow method (https://github.com/optuna/optuna-integration/pull/111, thanks @TTRh!)
- Use
TYPE_CHECKINGforObjectiveFuncType(https://github.com/optuna/optuna-integration/pull/113) - Ignore
ExperimentalWarningfortrack_in_wandb(https://github.com/optuna/optuna-integration/pull/122) - Remove unused module (https://github.com/optuna/optuna-integration/pull/127)
- Apply formatter and follow the Optuna conventions (https://github.com/optuna/optuna-integration/pull/133)
- Fix future annotations in
percentile.py(#5322, thanks @aaravm!) - Delete examples directory (#5329)
- Simplify annotations in
optuna/pruners/_hyperband.py(#5338, thanks @keita-sa!) - Simplify annotations in
optuna/pruners/_successive_halving.pyandoptuna/pruners/_threshold.py(#5343, thanks @keita-sa!) - Reduce test warnings (#5344)
- Simplify type annotations for
storages/_base.py(#5352, thanks @Obliquedbishop!) - Use
TYPE_CHECKINGforStudyinsamplers(#5391) - Refactor
_normalize_objective_valuesin NSGA-III to supressRuntimeWarning(#5399) - Make
ObjectiveFuncTypeavailable externally (#5401) - Replace
numpywithnp(#5412) - Bundle experimental feature warning (#5434)
- Simplify annotations in
_brute_force.py(#5441) - Add
__future__.annotationsto base sampler (#5442) - Introduce
__future__.annotationsto TPE-related modules (#5443) - Adapt to
__future__.annotationsinoptuna/storages/_rdb/models.py(#5452, thanks @aisha-partha!) - Debug an unintended assertion error in
GPSampler(#5484) - Make
WFGa function (#5504) - Enhance the comments in
create_new_trial(#5510) - Replace single trailing underscore with double trailing underscore in
.rstfiles (#5514, thanks @47aamir!) - Fix hyperlinks to use double trailing underscores (#5515, thanks @virendrapatil24!)
- Replace
_with__in the link in Sphinx (#5517) - Refactor
plot_parallel_coordinate()(#5527, thanks @karthikkurella!) - Remove an obsolete TODO comment (#5528)
- Unite the argument order of artifact APIs (#5533)
- Make
assume_unique_lexsortedinis_pareto_frontrequired (#5534) - Simplify annotations in
terminatormodule (#5536) - Simplify the type annotations in
samplers/_qmc.py(#5538, thanks @kAIto47802!) - Rename
solution_settoloss_valsin hypervolume computation (#5541) - Expand the type of
callbacksin optimize toIterable(#5542, thanks @kz4killua!) - Organize the directory structure of
JournalStorage(#5544) - Add followup of journal storage module structure organization PR (#5546)
- Move
RetryFailedTrialCallbacktooptuna.storages._callbacks(#5551) - Change
removed_versionof deprecatedJournalStorageclasses (#5552) - Reorganize a journal storage module structure (#5555)
- Remove unused private deprecated class
BaseJournalLogSnapshot(#5561)
Continuous Integration
- Split ci (https://github.com/optuna/optuna-integration/pull/98)
- Install
pipdeptreev2.16.2 to hotfix parse error (https://github.com/optuna/optuna-integration/pull/109) - Remove dask version constraint (https://github.com/optuna/optuna-integration/pull/112)
- Rename CI name (https://github.com/optuna/optuna-integration/pull/120)
- Add
deprecatedarg for the comet CI job (https://github.com/optuna/optuna-integration/pull/135) - Rename CI jobs (#5353, thanks @Obliquedbishop!)
- Update GitHub actions versions of
actions/setup-pythonandactions/checkout(#5367) - Add
type: ignorefor CI hotfix (#5419) - Use CPU-only PyTorch wheels on GitHub Actions (#5465)
- Add a version constraint to NumPy (#5492)
- Add the note of the Hotfix in the workflow file (#5494)
- Remove unnecessary version constraint from workflow (#5495)
- Remove skipped tests for BoTorch with Python 3.12 (#5519)
- Fix the version conflicts in the workflow for the minimum version constraints (#5523)
- Replace
sleepfunction with spin waiting to stabilize the frequent Mac test failure (#5549)
Other
- Bump up version number to 4.0.0dev (https://github.com/optuna/optuna-integration/pull/102)
- Update PyPI classifiers for Python 3.11 support (https://github.com/optuna/optuna-integration/pull/129)
- Bump up version number to 4.0.0b0 (https://github.com/optuna/optuna-integration/pull/139)
- Bump up to version number v4.0.0.dev (#5319)
- Bump up to version number 4.0.0b0 (#5572)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@47aamir, @Alnusjaponica, @HideakiImamura, @Obliquedbishop, @TTRh, @aaravm, @aisha-partha, @alxhslm, @c-bata, @caleb-kaiser, @contramundum53, @eukaryo, @gen740, @kAIto47802, @karthikkurella, @keisuke-umezawa, @keita-sa, @kz4killua, @nabenabe0928, @neel04, @not522, @nzw0301, @porink0424, @sgerloff, @toshihikoyanase, @virendrapatil24, @y0z
- Python
Published by not522 almost 2 years ago
optuna - v3.6.1
This is the release note of v3.6.1.
Bug Fixes
- [Backport] Fix Wilcoxon pruner bug when best_trial has no intermediate value #5370
- [Backport] Address issue#5358 (#5371)
- [Backport] Fix
average_is_bestimplementation inWilcoxonPruner(#5373)
Other
- Bump up version number to v3.6.1 (#5372)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@HideakiImamura, @eukaryo, @nabenabe0928
- Python
Published by eukaryo about 2 years ago
optuna - v3.6.0
This is the release note of v3.6.0.
Highlights
Optuna 3.6 newly supports the following new features. See our release blog for more detailed information. - Wilcoxon Pruner: New Pruner Based on Wilcoxon Signed-Rank Test - Lightweight Gaussian Process (GP)-Based Sampler - Speeding up Importance Evaluation with PED-ANOVA - Stricter Verification Logic for FrozenTrial - Refactoring the Optuna Dashboard - Migration to Optuna Integration
Breaking Changes
- Implement
optuna.terminatorusingoptuna._gp(#5241)
These migration-related PRs do not break the backward compatibility as long as optuna-integration v3.6.0 or later is installed in your environment.
- Move TensorBoard Integration (https://github.com/optuna/optuna-integration/pull/56, thanks @dheemantha-bhat!)
- Delete TensorBoard integration for migration to
optuna-integration(#5161, thanks @dheemantha-bhat!) - Remove CatBoost integration for isolation (#5198)
- Remove PyTorch integration (#5213)
- Remove Dask integration (#5222)
- Migrate the
sklearnintegration (#5225) - Remove BoTorch integration (#5230)
- Remove
SkoptSampler(#5234) - Remove the
cmaintegration (#5236) - Remove the
wandbintegration (#5237) - Remove XGBoost Integration (#5239)
- Remove MLflow integration (#5246)
- Migrate LightGBM integration (#5249)
- Add CatBoost integration (https://github.com/optuna/optuna-integration/pull/61)
- Add PyTorch integration (https://github.com/optuna/optuna-integration/pull/62)
- Add XGBoost integration (https://github.com/optuna/optuna-integration/pull/65, thanks @buruzaemon!)
- Add
sklearnintegration (https://github.com/optuna/optuna-integration/pull/66) - Move Dask integration (https://github.com/optuna/optuna-integration/pull/67)
- Migrate BoTorch integration (https://github.com/optuna/optuna-integration/pull/72)
- Move
SkoptSampler(https://github.com/optuna/optuna-integration/pull/74) - Migrate
pycmaintegration (https://github.com/optuna/optuna-integration/pull/77) - Migrate the Weights & Biases integration (https://github.com/optuna/optuna-integration/pull/79)
- Add LightGBM integration (https://github.com/optuna/optuna-integration/pull/81, thanks @DanielAvdar!)
- Migrate
MLflowintegration (https://github.com/optuna/optuna-integration/pull/84)
New Features
- Backport the change of the timeline plot in Optuna Dashboard (#5168)
- Wilcoxon pruner (#5181)
- Add
GPSampler(#5185) - Add a super quick f-ANOVA algorithm named PED-ANOVA (#5212)
Enhancements
- Add
formats.shbased onoptuna/master(https://github.com/optuna/optuna-integration/pull/75) - Use vectorization for categorical distance (#5147)
- Unify implementation of fast non-dominated sort (#5160)
- Raise
TypeErrorifparamsis not adictinenqueue_trial(#5164, thanks @adjeiv!) - Upgrade
FrozenTrial._validate()(#5211) - Import SQLAlchemy lazily (#5215)
- Add UCB for
optuna._gp(#5224) - Enhance performance of
GPSampler(#5274) - Fix inconsistencies between terminator and its visualization (#5276, thanks @SimonPop!)
- Enhance
GPSamplerperformance other than introducing local search (#5279)
Bug Fixes
- Fix import path (https://github.com/optuna/optuna-integration/pull/83)
- Fix
README.md(https://github.com/optuna/optuna-integration/pull/88) - Fix
LightGBMTunertest (https://github.com/optuna/optuna-integration/pull/89) - Fix
JSONDecodeErrorinJournalStorage(#5195) - Fix trial validation (#5229)
- Make
gp.fit_kernel_paramsmore robust (#5247) - Fix checking value in
study.tell(#5269, thanks @ryota717!) - Fix
_split_trialsofTPESamplerfor constrained optimization with constant liar (#5298) - Make each importance evaluator compatible with doc (#5311)
Documentation
- Remove
study optimizefrom CLI tutorial page (#5152) - Clarify the
GridSamplerwith ask-and-tell interface (#5153) - Clean-up
faq.rst(#5170) - Make Methods section hidden from Artifact Docs (#5188)
- Enhance README (#5189)
- Add a new section explaing how to customize figures (#5194)
- Replace legacy
plotly.graph_objswithplotly.graph_objects(#5223) - Add a note section to explain that reseed affects reproducibility (#5233)
- Update links to papers (#5235)
- adding link for module's example to documetation for the
optuna.terminatormodule (#5243, thanks @HarshitNagpal29!) - Replace the old example directory (#5244)
- Add Optuna Dashboard section to docs (#5250, thanks @porink0424!)
- Add a safety guard to Wilcoxon pruner, and modify the docstring (#5256)
- Replace LightGBM with PyTorch-based example to remove
lightgbmdependency in visualization tutorial (#5257) - Remove unnecessary comment in
Specify Hyperparameters Manuallytutorial page (#5258) - Add a tutorial of Wilcoxon pruner (#5266)
- Clarify that pruners module does not support multi-objective optimization (#5270)
- Minor fixes (#5275)
- Add a guide to PED-ANOVA for
n_trials>10000(#5310) - Minor fixes of docs and code comments for
PedAnovaImportanceEvaluator(#5312) - Fix doc for
WilcoxonPruner(#5313) - Fix doc example in
WilcoxonPruner(#5315)
Examples
- Remove Python 3.7 and 3.8 from tensorboard CI (https://github.com/optuna/optuna-examples/pull/231)
- Specify black version in the CI (https://github.com/optuna/optuna-examples/pull/232)
- Apply Black 2024 to codebase (https://github.com/optuna/optuna-examples/pull/236)
- Remove MXNet examples (https://github.com/optuna/optuna-examples/pull/237)
- Add an example of Wilcoxon pruner (https://github.com/optuna/optuna-examples/pull/238)
- Make Keras examples Keras 3 friendly (https://github.com/optuna/optuna-examples/pull/239)
- Remove a comment for keras that is not used anymore in this file (https://github.com/optuna/optuna-examples/pull/240)
- Use Keras 3 friendly syntax in MLflow example (https://github.com/optuna/optuna-examples/pull/242)
- Remove
-preoption in therlintegration (https://github.com/optuna/optuna-examples/pull/243) - Hotfix CI by adding version constraints to
daskandtensorflow(https://github.com/optuna/optuna-examples/pull/245)
Tests
- Unify the implementation of
_create_frozen_trial()undertestingmodule (#5157) - Remove the Python version constraint for PyTorch (#5278)
Code Fixes
- Fix unused (and unintended) import (https://github.com/optuna/optuna-integration/pull/68)
- Add Dask to
__init__.pyand fix its documentation generation (https://github.com/optuna/optuna-integration/pull/71) - Replace
optuna.integrationwithoptuna_integrationin the doc and the issue template (https://github.com/optuna/optuna-integration/pull/73) - Fix the doc for TensorFlow (https://github.com/optuna/optuna-integration/pull/76)
- Add skopt dependency (https://github.com/optuna/optuna-integration/pull/78)
- Fastai readme fix (https://github.com/optuna/optuna-integration/pull/82, thanks @DanielAvdar!)
- Fix
__init__.py(https://github.com/optuna/optuna-integration/pull/86) - Apply Black 2024 to codebase (https://github.com/optuna/optuna-integration/pull/87)
- Change the order of dependencies by name (https://github.com/optuna/optuna-integration/pull/92)
- Remove the deprecated decorator of
KerasPruningCallback(https://github.com/optuna/optuna-integration/pull/93) - Remove
UserWarningbytests/test_keras.py(https://github.com/optuna/optuna-integration/pull/94) - Refactor
TPESamplerfor more clarity before c-TPE integration (#5117) - Fix
Checks(integration)failure (#5167) - Fix type annotation of logging (#5176)
- Update NamedTuple in
_ParzenEstimatorParametersto more modern style (#5193) - Apply Black 2024 to codebase (#5252)
- Simplify annotations in
optuna/study/_optimize.py(#5261, thanks @shahpratham!) - Unify and refactor
plot_timelinetest (#5281)
Continuous Integration
- Remove non oldest and latest Python versions from tests (https://github.com/optuna/optuna-integration/pull/44)
- Fix flake8 failure in CI (https://github.com/optuna/optuna-integration/pull/55)
- Delete workflow dispatch input (https://github.com/optuna/optuna-integration/pull/57)
- Fix default branch (https://github.com/optuna/optuna-integration/pull/58)
- Fix coverage source path (https://github.com/optuna/optuna-integration/pull/60)
- Not use
black 24.*(https://github.com/optuna/optuna-integration/pull/64) - Simplify integration test (https://github.com/optuna/optuna-integration/pull/95)
- Hotfix the version of
botorch<0.10.for CI failures (https://github.com/optuna/optuna-integration/pull/96) - Hotfix the CI error by adding version constraint to dask (https://github.com/optuna/optuna-integration/pull/99)
- Fix tests with MPI (#5166)
- Fix Checks (Integration) CI for NumPy 1.23.5 (#5177)
- Add version constraint for black (#5210)
- Skip the reproducibility tests for lightgbm (#5214)
- Fix the errors in mypy for the
Checks (Integration)CI (#5217) - Add a version constraint for Torch (#5221)
- Hotfix mypy error in integration (#5232)
- Skip
test_reproducible_in_other_processforGPSamplerwith Python 3.12 (#5251) - Add CI settings to test Matplotlib without Plotly (#5263, thanks @DanielAvdar!)
- Unify indent size, two in toml file (#5271)
- Follow up for split integrations (#5277)
- Add a version constraint to
fakeredis(#5307)
Other
- Bump up version number to 3.6.0.dev (https://github.com/optuna/optuna-integration/pull/53)
- Bump up version number to 3.6.0 (https://github.com/optuna/optuna-integration/pull/100)
- Bump the version up to v3.6.0.dev (#5143)
- Ignore auto generated files by Sphinx (#5192)
- Delete
labeler.ymlto disable thetriageaction (#5240) - Bump up to version number 3.6.0 (#5318)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Alnusjaponica, @DanielAvdar, @HarshitNagpal29, @HideakiImamura, @SimonPop, @adjeiv, @buruzaemon, @c-bata, @contramundum53, @dheemantha-bhat, @eukaryo, @gen740, @hrntsm, @knshnb, @nabenabe0928, @not522, @nzw0301, @porink0424, @ryota717, @shahpratham, @toshihikoyanase, @y0z
- Python
Published by HideakiImamura over 2 years ago
optuna - v3.5.0
This is the release note of v3.5.0.
Highlights
This is a maintenance release with various bug fixes and improvements to the documentation and more.
Breaking Changes
- Isolate the fast.ai module from optuna (https://github.com/optuna/optuna-integration/pull/49, thanks @sousu4!)
- Change
n_objectivescondition to be greater than 4 in candidates functions (#5121, thanks @adjeiv!)
New Features
- Support constraints in plot contour (#4975, thanks @y-kamiya!)
- Support infeasible coloring for plot_timeline (#5014)
- Support
constant_liarin multi-objectiveTPESampler(#5021) - Add
optuna study-namescli (#5029) - Use
ExpectedHypervolumeImprovementcandidates function forBotorchSampler(#5065, thanks @adjeiv!) - Fix logeicandidatesfunc in
botorch.py(#5094, thanks @sousu4!) - Report CV scores from within
OptunaSearchCV(#5098, thanks @adjeiv!)
Enhancements
- Support
constant_liarin multi-objectiveTPESampler(#5021) - Make positional args to kwargs in suggest_int (#5044)
- Ensure n_below is never negative in TPESampler (#5074, thanks @p1kit!)
- Improve visibility of infeasible trials in
plot_contour(#5107)
Bug Fixes
- Fix random number generator of
NSGAIIChildGenerationStrategy(#5003) - Return
trialsfor above in MO split whenn_below=0(#5079) - Enable loading of read-only files (#5103, thanks @Guillaume227!)
- Fix
logpdffor scaledtruncnorm(#5110) - Fix the bug of matplotlib's plot_rank function (#5133)
Documentation
- Add the table of dependencies in each integration module (#5005)
- Enhance the documentation of
LightGBMtuner and separatetrain()from__init__.py(#5010) - Update link to reference (#5064)
- Update the FAQ on reproducible optimization results to remove note on
HyperbandPruner(#5075, thanks @felix-cw!) - Remove
MOTPESamplerfromindex.rstfile (#5084, thanks @Ashhar-24!) - Add a note about the deprecation of
MOTPESamplerto the doc (#5086) - Add the TPE tutorial paper to the doc-string (#5096)
- Update
README.mdto fix the installation and integration (#5126) - Clarify that
Recommended budgetsincluden_startup_trials(#5137)
Examples
- Update version syntax for PyTorch and PyTorch Lightning examples (https://github.com/optuna/optuna-examples/pull/205, thanks @JustinGoheen!)
- Update import path (https://github.com/optuna/optuna-examples/pull/213)
- Bump up python versions (https://github.com/optuna/optuna-examples/pull/214)
- Add the simplest example directly to README (https://github.com/optuna/optuna-examples/pull/215)
- Add simples examples for multi-objective and constrained optimizations (https://github.com/optuna/optuna-examples/pull/216)
- Revise the comment to describe the problem (https://github.com/optuna/optuna-examples/pull/217)
- Modify simple examples based on the Optuna code conventions (https://github.com/optuna/optuna-examples/pull/218)
- Remove version specification of
jaxandjaxlib(https://github.com/optuna/optuna-examples/pull/223) - Import examples from
optuna/optuna-dashboard(https://github.com/optuna/optuna-examples/pull/224) - Add
OptunaSearchCVwith terminator (https://github.com/optuna/optuna-examples/pull/225) - Drop python 3.8 from haiku test (https://github.com/optuna/optuna-examples/pull/227)
- Run MXNet in Python 3.11 (https://github.com/optuna/optuna-examples/pull/228)
Tests
- Remove tests for allennlp and chainer (https://github.com/optuna/optuna-integration/pull/47)
- Reduce the warning in
tests/study_tests/test_study.py(#5070, thanks @sousu4!)
Code Fixes
- Implement NSGA-III elite population selection strategy (#5027)
- Fix import path of
PyTorchLightning(#5028) - Fix
Anywithfloatin_TreeNode.children(#5040, thanks @aanghelidi!) - Fix future annotation in
typing.py(#5054, thanks @jot-s-bindra!) - Add future annotations to callback and terminator files inside terminator folder (#5055, thanks @jot-s-bindra!)
- Fix future annotations to edf python file (#5056, thanks @Vaibhav101203!)
- Fix future annotations in hypervolumehistory.py (#5057, thanks @Vaibhav101203!)
- Reduce the warning in
tests/storages_tests/test_heartbeat.py(#5066, thanks @sousu4!) - Fix future annotation to
frozen.py(#5080, thanks @Vaibhav101203!) - Fix annotation for
dataframe.py(#5081, thanks @Vaibhav101203!) - Fix future annotation (#5083, thanks @Vaibhav101203!)
- Fix type annotation (#5105)
- Fix mypy error in CI (#5106)
- Isolate the fast.ai module (#5120, thanks @sousu4!)
- Clean up workflow file (#5122)
Continuous Integration
- Run
test_tensorflowin Python 3.11 (https://github.com/optuna/optuna-integration/pull/46) - Exclude mypy checks for chainer (https://github.com/optuna/optuna-integration/pull/48)
- Support Python 3.12 on tests for core modules (#5018)
- Fix the issue where formats.sh does not handle tutorial/ (#5023, thanks @sousu4!)
- Skip slow integration tests (#5033)
- Install PyTorch for CPU on CIs (#5042)
- Remove unused
type: ignore(#5047) - Reduce
tests-mpito the oldest and latest Python versions (#5067) - Add workflow matrices for the tests to reduce GitHub check runtime (#5093)
- Remove the skip of Python 3.11 in
tests-mpi(#5100) - Downgrade kaleido to 0.1.0post1 for fixing Windows CI (#5101)
- Rename
should-skiptotest-trigger-typefor more clarity (#5134) - Pin the version of PyQt6-Qt6 (#5135)
- Revert
Pin the version of PyQt6-Qt6(#5140)
Other
- Bump up version to v3.5.0.dev (https://github.com/optuna/optuna-integration/pull/43)
- Bump up version number to 3.5.0 (https://github.com/optuna/optuna-integration/pull/52)
- Bump the version up to v3.5.0.dev (#5032)
- Remove email of authors (#5078)
- Update the integration sections in
README.md(#5108) - Pin mypy version to 1.6.* (#5123)
- Remove
!examplesfrom.dockerignore(#5129)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Alnusjaponica, @Ashhar-24, @Guillaume227, @HideakiImamura, @JustinGoheen, @Vaibhav101203, @aanghelidi, @adjeiv, @c-bata, @contramundum53, @eukaryo, @felix-cw, @gen740, @jot-s-bindra, @keisuke-umezawa, @knshnb, @nabenabe0928, @not522, @nzw0301, @p1kit, @sousu4, @toshihikoyanase, @y-kamiya
- Python
Published by HideakiImamura over 2 years ago
optuna - v3.4.0
This is the release note of v3.4.0.
Highlights
Optuna 3.4 newly supports the following new features. See our release blog for more detailed information.
- Preferential Optimization (Optuna Dashboard)
- Optuna Artifact
- Jupyter Lab Extension
- VS Code Extension
- User-defined Distance for Categorical Parameters in TPE
- Constrained Optimization Support for Visualization Functions
- User-Defined Plotly’s Figure Support (Optuna Dashboard)
- 3D Model Viewer Support (Optuna Dashboard)
Breaking Changes
- Remove deprecated arguments with regard to
LightGBM>=4.0(#4844) - Deprecate
SkoptSampler(#4913)
New Features
- Support constraints for intermediate values plot (#4851, thanks @adjeiv!)
- Display all objectives on hyperparameter importances plot (#4871)
- Implement
get_all_study_names()(#4898) - Support constraints
plot_rank(#4899, thanks @ryota717!) - Support Study Artifacts (#4905)
- Support specifying distance between categorical choices in
TPESampler(#4926) - Add
metric_namesgetter to study (#4930) - Add artifact middleware for exponential backoff retries (#4956)
- Add
GCSArtifactStore(#4967, thanks @semiexp!) - Add
BestValueStagnationEvaluator(#4974, thanks @smygw72!) - Allow user-defined objective names in hyperparameter importance plots (#4986)
Enhancements
- CHG constrained param displayed in #cccccc (#4877, thanks @louis-she!)
- Faster implementation of fANOVA (#4897)
- Support constraint in plot slice (#4906, thanks @hrntsm!)
- Add mimetype input (#4910, thanks @hrntsm!)
- Show all ticks in
_parallel_coordinate.pywhen log scale (#4911) - Speed up multi-objective TPE (#5017)
Bug Fixes
- Fix numpy indexing bugs and named tuple comparing (#4874, thanks @ryota717!)
- Fix
fail_stale_trialswith race condition (#4886) - Fix alias handler (#4887)
- Add lazy random state and use it in
RandomSampler(#4970, thanks @shu65!) - Fix TensorBoard error on categorical choices of mixed types (#4973, thanks @ciffelia!)
- Use lazy random state in samplers (#4976, thanks @shu65!)
- Fix an error that does not consider
min_child_samples(#5007) - Fix
BruteForceSamplerin parallel optimization (#5022)
Documentation
- Fix typo in
_filesystem.py(#4909) - Mention a pruner instance is not stored in a storage in resuming tutorial (#4927)
- Add introduction of
optuna-fast-fanovain documents (#4943) - Add artifact tutorial (#4954)
- Fix an example code in
Boto3ArtifactStore's docstring (#4957) - Add tutorial for
JournalStorage(#4980, thanks @semiexp!) - Fix document regarding
ArtifactNotFound(#4982, thanks @smygw72!) - Add the workaround for duplicated samples to FAQ (#5006)
Examples
- Add huggingface's link to external projects (https://github.com/optuna/optuna-examples/pull/201)
- Fix samplers CI (https://github.com/optuna/optuna-examples/pull/202)
- Set version constraint on aim (https://github.com/optuna/optuna-examples/pull/206)
- Add an example of Optuna Terminator for LightGBM (https://github.com/optuna/optuna-examples/pull/210, thanks @hamster-86!)
Tests
- Reduce
n_trialsintest_combination_of_different_distributions_objective(#4950) - Replaces California housing dataset with iris dataset (#4953)
- Fix numpy duplication warning (#4978, thanks @torotoki!)
- Make test order deterministic for
pytest-xdist(#4999)
Code Fixes
- Move shap (https://github.com/optuna/optuna-integration/pull/32)
- Remove shap (#4791)
- Use
isinstanceinstead ofif type() is ...(#4896) - Make
cmaesdependency optional (#4901) - Call internal sampler's
before_trial(#4914) - Refactor
_grid.py(#4918) - Fix the
checks-integrationerrors on LightGBMTuner (#4923) - Replace deprecated
botorchmethod to remove warning (#4940) - Fix type annotation (#4941)
- Add
_split_trialsinstead of_get_observation_pairsand_split_observation_pairs(#4947) - Use
__future__.annotationsinoptuna/visualization/_optimization_history.py(#4964, thanks @YuigaWada!) - Fix #4508 for
optuna/visualization/_hypervolume_history.py(#4965, thanks @RuTiO2le!) - Use future annotation in
optuna/_convert_positional_args.py(#4966, thanks @hamster-86!) - Fix type annotation of
SQLAlchemy(#4968) - Use
collections.abcinoptuna/visualization/_edf.py(#4969, thanks @g-tamaki!) - Use
collections.abcin plot pareto front (#4971) - Remove
experimental_funcfrommetric_namesproperty (#4983, thanks @semiexp!) - Add
__future__.annotationstoprogress_bar.py(#4992) - Fix annotations in
optuna/optuna/visualization/matplotlib/_optimization_history.py(#5015, thanks @sousu4!)
Continuous Integration
- Fix checks integration (#4869)
- Remove fakeredis version constraint (#4873)
- Support
asv0.6.0 (#4882) - Fix speed-benchmarks CI (#4903)
- Fix Tests (MPI) CI (#4904)
- Fix xgboost pruning callback (#4921)
- Enhance speed benchmark (#4981, thanks @g-tamaki!)
- Drop Python 3.7 on
tests-mpi(#4998) - Remove Python 3.7 from the development docker image build (#5009)
- Use CPU version of PyTorch in Docker image (#5019)
Other
- Bump up version number to v3.4.0.dev (https://github.com/optuna/optuna-integration/pull/37)
- Update python shield in
README.md(https://github.com/optuna/optuna-integration/pull/39) - Replace deprecated mypy option (https://github.com/optuna/optuna-integration/pull/40)
- Bump up version to v3.4.0 (https://github.com/optuna/optuna-integration/pull/42)
- Bump the version up to v3.4.0.dev (#4861)
- Use OIDC (#4867)
- Add
FUNDING.yml(#4912) - Update
optional-dependenciesand document deselecting integration tests inCONTRIBUTING.md(#4962) - Bump the version up to v3.4.0 (#5031)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Alnusjaponica, @HideakiImamura, @RuTiO2le, @YuigaWada, @adjeiv, @c-bata, @ciffelia, @contramundum53, @cross32768, @eukaryo, @g-tamaki, @g-votte, @gen740, @hamster-86, @hrntsm, @hvy, @keisuke-umezawa, @knshnb, @lucasmrdt, @louis-she, @moririn2528, @nabenabe0928, @not522, @nzw0301, @ryota717, @semiexp, @shu65, @smygw72, @sousu4, @torotoki, @toshihikoyanase, @xadrianzetx
- Python
Published by contramundum53 over 2 years ago
optuna - v3.3.0
This is the release note of v3.3.0.
Highlights
CMA-ES with Learning Rate Adaptation
A new variant of CMA-ES has been added. By setting the lr_adapt argument to True in CmaEsSampler, you can utilize it. For multimodal and/or noisy problems, adapting the learning rate can help avoid getting trapped in local optima. For more details, please refer to #4817. We want to thank @nomuramasahir0, one of the authors of LRA-CMA-ES, for his great work and the development of cmaes library.
Hypervolume History Plot for Multiobjective Optimization
In multiobjective optimization, the history of hypervolume is commonly used as an indicator of performance. Optuna now supports this feature in the visualization module. Thanks to @y0z for your great work!
Constrained Optimization Support for Visualization Functions
| Plotly | matplotlib |
| --- | --- |
| |
|
Some samplers support constrained optimization, however, many other features cannot handle it. We are continuously enhancing support for constraints. In this release, plot_optimization_history starts to consider constraint violations. Thanks to @hrntsm for your great work!
```python import optuna
def objective(trial): x = trial.suggestfloat("x", -15, 30) y = trial.suggestfloat("y", -15, 30) v0 = 4 * x2 + 4 * y2 trial.setuserattr("constraint", [1000 - v0]) return v0
def constraintsfunc(trial): return trial.userattrs["constraint"]
sampler = optuna.samplers.TPESampler(constraintsfunc=constraintsfunc) study = optuna.createstudy(sampler=sampler) study.optimize(objective, ntrials=100) fig = optuna.visualization.plotoptimizationhistory(study) fig.show() ```
Streamlit Integration for Human-in-the-loop Optimization
Optuna Dashboard v0.11.0 provides the tight integration with Streamlit framework. By using this feature, you can create your own application for human-in-the-loop optimization. Please check out the documentation and the example for details.
Breaking Changes
- Move mxnet (https://github.com/optuna/optuna-integration/pull/31)
- Remove mxnet (#4790)
- Remove
ordered_dictargument fromIntersectionSearchSpace(#4846)
New Features
- Add
logei_candidate_funcand make it default when available (#4667) - Support
JournalFileStorageandJournalRedisStorageon CLI (#4696) - Implement hypervolume history plot for matplotlib backend (#4748, thanks @y0z!)
- Add
cv_results_toOptunaSearchCV(#4751, thanks @jckkvs!) - Add
optuna.integration.botorch.qnei_candidates_func(#4753, thanks @kstoneriv3!) - Add hypervolume history plot for
plotlybackend (#4757, thanks @y0z!) - Add
FileSystemArtifactStore(#4763) - Sort params on fetch (#4775)
- Add constraints support to
_optimization_history_plot(#4793, thanks @hrntsm!) - Bump up
LightGBMversion to v4.0.0 (#4810) - Add constraints support to
matplotlib._optimization_history_plot(#4816, thanks @hrntsm!) - Introduce CMA-ES with Learning Rate Adaptation (#4817)
- Add
upload_artifactapi (#4823) - Add
before_trial(#4825) - Add
Boto3ArtifactStore(#4840) - Display best objective value in contour plot for a given param pair, not the value from the most recent trial (#4848)
Enhancements
- Speed up
logpdfin_truncnorm.py(#4712) - Speed up
erf(#4713) - Speed up
get_all_trialsinInMemoryStorage(#4716) - Add a warning for a progress bar not being displayed #4679 (#4728, thanks @rishabsinghh!)
- Make
BruteForceSamplerconsider failed trials (#4747) - Use shallow copy in
_get_latest_trial(#4774) - Speed up
plot_hypervolume_history(#4776)
Bug Fixes
- Solve issue #4557 - error_score (#4642, thanks @jckkvs!)
- Fix
BruteForceSamplerfor pruned trials (#4720) - Fix
plot_slicebug when some of the choices are numeric (#4724) - Make
LightGBMTunerreproducible (#4795)
Installation
- Bump up python version (https://github.com/optuna/optuna-integration/pull/34)
Documentation
- Remove
jquery-extension(#4691) - Add FAQ on combinatorial search space (#4723)
- Fix docs (#4732)
- Add
plot_rankandplot_timelineplots to visualization tutorial (#4735) - Fix typos found in
integration/sklearn.py(#4745) - Remove
study.n_objectivesfrom document (#4796) - Add lower version constraint for
sphinx_rtd_theme(#4853) - Artifact docs (#4855)
Examples
- Run DaskML example with Python 3.11 (https://github.com/optuna/optuna-examples/pull/188)
- Show more information in terminator examples (https://github.com/optuna/optuna-examples/pull/192)
- Drop support for Python 3.7 on Haiku (https://github.com/optuna/optuna-examples/pull/198)
- Add
LICENSEfile (https://github.com/optuna/optuna-examples/pull/200)
Tests
- Remove unnecessary
pytestmark(https://github.com/optuna/optuna-integration/pull/29) - Add
GridSamplertest for failed trials (#4721) - Follow up PR #4642 by adding a unit test to confirm
OptunaSearchCVbehavior (#4758) - Fix
test_log_gass_masswith SciPy 1.11.0 (#4766) - Fix Pytorch lightning unit test (#4780)
- Remove skopt (#4792)
- Rename test directory (#4839)
Code Fixes
- Simplify the type annotations in
benchmarks(#4703, thanks @caprest!) - Unify sampling implementation in
TPESampler(#4717) - Get values after
_get_observation_pairs(#4742) - Remove unnecessary period (#4746)
- Handle deprecated argument
early_stopping_rounds(#4752) - Separate dominate function from
_fast_non_dominated_sort()(#4759) - Separate
after_trialstrategy (#4760) - Remove unused attributes in
TPESampler(#4769) - Remove
pkg_resources(#4770) - Use trials as argument of
_calculate_weights_below_for_multi_objective(#4773) - Fix type annotation (#4797, thanks @taniokay!)
- Follow up separation of after trial strategy (#4803)
- Loose coupling nsgaii child generation (#4806)
- Remove
_study_idparameter fromTrialclass (#4811, thanks @adjeiv!) - Loose coupling nsgaii elite population selection (#4821)
- Fix checks integration (#4826)
- Remove
OrderedDict(#4838, thanks @taniokay!) - Fix typo (#4842, thanks @wouterzwerink!)
- Followup child generation strategy (#4856)
- Remove
samplers._search_space.IntersectionSearchSpace(#4857) - Add experimental decorators to artifacts functionalities (#4858)
Continuous Integration
- Output dependency tree (https://github.com/optuna/optuna-integration/pull/9)
- Use OIDC (https://github.com/optuna/optuna-integration/pull/33)
- Drop Python 3.7 support (https://github.com/optuna/optuna-integration/pull/35)
- Enhance speed benchmark for storages (#4778)
- Drop Python 3.7 on
tests-integration(#4784) - Remove unused
type:ignores (#4787) - Restrict numpy version < 1.24 (#4788)
- Upgrade redis version (#4805)
- Add version constraints on LightGBM (#4807)
- Follow-up #4807 : Fix windows-tests and mac-tests (#4809)
- Support 3.11 integration (#4820)
- Support flake8 6.1.0 (#4847)
Other
- Bump up version number to 3.3.0dev (https://github.com/optuna/optuna-integration/pull/27)
- Bump up version number to 3.3.0 (https://github.com/optuna/optuna-integration/pull/36)
- Bump up version number to 3.3.0dev (#4710)
- Bump the version up to v3.3.0 (#4860)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Alnusjaponica, @HideakiImamura, @adjeiv, @c-bata, @caprest, @contramundum53, @cross32768, @eukaryo, @gen740, @hrntsm, @jckkvs, @knshnb, @kstoneriv3, @nomuramasahir0, @not522, @nzw0301, @rishabsinghh, @taniokay, @toshihikoyanase, @wouterzwerink, @xadrianzetx, @y0z
- Python
Published by c-bata almost 3 years ago
optuna - v3.2.0
This is the release note of v3.2.0.
Highlights
Human-in-the-loop optimization
With the latest release, we have incorporated support for human-in-the-loop optimization. It enables an interactive optimization process between users and the optimization algorithm. As a result, it opens up new opportunities for the application of Optuna in tuning Generative AI. For further details, please check out our human-in-the-loop optimization tutorial.
Overview of human-in-the-loop optimization. Generated images and sounds are displayed on Optuna Dashboard, and users can directly evaluate them there.
Automatic optimization terminator(Optuna Terminator)
Optuna Terminator is a new feature that quantitatively estimates room for optimization and automatically stops the optimization process. It is designed to alleviate the burden of figuring out an appropriate value for the number of trials (n_trials), or unnecessarily consuming computational resources by indefinitely running the optimization loop. See #4398 and optuna-examples#190.
Transition of estimated room for improvement. It steadily decreases towards the level of cross-validation errors.
New sampling algorithms
NSGA-III for many-objective optimization
We've introduced the NSGAIIISampler as a new multi-objective optimization sampler. It implements NSGA-III, which is an extended variant of NSGA-II, designed to efficiently optimize even when the dimensionality of the objective values is large (especially when it's four or more). NSGA-II had an issue where the search would become biased towards specific regions when the dimensionality of the objective values exceeded four. In NSGA-III, the algorithm is designed to distribute the points more uniformly. This feature was introduced by #4436.
Objective value space for multi-objective optimization (minimization problem). Red points represent Pareto solutions found by NSGA-II. Blue points represent those found by NSGA-III. NSGA-II shows a tendency for points to concentrate towards each axis (corresponding to the ends of the Pareto Front). On the other hand, NSGA-III displays a wider distribution across the Pareto Front.
BI-population CMA-ES
Continuing from v3.1, significant improvements have been made to the CMA-ES Sampler. As a new feature, we've added the BI-population CMA-ES algorithm, a kind of restart strategy that mitigates the problem of falling into local optima. Whether the IPOP CMA-ES, which we've been providing so far, or the new BI-population CMA-ES is better depends on the problems. If you're struggling with local optima, please try BI-population CMA-ES as well. For more details, please see #4464.
New visualization functions
Timeline plot for trial life cycle
The timeline plot visualizes the progress (status, start and end times) of each trial. In this plot, the horizontal axis represents time, and trials are plotted in the vertical direction. Each trial is represented as a horizontal bar, drawn from the start to the end of the trial. With this plot, you can quickly get an understanding of the overall progress of the optimization experiment, such as whether parallel optimization is progressing properly or if there are any trials taking an unusually long time.
Similar to other plot functions, all you need to do is pass the study object to plot_timeline. For more details, please refer to #4470 and #4538.
Rank plot to understand input-output relationship
A new visualization feature, plot_rank, has been introduced. This plot provides valuable insights into landscapes of objective functions, i.e., relationship between parameters and objective values. In this plot, the vertical and horizontal axes represent the parameter values, and each point represents a single trial. The points are colored according to their ranks.
Similar to other plot functions, all you need to do is pass the study object to plot_rank. For more details, please refer to #4427 and #4541.
Isolating integration modules
We have separated Optuna's integration module into a different package called optuna-integration. Maintaining many integrations within the Optuna package was becoming costly. By separating the integration module, we aim to improve the development speed of both Optuna itself and its integration module. As of the release of v3.2, we have migrated six integration modules: allennlp, catalyst, chainer, keras, skorch, and tensorflow (excepting for the TensorBoard integration). To use integration module, pip install optuna-integration will be necessary. See #4484.
- Move
chainermnintegration (https://github.com/optuna/optuna-integration/pull/1) - Move
integration/keras.py(https://github.com/optuna/optuna-integration/pull/5) - Move
integration/allennlp(https://github.com/optuna/optuna-integration/pull/8) - Move Catalyst (https://github.com/optuna/optuna-integration/pull/19)
- Move
tf.kerasintegration (https://github.com/optuna/optuna-integration/pull/21) - Move
skorch(https://github.com/optuna/optuna-integration/pull/22) - Move
tensorflowintegration (https://github.com/optuna/optuna-integration/pull/23) - Partially follow
sklearn.model_selection.GridSearchCV's arguments (#4336) - Delete
optuna.integration.ChainerPruningExtensionfor migrating to optuna-integration package (#4370) - Delete
optuna.integration.ChainerMNStudyfor migrating to optuna-integration package (#4497) - Delete
optuna.integration.KerasPruningCallbackfor migration to optuna-integration (#4558) - Delete
AllenNLPintegration for migration to optuna-integration (#4579) - DeleteCatalyst integration for migration to optuna-integration (#4644)
- Remove
tf.kerasintegration (#4662) - Delete
skorchintegration for migration to optuna-integration (#4663) - Remove
tensorflowintegration (#4666)
Starting support for Mac & Windows
We have started supporting Optuna on Mac and Windows. While many features already worked in previous versions, we have fixed issues that arose in certain modules, such as Storage. See #4457 and #4458.
Breaking Changes
- Update deletion timing of
system_attrsandset_system_attr(https://github.com/optuna/optuna-integration/pull/4) - Change deletion timing of
system_attrsandset_system_attr(#4550)
New Features
- Show custom objective names for multi-objective optimization (#4383)
- Support DDP in
PyTorch-Lightning(#4384) - Implement the evaluator of regret bounds and its GP backend for Optuna Terminator 🤖 (#4401)
- Implement the termination logic and APIs of Optuna Terminator 🤖 (#4405)
- Add rank plot (#4427)
- Implement NSGA-III (#4436)
- Add BIPOP-CMA-ES support in
CmaEsSampler(#4464) - Add timeline plot with plotly as backend (#4470)
- Move
optuna.samplers._search_space.intersection.pytooptuna.search_space.intersection.py(#4505) - Add timeline plot with matplotlib as backend (#4538)
- Add rank plot matplotlib version (#4541)
- Support batched sampling with BoTorch (#4591, thanks @kstoneriv3!)
- Add
plot_terminator_improvementas visualization ofoptuna.terminator(#4609) - Add import for public API of
optuna.terminatortooptuna/terminator/__init__.py(#4669) - Add matplotlib version of
plot_terminator_improvement(#4701)
Enhancements
- Import
cmaespackage lazily (#4394) - Make
BruteForceSamplerstateless (#4408) - Sort studies by study_id (#4414)
- Add index study_id column on trials table (#4449, thanks @Ilevk!)
- Cache all trials in Study with delayed relative sampling (#4468)
- Avoid error at import time for
optuna.terminator.improvement.gp.botorch(#4483) - Avoid standardizing
Yvarin_BoTorchGaussianProcess(#4488) - Change the noise value in
_BoTorchGaussianProcessto suppress warning messages (#4510) - Change the argument of
intersection_search_spacefromstudytotrials(#4514) - Improve deprecated messages in the old suggest functions (#4562)
- Add support for
distributed>=2023.3.2(#4589, thanks @jrbourbeau!) - Fix
plot_rankmarker lines (#4602) - Sync owned trials when calling
study.askandstudy.get_trials(#4631) - Ensure that the plotly version of timeline plot draws a legend even if all TrialStates are the same (#4635)
Bug Fixes
- Fix
botorchdependency (#4368) - Mitigate a blocking issue while running migrations with SQLAlchemy 2.0 (#4386)
- Fix
colorlogcompatibility problem (#4406) - Validate length of values in
add_trial(#4416) - Fix
RDBStorage.get_best_trialwhen there areinfs (#4422) - Fix bug of CMA-ES with margin on
RDBStorageorJournalStorage(#4434) - Fix CMA-ES Sampler (#4443)
- Fix
param_maskfor multivariate TPE withconstant_liar(#4462) - Make
QMCSamplersamplers reproducible withseed=0(#4480) - Fix noise becoming NaN for the terminator module (#4512)
- Fix
metric_nameson_log_completed_trial()function (#4594) - Fix
ImportErrorforbotorch<=0.4.0(#4626) - Fix index of
n_retries += 1inRDBStorage(#4658) - Fix CMA-ES with margin bug (#4661)
- Fix a logic for invalidating the cache in
CachedStorage(#4670) - Fix #4697
ValueError: Rank 0 node expects anoptuna.trial.Trialinstance as the trial argument (#4698, thanks @keisukefukuda!) - Fix a bug reported in issue #4699 (#4700)
- Add tests for
plot_terminator_improvementand fix some bugs (#4702)
Installation
- Remove codecov dependencies (https://github.com/optuna/optuna-integration/pull/13)
- Migration to
pyproject.tomlfor packaging (#4164) - [RFC] Remove specific pytorch version to support the latest stable PyTorch (#4585)
Documentation
- Create the document and run the test to create document in each PR (https://github.com/optuna/optuna-integration/pull/2)
- Fix Keras docs (https://github.com/optuna/optuna-integration/pull/12)
- Add links of documents (https://github.com/optuna/optuna-integration/pull/17)
- Load
sphinxcontrib.jqueryexplicitly (https://github.com/optuna/optuna-integration/pull/18) - Add docstring for the
Terminatorclass (#4596) - Fix the build on Read the Docs by following optuna #4659 (https://github.com/optuna/optuna-integration/pull/20)
- Add external packages to
intersphinx_mappinginconf.py(#4290) - Minor fix of documents (#4360)
- Fix a typo in
MeanDecreaseImpurityImportanceEvaluator(#4385) - Update to Sphinx 6 (#4479)
- Fix URL to the line of optuna-integration file (#4498)
- Fix typo (#4515, thanks @gituser789!)
- Resolve error in compiling PDF documents (#4605)
- Add
sphinxcontrib.jqueryextension toconf.py(#4615) - Remove an example code of
SkoptSampler(#4625) - Add links to the optuna-integration document (#4638)
- Add manually written index page of tutorial (#4640)
- Fix the build on Read the Docs (#4659)
- Improve docstring of
rank_plotfunction and its matplotlib version (#4660) - Add a link to tutorial of human-in-the-loop optimization (#4665)
- Fix typo for progress bar in documentation (#4673, thanks @gituser789!)
- Add docstrings to
optuna.termintor(#4675) - Add docstring for
plot_terminator_improvement(#4677) - Remove
versionaddeddirectives (#4681) - Add pareto front display example: 2D-plot from 3D-optimization including crop the scale (#4685, thanks @gituser789!)
- Embed a YouTube video in the docstring of
DaskStorage(#4694) - List Dashboard in navbar (#4708)
- Fix docstring of terminator improvement for
min_n_trials(#4709)
Examples
- An example of using pytorch distributed data parallel on 1 machine with arbitrary multiple GPUs (https://github.com/optuna/optuna-examples/pull/155, thanks @li-li-github!)
- Apply
black .with black 23.1.0 (https://github.com/optuna/optuna-examples/pull/168) - Add Aim example (https://github.com/optuna/optuna-examples/pull/170)
- Resolve todo and fix docstrings in fastaiv2 example (https://github.com/optuna/optuna-examples/pull/171)
- Update pytorch-lightning version (https://github.com/optuna/optuna-examples/pull/172)
- Add python 3.11 to ray's version matrix (https://github.com/optuna/optuna-examples/pull/174)
- Minor code change suggestions to
pytorch_distributed_spawn.py(https://github.com/optuna/optuna-examples/pull/175) - Install
optuna-integrationinchainerCI (https://github.com/optuna/optuna-examples/pull/176) - Add python 3.11 skimage's version matrix and remove warning for inputs data (https://github.com/optuna/optuna-examples/pull/177)
- Execute Ray example in CI (https://github.com/optuna/optuna-examples/pull/178)
- Update pytorch lightning version for ddp (https://github.com/optuna/optuna-examples/pull/179)
- Don't run evaluation twice on the last epoch (https://github.com/optuna/optuna-examples/pull/181, thanks @Jendker!)
- Use BoTorch 0.8 or higher (https://github.com/optuna/optuna-examples/pull/185)
- Run catboost example with python 3.11 (https://github.com/optuna/optuna-examples/pull/186)
- Add terminator examples (https://github.com/optuna/optuna-examples/pull/190)
- Use Gymnasium and pre-released Stable-Baselines3 (https://github.com/optuna/optuna-examples/pull/191)
- Fix the AllenNLP CI (https://github.com/optuna/optuna-examples/pull/193)
Tests
- Suppress
FutureWarningaboutTrial.set_system_attrin storage tests (#4323) - Add test for casting in
test_nsgaii.py(#4387) - Fix the blocking issue on
test_with_server.py(#4402) - Fix mypy error about
Chainer(#4410) - Add unit tests for the _BoTorchGaussianProcess class (#4441)
- Implement unit tests for
optuna.terminator.improvement._preprocessing.py(#4506) - Fix mypy error about
PyTorch Lightning(#4520)
Code Fixes
- Simplify type annotations (https://github.com/optuna/optuna-integration/pull/10)
- Copy
_imports.pyfrom optuna (https://github.com/optuna/optuna-integration/pull/16) - Refactor ParzenEstimator (#4183)
- Fix mypy error abut
AllenNLPin Checks (integration) (#4277) - Fix checks integration about pytorch lightning (#4322)
- Minor refactoring of
tests/hypervolume_tests/test_hssp.py(#4329) - Remove unnecessary sklearn version condition (#4379)
- Support black 23.1.0 (#4382)
- Warn unexpected search spaces for
CmaEsSampler(#4395) - Fix flake8 errors on sklearn integration (#4407)
- Fix mypy error about
PyTorch Distributed(#4413) - Use
numpy.polynomialin_erf.py(#4415) - Refactor
_ParzenEstimator(#4433) - Simplify an argument's name of
RegretBoundEvaluator(#4442) - Fix
Checks(integration)aboutterminator/.../botorch.py(#4461) - Add an experimental decorator to
RegretBoundEvaluator(#4469) - Add JSON serializable type (#4478)
- Move
optuna.samplers._search_space.group_decomposed.pytooptuna.search_space.group_decomposed.py(#4491) - Simplify annotations in
optuna.visualization(#4525, thanks @harupy!) - Simplify annotations in
tests.visualization_tests(#4526, thanks @harupy!) - Remove unused instance variables in
_BoTorchGaussianProcess(#4530) - Avoid deepcopy in
optuna.visualization.plot_timeline(#4540) - Use
SingleTaskGPfor Optuna terminator (#4542) - Change deletion timing of
optuna.samplers.IntersectionSearchSpaceandoptuna.samplers.intersection_search_space(#4549) - Remove
IntersectionSearchSpaceinoptuna.terminatormodule (#4595) - Change arguments of
BaseErrorEvaluatorand classes that inherit from it (#4607) - Delete
import Rectangleinvisualization/matplotlib(#4620) - Simplify type annotations in
visualize/_rank.pyandvisualization_tests/(#4628) - Move the function
_distribution_is_logtooptuna.distributionsP fromoptuna/terminator/init.py` (#4668) - Separate
_fast_non_dominated_sort()from the samplers (#4671) - Read trials from remote storage whenever
get_all_trialsof_CachedStorageis called (#4672) - Remove experimental label from _ProgressBar (#4684, thanks @tungbq!)
Continuous Integration
- Fix coverage.yml (https://github.com/optuna/optuna-integration/pull/3)
- Delete labeler.yaml (https://github.com/optuna/optuna-integration/pull/6)
- Fix pypi publish.yaml (https://github.com/optuna/optuna-integration/pull/11)
- Test on an arbitrary branch (https://github.com/optuna/optuna-integration/pull/15)
- Fix the CI with AllenNLP (https://github.com/optuna/optuna-integration/pull/24)
- Update actions/setup-python@v2 -> v4 (#4307, thanks @Kaushik-Iyer!)
- Update action versions (#4328)
- Update
actions/setup-pythoninmac-tests(follow-up for #4307) (#4343) - Add type ignore to
ProcessGroupimport fromtorch.distributed(#4347) - Fix label of
pypigh-action-pypi-publish(#4359) - [Hotfix] Avoid to install SQLAlchemy 2.0 on
checks(#4364) - [Hotfix] Add version constriant on SQLAlchemy for tests storage with server (#4372)
- Disable colored log when
NO_COLORenv or not tty (#4376) - Output installed packages in Tests CI (#4381)
- Output installed packages in mac-test CI (#4397)
- Use
ubuntu-latestin PyPI publish CI (#4400) - Output installed packages in Checks CI (#4417, thanks @Kaushik-Iyer!)
- Output installed packages in Coverage CI (#4423, thanks @Kaushik-Iyer!)
- Fix mypy error on checks-integration CI (#4424)
- Fix mac-test cache path (#4425)
- Add minimum version tests of numpy, tqdm, colorlog, PyYAML (#4428)
- Remove ignore testpytorchlightning (#4432)
- Use
PyYAML==5.1ontests-with-minimum-dependencies(#4435) - Remove trailing spaces in CI configs (#4439)
- Output installed packages in all remaining CIs (#4445, thanks @Kaushik-Iyer!)
- Add windows ci check (#4457)
- Make mac-test executed on PRs (#4458)
- Add sqlalchemy<2.0.0 in
Checks(integration)(#4482) - Fix ci test conditions (#4496)
- Deploy results of visual regression test on Netlify (#4507)
- Pin pytorch lightning version (#4522)
- Securely deploy results of visual regression test on Netlify (#4532)
- Pin
Distributedversion (#4545) - Delete fragile heartbeat test (#4551)
- Ignore AllenNLP test from Mac-CI (#4561)
- Delete visual-regression.yml (#4597)
- Remove dependency on
codecov(#4606) - Install
testinchecks-integrationCI (#4612) - Fix checks integration (#4617)
- Add
Output dependency treeby pipdeptree to Actions (#4624) - Add a version constraint on
fakeredis(#4637) - Hotfix and run catboost test w/ python 3.11 except for MacOS (#4646)
- Run
mlflowwith Python 3.11 (#4647)
Other
- Update repository settings as in optuna/optuna (https://github.com/optuna/optuna-integration/pull/7)
- Bump up version to v3.2.0.dev (#4345)
- Remove
cached-pathfromsetup.py(#4357) - Revert a merge commit for #4183 (#4429)
- Include both venv and .venv in the exclude setting of the formatters (#4476)
- Replace
hackingwithflake8(#4556) - Fix Codecov link (#4564)
- Add
lightning_logsto.gitignore(#4565) - Fix targets of
blackandisortinformats.sh(#4610) - Install
benchmark,optional, andtestin dev Docker image (#4611) - Provide kind error massage for missing
optuna-integration(#4636)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Alnusjaponica, @HideakiImamura, @Ilevk, @Jendker, @Kaushik-Iyer, @amylase, @c-bata, @contramundum53, @cross32768, @eukaryo, @g-votte, @gen740, @gituser789, @harupy, @himkt, @hvy, @jrbourbeau, @keisuke-umezawa, @keisukefukuda, @knshnb, @kstoneriv3, @li-li-github, @nomuramasahir0, @not522, @nzw0301, @toshihikoyanase, @tungbq
- Python
Published by toshihikoyanase about 3 years ago
optuna - v3.1.1
This is the release note of v3.1.1.
Enhancements
- [Backport] Import
cmaespackage lazily (#4573)
Bug Fixes
- [Backport] Fix botorch dependency (#4569)
- [Backport] Fix parammask for multivariate TPE with constantliar (#4570)
- [Backport] Mitigate a blocking issue while running migrations with SQLAlchemy 2.0 (#4571)
- [Backport] Fix bug of CMA-ES with margin on
RDBStorageorJournalStorage(#4572) - [Backport] Fix RDBStorage.getbesttrial when there are
infs (#4574) - [Backport] Fix CMA-ES Sampler (#4581)
Code Fixes
- [Backport] Add
types-tqdmfor lint (#4566)
Other
- Update version number to v3.1.1 (#4567)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@HideakiImamura, @contramundum53, @not522
- Python
Published by HideakiImamura about 3 years ago
optuna - v3.0.6
This is the release note of v3.0.6.
Installation
- Fix a project metadata for scipy version constraint (#4494)
Other
- Bump up version number to v3.0.6 (#4493)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@c-bata @HideakiImamura
- Python
Published by c-bata over 3 years ago
optuna - v3.1.0
This is the release note of v3.1.0.
This is not something you have to read from top to bottom to learn about the summary of Optuna v3.1. The recommended way is reading the release blog.
Highlights
New Features
CMA-ES with Margin
| CMA-ES | CMA-ES with Margin | | ------- | -------- | |
|
|
“The animation is referred from https://github.com/EvoConJP/CMA-ESwithMargin, which is distributed under the MIT license.”
CMA-ES achieves strong performance for continuous optimization, but there is still room for improvement in mixed-integer search spaces. To address this, we have added support for the "CMA-ES with Margin" algorithm to our CmaEsSampler, which makes it more efficient in these cases. You can see the benchmark results here. For more detailed information about CMA-ES with Margin, please refer to the paper “CMA-ES with Margin: Lower-Bounding Marginal Probability for Mixed-Integer Black-Box Optimization - arXiv”, which has been accepted for presentation at GECCO 2022.
```python import optuna from optuna.samplers import CmaEsSampler
def objective(trial): x = trial.suggestfloat("y", -10, 10, step=0.1) y = trial.suggestint("x", -100, 100) return x**2 + y
study = optuna.createstudy(sampler=CmaEsSampler(withmargin=True)) study.optimize(objective) ```
Distributed Optimization via NFS
JournalFileStorage, a file storage backend based on JournalStorage, supports NFS (Network File System) environments. It is the easiest option for users who wish to execute distributed optimization in environments where it is difficult to set up database servers such as MySQL, PostgreSQL or Redis (e.g. #815, #1330, #1457 and #2216).
```python import optuna from optuna.storages import JournalStorage, JournalFileStorage
def objective(trial): x = trial.suggestfloat("x", -100, 100) y = trial.suggestfloat("y", -100, 100) return x**2 + y
storage = JournalStorage(JournalFileStorage("./journal.log")) study = optuna.create_study(storage=storage) study.optimize(objective) ```
For more information on JournalFileStorage, see the blog post “Distributed Optimization via NFS Using Optuna’s New Operation-Based Logging Storage” written by @wattlebirdaz.
A Brand-New Redis Storage
We have replaced the Redis storage backend with a JournalStorage-based one. The experimental RedisStorage class has been removed in v3.1. The following example shows how to use the new JournalRedisStorage class.
```python import optuna from optuna.storages import JournalStorage, JournalRedisStorage
def objective(trial): …
storage = JournalStorage(JournalRedisStorage("redis://localhost:6379")) study = optuna.create_study(storage=storage) study.optimize(objective) ```
Dask.distributed Integration
DaskStorage, a new storage backend based on Dask.distributed, is supported. It allows you to leverage distributed capabilities in similar APIs with concurrent.futures. DaskStorage can be used with InMemoryStorage, so you don't need to set up a database server. Here's a code example showing how to use DaskStorage:
```python import optuna from optuna.storages import InMemoryStorage from optuna.integration import DaskStorage from distributed import Client, wait
def objective(trial): ...
with Client("192.168.1.8:8686") as client: study = optuna.createstudy(storage=DaskStorage(InMemoryStorage())) futures = [ client.submit(study.optimize, objective, ntrials=10, pure=False) for i in range(10) ] wait(futures) print(f"Best params: {study.best_params}") ```
Setting up a Dask cluster is easy: install dask and distributed, then run the dask scheduler and dask worker commands, as detailed in the Quick Start Guide in the Dask.distributed documentation.
```console $ pip install optuna dask distributed
$ dark scheduler INFO - Scheduler at: tcp://192.168.1.8:8686 INFO - Dashboard at: :8687 …
$ dask worker tcp://192.168.1.8:8686 $ dask worker tcp://192.168.1.8:8686 $ dask worker tcp://192.168.1.8:8686 ```
See the documentation for more information.
Brute-force Sampler
BruteForceSampler, a new sampler for brute-force search, tries all combinations of parameters. In contrast to GridSampler, it does not require passing the search space as an argument and works even with branches. This sampler constructs the search space with the define-by-run style, so it works by just adding sampler=optuna.samplers.BruteForceSampler().
```python import optuna
def objective(trial): c = trial.suggestcategorical("c", ["float", "int"]) if c == "float": return trial.suggestfloat("x", 1, 3, step=0.5) elif c == "int": a = trial.suggestint("a", 1, 3) b = trial.suggestint("b", a, 3) return a + b
study = optuna.create_study(sampler=optuna.samplers.BruteForceSampler()) study.optimize(objective) ```
Other Improvements
Bug Fix for TPE’s constant_liar Option
The constant_liar option of TPESampler is an option for the distributed optimization or batch optimization. It has been introduced in v2.8.0, but suffers from performance degradation in specific situations. In this release, we have detected the cause of the problem, and resolve it with fruitful performance verification. See #4073 for more details.

Make Scipy Dependency Optional
50% time of import optuna is consumed by SciPy-related modules. Also, it consumes 110MB of storage space, which is really problematic in environments with limited resources such as serverless computing.
We decided to implement scientific functions on our own to make the SciPy dependency optional. Thanks to contributors' effort on performance optimization, our implementation is as fast as the code with SciPy although ours is written in pure Python. See #4105 for more information.
Note that QMCSampler still depends on SciPy. If you use QMCSampler, please explicitly specify SciPy as your dependency.
The New UI for Optuna Dashboard

We are developing a new UI for Optuna Dashboard that is available as an opt-in feature from the beta release - simply launch the dashboard as usual and click the link to the new UI. Please try it out and share your thoughts with us.
console
$ pip install "optuna-dashboard>=0.9.0b2"
Feedback Survey: The New UI for Optuna Dashboard
Change Supported Python Versions
We have changed the supported Python versions. Specifically, Python 3.6 has been removed from the supported versions and Python 3.11 has been added. See #3021 and #3964 for more details.
Breaking Changes
- Allow users to call
study.optimize()in multiple threads (#4068) - Use all trials in
TPESamplereven whenmultivariate=True(#4079) - Drop Python 3.6 (#4150)
- Remove
RedisStorage(#4156) - Deprecate
set_system_attrinStudyandTrial(#4188) - Add a
directionsarg tostorage.create_new_study(#4189) - Deprecate
system_attrsinStudyclass (#4250) - Deprecate
Trial.system_attrsproperty method (#4264) - Remove
deviceargument ofTorchDistributedTrial(#4266)
New Features
- Add Dask integration (#2023, thanks @jrbourbeau!)
- Add journal-style log storage (#3854)
- Support CMA-ES with margin in
CmaEsSampler(#4016) - Add journal redis storage (#4086)
- Add device argument to
BoTorchSampler(#4101) - Add the feature to
JournalStorageof Redis backend to resume from a snapshot (#4102) TorchDistributedTrialusesgroupas parameter instead ofdevice(#4106, thanks @reyoung!)- Added
user_attrsto print by Optuna studies incli.py(#4129, thanks @gonzaload!) - Add
BruteForceSampler(#4132, thanks @semiexp!) - Add
__getstate__and__setstate__toRedisStorage(#4135, thanks @shu65!) - Make journal redis storage picklable (#4139, thanks @shu65!)
- Support for
qNoisyExpectedHypervolumeImprovementacquisition function from Botorch (Issue#4014) (#4186) - Show best trial number and value in progress bar (#4205)
Enhancements
- Change the log message format for failed trials (#3857, thanks @erentknn!)
- Move default logic of
get_trial_id_from_study_id_trial_number()method toBaseStorage(#3910) - Fix the data migration script for v3 release (#4020)
- Convert
search_spacevalues ofGridSamplerexplicitly (#4062) - Add single exception catch to study
optimize(#4098) - Remove scipy dependencies from
TPESampler(#4105) - Add validation in
enqueue_trial(#4126) - Speed up
tests/samplers_tests/test_nsgaii.py::test_fast_non_dominated_sort_with_constraints(#4128, thanks @mist714!) - Add
getstateandsetstateto journal storage (#4130, thanks @shu65!) - Support
Nonein slice plot (#4133, thanks @belldandyxtq!) - Add marker to matplotlib
plot_intermediate_value(#4134, thanks @belldandyxtq!) - Add overloads for type narrowing in
suggest_categorical(#4143, thanks @ConnorBaker!) - Cache
study.directionsto reduce the number ofget_study_directions()calls (#4146) - Add an in-memory cache in
Trialclass (#4240) - Use
CMAwMclass even when there is no discrete params (#4289) - Refer
OPTUNA_STORAGEenvironment variable in Optuna CLI (#4299, thanks @Hakuyume!) - Apply
@overloadtoChainerMNTrialandTorchDistributedTrial(Follow-up of #4143) (#4300) - Make
OPTUNA_STORAGEenvironment variable experimental (#4316)
Bug Fixes
- Fix infinite loop bug in
TPESampler(#3953, thanks @gasin!) - Fix
GridSampler(#3957) - Fix an import error of
sqlalchemy.orm.declarative_base(#3967) - Skip to add
intermediate_value_typeandvalue_typecolumns if exists (#4015) - Fix duplicated sampling of
SkoptSampler(#4023) - Avoid parse errors of
datetime.isoformatstrings (#4025) - Fix a concurrency bug of
JournalStorageset_trial_state_values(#4033) - Specify object type to numpy array init to avoid unintended str cast (#4035)
- Make
TPESamplerreproducible (#4056) - Fix bugs in
constant_liaroption (#4073) - Add a flush to
JournalFileStorage.append_logs(#4076) - Add a lock to
MLflowCallback(#4097) - Reject deprecated distributions in
OptunaSearchCV(#4120) - Stop using hash function in
_get_bracket_idinHyperbandPruner(#4131, thanks @zaburo-ch!) - Validation for the parameter enqueued in
to_internal_reprofFloatDistributionandIntDistribution(#4137) - Fix
PartialFixedSamplerto handleNonecorrectly (#4147, thanks @halucinor!) - Fix the bug of
JournalFileStorageon Windows (#4151) - Fix CmaEs system attribution key (#4184)
- Skip constraint check for running trial (#4275)
- Fix constrained optimization with
TPESampler'sconstant_liar(#4325) - Fix import of
ProcessGroupfromtorch.distributed(#4344)
Installation
- Replace
thopwithfvcore(#3906) - Use the latest stable scipy (#3959, thanks @gasin!)
- Remove GPyTorch version constraint (#3986)
- Make typing_extensions optional (#3990)
- Add version constraint on
importlib-metadata(#4036) - Add a version constraint of
matplotlib(#4044)
Documentation
- Update cli tutorial (#3902)
- Replace
thopwithfvcore(#3906) - Slightly improve docs of
FrozenTrial(#3943) - Refine docs in
BaseStorage(#3948) - Remove "Edit on GitHub" button from readthedocs (#3952)
- Mention restoring sampler in saving/resuming tutorial (#3992)
- Use
log_lossinstead of deprecatedlogsincesklearn1.1 (#3993) - Fix script path in
benchmarks/README.md(#4021) - Ignore
ConvergenceWarningin the ask-and-tell tutorial (#4032) - Update docs to let users know the concurrency problem on SQLite3 (#4034)
- Fix the time complexity of
NSGAIISampler(#4045) - Fix sampler comparison table (#4082)
- Add
BruteForceSamplerin the samplers' list (#4152) - Remove markup from NaN in FAQ (#4155)
- Remove the document of the
multi_objectivemodule (#4167) - Fix a typo in
QMCSampler(#4179) - Introduce Optuna Dashboard in tutorial docs (#4226)
- Remove
RedisStoragefrom docstring (#4232) - Add the
BruteForceSamplerexample to the document (#4244) - Improve the document of
BruteForceSampler(#4245) - Fix an inline markup in distributed tutorial (#4247)
- Fix a typo in
BruteForceSampler(#4267) - Update FAQ (#4269)
- Fix a typo in
XGBoostPruningCallback(#4270) - Fix
CMAEvolutionStrategylink inintegration.PyCmaSamplerdocument (#4284, thanks @hrntsm!) - Resolve warnings by
sphinxwith nitpicky option and fix typos (#4287) - Fix typos (#4291)
- Improve the document of
JournalStorage(#4308, thanks @hrntsm!) - Fix typo (#4332, thanks @Jasha10!)
- Fix docstring in
optuna/integration/dask.py(#4333) - Mention
suggest_floatinBruteForceSampler(#4334) - Remove
verbose_evalargument fromlightgbmcallback in tutorial pages (#4335) - Use Sphinx 5 until
sphinx_rtd_themesupports Sphinx 6 (#4341)
Examples
- Add Dask example (https://github.com/optuna/optuna-examples/pull/46, thanks @jrbourbeau!)
- Hotfix for botorch example (https://github.com/optuna/optuna-examples/pull/134)
- Replace
thopwithfvcore(https://github.com/optuna/optuna-examples/pull/136) - Add
Optuna-distributedto external projects (https://github.com/optuna/optuna-examples/pull/137) - Remove the version constraint of GPyTorch (https://github.com/optuna/optuna-examples/pull/138)
- Fix a file path in
CONTRIBUTING.md(https://github.com/optuna/optuna-examples/pull/139) - Install
scikit-learninstead ofsklearn(https://github.com/optuna/optuna-examples/pull/141) - Add constraint on
tensorflowto<2.11.0(https://github.com/optuna/optuna-examples/pull/146) - Specify
botorchversion (https://github.com/optuna/optuna-examples/pull/151) - Add an example of Optuna Dashboard (https://github.com/optuna/optuna-examples/pull/152)
- Pin
numpyversion to1.23.xformxnetexamples (https://github.com/optuna/optuna-examples/pull/154) - Use
tensorflow2.11 syntax to fix CI error (https://github.com/optuna/optuna-examples/pull/156) - Add Python 3.11 to version-matrix except for integration (https://github.com/optuna/optuna-examples/pull/160)
- Use latest stable version of actions (https://github.com/optuna/optuna-examples/pull/161)
- Use
Monitorto resolvestable_baselines3's warning (https://github.com/optuna/optuna-examples/pull/162) - Add Python 3.11 to a part of CI jobs (https://github.com/optuna/optuna-examples/pull/163)
Tests
- Suppress warnings in
tests/test_distributions.py(#3912) - Suppress warnings and minor code fixes in
tests/trial_tests(#3914) - Reduce warning messages by
tests/study_tests/(#3915) - Remove dynamic search space based objective from a parallel job test (#3916)
- Remove all warning messages from
tests/integration_tests/test_sklearn.py(#3922) - Remove out-of-range related warning messages from
MLflowCallbackandWeightsAndBiasesCallback(#3923) - Ignore
RuntimeWarningwhennanminandnanmaxtake an array only containing nan values frompruners_tests(#3924) - Remove warning messages from test files for
pytorch_distributedandchainermnmodules (#3927) - Remove warning messages from
tests/integration_tests/test_lightgbm.py(#3944) - Resolve warnings in
tests/visualization_tests/test_contour.py(#3954) - Reduced warning messages from
tests/visualization_tests/test_slice.py(#3970, thanks @jmsykes83!) - Remove warning from a few visualization tests (#3989)
- Deselect integration tests in Tests CI (#4013)
- Remove warnings from
tests/visualization_tests/test_optimization_history.py(#4024) - Unset
PYTHONHASHSEEDfor the hash-depedenet test (#4031) - Call
study.tellfrom another process (#4039, thanks @Abelarm!) - Improve test for heartbeat: Add test for the case that trial state should be kept running (#4055)
- Remove warnings in the test of Pareto front (#4072)
- Remove matplotlib's
get_cmapwarning fromtests/visualization_tests/test_param_importances.py(#4095) - Reduce tests'
n_trialsfor CI time reduction (#4117) - Skip
test_pop_waiting_trial_thread_safeon RedisStorage (#4119) - Simplify the test of
BruteForceSamplerfor infinite search space (#4153) - Add sep-CMA-ES in
parametrize_sampler(#4154) - Fix a broken test for
dask.distributedintegration (#4170) - Add
DaskStorageto existing storage tests (#4176, thanks @jrbourbeau!) - Fix a test error in
test_catboost.py(#4190) - Remove
test/integration_tests/test_sampler.py(#4204) - Fix mypy error abut
PyTorch Lightningin Checks (integration) (#4279) - Remove
OPTUNA_STORAGEenvironment variable to check missing storage errors (#4306) - Use
TrialnotFrozenTrialin a test ofWeightsAndBiasesCallback(#4309) - Activate a test case for
_set_alembic_revision(#4319) - Add test to check
error_scoreis stored (#4337)
Code Fixes
- Refactor
_tell.py(#3841) - Make log message user-friendly when objective returns a sequence of unsupported values (#3868)
- Gather mask of
Noneparameter inTPESampler(#3886) - Migrate CLI from
clifftoargparse(#4100) - Enable mypy
--no-implicit-reexportoption (#4110) - Remove unused function:
find_any_distribution(#4127) - Remove object inheritance from base classes (#4161)
- Use
mlflow2.0.1 syntax (#4173) - Simplify implementation of
_preprocess_argvin CLI (#4187) - Move
_solve_hsspto_hypervolume/utils.py(#4227, thanks @jpbianchi!) - Add tests for
CmaEsSampler(#4233) - Remove an obsoleted logic from
CmaEsSampler(#4239) - Avoid to decode log string in
JournalRedisStorage(#4246) - Fix a typo in
TorchDistributedTrial(#4271) - Fix mypy error abut
Chainerin Checks (integration) (#4276) - Fix mypy error abut
BoTorchin Checks (integration) (#4278) - Fix mypy error abut
dask.pyin Checks (integration) (#4280) - Avoid to use features that will be removed in SQLAlchemy v2.0 (#4304)
Continuous Integration
- Hotfix
botorchmodule by adding the version constraint ofgpytorch(#3950) - Drop Python 3.6 from integration CIs (#3983)
- Use PyTorch 1.11 for consistency and fix a typo (#3987)
- Support Python 3.11 (#4018)
- Remove
# type: ignorefor mypy 0.981 (#4019) - Fix metric inconsistency between bayesmark plots and report (#4077)
- Pin Ubuntu version to 20.04 in
TestsandTests (Storage with server)(#4118) - Add workflow to test Optuna with lower versions of constraints (#4125)
- Mark some tests slow and ignore in pull request trigger (#4138, thanks @mist714!)
- Allow display names to be changed in benchmark scripts (Issue #4017) (#4145)
- Disable scheduled workflow runs in forks (#4159)
- Remove the CircleCI job
document(#4160) - Stop running reproducibility tests on CI for PR (#4162)
- Stop running reproducibility tests for coverage (#4163)
- Add
workflow_dispatchtrigger to the integration tests (#4166) - Fix CI errors when using
mlflow==2.0.1(#4171) - Add
fakeredisin benchmark dependencies (#4177) - Fix
asvspeed benchmark (#4185) - Skip tests with minimum version for Python 3.10 and 3.11 (#4199)
- Split normal tests and tests with minimum versions (#4200)
- Update action/checkout@v2 -> v3 (#4206)
- Update actions/cache@v2 -> v3 (#4207)
- Update actions/stale@v5 -> v6 (#4208)
- Pin
botorchto avoid CI failure (#4228) - Add the
pytestdependency forasv(#4243) - Fix mypy error about
pytorch_distributed.pyin Checks (integration) (#4281) - Run
test_pytorch_distributed.pyagain (#4301) - Remove all CircleCI config (#4315)
- Update minimum version of
cmaes(#4321) - Add Python 3.11 to integration CI (#4327)
Other
- Bump up version number to 3.1.0.dev (#3934)
- Remove the news section on README (#3940)
- Add issue template for code fix (#3968)
- Close stale issues immediately after labeling
stale(#4071) - Remove
tox.ini(#4078) - Replace gitter with GitHub Discussions (#4083)
- Deprecate description-checked label (#4090)
- Make
days-before-issue-stale300 days (#4091) - Unnecessary space removed (#4109, thanks @gonzaload!)
- Add note not to share pickle files in bug reports (#4212)
- Update the description of optuna-dashboard on README (#4217)
- Remove
optuna.TYPE_CHECKING(#4238) - Bump up version to v3.1.0-b0 (#4262)
- Remove the list of examples from
examples/README(#4283) - Exclude benchmark directories from the sdist package (#4318)
- Bump up version number to 3.1.0 (#4346)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Abelarm, @Alnusjaponica, @ConnorBaker, @Hakuyume, @HideakiImamura, @Jasha10, @amylase, @belldandyxtq, @c-bata, @contramundum53, @cross32768, @erentknn, @eukaryo, @g-votte, @gasin, @gen740, @gonzaload, @halucinor, @himkt, @hrntsm, @hvy, @jmsykes83, @jpbianchi, @jrbourbeau, @keisuke-umezawa, @knshnb, @mist714, @ncclementi, @not522, @nzw0301, @rene-rex, @reyoung, @semiexp, @shu65, @sile, @toshihikoyanase, @wattlebirdaz, @xadrianzetx, @zaburo-ch
- Python
Published by HideakiImamura over 3 years ago
optuna - v3.1.0-b0
This is the release note of v3.1.0-b0.
Highlights
CMA-ES with Margin support
| CMA-ES | CMA-ES with Margin | | ------- | -------- | |
“The animation is referred from https://github.com/EvoConJP/CMA-ESwithMargin, which is distributed under the MIT license.”
CMA-ES achieves strong performance for continuous optimization, but there is still room for improvement in mixed-integer search spaces. To address this, we have added support for the "CMA-ES with Margin" algorithm to our CmaEsSampler, which makes it more efficient in these cases. You can see the benchmark results here. For more detailed information about CMA-ES with Margin, please refer to the paper “CMA-ES with Margin: Lower-Bounding Marginal Probability for Mixed-Integer Black-Box Optimization - arXiv”, which has been accepted for presentation at GECCO 2022.
```python import optuna from optuna.samplers import CmaEsSampler
def objective(trial): x = trial.suggestfloat("y", -10, 10, step=0.1) y = trial.suggestint("x", -100, 100) return x**2 + y
study = optuna.createstudy(sampler=CmaEsSampler(withmargin=True)) study.optimize(objective) ```
Distributed Optimization via NFS
JournalFileStorage, a file storage backend based on JournalStorage, supports NFS (Network File System) environments. It is the easiest option for users who wish to execute distributed optimization in environments where it is difficult to set up database servers such as MySQL, PostgreSQL or Redis (e.g. #815, #1330, #1457 and #2216).
```python import optuna from optuna.storages import JournalStorage, JournalFileStorage
def objective(trial): x = trial.suggestfloat("x", -100, 100) y = trial.suggestfloat("y", -100, 100) return x**2 + y
storage = JournalStorage(JournalFileStorage("./journal.log")) study = optuna.create_study(storage=storage) study.optimize(objective) ```
For more information on JournalFileStorage, see the blog post “Distributed Optimization via NFS Using Optuna’s New Operation-Based Logging Storage” written by @wattlebirdaz.
Dask Integration
DaskStorage, a new storage backend based on Dask.distributed, is supported. It enables distributed computing in similar APIs with concurrent.futures. An example code is like the following (The full example code is available in the optuna-examples repository).
```python import optuna from optuna.storages import InMemoryStorage from optuna.integration import DaskStorage from distributed import Client, wait
def objective(trial): ...
with Client("192.168.1.8:8686") as client: study = optuna.createstudy(storage=DaskStorage(InMemoryStorage())) futures = [ client.submit(study.optimize, objective, ntrials=10, pure=False) for i in range(10) ] wait(futures) print(f"Best params: {study.best_params}") ```
One of the interesting aspects is the availability of InMemoryStorage. You don’t need to set up database servers for distributed optimization. Although you still need to set up the Dask.distributed cluster, it’s quite easy like the following. See Quickstart of the Dask.distributed documentation for more details.
```python $ pip install optuna dask distributed
$ dark-scheduler INFO - Scheduler at: tcp://192.168.1.8:8686 INFO - Dashboard at: :8687 …
$ dask-worker tcp://192.168.1.8:8686 $ dask-worker tcp://192.168.1.8:8686 $ dask-worker tcp://192.168.1.8:8686
$ python dask_simple.py ```
A brand-new Redis storage
We have replaced the Redis storage backend with a JournalStorage-based one. The experimental RedisStorage class has been removed in v3.1. The following example shows how to use the new JournalRedisStorage class.
```python import optuna from optuna.storages import JournalStorage, JournalRedisStorage
def objective(trial): …
storage = JournalStorage(JournalRedisStorage("redis://localhost:6379")) study = optuna.create_study(storage=storage) study.optimize(objective) ```
Sampler for brute-force search
BruteForceSampler, a new sampler for brute-force search, tries all combinations of parameters. In contrast to GridSampler, it does not require passing the search space as an argument and works even with branches. This sampler constructs the search space with the define-by-run style, so it works by just adding sampler=optuna.samplers.BruteForceSampler().
```python import optuna
def objective(trial): c = trial.suggestcategorical("c", ["float", "int"]) if c == "float": return trial.suggestfloat("x", 1, 3, step=0.5) elif c == "int": a = trial.suggestint("a", 1, 3) b = trial.suggestint("b", a, 3) return a + b
study = optuna.create_study(sampler=optuna.samplers.BruteForceSampler()) study.optimize(objective) ```
Breaking Changes
- Allow users to call
study.optimize()in multiple threads (#4068) - Use all trials in
TPESamplereven whenmultivariate=True(#4079) - Drop Python 3.6 (#4150)
- Remove
RedisStorage(#4156) - Deprecate
set_system_attrinStudyandTrial(#4188) - Deprecate
system_attrsinStudyclass (#4250)
New Features
- Add Dask integration (#2023, thanks @jrbourbeau!)
- Add journal-style log storage (#3854)
- Support CMA-ES with margin in
CmaEsSampler(#4016) - Add journal redis storage (#4086)
- Add device argument to
BoTorchSampler(#4101) - Add the feature to
JournalStorageof Redis backend to resume from a snapshot (#4102) - Added
user_attrsto print by optuna studies incli.py(#4129, thanks @gonzaload!) - Add
BruteForceSampler(#4132, thanks @semiexp!) - Add
__getstate__and__setstate__toRedisStorage(#4135, thanks @shu65!) - Support pickle in
JournalRedisStorage(#4139, thanks @shu65!) - Support for
qNoisyExpectedHypervolumeImprovementacquisition function fromBoTorch(Issue#4014) (#4186)
Enhancements
- Change the log message format for failed trials (#3857, thanks @erentknn!)
- Move default logic of
get_trial_id_from_study_id_trial_number()method to BaseStorage (#3910) - Fix the data migration script for v3 release (#4020)
- Convert
search_spacevalues ofGridSamplerexplicitly (#4062) - Add single exception catch to study optimize (#4098)
- Add validation in
enqueue_trial(#4126) - Speed up
tests/samplers_tests/test_nsgaii.py::test_fast_non_dominated_sort_with_constraints(#4128, thanks @mist714!) - Add getstate and setstate to journal storage (#4130, thanks @shu65!)
- Support
Nonein slice plot (#4133, thanks @belldandyxtq!) - Add marker to matplotlib
plot_intermediate_value(#4134, thanks @belldandyxtq!) - Cache
study.directionsto reduce the number ofget_study_directions()calls (#4146) - Add an in-memory cache in
Trialclass (#4240)
Bug Fixes
- Fix infinite loop bug in
TPESampler(#3953, thanks @gasin!) - Fix
GridSampler(#3957) - Fix an import error of
sqlalchemy.orm.declarative_base(#3967) - Skip to add
intermediate_value_typeandvalue_typecolumns if exists (#4015) - Fix duplicated sampling of
SkoptSampler(#4023) - Avoid parse errors of
datetime.isoformatstrings (#4025) - Fix a concurrency bug of JournalStorage
set_trial_state_values(#4033) - Specify object type to numpy array init to avoid unintended str cast (#4035)
- Make
TPESamplerreproducible (#4056) - Fix bugs in
constant_liaroption (#4073) - Add a flush to
JournalFileStorage.append_logs(#4076) - Add a lock to
MLflowCallback(#4097) - Reject deprecated distributions in
OptunaSearchCV(#4120) - Stop using hash function in
_get_bracket_idinHyperbandPruner(#4131, thanks @zaburo-ch!) - Validation for the parameter enqueued in
to_internal_reprofFloatDistributionandIntDistribution(#4137) - Fix
PartialFixedSamplerto handleNonecorrectly (#4147, thanks @halucinor!) - Fix the bug of JournalFileStorage on Windows (#4151)
- Fix CmaEs system attribution key (#4184)
Installation
- Replace
thopwithfvcore(#3906) - Use the latest stable scipy (#3959, thanks @gasin!)
- Remove GPyTorch version constraint (#3986)
- Make typing_extensions optional (#3990)
- Add version constraint on
importlib-metadata(#4036) - Add a version constraint of
matplotlib(#4044)
Documentation
- Update cli tutorial (#3902)
- Replace
thopwithfvcore(#3906) - Slightly improve docs of
FrozenTrial(#3943) - Refine docs in
BaseStorage(#3948) - Remove "Edit on GitHub" button from readthedocs (#3952)
- Mention restoring sampler in saving/resuming tutorial (#3992)
- Use
log_lossinstead of deprecatedlogsincesklearn1.1 (#3993) - Fix script path in benchmarks/README.md (#4021)
- Ignore
ConvergenceWarningin the ask-and-tell tutorial (#4032) - Update docs to let users know the concurrency problem on SQLite3 (#4034)
- Fix the time complexity of
NSGAIISampler(#4045) - Fix sampler comparison table (#4082)
- Add
BruteForceSamplerin the samplers' list (#4152) - Remove markup from NaN in FAQ (#4155)
- Remove the document of the
multi_objectivemodule (#4167) - Fix a typo in
QMCSampler(#4179) - Introduce Optuna Dashboard in tutorial docs (#4226)
- Remove
RedisStoragefrom docstring (#4232) - Add the
BruteForceSamplerexample to the document (#4244) - Improve the document of
BruteForceSampler(#4245) - Fix an inline markup in distributed tutorial (#4247)
Examples
- Add Dask example (https://github.com/optuna/optuna-examples/pull/46, thanks @jrbourbeau!)
- Hotfix for botorch example (https://github.com/optuna/optuna-examples/pull/134)
- Replace
thopwithfvcore(https://github.com/optuna/optuna-examples/pull/136) - Add
Optuna-distributedto external projects (https://github.com/optuna/optuna-examples/pull/137) - Remove the version constraint of GPyTorch (https://github.com/optuna/optuna-examples/pull/138)
- Fix a file path in
CONTRIBUTING.md(https://github.com/optuna/optuna-examples/pull/139) - Install
scikit-learninstead ofsklearn(https://github.com/optuna/optuna-examples/pull/141) - Add constraint on
tensorflowto<2.11.0(https://github.com/optuna/optuna-examples/pull/146) - Specify botorch version (https://github.com/optuna/optuna-examples/pull/151)
- Pin numpy version to
1.23.xfor mxnet examples (https://github.com/optuna/optuna-examples/pull/154)
Tests
- Suppress warnings in
tests/test_distributions.py(#3912) - Suppress warnings and minor code fixes in
tests/trial_tests(#3914) - Reduce warning messages by
tests/study_tests/(#3915) - Remove dynamic search space based objective from a parallel job test (#3916)
- Remove all warning messages from
tests/integration_tests/test_sklearn.py(#3922) - Remove out-of-range related warning messages from
MLflowCallbackandWeightsAndBiasesCallback(#3923) - Ignore
RuntimeWarningwhennanminandnanmaxtake an array only containing nan values frompruners_tests(#3924) - Remove warning messages from test files for
pytorch_distributedandchainermnmodules (#3927) - Remove warning messages from
tests/integration_tests/test_lightgbm.py(#3944) - Resolve warnings in
tests/visualization_tests/test_contour.py(#3954) - Reduced warning messages from
tests/visualization_tests/test_slice.py(#3970, thanks @jmsykes83!) - Remove warning from a few visualizaiton tests (#3989)
- Deselect integration tests in Tests CI (#4013)
- Remove warnings from
tests/visualization_tests/test_optimization_history.py(#4024) - Unset
PYTHONHASHSEEDfor the hash-depedenet test (#4031) - Test: calling
study.tellfrom another process (#4039, thanks @Abelarm!) - Improve test for heartbeat: Add test for the case that trial state should be kept running (#4055)
- Remove warnings in the test of Paretopereto front (#4072)
- Remove matplotlib
get_cmapwarning fromtests/visualization_tests/test_param_importances.py(#4095) - Reduce tests'
n_trialsfor CI time reduction (#4117) - Skip
test_pop_waiting_trial_thread_safeon RedisStorage (#4119) - Simplify the test of
BruteForceSamplerfor infinite search space (#4153) - Add sep-CMA-ES in
parametrize_sampler(#4154) - Fix a broken test for
dask.distributedintegration (#4170) - Add
DaskStorageto existing storage tests (#4176, thanks @jrbourbeau!) - Fix a test error in
test_catboost.py(#4190) - Remove
test/integration_tests/test_sampler.py(#4204)
Code Fixes
- Refactor
_tell.py(#3841) - Make log message user-friendly when objective returns a sequence of unsupported values (#3868)
- Gather mask of None parameter in
TPESampler(#3886) - Update cli tutorial (#3902)
- Migrate CLI from
clifftoargparse(#4100) - Enable mypy
--no-implicit-reexportoption (#4110) - Remove unused function:
find_any_distribution(#4127) - Remove object inheritance from base classes (#4161)
- Use mlflow 2.0.1 syntax (#4173)
- Simplify implementation of
_preprocess_argvin CLI (#4187) - Move
_solve_hsspto_hypervolume/utils.py(#4227, thanks @jpbianchi!) - Avoid to decode log string in
JournalRedisStorage(#4246)
Continuous Integration
- Hotfix
botorchmodule by adding the version constraint ofgpytorch(#3950) - Drop python 3.6 from integration CIs (#3983)
- Use PyTorch 1.11 for consistency and fix a typo (#3987)
- Support Python 3.11 (#4018)
- Remove
# type: ignorefor mypy 0.981 (#4019) - Fix metric inconsistency between bayesmark plots and report (#4077)
- Pin Ubuntu version to 20.04 in
TestsandTests (Storage with server)(#4118) - Add workflow to test Optuna with lower versions of constraints (#4125)
- Mark some tests slow and ignore in pull request trigger (#4138, thanks @mist714!)
- Allow display names to be changed in benchmark scripts (Issue #4017) (#4145)
- Disable scheduled workflow runs in forks (#4159)
- Remove the CircleCI job
document(#4160) - Stop running reproducibility tests on CI for PR (#4162)
- Stop running reproducibility tests for coverage (#4163)
- Add
workflow_dispatchtrigger to the integration tests (#4166) - [hotfix] Fix CI errors when using
mlflow==2.0.1(#4171) - Add
fakeredisin benchmark deps (#4177) - Fix
asvspeed benchmark (#4185) - Skip tests with minimum version for Python 3.10 and 3.11 (#4199)
- Split normal tests and tests with minimum versions (#4200)
- Update action/checkout@v2 -> v3 (#4206)
- Update actions/stale@v5 -> v6 (#4208)
- Pin
botorchto avoid CI failure (#4228) - Add the
pytestdependency for asv (#4243)
Other
- Bump up version number to 3.1.0.dev (#3934)
- Remove the news section on README (#3940)
- Add issue template for code fix (#3968)
- Close stale issues immediately after labeling
stale(#4071) - Remove
tox.ini(#4078) - Replace gitter with GitHub Discussions (#4083)
- Deprecate description-checked label (#4090)
- Make
days-before-issue-stale300 days (#4091) - Unnecessary space removed (#4109, thanks @gonzaload!)
- Add note not to share pickle files in bug reports (#4212)
- Update the description of optuna-dashboard on README (#4217)
- Remove
optuna.TYPE_CHECKING(#4238) - Bump up version to v3.1.0-b0 (#4262)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Abelarm, @Alnusjaponica, @HideakiImamura, @amylase, @belldandyxtq, @c-bata, @contramundum53, @cross32768, @erentknn, @eukaryo, @g-votte, @gasin, @gen740, @gonzaload, @halucinor, @himkt, @hvy, @jmsykes83, @jpbianchi, @jrbourbeau, @keisuke-umezawa, @knshnb, @mist714, @ncclementi, @not522, @nzw0301, @rene-rex, @semiexp, @shu65, @sile, @toshihikoyanase, @wattlebirdaz, @xadrianzetx, @zaburo-ch
- Python
Published by contramundum53 over 3 years ago
optuna - v3.0.5
This is the release note of v3.0.5.
Bug Fixes
- [Backport] Fix bugs in
constant_liaroption (#4257)
Other
- Bump up version number to 3.0.5 (#4256)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@HideakiImamura, @eukaryo, @toshihikoyanase
- Python
Published by toshihikoyanase over 3 years ago
optuna - v3.0.4
This is the release note of v3.0.4.
Bug Fixes
- [Backport] Specify object type to numpy array init to avoid unintended str cast (#4218)
Other
- Bump up version to v3.0.4 (#4214)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@HideakiImamura, @contramundum53
- Python
Published by HideakiImamura over 3 years ago
optuna - v3.0.3
This is the release note of v3.0.3.
Enhancements
- [Backport] Fix the data migration script for v3 release (#4053)
Bug Fixes
- [Backport] Skip to add
intermediate_value_typeandvalue_typecolumns if exists (#4052)
Installation
- Backport #4036 and #4044 to pass tests on
release-v3.0.3branch (#4043)
Other
- Bump up version to v3.0.3 (#4041)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@c-bata, @contramundum53
- Python
Published by c-bata over 3 years ago
optuna - v3.0.2
This is the release note of v3.0.2.
Highlights
Bug fix for DB migration with SQLAlchemy v1.3
In v3.0.0 or v3.0.1, DB migration fails with SQLAlchemy v1.3. We fixed this issue in v3.0.2.
Removing typing-extensions from dependency
In v3.0.0, typing-extensions was used for fine-grained type checking. However, that resulted in import failures when using older versions of typing-extensions. We made the dependency optional in v3.0.2.
Bug Fixes
- [Backport] Merge pull request #3967 from c-bata/fix-issue-3966 (#4004)
Installation
- [Backport] Merge pull request #3990 from c-bata/make-typing-extensions-optional (#4005)
Others
- Bump up version number to v3.0.2 (#3991)
Thanks to All the Contributors!
@contramundum53, @c-bata
This release was made possible by the authors and the people who participated in the reviews and discussions.
- Python
Published by c-bata almost 4 years ago
optuna - v3.0.1
This is the release note of v3.0.1.
Highlights
Bug fix for GridSampler with RDB
In v3.0.0, GridSampler with RDB raises an error. This patch fixes this combination.
Bug Fixes
- Backport #3957 (#3972)
Others
- Bump up version number to v3.0.1 (#3973)
Thanks to All the Contributors!
@HideakiImamura, @contramundum53, @not522
This release was made possible by the authors and the people who participated in the reviews and discussions.
- Python
Published by contramundum53 almost 4 years ago
optuna - v3.0.0
This is the release note of v3.0.0.
This is not something you have to read from top to bottom to learn about the summary of Optuna v3. The recommended way is reading the release blog.
If you want to update your existing projects from Optuna v2.x to Optuna v3, please see the migration guide and try out Optuna v3.
Highlights
New Features
New NSGA-II Crossover Options
New crossover options are added to NSGA-II sampler, the default multi-objective algorithm of Optuna. The performance for floating point parameters are improved. Please visit #2903, #3221, and the document for more information.

A New Algorithm: Quasi-Monte Carlo Sampler
Quasi-Monte Carlo sampler is now supported. It can be used in place of RandomSampler, and can improve performance especially for high dimensional problems. See #2423, #2964, and the document for more information.

Constrained Optimization Support for TPE
TPESampler now supports constraint-aware optimization. For more information on this feature, please visit #3506 and the document.
| Without constraints | With constraints |
| - | - |
|  |
|  |
|
Constraints Support for Pareto-front Plot
Pareto-front plot now shows which trials satisfy the constraints and which do not. For more information, please see the following PRs (#3128, #3497, and #3389) and the document.

A New Importance Evaluator: ShapleyImportanceEvaluator
We introduced a new importance evaluator, optuna.integration.ShapleyImportanceEvaluator, which uses SHAP. See #3507 and the document for more information.

New History Visualization with Multiple Studies
Optimization history plot can now compare multiple studies or display the mean and variance of multiple studies optimized with the same settings. For more information, please see the following multiple PRs (#2807, #3062, #3122, and #3736) and the document.


Improved Stability
Optuna has a number of core APIs. One being the suggest API and the optuna.Study class. The visualization module is also frequently used to analyze results. Many of these have been simplified, stabilized, and refactored in v3.0.
Simplified Suggest API
The suggest API has been aggregated into 3 APIs: suggest_float for floating point parameters, suggest_int for integer parameters, and suggest_catagorical for categorical parameters. For more information, see #2939, #2941, and PRs submitted for those issues.
Introduction of a Test Policy
We have developed and published a test policy in v3.0 that defines how tests for Optuna should be written. Based on the published test policy, we have improved many unit tests. For more information, see https://github.com/optuna/optuna/issues/2974 and PRs with test label.
Visualization Refactoring
Optuna's visualization module had a deep history and various debts. We have worked throughout v3.0 to eliminate this debt with the help of many contributors. See #2893, #2913, #2959 and PRs submitted for those issues.
Stabilized Features
Through the development of v3.0, we have decided to provide many experimental features as stable features by going through their behavior, fixing bugs, and analyzing use cases. The following is a list of features that have been stabilized in v3.0.
- optuna.study.MaxTrialsCallback
- optuna.study.Study.enqueue_trial
- optuna.study.Study.add_trial
- optuna.study.Study.add_trials
- optuna.study.copy_study
- optuna.trial.create_trial
- optuna.visualization.plotparetofront
Performance Verification
Optuna has many algorithms implemented, but many of their behaviors and characteristics are unknown to the user. We have developed the following table to inform users of empirically known behaviors and characteristics. See #3571 and #3593 for more details.
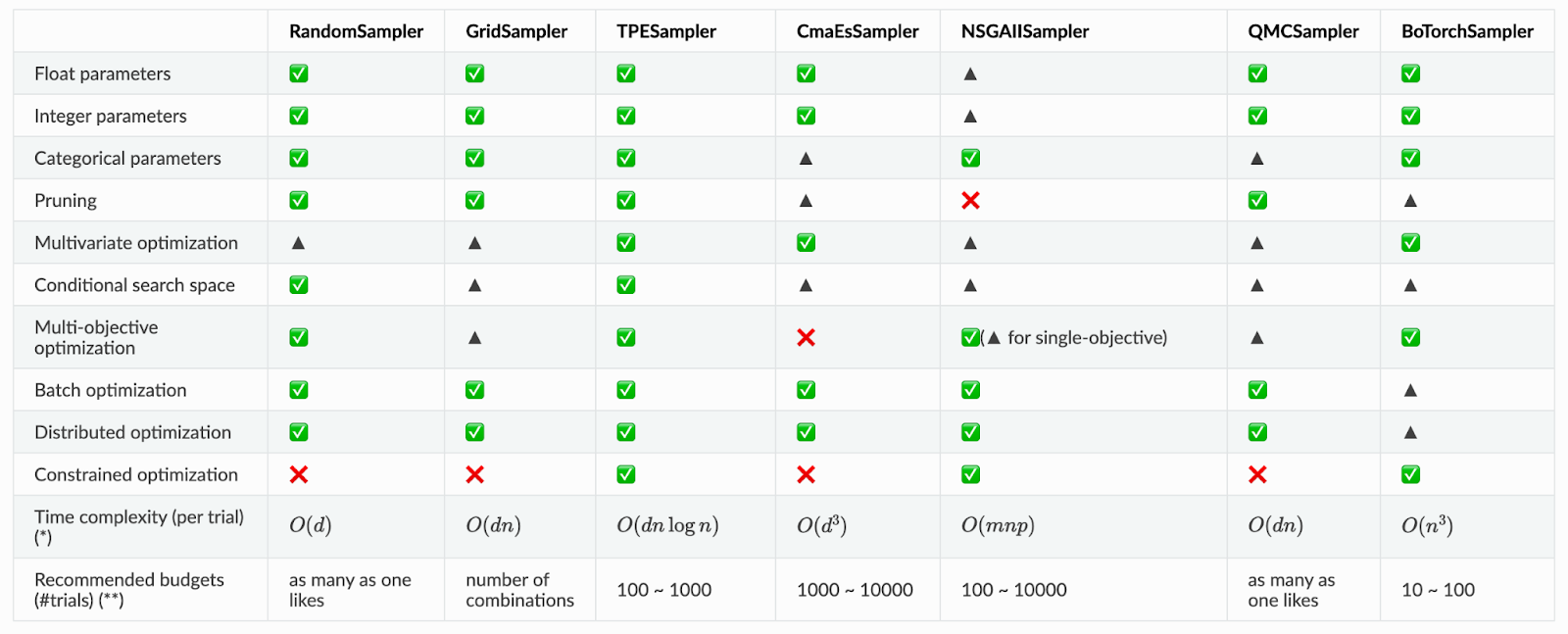
To quantitatively assess the performance of our algorithms, we have developed a benchmarking environment. We also evaluated the performance of the algorithms by conducting actual benchmarking experiments using this environment. See here, #2964, and #2906 for more details.

Breaking Changes
Changes to the RDB schema:
- To use Optuna v3.0.0 with
RDBStoragethat was created in the previous versions of Optuna, please executeoptuna storage upgradeto migrate your database (#3113, #3559, #3603, #3668).
Features deprecated in 3.0:
suggest_uniform(),suggest_loguniform(), andsuggest_discrete_uniform()UniformDistribution,LogUniformDistribution,DiscreteUniformDistribution,IntUniformDistribution, andIntLogUniformDistribution(#3246, #3420)- Positional arguments of
create_study(),load_study(),delete_study(), andcreate_study()(#3270) axis_orderargument ofplot_pareto_front()(#3341)
Features removed in 3.0:
optuna dashboardcommand (#3058)optuna.structsmodule (#3057)best_boosterproperty ofLightGBMTuner(#3057)type_checkingmodule (#3235)
Minor breaking changes:
- Add option to exclude best trials from study summaries (#3109)
- Move validation logic from
_run_trialtostudy.tell(#3144) - Use an enqueued parameter that is out of range from suggest API (#3298)
- Fix distribution compatibility for linear and logarithmic distribution (#3444)
- Remove
get_study_id_from_trial_id, the method ofBaseStorage(#3538)
New Features
- Add interval for LightGBM callback (#2490)
- Allow multiple studies and add error bar option to
plot_optimization_history(#2807) - Support PyTorch-lightning DDP training (#2849, thanks @tohmae!)
- Add crossover operators for NSGA-II (#2903, thanks @yoshinobc!)
- Add abbreviated JSON formats of distributions (#2905)
- Extend
MLflowCallbackinterface (#2912, thanks @xadrianzetx!) - Support AllenNLP distributed pruning (#2977)
- Make
trial.user_attrslogging optional inMLflowCallback(#3043, thanks @xadrianzetx!) - Support multiple input of studies when plot with Matplotlib (#3062, thanks @TakuyaInoue-github!)
- Add
IntDistribution&FloatDistribution(#3063, thanks @nyanhi!) - Add
trial.user_attrstopareto_fronthover text (#3082, thanks @kasparthommen!) - Support error bar for Matplotlib (#3122, thanks @TakuyaInoue-github!)
- Add
optuna tellwith--skip-if-finished(#3131) - Add QMC sampler (#2423, thanks @kstoneriv3!)
- Refactor pareto front and support
constraints_funcinplot_pareto_front(#3128, thanks @semiexp!) - Add
skip_if_finishedflag toStudy.tell(#3150, thanks @xadrianzetx!) - Add
user_attrsargument toStudy.enqueue_trial(#3185, thanks @knshnb!) - Option to inherit intermediate values in
RetryFailedTrialCallback(#3269, thanks @knshnb!) - Add setter method for
DiscreteUniformDistribution.q(#3283) - Stabilize allennlp integrations (#3228)
- Stabilize
create_trial(#3196) - Add
CatBoostPruningCallback(#2734, thanks @tohmae!) - Create common API for all NSGA-II crossover operations (#3221)
- Add a history of retried trial numbers in
Trial.system_attrs(#3223, thanks @belltailjp!) - Convert all positional arguments to keyword-only (#3270, thanks @higucheese!)
- Stabilize
study.py(#3309) - Add
targetsand deprecateaxis_orderinoptuna.visualization.matplotlib.plot_pareto_front(#3341, thanks @shu65!) - Add
targetsargument toplot_pareto_plontofplotlybackend (#3495, thanks @TakuyaInoue-github!) - Support
constraints_funcinplot_pareto_frontin matplotlib visualization (#3497, thanks @fukatani!) - Calculate the feature importance with mean absolute SHAP values (#3507, thanks @liaison!)
- Make
GridSamplerreproducible (#3527, thanks @gasin!) - Replace
ValueErrorwithwarninginGridSearchSampler(#3545) - Implement
callbacksargument ofOptunaSearchCV(#3577) - Add option to skip table creation to
RDBStorage(#3581) - Add constraints option to
TPESampler(#3506) - Add
skip_if_existsargument toenqueue_trial(#3629) - Remove experimental from
plot_pareto_front(#3643) - Add
popsizeargument toCmaEsSampler(#3649) - Add
seedargument forBoTorchSampler(#3756) - Add
seedargument forSkoptSampler(#3791) - Revert AllenNLP integration back to experimental (#3822)
- Remove abstractmethod decorator from
get_trial_id_from_study_id_trial_number(#3909)
Enhancements
- Add single distribution support to
BoTorchSampler(#2928) - Speed up
import optuna(#3000) - Fix
_containsofIntLogUniformDistribution(#3005) - Render importance scores next to bars in
matplotlib.plot_param_importances(#3012, thanks @xadrianzetx!) - Make default value of
verbose_evalNoneN forLightGBMTuner/LightGBMTunerCV` to avoid conflict (#3014, thanks @chezou!) - Unify colormap of
plot_contour(#3017) - Relax
FixedTrialandFrozenTrialallowing not-contained parameters duringsuggest_*(#3018) - Raise errors if
optuna askCLI receives--sampler-kwargswithout--sampler(#3029) - Remove
_get_removed_version_from_deprecated_versionfunction (#3065, thanks @nuka137!) - Reformat labels for small importance scores in
plotly.plot_param_importances(#3073, thanks @xadrianzetx!) - Speed up Matplotlib backend
plot_contourusing SciPy'sspsolve(#3092) - Remove updates in cached storage (#3120, thanks @shu65!)
- Reduce number of queries to fetch
directions,user_attrsandsystem_attrsof study summaries (#3108) - Support
FloatDistributionacross codebase (#3111, thanks @xadrianzetx!) - Use
json.loadsto decode pruner configuration loaded from environment variables (#3114) - Show progress bar based on
timeout(#3115, thanks @xadrianzetx!) - Support
IntDistributionacross codebase (#3126, thanks @nyanhi!) - Make progress bar available with n_jobs!=1 (#3138, thanks @masap!)
- Wrap
RedisStorageinCachedStorage(#3204, thanks @masap!) - Use
functools.wrapsintrack_in_mlflowdecorator (#3216) - Make
RedisStoragefast when running multiple trials (#3262, thanks @masap!) - Reduce database query result for
Study.ask()(#3274, thanks @masap!) - Enable cache for
study.tell()(#3265, thanks @masap!) - Warn if heartbeat is used with ask-and-tell (#3273)
- Make
optuna.study.get_all_study_summaries()ofRedisStoragefast (#3278, thanks @masap!) - Improve Ctrl-C interruption handling (#3374, thanks @CorentinNeovision!)
- Use same colormap among
plotlyvisualization methods (#3376) - Make EDF plots handle trials with nonfinite values (#3435)
- Make logger message optional in
filter_nonfinite(#3438) - Set
precisionofsqlalchemy.FloatinRDBStoragetable definition (#3327) - Accept
nanintrial.report(#3348, thanks @belldandyxtq!) - Lazy import of alembic, sqlalchemy, and scipy (#3381)
- Unify pareto front (#3389, thanks @semiexp!)
- Make
set_trial_param()ofRedisStoragefaster (#3391, thanks @masap!) - Make
_set_best_trial()ofRedisStoragefaster (#3392, thanks @masap!) - Make
set_study_directions()ofRedisStoragefaster (#3393, thanks @masap!) - Make optuna compatible with wandb sweep panels (#3403, thanks @captain-pool!)
- Change "#Trials" to "Trial" in
plot_slice,plot_pareto_front, andplot_optimization_history(#3449, thanks @dubey-anshuman!) - Make contour plots handle trials with nonfinite values (#3451)
- Query studies for trials only once in EDF plots (#3460)
- Make Parallel-Coordinate plots handle trials with nonfinite values (#3471, thanks @divyanshugit!)
- Separate heartbeat functionality from
BaseStorage(#3475) - Remove
torch.distributedcalls fromTorchDistributedTrialproperties (#3490, thanks @nlgranger!) - Remove the internal logic that calculates the interaction of two or more variables in fANOVA (#3543)
- Handle inf/-inf for
trial_valuestable in RDB (#3559) - Add
intermediate_value_typecolumn to represent inf/-inf onRDBStorage(#3564) - Move
is_heartbeat_enabledfrom storage to heartbeat (#3596) - Refactor
ImportanceEvaluators(#3597) - Avoid maximum limit when MLflow saves information (#3651)
- Control metric decimal digits precision in
bayesmarkbenchmark report (#3693) - Support
infvalues for crowding distance (#3743) - Normalize importance values (#3828)
Bug Fixes
- Add tests of
sample_relativeand fix type of return values ofSkoptSamplerandPyCmaSampler(#2897) - Fix
GridSamplerwithRetryFailedTrialCallbackorenqueue_trial(#2946) - Fix the type of
trial.valuesin MLflow integration (#2991) - Fix to raise
ValueErrorfor invalidqinDiscreteUniformDistribution(#3001) - Do not call
trial.reportduring sanity check (#3002) - Fix
matplotlib.plot_contourbug (#3046, thanks @IEP!) - Handle
singledistributions infANOVAevaluator (#3085, thanks @xadrianzetx!) - Fix bug of nondeterministic behavior of
TPESamplerwhengroup=True(#3187, thanks @xuzijian629!) - Handle non-numerical params in
matplotlib.contour_plot(#3213, thanks @xadrianzetx!) - Fix log scale axes padding in
matplotlib.contour_plot(#3218, thanks @xadrianzetx!) - Handle
-infandinfvalues inRDBStorage(#3238, thanks @xadrianzetx!) - Skip limiting the value if it is
nan(#3286) - Make TPE work with a categorical variable with different choice types (#3190, thanks @keisukefukuda!)
- Fix axis range issue in
matplotlibcontour plot (#3249, thanks @harupy!) - Allow
fail_state_trialsshow warning when heartbeat is enabled (#3301) - Clip untransformed values sampled from int uniform distributions (#3319)
- Fix missing
user_attrsandsystem_attrsin study summaries (#3352) - Fix objective scale in parallel coordinate of Matplotlib (#3369)
- Fix
matplotlib.plot_parallel_coordinatewith log distributions (#3371) - Fix parallel coordinate with missing value (#3373)
- Add utility to filter trials with
infvalues from visualizations (#3395) - Return the best trial number, not worst trial number by
best_index_(#3410) - Avoid using
px.colors.sequential.Bluesthat introducespandasdependency (#3422) - Fix
_is_reverse_scale(#3424) - Import
COLOR_SCALEinside import util context (#3492) - Remove
-voption ofoptuna study set-user-attrcommand (#3499, thanks @nyanhi!) - Filter trials with nonfinite value in
optuna.visualization.plot_param_importancesandoptuna.visualization.matplotlib.plot_param_importance(#3500, thanks @takoika!) - Fix
--verboseand--quietoptions in CLI (#3532, thanks @nyanhi!) - Replace
ValueErrorwithRuntimeErroringet_best_trial(#3541) - Take the same search space as in
CategoricalDistributionbyGridSampler(#3544) - Fix
CategoricalDistributionwith NaN (#3567) - Fix NaN comparison in grid sampler (#3592)
- Fix bug in
IntersectionSearchSpace(#3666) - Remove
trial_valuesrecords whose values areNone(#3668) - Fix PostgreSQL primary key unsorted problem (#3702, thanks @wattlebirdaz!)
- Raise error on NaN in
_constrained_dominates(#3738) - Fix
inf-related issue on implementation of_calculate_nondomination_rank(#3739) - Raise errors for NaN in constraint values (#3740)
- Fix
_calculate_weightssuch that it throwsValueErroron invalid weights (#3742) - Change warning for
axis_orderofplot_pareto_front(#3802) - Fix check for number of objective values (#3808)
- Raise
ValueErrorwhen waiting trial is told (#3814) - Fix
Study.tellwith invalid values (#3819) - Fix infeasible case in NSGAII test (#3839)
Installation
- Support scikit-learn v1.0.0 (#3003)
- Pin
tensorflowandtensorflow-estimatorversions to<2.7.0(#3059) - Add upper version constraint of PyTorchLightning (#3077)
- Pin
kerasversion to<2.7.0(#3078) - Remove version constraints of
tensorflow(#3084) - Bump to
torchrelated packages (#3156) - Use
pytorch-lightning>=1.5.0(#3157) - Remove testoutput from doctest of
mlflowintegration (#3170) - Restrict
nltkversion (#3201) - Add version constraints of
setuptools(#3207) - Remove version constraint of
setuptools(#3231) - Remove Sphinx version constraint (#3237)
- Drop TensorFlow support for Python 3.6 (#3296)
- Pin AllenNLP version (#3367)
- Skip run
fastaijob on Python 3.6 (#3412) - Avoid latest
click==8.1.0that removed a deprecated feature (#3413) - Avoid latest PyTorch lightning until integration is updated (#3417)
- Revert "Avoid latest
click==8.1.0that removed a deprecated feature" (#3430) - Partially support Python 3.10 (#3353)
- Clean up
setup.py(#3517) - Remove duplicate requirements from
documentsection (#3613) - Add a version constraint of cached-path (#3665)
- Relax version constraint of
fakeredis(#3905) - Add version constraint for
typing_extensionsto useParamSpec(#3926)
Documentation
- Add note of the behavior when calling multiple
trial.report(#2980) - Add note for DDP training of
pytorch-lightning(#2984) - Add note to
OptunaSearchCVabout direction (#3007) - Clarify
n_trialsin the docs (#3016, thanks @Rohan138!) - Add a note to use pickle with different optuna versions (#3034)
- Unify the visualization docs (#3041, thanks @sidshrivastav!)
- Fix a grammatical error in FAQ doc (#3051, thanks @belldandyxtq!)
- Less ambiguous documentation for
optuna tell(#3052) - Add example for
logging.set_verbosity(#3061, thanks @drumehiron!) - Mention the tutorial of
002_configurations.pyin theTrialAPI page (#3067, thanks @makkimaki!) - Mention the tutorial of
003_efficient_optimization_algorithms.pyin theTrialAPI page (#3068, thanks @makkimaki!) - Add link from
set_user_attrsinStudyto theuser_attrsentry in Tutorial (#3069, thanks @MasahitoKumada!) - Update description for missing samplers and pruners (#3087, thanks @masaaldosey!)
- Simplify the unit testing explanation (#3089)
- Fix range description in
suggest_floatdocstring (#3091, thanks @xadrianzetx!) - Fix documentation for the package installation procedure on different OS (#3118, thanks @masap!)
- Add description of
ValueErrorandTypeErorrtoRaisessection ofTrial.report(#3124, thanks @MasahitoKumada!) - Add a note
logging_callbackonly works in single process situation (#3143) - Correct
FrozenTrial's docstring (#3161) - Promote to use of v3.0.0a0 in
README.md(#3167) - Mention tutorial of callback for
Study.optimizefrom API page (#3171, thanks @xuzijian629!) - Add reference to tutorial page in
study.enqueue_trial(#3172, thanks @knshnb!) - Fix typo in specify_params (#3174, thanks @knshnb!)
- Guide to tutorial of Multi-objective Optimization in visualization tutorial (#3182, thanks @xuzijian629!)
- Add explanation about Parallelize Optimization at FAQ (#3186, thanks @MasahitoKumada!)
- Add order in tutorial (#3193, thanks @makinzm!)
- Fix inconsistency in
distributionsdocumentation (#3222, thanks @xadrianzetx!) - Add FAQ entry for heartbeat (#3229)
- Replace AUC with accuracy in docs (#3242)
- Fix
Raisessection ofFloatDistributiondocstring (#3248, thanks @xadrianzetx!) - Add
{Float,Int}Distributionto docs (#3252) - Update explanation for metrics of
AllenNLPExecutor(#3253) - Add missing cli methods to the list (#3268)
- Add docstring for property
DiscreteUniformDistribution.q(#3279) - Add reference to tutorial page in CLI (#3267, thanks @tsukudamayo!)
- Carry over notes on
stepbehavior to new distributions (#3276) - Correct the disable condition of
show_progress_bar(#3287) - Add a document to lead FAQ and example of heartbeat (#3294)
- Add a note for
copy_study: it creates a copy regardless of its state (#3295) - Add note to recommend Python 3.8 or later in documentation build with artifacts (#3312)
- Fix crossover references in
Raisesdoc section (#3315) - Add reference to
QMCSamplerin tutorial (#3320) - Fix layout in tutorial (with workaround) (#3322)
- Scikit-learn required for
plot_param_importances(#3332, thanks @ll7!) - Add a link to multi-objective tutorial from a pareto front page (#3339, thanks @kei-mo!)
- Add reference to tutorial page in visualization (#3340, thanks @Hiroyuki-01!)
- Mention tutorials of User-Defined Sampler/Pruner from the API reference pages (#3342, thanks @hppRC!)
- Add reference to saving/resuming study with RDB backend (#3345, thanks @Hiroyuki-01!)
- Fix a typo (#3360)
- Remove deprecated command
optuna study optimizein FAQ (#3364) - Fix nit typo (#3380)
- Add see also section for
best_trial(#3396, thanks @divyanshugit!) - Updates the tutorial page for re-use the best trial (#3398, thanks @divyanshugit!)
- Add explanation about
Study.best_trialsin multi-objective optimization tutorial (#3443) - Clean up exception docstrings (#3429)
- Revise docstring in MLFlow and WandB callbacks (#3477)
- Change the parameter name from
classifiertoregressorin the code snippet ofREADME.md(#3481) - Add link to Minituna in
CONTRIBUTING.md(#3482) - Fix
benchmarks/README.mdfor thebayesmarksection (#3496) - Mention
Study.stopas a criteria to stop creating trials in document (#3498, thanks @takoika!) - Fix minor English errors in the docstring of
study.optimize(#3505) - Add Python 3.10 in supported version in
README.md(#3508) - Remove articles at the beginning of sentences in crossovers (#3509)
- Correct
FronzenTrial's docstring (#3514) - Mention specify hyperparameter tutorial (#3515)
- Fix typo in MLFlow callback (#3533)
- Improve docstring of
GridSampler's seed option (#3568) - Add the samplers comparison table (#3571)
- Replace
youtube.comwithyoutube-nocookie.com(#3590) - Fix time complexity of the samplers comparison table (#3593)
- Remove
languagefrom docs configuration (#3594) - Add documentation of SHAP integration (#3623)
- Remove news entry on Optuna user survey (#3645)
- Introduce
optuna-fast-fanova(#3647) - Add github discussions link (#3660)
- Fix a variable name of ask-and-tell tutorial (#3663)
- Clarify which trials are used for importance evaluators (#3707)
- Fix typo in
Study.optimize(#3720, thanks @29Takuya!) - Update link to plotly's jupyterlab-support page (#3722, thanks @29Takuya!)
- Update
CONTRIBUTING.md(#3726) - Remove "Edit on Github" button (#3777, thanks @cfkazu!)
- Remove duplicated period at the end of copyright (#3778)
- Add note for deprecation of
plot_pareto_front'saxis_order(#3803) - Describe the purpose of
prepare_study_with_trials(#3809) - Fix a typo in docstring of
ShapleyImportanceEvaluator(#3810) - Add a reference for MOTPE (#3838, thanks @y0z!)
- Minor fixes of sampler comparison table (#3850)
- Fix typo: Replace
trailwithtrial(#3861) - Add
.. seealso::inStudy.get_trialsandStudy.trials(#3862, thanks @jmsykes83!) - Add docstring of
TrialState.is_finished(#3869) - Fix docstring in
FrozenTrial(#3872, thanks @wattlebirdaz!) - Add note to explain when colormap reverses (#3873)
- Make
NSGAIISamplerdocs informative (#3880) - Add note for
constant_liarwith multi-objective function (#3881) - Use
copybutton_prompt_textnot to copy the bash prompt (#3882) - Fix typo in
HyperbandPruner(#3894) - Improve HyperBand docs (#3900)
- Mention reproducibility of
HyperBandPruner(#3901) - Add a new note to mention unsupported GPU case for
CatBoostPruningCallback(#3903)
Examples
- Use
RetryFailedTrialCallbackinpytorch_checkpointexample (https://github.com/optuna/optuna-examples/pull/59, thanks @xadrianzetx!) - Add Python 3.9 to CI yaml files (https://github.com/optuna/optuna-examples/pull/61)
- Replace
suggest_uniformwithsuggest_float(https://github.com/optuna/optuna-examples/pull/63) - Remove deprecated warning message in
lightgbm(https://github.com/optuna/optuna-examples/pull/64) - Pin
tensorflowandtensorflow-estimatorversions to<2.7.0(https://github.com/optuna/optuna-examples/pull/66) - Restrict upper version of
pytorch-lightning(https://github.com/optuna/optuna-examples/pull/67) - Add an external resource to
README.md(https://github.com/optuna/optuna-examples/pull/68, thanks @solegalli!) - Add pytorch-lightning DDP example (https://github.com/optuna/optuna-examples/pull/43, thanks @tohmae!)
- Install latest AllenNLP (https://github.com/optuna/optuna-examples/pull/73)
- Restrict
nltkversion (https://github.com/optuna/optuna-examples/pull/75) - Add version constraints of
setuptools(https://github.com/optuna/optuna-examples/pull/76) - Remove constraint of
setuptools(https://github.com/optuna/optuna-examples/pull/79) - Remove Python 3.6 from
haiku's CI (https://github.com/optuna/optuna-examples/pull/83) - Apply
black22.1.0 & runchecksdaily (https://github.com/optuna/optuna-examples/pull/84) - Add
hiplotexample (https://github.com/optuna/optuna-examples/pull/86) - Stop running jobs using TF with Python3.6 (https://github.com/optuna/optuna-examples/pull/87)
- Pin AllenNLP version (https://github.com/optuna/optuna-examples/pull/89)
- Add Medium link (https://github.com/optuna/optuna-examples/pull/91)
- Use official
CatBoostPruningCallback(https://github.com/optuna/optuna-examples/pull/92) - Stop running
fastaijob on Python 3.6 (https://github.com/optuna/optuna-examples/pull/93) - Specify Python version using
strin workflow files (https://github.com/optuna/optuna-examples/pull/95) - Introduce upper version constraint of PyTorchLightning (https://github.com/optuna/optuna-examples/pull/96)
- Update
SimulatedAnnealingSamplerto supportFloatDistribution(https://github.com/optuna/optuna-examples/pull/97) - Fix version of JAX (https://github.com/optuna/optuna-examples/pull/99)
- Remove constraints by #99 (https://github.com/optuna/optuna-examples/pull/100)
- Replace some methods in the
sklearnexample (https://github.com/optuna/optuna-examples/pull/102, thanks @MasahitoKumada!) - Add Python3.10 in
allennlp.yml(https://github.com/optuna/optuna-examples/pull/104) - Remove numpy (https://github.com/optuna/optuna-examples/pull/105)
- Add python 3.10 to fastai CI (https://github.com/optuna/optuna-examples/pull/106)
- Add python 3.10 to non-integration examples CIs (https://github.com/optuna/optuna-examples/pull/107)
- Add python 3.10 to Hiplot CI (https://github.com/optuna/optuna-examples/pull/108)
- Add a comma to
visualization.yml(https://github.com/optuna/optuna-examples/pull/109) - Rename WandB example to follow naming rules (https://github.com/optuna/optuna-examples/pull/110)
- Add scikit-learn version constraint for Dask-ML (https://github.com/optuna/optuna-examples/pull/112)
- Add python 3.10 to sklearn CI (https://github.com/optuna/optuna-examples/pull/113)
- Set version constraint of
protobufin PyTorch Lightning example (https://github.com/optuna/optuna-examples/pull/116) - Introduce stale bot (https://github.com/optuna/optuna-examples/pull/119)
- Use Hydra 1.2 syntax (https://github.com/optuna/optuna-examples/pull/122)
- Fix CI due to
thop(https://github.com/optuna/optuna-examples/pull/123) - Hotfix
allennlpdependency (https://github.com/optuna/optuna-examples/pull/124) - Remove unreferenced variable in
pytorch_simple.py(https://github.com/optuna/optuna-examples/pull/125) - set
OMPI_MCA_rmaps_base_oversubscribe=yesbeforempirun(https://github.com/optuna/optuna-examples/pull/126) - Add python 3.10 to
python-version(https://github.com/optuna/optuna-examples/pull/127) - Remove upper version constraint of
sklearn(https://github.com/optuna/optuna-examples/pull/128) - Move
catboostintegration line to integration section from pruning section (https://github.com/optuna/optuna-examples/pull/129) - Simplify
skimageexample (https://github.com/optuna/optuna-examples/pull/130) - Remove deprecated warning in PyTorch Lightning example (https://github.com/optuna/optuna-examples/pull/131)
- Resolve TODO task in ray example (https://github.com/optuna/optuna-examples/pull/132)
- Remove version constraint of
cached-path(https://github.com/optuna/optuna-examples/pull/133)
Tests
- Add test case of samplers for conditional objective function (#2904)
- Test int distributions with default step (#2924)
- Be aware of trial preparation when checking heartbeat interval (#2982)
- Simplify the DDP model definition in the test of
pytorch-lightning(#2983) - Wrap data with
np.asarrayinlightgbmtest (#2997) - Patch calls to deprecated
suggestAPIs across codebase (#3027, thanks @xadrianzetx!) - Make
return_cvboosterofLightGBMTunerconsistent to the original value (#3070, thanks @abatomunkuev!) - Fix
parametrize_sampler(#3080) - Fix verbosity for
tests/integration_tests/lightgbm_tuner_tests/test_optimize.py(#3086, thanks @nyanhi!) - Generalize empty search space test case to all hyperparameter importance evaluators (#3096, thanks @xadrianzetx!)
- Check if texts in legend by order agnostic way (#3103)
- Add tests for axis scales to
matplotlib.plot_slice(#3121) - Add tests for transformer with upper bound parameter (#3163)
- Add tests in
visualization_tests/matplotlib_tests/test_slice.py(#3175, thanks @keisukefukuda!) - Add test case of the value in optimization history with matplotlib (#3176, thanks @TakuyaInoue-github!)
- Add tests for generated plots of
matplotlib.plot_edf(#3178, thanks @makinzm!) - Improve pareto front figure tests for matplotlib (#3183, thanks @akawashiro!)
- Add tests for generated plots of
plot_edf(#3188, thanks @makinzm!) - Match contour tests between Plotly and Matplotlib (#3192, thanks @belldandyxtq!)
- Implement missing
matplotlib.contour_plottest (#3232, thanks @xadrianzetx!) - Unify the validation function of edf value between visualization backends (#3233)
- Add test for default grace period (#3263, thanks @masap!)
- Add the missing tests of Plotly's
plot_parallel_coordinate(#3266, thanks @MasahitoKumada!) - Switch function order progbar tests (#3280, thanks @BasLaa!)
- Add plot value tests to
matplotlib_tests/test_param_importances(#3180, thanks @belldandyxtq!) - Make tests of
plot_optimization_historymethods consistent (#3234) - Add integration test for
RedisStorage(#3258, thanks @masap!) - Change the order of arguments in the
catalystintegration test (#3308) - Cleanup
MLflowCallbacktests (#3378) - Test serialize/deserialize storage on parametrized conditions (#3407)
- Add tests for parameter of 'None' for TPE (#3447)
- Improve
matplotlibparallel coordinate test (#3368) - Save figures for all
matplotlibtests (#3414, thanks @divyanshugit!) - Add
inftest to intermediate values test (#3466) - Add test cases for
test_storages.py(#3480) - Improve the tests of
optuna.visualization.plot_pareto_front(#3546) - Move heartbeat-related tests in
test_storages.pyto another file (#3553) - Use
seedmethod ofnp.random.RandomStatefor reseeding and fixtest_reseed_rng(#3569) - Refactor
test_get_observation_pairs(#3574) - Add tests for
inf/nanobjectives forShapleyImportanceEvaluator(#3576) - Add deprecated warning test to the multi-objective sampler test file (#3601)
- Simplify multi-objective TPE tests (#3653)
- Add edge cases to multi-objective TPE tests (#3662)
- Remove tests on
TypeError(#3667) - Add edge cases to the tests of the parzen estimator (#3673)
- Add tests for
_constrained_dominates(#3683) - Refactor tests of constrained TPE (#3689)
- Add
infand NaN tests fortest_constraints_func(#3690) - Fix calling storage API in study tests (#3695, thanks @wattlebirdaz!)
- DRY
test_frozen.py(#3696) - Unify the tests of
plot_contours (#3701) - Add test cases for crossovers of NSGAII (#3705)
- Enhance the tests of
NSGAIISampler._crowding_distance_sort(#3706) - Unify edf test files (#3730)
- Fix
test_calculate_weights_below(#3741) - Refactor
test_intermediate_plot.py(#3745) - Test samplers are reproducible (#3757)
- Add tests for
_dominatesfunction (#3764) - DRY importance tests (#3785)
- Move tests for
create_trial(#3794) - Remove
with_c_doption fromprepare_study_with_trials(#3799) - Use
DeterministicRelativeSamplerintest_trial.py(#3807) - Add tests for
_fast_non_dominated_sort(#3686) - Unify slice plot tests (#3784)
- Unify the tests of
plot_parallel_coordinates (#3800) - Unify optimization history tests (#3806)
- Suppress warnings in tests for
multi_objectivemodule (#3911) - Remove
warnings: UserWarningfromtests/visualization_tests/test_utils.py(#3919, thanks @jmsykes83!)
Code Fixes
- Add test case of samplers for conditional objective function (#2904)
- Fix #2949, remove
BaseStudy(#2986, thanks @twsl!) - Use
optuna.load_studyinoptuna askCLI to omitdirection/directionsoption (#2989) - Fix typo in
Trialwarning message (#3008, thanks @xadrianzetx!) - Replaces boston dataset with california housing dataset (#3011, thanks @avats-dev!)
- Fix deprecation version of
suggestAPIs (#3054, thanks @xadrianzetx!) - Add
remove_versionto the missing@deprecatedargument (#3064, thanks @nuka137!) - Add example of
optuna.logging.get_verbosity(#3066, thanks @MasahitoKumada!) - Support
{Float|Int}Distributionin NSGA-II crossover operators (#3139, thanks @xadrianzetx!) - Black fix (#3147)
- Switch to
FloatDistribution(#3166, thanks @xadrianzetx!) - Remove
deprecateddecorator of the feature ofn_jobs(#3173, thanks @MasahitoKumada!) - Fix black and blackdoc errors (#3260, thanks @masap!)
- Remove experimental label from
MaxTrialsCallback(#3261, thanks @knshnb!) - Remove redundant
_check_trial_id(#3264, thanks @masap!) - Make existing int/float distributions wrapper of
{Int,Float}Distribution(#3244) - Switch to
IntDistribution(#3181, thanks @nyanhi!) - Fix type hints for Python 3.8 (#3240)
- Remove
UniformDistribution,LogUniformDistributionandDiscreteUniformDistributioncode paths (#3275) - Merge
set_trial_state()andset_trial_values()into one function (#3323, thanks @masap!) - Follow up for
{Float, Int}Distributions(#3337, thanks @nyanhi!) - Move the
get_trial_xxxabstract functions to base (#3338, thanks @belldandyxtq!) - Update type hints of
states(#3359, thanks @BasLaa!) - Remove unused function from
RedisStorage(#3394, thanks @masap!) - Remove unnecessary string concatenation (#3406)
- Follow coding style and fix typos in
tests/integration_tests(#3408) - Fix log message formatting in
filter_nonfinite(#3436) - Add
RetryFailedTrialCallbacktooptuna.storages.*(#3441) - Unify
fail_stale_trialsin each storage implementation (#3442, thanks @knshnb!) - Ignore incomplete trials in
matplotlib.plot_parallel_coordinate(#3415) - Update warning message and add a test when a trial fails with exception (#3454)
- Remove old distributions from NSGA-II sampler (#3459)
- Remove duplicated DB access in
_log_completed_trial(#3551) - Reduce the number of
copy.deepcopy()calls inimportancemodule (#3554) - Remove duplicated
check_trial_is_updatable(#3557) - Replace
optuna.testing.integration.create_running_trialwithstudy.ask(#3562) - Refactor
test_get_observation_pairs(#3574) - Update label of feasible trials if
constraints_funcis specified (#3587) - Replace unused variable name with underscore (#3588)
- Enable
no-implicit-optionalformypy(#3599, thanks @harupy!) - Enable
warn_redundant_castsformypy(#3602, thanks @harupy!) - Refactor the type of value of
TrialIntermediateValueModel(#3603) - Fix broken
mypychecks of Alembic'sget_current_head()method (#3608) - Move heartbeat-related thread operation in
_optimize.pyto_heartbeat.py(#3609) - Sort dependencies by name (#3614)
- Add typehint for deprecated and experimental (#3575)
- Remove useless object inheritance (#3628, thanks @harupy!)
- Remove useless
exceptclauses (#3632, thanks @harupy!) - Rename
optuna.testing.integrationwithoptuna.testing.pruner(#3638) - Cosmetic fix in Optuna CLI (#3641)
- Enable
strict_equalityformypy#3579 (#3648, thanks @wattlebirdaz!) - Make file names in testing consistent with
optunamodule (#3657) - Remove the implementation of
read_trials_from_remote_storagein the all storages apart fromCachedStorage(#3659) - Remove unnecessary deep copy in Redis storage (#3672, thanks @wattlebirdaz!)
- Workaround
mypybug (#3679) - Unify
plot_contours (#3682) - Remove
storage.get_all_study_summaries(include_best_trial: bool)(#3697, thanks @wattlebirdaz!) - Unify the logic of edf functions (#3698)
- Unify the logic of
plot_param_importancesfunctions (#3700) - Enable
disallow_untyped_callsformypy(#3704, thanks @29Takuya!) - Use
get_trialswithstatesargument to filter trials depending on trial state (#3708) - Return Python's native float values (#3714)
- Simplify
bayesmarkbenchmark report rendering (#3725) - Unify the logic of intermediate plot (#3731)
- Unify the logic of slice plot (#3732)
- Unify the logic of
plot_parallel_coordinates (#3734) - Unify implementation of
plot_optimization_historybetweenplotlyandmatplotlib(#3736) - Extract
fail_objectiveandpruned_objectivefor tests (#3737) - Remove deprecated storage functions (#3744, thanks @29Takuya!)
- Remove unnecessary optionals from
visualization/_pareto_front.py(#3752) - Change types inside
_ParetoInfoType(#3753) - Refactor pareto front (#3754)
- Use
_ContourInfoto plot inplot_contour(#3755) - Follow up #3465 (#3763)
- Refactor importances plot (#3765)
- Remove
no_trialsoption ofprepare_study_with_trials(#3766) - Follow the coding style of comments in
plot_contourfiles (#3767) - Raise
ValueErrorfor invalid returned type oftargetin_filter_nonfinite(#3768) - Fix value error condition in
plot_contour(#3769) - DRY constraints in
Sampler.after_trial(#3775) - DRY
stop_objective(#3786) - Refactor non-exist param test in
plot_contourtest (#3787) - Remove
less_than_twoandmore_than_threeoptions fromprepare_study_with_trials(#3789) - Fix return value's type of
_get_node_value(#3818) - Remove unused
type: ignore(#3832) - Fix typos and remove unused argument in
QMCSampler(#3837) - Unify tests for
plot_param_importances(#3760) - Refactor
test_pareto_front(#3798) - Remove duplicated definition of
CategoricalChoiceTypefromoptuna.distributions(#3846) - Revert most of changes by 3651 (#3848)
- Attach abstractmethod decorator to
BaseStorage.get_trial_id_from_study_id_trial_number(#3870, thanks @wattlebirdaz!) - Refactor
BaseStorage.get_best_trial(#3871, thanks @wattlebirdaz!) - Simplify
IntersectionSearchSpace.calculate(#3887) - Replace
qwithstepin private function and warning message (#3913) - Reduce warnings in storage tests (#3917)
- Reduce trivial warning messages from
tests/sampler_tests(#3921)
Continuous Integration
- Install
botorchto CI jobs on mac (#2988) - Use libomp 11.1.0 for Mac (#3024)
- Run
mac-testsCI at a scheduled time (#3028) - Set concurrency to github workflows (#3095)
- Skip CLI tests when calculating the coverage (#3097)
- Migrate
mypyversion to 0.910 (#3123) - Avoid installing the latest MLfow to prevent doctests from failing (#3135)
- Use python 3.8 for CI and docker (#3026)
- Add performance benchmarks using
kurobako(#3155) - Use Python 3.7 in checks CI job (#3239)
- Add performance benchmarks using
bayesmark(#3354) - Fix speed benchmarks (#3362)
- Pin
setuptools(#3427) - Introduce the benchmark for multi-objectives samplers (#3271, thanks @drumehiron!)
- Use
coveragedirectly (#3347, thanks @higucheese!) - Add WFG benchmark test (#3349, thanks @kei-mo!)
- Add workflow to use
reviewdog(#3357) - Add NASBench201 from NASLib (#3465)
- Fix speed benchmarks CI (#3470)
- Support PyTorch 1.11.0 (#3510)
- Install 3rd party libraries in CI for lint (#3580)
- Make
bayesmarkbenchmark results comparable tokurobako(#3584) - Restore
virtualenvfor benchmark extras (#3585) - Use
protobuf<4.0.0to resolve Sphinx CI error (#3591) - Unpin
protobuf(#3598, thanks @harupy!) - Extract MPI tests from integration CI as independent CI (#3606)
- Enable
warn_unused_ignoresformypy(#3627, thanks @harupy!) - Add
onnxand version constrainedprotobufto document dependencies (#3658) - Add
mo-kurobakobenchmark to CI (#3691) - Enable mypy's strict configs (#3710)
- Run visual regression tests to find regression bugs of visualization module (#3721)
- Remove downloading old
libompfor mac tests (#3728) - Match Python versions between
bayesmarkCI jobs (#3750) - Set
OMPI_MCA_rmaps_base_oversubscribe=yesbeforempirun(#3758) - Add
budgetoption to benchmarks (#3774) - Add
n_concurrencyoption to benchmarks (#3776) - Use
n-runsinstead ofrepeatto represent the number of studies in the bayesmark benchmark (#3780) - Fix type hints for
mypy 0.971(#3797) - Pin scipy to avoid the CI failure (#3834)
- Extract float value from tensor for
trial.reportinPyTorchLightningPruningCallback(#3842)
Other
- Bump up version to 2.11.0dev (#2976)
- Add roadmap news to
README.md(#2999) - Bump up version number to 3.0.0a1.dev (#3006)
- Add Python 3.9 to
tox.ini(#3025) - Fix version number to 3.0.0a0 (#3140)
- Bump up version to v3.0.0a1.dev (#3142)
- Introduce a form to make TODOs explicit when creating issues (#3169)
- Bump up version to
v3.0.0b0.dev(#3289) - Add description field for
question-and-help-support(#3305) - Update README to inform
v3.0.0a2(#3314) - Add Optuna-related URLs for PyPi (#3355, thanks @andriyor!)
- Bump Optuna to
v3.0.0-b0(#3458) - Bump up version to v3.0.0b1.dev (#3457)
- Fix
kurobakobenchmark code to run it locally (#3468) - Fix label of issue template (#3493)
- Improve issue templates (#3536)
- Hotfix for
fakeredis1.7.4 release (#3549) - Remove the version constraint of
fakeredis(#3561) - Relax version constraint of
fakeredis(#3607) - Shorten the durations of the stale bot for PRs (#3611)
- Clarify the criteria to assign reviewers in the PR template (#3619)
- Bump up version number to v3.0.0rc0.dev (#3621)
- Make
tox.iniconsistent withchecking(#3654) - Avoid to stale description-checked issues (#3816)
- Bump up version to v3.0.0.dev (#3852)
- Bump up version to v3.0.0 (#3933)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@29Takuya, @BasLaa, @CorentinNeovision, @Crissman, @HideakiImamura, @Hiroyuki-01, @IEP, @MasahitoKumada, @Rohan138, @TakuyaInoue-github, @abatomunkuev, @akawashiro, @andriyor, @avats-dev, @belldandyxtq, @belltailjp, @c-bata, @captain-pool, @cfkazu, @chezou, @contramundum53, @divyanshugit, @drumehiron, @dubey-anshuman, @fukatani, @g-votte, @gasin, @harupy, @higucheese, @himkt, @hppRC, @hvy, @jmsykes83, @kasparthommen, @kei-mo, @keisuke-umezawa, @keisukefukuda, @knshnb, @kstoneriv3, @liaison, @ll7, @makinzm, @makkimaki, @masaaldosey, @masap, @nlgranger, @not522, @nuka137, @nyanhi, @nzw0301, @semiexp, @shu65, @sidshrivastav, @sile, @solegalli, @takoika, @tohmae, @toshihikoyanase, @tsukudamayo, @tupui, @twsl, @wattlebirdaz, @xadrianzetx, @xuzijian629, @y0z, @yoshinobc, @ytsmiling
- Python
Published by HideakiImamura almost 4 years ago
optuna - v3.0.0-rc0
This is the release note of v3.0.0-rc0. This is a release candidate of Optuna V3. We plan to release the major version within a few weeks. Please try this version and report bugs!
Highlights
Constrained Optimization Support for TPE
TPESampler, the default sampler of Optuna, now supports constrained optimization. It takes a function constraints_func as an argument, and examines whether trials are feasible or not. Feasible trials are prioritized over infeasible ones similarly to NSGAIISampler. See #3506 for more details.
```python def objective(trial): # Binh and Korn function with constraints. x = trial.suggestfloat("x", -15, 30) y = trial.suggestfloat("y", -15, 30)
# Store the constraints as user attributes so that they can be restored after optimization.
c0 = (x - 5) ** 2 + y ** 2 - 25
c1 = -((x - 8) ** 2) - (y + 3) ** 2 + 7.7
trial.set_user_attr("constraints", (c0, c1))
v0 = 4 * x ** 2 + 4 * y ** 2
v1 = (x - 5) ** 2 + (y - 5) ** 2
return v0, v1
def constraints(trial): return trial.user_attrs["constraints"]
if name == "main": sampler = optuna.samplers.TPESampler( constraintsfunc=constraints, ) study = optuna.createstudy( directions=["minimize", "minimize"], sampler=sampler, ) study.optimize(objective, n_trials=1000)
optuna.visualization.plot_pareto_front(study, constraints_func=constraints).show()
```
| MOTPE without constraints | MOTPE with constraints |
| - | - |
|  |
|  |
|
A Major Refactoring of Visualization Module
We have undertaken major refactoring of the visualization features as one of the major tasks of Optuna V3. The current situation is as follows.
Unification of implementations of different backends: plotly and matplotlib
Historically, the implementations of Optuna's visualization features were split between two different backends, plotly and matplotlib. Many of these implementations were duplicated and unmaintainable, and many were implemented as a single large function, resulting in poor testability and, as a result, becoming the cause of many bugs. We clarified the specifications that each visualization function in Optuna must meet and defined the backend-independent information needed to perform the visualization. By using this information commonly across different backends, we achieved a highly maintainable and testable implementation, and improved the stability of the visualization functions dramatically. We are currently rewriting the unit tests, and the resulting tests will be simple yet powerful.
Visual Regression Test
It is very important to detect hidden bugs in the implementation through PR reviews. However, visualizations are likely to contain bugs that are difficult to find just by reading the code, and many of these bugs are only revealed when the visualization is actually performed. Therefore, we introduced the Visual Regression Test to improve the review process. In the PR for visualization features, you can jump to the Visual Regression Test link by clicking on the link generated from within the PR. Reviewers can verify that the PR implementation is performing the visualization properly.

Improve Code Quality Including Many Bugfix
In the latter development cycle of Optuna v3, we put emphasis on improving the overall code quality of the library. We fixed several bugs and possible corruption of internal data structures on e.g. handling Inf/NaN values (#3567, #3592, #3738, #3739, #3740) and invalid inputs (#3668, #3808, #3814, #3819). For example, there had been bugs before v3 when NaN values were used in a CategoricalDistribution or GridSampler. In several other functions, NaN values were unacceptable but the library failed silently without any warning or error. Such bugs are fixed in this release.
New Features
- Add constraints option to
TPESampler(#3506) - Add
skip_if_existsargument toenqueue_trial(#3629) - Remove experimental from
plot_pareto_front(#3643) - Add
popsizeargument toCmaEsSampler(#3649) - Add
seedargument forBoTorchSampler(#3756) - Add
seedargument forSkoptSampler(#3791) - Revert AllenNLP integration back to experimental (#3822)
Enhancements
- Move
is_heartbeat_enabledfrom storage to heartbeat (#3596) - Refactor
ImportanceEvaluators(#3597) - Avoid maximum limit when MLflow saves information (#3651)
- Control metric decimal digits precision in
bayesmarkbenchmark report (#3693) - Support
infvalues for crowding distance (#3743) - Normalize importance values (#3828)
Bug Fixes
- Fix
CategoricalDistributionwith NaN (#3567) - Fix NaN comparison in grid sampler (#3592)
- Fix bug in
IntersectionSearchSpace(#3666) - Remove
trial_valuesrecords whose values areNone(#3668) - Fix PostgreSQL primary key unsorted problem (#3702, thanks @wattlebirdaz!)
- Raise error on NaN in
_constrained_dominates(#3738) - Fix
inf-related issue on implementation of_calculate_nondomination_rank(#3739) - Raise errors for NaN in constraint values (#3740)
- Fix
_calculate_weightssuch that it throwsValueErroron invalid weights (#3742) - Change warning for
axis_orderofplot_pareto_front(#3802) - Fix check for number of objective values (#3808)
- Raise
ValueErrorwhen waiting trial is told (#3814) - Fix
Study.tellwith invalid values (#3819) - Fix infeasible case in NSGAII test (#3839)
Installation
- Add a version constraint of cached-path (#3665)
Documentation
- Add documentation of SHAP integration (#3623)
- Remove news entry on Optuna user survey (#3645)
- Introduce
optuna-fast-fanova(#3647) - Add github discussions link (#3660)
- Fix a variable name of ask-and-tell tutorial (#3663)
- Clarify which trials are used for importance evaluators (#3707)
- Fix typo in
Study.optimize(#3720, thanks @29Takuya!) - Update link to plotly's jupyterlab-support page (#3722, thanks @29Takuya!)
- Update
CONTRIBUTING.md(#3726) - Remove "Edit on Github" button (#3777, thanks @cfkazu!)
- Remove duplicated period at the end of copyright (#3778)
- Add note for deprecation of
plot_pareto_front'saxis_order(#3803) - Describe the purpose of
prepare_study_with_trials(#3809) - Fix a typo in docstring of
ShapleyImportanceEvaluator(#3810) - Add a reference for MOTPE (#3838, thanks @y0z!)
Examples
- Introduce stale bot (https://github.com/optuna/optuna-examples/pull/119)
- Use Hydra 1.2 syntax (https://github.com/optuna/optuna-examples/pull/122)
- Fix CI due to
thop(https://github.com/optuna/optuna-examples/pull/123) - Hotfix
allennlpdependency (https://github.com/optuna/optuna-examples/pull/124) - Remove unreferenced variable in
pytorch_simple.py(https://github.com/optuna/optuna-examples/pull/125) - set
OMPI_MCA_rmaps_base_oversubscribe=yesbeforempirun(https://github.com/optuna/optuna-examples/pull/126)
Tests
- Simplify multi-objective TPE tests (#3653)
- Add edge cases to multi-objective TPE tests (#3662)
- Remove tests on
TypeError(#3667) - Add edge cases to the tests of the parzen estimator (#3673)
- Add tests for
_constrained_dominates(#3683) - Refactor tests of constrained TPE (#3689)
- Add
infand NaN tests fortest_constraints_func(#3690) - Fix calling storage API in study tests (#3695, thanks @wattlebirdaz!)
- DRY
test_frozen.py(#3696) - Unify the tests of
plot_contours (#3701) - Add test cases for crossovers of NSGAII (#3705)
- Enhance the tests of
NSGAIISampler._crowding_distance_sort(#3706) - Unify edf test files (#3730)
- Fix
test_calculate_weights_below(#3741) - Refactor
test_intermediate_plot.py(#3745) - Test samplers are reproducible (#3757)
- Add tests for
_dominatesfunction (#3764) - DRY importance tests (#3785)
- Move tests for
create_trial(#3794) - Remove
with_c_doption fromprepare_study_with_trials(#3799) - Use
DeterministicRelativeSamplerintest_trial.py(#3807)
Code Fixes
- Add typehint for deprecated and experimental (#3575)
- Move heartbeat-related thread operation in
_optimize.pyto_heartbeat.py(#3609) - Remove useless object inheritance (#3628, thanks @harupy!)
- Remove useless
exceptclauses (#3632, thanks @harupy!) - Rename
optuna.testing.integrationwithoptuna.testing.pruner(#3638) - Cosmetic fix in Optuna CLI (#3641)
- Enable
strict_equalityformypy#3579 (#3648, thanks @wattlebirdaz!) - Make file names in testing consistent with
optunamodule (#3657) - Remove the implementation of
read_trials_from_remote_storagein the all storages apart fromCachedStorage(#3659) - Remove unnecessary deep copy in Redis storage (#3672, thanks @wattlebirdaz!)
- Workaround
mypybug (#3679) - Unify
plot_contours (#3682) - Remove
storage.get_all_study_summaries(include_best_trial: bool)(#3697, thanks @wattlebirdaz!) - Unify the logic of edf functions (#3698)
- Unify the logic of
plot_param_importancesfunctions (#3700) - Enable
disallow_untyped_callsformypy(#3704, thanks @29Takuya!) - Use
get_trialswithstatesargument to filter trials depending on trial state (#3708) - Return Python's native float values (#3714)
- Simplify
bayesmarkbenchmark report rendering (#3725) - Unify the logic of intermediate plot (#3731)
- Unify the logic of slice plot (#3732)
- Unify the logic of
plot_parallel_coordinates (#3734) - Unify implementation of
plot_optimization_historybetweenplotlyandmatplotlib(#3736) - Extract
fail_objectiveandpruned_objectivefor tests (#3737) - Remove deprecated storage functions (#3744, thanks @29Takuya!)
- Remove unnecessary optionals from
visualization/_pareto_front.py(#3752) - Change types inside
_ParetoInfoType(#3753) - Refactor pareto front (#3754)
- Use
_ContourInfoto plot inplot_contour(#3755) - Follow up #3465 (#3763)
- Refactor importances plot (#3765)
- Remove
no_trialsoption ofprepare_study_with_trials(#3766) - Follow the coding style of comments in
plot_contourfiles (#3767) - Raise
ValueErrorfor invalid returned type oftargetin_filter_nonfinite(#3768) - Fix value error condition in
plot_contour(#3769) - DRY constraints in
Sampler.after_trial(#3775) - DRY
stop_objective(#3786) - Refactor non-exist param test in
plot_contourtest (#3787) - Remove
less_than_twoandmore_than_threeoptions fromprepare_study_with_trials(#3789) - Fix return value's type of
_get_node_value(#3818) - Remove unused
type: ignore(#3832) - Fix typos and remove unused argument in
QMCSampler(#3837)
Continuous Integration
- Use
coveragedirectly (#3347, thanks @higucheese!) - Install 3rd party libraries in CI for lint (#3580)
- Make
bayesmarkbenchmark results comparable tokurobako(#3584) - Enable
warn_unused_ignoresformypy(#3627, thanks @harupy!) - Add
onnxand version constrainedprotobufto document dependencies (#3658) - Add
mo-kurobakobenchmark to CI (#3691) - Enable mypy's strict configs (#3710)
- Run visual regression tests to find regression bugs of visualization module (#3721)
- Remove downloading old
libompfor mac tests (#3728) - Match Python versions between
bayesmarkCI jobs (#3750) - Set
OMPI_MCA_rmaps_base_oversubscribe=yesbeforempirun(#3758) - Add
budgetoption to benchmarks (#3774) - Add
n_concurrencyoption to benchmarks (#3776) - Use
n-runsinstead ofrepeatto represent the number of studies in the bayesmark benchmark (#3780) - Fix type hints for
mypy 0.971(#3797) - Pin scipy to avoid the CI failure (#3834)
- Extract float value from tensor for
trial.reportinPyTorchLightningPruningCallback(#3842)
Other
- Clarify the criteria to assign reviewers in the PR template (#3619)
- Bump up version number to v3.0.0rc0.dev (#3621)
- Make
tox.iniconsistent withchecking(#3654) - Avoid to stale description-checked issues (#3816)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@29Takuya, @HideakiImamura, @c-bata, @cfkazu, @contramundum53, @g-votte, @harupy, @higucheese, @himkt, @hvy, @keisuke-umezawa, @knshnb, @not522, @nzw0301, @sile, @toshihikoyanase, @wattlebirdaz, @xadrianzetx, @y0z
- Python
Published by HideakiImamura almost 4 years ago
optuna - v2.10.1
This is the release note of v2.10.1.
This is a patch release to resolve the issues on the document build. No feature updates are included.
Installation
- Fix document build of v2.10.1 (#3642)
Documentation
- Backport #3590: Replace
youtube.comwithyoutube-nocookie.com(#3633)
Other
- Bump up version to v2.10.1 (#3635)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@contramundum53, @toshihikoyanase
- Python
Published by contramundum53 about 4 years ago
optuna - v3.0.0-b1
This is the release note of v3.0.0-b1.
Highlights
A Samplers Comparison Table
We added a sampler comparison table on the samplers' documentation page. It includes supported options (parameter types, pruning, multi-objective optimization, constrained optimization, etc.), time complexity, and recommended budgets for each sampler. Please use this to select appropriate samplers for your tasks! See #3571 and #3593 for more details.

A New Importance Evaluator: ShapleyImportanceEvaluator
Optuna now supports mean absolute SHAP value for evaluating parameter importances through integration with the SHAP library. SHAP value is a game-theoretic measure of parameter importance featuring nice theoretical properties (See paper for more information).

To use mean absolute SHAP importances, an object of optuna.integration.shap.ShapleyImportanceEvaluator can be passed to evaluator argument in optuna.visualization.plot_param_importances or optuna.importance.get_param_importances.
``` import optuna from optuna.integration.shap import ShapleyImportanceEvaluator
study = optuna.createstudy() study.optimize(objective, ntrials=100)
optuna.visualization.plotparamimportances(study, evaluator=ShapleyImportanceEvaluator()) ```
See the #3507 for more details.
A New Benchmarking Task
The benchmarking environment for black-box optimization algorithms on the GitHub Actions was introduced in the previous release. We have further enhanced its capabilities. The benchmarking functionality introduced can be run on all users' forks using GitHub Actions. You can also freely customize and run benchmarks on more computationally powerful clusters, for example, AWS, using the code in the optuna/benchmarks directory.
Neural Architecture Search Benchmark Support
Optuna's algorithms can now be benchmarked using NASLib, the Neural Architecture Search benchmark library. For now we only support one dataset, NASBench 201, which deals with image recognition. Larger datasets and datasets from other areas such as natural language processing will be supported in the future.
| cifar10 | cifar100 | imagenet16-120|
| ---- | ---- | ---- |
|  |
|  |
|  |
|
See README and #3465 for more information.
Multi-objective Optimization Benchmark Support
We are now able to benchmark our multi-objective optimization algorithms. They are not yet available on GitHub Actions, but you can use optuna/benchmarks/run_mo_kurobakmo.py directly. They will be available on GitHub Actions in the next release, so stay tuned! See #3271 and #3349 for more details.
Python 3.10 Support
This is the first version to officially support Python 3.10. All tests are passed including integration modules, with a few exceptions.
Storage Database Migration
To use Optuna v3.0.0-b1 with RDBStorage that was created in the previous versions of Optuna, please run optuna storage upgrade to migrate your database.
```sh
YOUR_RDB_URL is the URL of your database.
optuna storage upgrade –storage YOURRDBURL ```
If you use RedisStorage, copy your study with RDBStorage using copy_study with the Optuna you used to create the study, thenrun optuna storage upgrade with Optuna v3.0.0-b0. After upgrading the storage, copy the study back as a new RedisStorage.
sh
python -c ‘import optuna; optuna.copy_study(from_study_name=”example”, from_storage=”redis://localhost:6379”, to_storage=”sqlite:///upgrade.db”)
pip install –pre -U optuna
optuna storage upgrade –storage sqlite:///upgrade.db
python -c ‘import optuna; optuna.copy_study(from_study_name="example", from_storage="sqlite:///upgrade.db", to_study_name="new-example", to_storage="redis://localhost:6379")’
Breaking Changes
- Fix distribution compatibility for linear and logarithmic distribution (#3444)
- Remove
get_study_id_from_trial_id(#3538)
New Features
- Add
targetsargument toplot_pareto_plontofplotlybackend (#3495, thanks @TakuyaInoue-github!) - Support
constraints_funcinplot_pareto_frontin matplotlib visualization (#3497, thanks @fukatani!) - Calculate the feature importance with mean absolute SHAP values (#3507, thanks @liaison!)
- Make
GridSamplerreproducible (#3527, thanks @gasin!) - Replace
ValueErrorwithwarninginGridSearchSampler(#3545) - Implement
callbacksargument ofOptunaSearchCV(#3577) - Add option to skip table creation to
RDBStorage(#3581)
Enhancements
- Set
precisionofsqlalchemy.FloatinRDBStoragetable definition (#3327) - Accept
nanintrial.report(#3348, thanks @belldandyxtq!) - Lazy import of alembic, sqlalchemy, and scipy (#3381)
- Unify pareto front (#3389, thanks @semiexp!)
- Make
set_trial_param()ofRedisStoragefaster (#3391, thanks @masap!) - Make
_set_best_trial()ofRedisStoragefaster (#3392, thanks @masap!) - Make
set_study_directions()ofRedisStoragefaster (#3393, thanks @masap!) - Make optuna compatible with wandb sweep panels (#3403, thanks @captain-pool!)
- Change "#Trials" to "Trial" in
plot_slice,plot_pareto_front, andplot_optimization_history(#3449, thanks @dubey-anshuman!) - Make contour plots handle trials with nonfinite values (#3451)
- Query studies for trials only once in EDF plots (#3460)
- Make Parallel-Coordinate plots handle trials with nonfinite values (#3471, thanks @divyanshugit!)
- Separate heartbeat functionality from
BaseStorage(#3475) - Remove
torch.distributedcalls fromTorchDistributedTrialproperties (#3490, thanks @nlgranger!) - Remove the internal logic that calculates the interaction of two or more variables in fANOVA (#3543)
- Handle inf/-inf for
trial_valuestable in RDB (#3559) - Add
intermediate_value_typecolumn to represent inf/-inf onRDBStorage(#3564)
Bug Fixes
- Import
COLOR_SCALEinside import util context (#3492) - Remove
-voption ofoptuna study set-user-attrcommand (#3499, thanks @nyanhi!) - Filter trials with nonfinite value in
optuna.visualization.plot_param_importancesandoptuna.visualization.matplotlib.plot_param_importance(#3500, thanks @takoika!) - Fix
--verboseand--quietoptions in CLI (#3532, thanks @nyanhi!) - Replace
ValueErrorwithRuntimeErroringet_best_trial(#3541) - Take the same search space as in
CategoricalDistributionbyGridSampler(#3544)
Installation
- Partially support Python 3.10 (#3353)
- Clean up
setup.py(#3517) - Remove duplicate requirements from
documentsection (#3613)
Documentation
- Clean up exception docstrings (#3429)
- Revise docstring in MLFlow and WandB callbacks (#3477)
- Change the parameter name from
classifiertoregressorin the code snippet ofREADME.md(#3481) - Add link to Minituna in
CONTRIBUTING.md(#3482) - Fix
benchmarks/README.mdfor thebayesmarksection (#3496) - Mention
Study.stopas a criteria to stop creating trials in document (#3498, thanks @takoika!) - Fix minor English errors in the docstring of
study.optimize(#3505) - Add Python 3.10 in supported version in
README.md(#3508) - Remove articles at the beginning of sentences in crossovers (#3509)
- Correct
FronzenTrial's docstring (#3514) - Mention specify hyperparameter tutorial (#3515)
- Fix typo in MLFlow callback (#3533)
- Improve docstring of
GridSampler's seed option (#3568) - Add the samplers comparison table (#3571)
- Replace
youtube.comwithyoutube-nocookie.com(#3590) - Fix time complexity of the samplers comparison table (#3593)
- Remove
languagefrom docs configuration (#3594)
Examples
- Fix version of JAX (https://github.com/optuna/optuna-examples/pull/99)
- Remove constraints by #99 (https://github.com/optuna/optuna-examples/pull/100)
- Replace some methods in the
sklearnexample (https://github.com/optuna/optuna-examples/pull/102, thanks @MasahitoKumada!) - Add Python3.10 in
allennlp.yml(https://github.com/optuna/optuna-examples/pull/104) - Remove numpy (https://github.com/optuna/optuna-examples/pull/105)
- Add python 3.10 to fastai CI (https://github.com/optuna/optuna-examples/pull/106)
- Add python 3.10 to non-integration examples CIs (https://github.com/optuna/optuna-examples/pull/107)
- Add python 3.10 to Hiplot CI (https://github.com/optuna/optuna-examples/pull/108)
- Add a comma to
visualization.yml(https://github.com/optuna/optuna-examples/pull/109) - Rename WandB example to follow naming rules (https://github.com/optuna/optuna-examples/pull/110)
- Add scikit-learn version constraint for Dask-ML (https://github.com/optuna/optuna-examples/pull/112)
- Add python 3.10 to sklearn CI (https://github.com/optuna/optuna-examples/pull/113)
- Set version constraint of
protobufin PyTorch Lightning example (https://github.com/optuna/optuna-examples/pull/116)
Tests
- Improve
matplotlibparallel coordinate test (#3368) - Save figures for all
matplotlibtests (#3414, thanks @divyanshugit!) - Add
inftest to intermediate values test (#3466) - Add test cases for
test_storages.py(#3480) - Improve the tests of
optuna.visualization.plot_pareto_front(#3546) - Move heartbeat-related tests in
test_storages.pyto another file (#3553) - Use
seedmethod ofnp.random.RandomStatefor reseeding and fixtest_reseed_rng(#3569) - Refactor
test_get_observation_pairs(#3574) - Add tests for
inf/nanobjectives forShapleyImportanceEvaluator(#3576) - Add deprecated warning test to the multi-objective sampler test file (#3601)
Code Fixes
- Ignore incomplete trials in
matplotlib.plot_parallel_coordinate(#3415) - Update warning message and add a test when a trial fails with exception (#3454)
- Remove old distributions from NSGA-II sampler (#3459)
- Remove duplicated DB access in
_log_completed_trial(#3551) - Reduce the number of
copy.deepcopy()calls inimportancemodule (#3554) - Remove duplicated
check_trial_is_updatable(#3557) - Replace
optuna.testing.integration.create_running_trialwithstudy.ask(#3562) - Refactor
test_get_observation_pairs(#3574) - Update label of feasible trials if
constraints_funcis specified (#3587) - Replace unused variable name with underscore (#3588)
- Enable
no-implicit-optionalformypy(#3599, thanks @harupy!) - Enable
warn_redundant_castsformypy(#3602, thanks @harupy!) - Refactor the type of value of
TrialIntermediateValueModel(#3603) - Fix broken
mypychecks of Alembic'sget_current_head()method (#3608) - Sort dependencies by name (#3614)
Continuous Integration
- Introduce the benchmark for multi-objectives samplers (#3271, thanks @drumehiron!)
- Add WFG benchmark test (#3349, thanks @kei-mo!)
- Add workflow to use
reviewdog(#3357) - Add NASBench201 from NASLib (#3465)
- Fix speed benchmarks CI (#3470)
- Support PyTorch 1.11.0 (#3510)
- Restore
virtualenvfor benchmark extras (#3585) - Use
protobuf<4.0.0to resolve Sphinx CI error (#3591) - Unpin
protobuf(#3598, thanks @harupy!) - Extract MPI tests from integration CI as independent CI (#3606)
Other
- Bump up version to v3.0.0b1.dev (#3457)
- Fix
kurobakobenchmark code to run it locally (#3468) - Fix label of issue template (#3493)
- Improve issue templates (#3536)
- Hotfix for
fakeredis1.7.4 release (#3549) - Remove the version constraint of
fakeredis(#3561) - Relax version constraint of
fakeredis(#3607) - Shorten the durations of the stale bot for PRs (#3611)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@HideakiImamura, @MasahitoKumada, @TakuyaInoue-github, @belldandyxtq, @c-bata, @captain-pool, @contramundum53, @divyanshugit, @drumehiron, @dubey-anshuman, @fukatani, @g-votte, @gasin, @harupy, @himkt, @hvy, @kei-mo, @keisuke-umezawa, @knshnb, @liaison, @masap, @nlgranger, @not522, @nyanhi, @nzw0301, @semiexp, @sile, @takoika, @toshihikoyanase, @xadrianzetx
- Python
Published by HideakiImamura about 4 years ago
optuna - v3.0.0-b0
This is the release note of v3.0.0-b0.
Highlights
Simplified Distribution Classes: Float, Int and Categorical
Search space definitions, which consist of BaseDistribution and its child classes in Optuna, are greatly simplified. We have introduced FloatDistribution, IntDistribution, and CategoricalDistribution. If you use the suggest API and Study.optimize, the search space information is stored as these three distributions. Previous UniformDistribution, LogUniformDistribution, DiscreteUniformDistribution, IntUniformDistribution, and IntLogUniformDistribution are deprecated. If you pass deprecated distributions to APIs such as Study.ask or create_trial, they are internally converted to corresponding FloatDistribution or IntDistribution.
Storage Database Migration
To use Optuna v3.0.0-b0 with RDBStorage that was created in the previous versions of Optuna, please run optuna storage upgrade to migrate your database.
If you use RedisStorage, copy your study with RDBStorage using copy_study with the Optuna you used to create the study, thenrun optuna storage upgrade with Optuna v3.0.0-b0. After upgrading the storage, copy the study back as a new RedisStorage.
sh
python -c ‘import optuna; optuna.copy_study(from_study_name=”example”, from_storage=”redis://localhost:6379”, to_storage=”sqlite:///upgrade.db”)
pip install –pre -U optuna
optuna storage upgrade –storage sqlite:///upgrade.db
python -c ‘import optuna; optuna.copy_study(from_study_name="example", from_storage="sqlite:///upgrade.db", to_study_name="new-example", to_storage="redis://localhost:6379")’
Consistent Ask-and-Tell Interface with Study.optimize
Study.tell fails a trial when it is called with certain invalid combinations of state and values, instead of raising an error. This change aims to make Study.tell consistent with Study.optimize, which continues an optimization even if an objective returns an invalid value.
Study.tell now also returns the resulting trial (FrozenTrial) in order to allow inspecting how the arguments were interpreted.
Before
Study.tell raises an exception when it is called with an invalid combination of state and values.
```python study.tell(study.ask(), values=None)
Traceback (most recent call last):
File "", line 1, in
File "/…/optuna/optuna/study/study.py", line 579, in tell
raise ValueError(
ValueError: No values were told. Values are required when state is TrialState.COMPLETE.
```
After
Study.tell automatically fails the trial.
python
trial: FrozenTrial = study.tell(study.ask(), value=None)
assert trial.state == TrialState.FAIL
See #3144 for more details.
Stable Study APIs
We are converting all positional arguments of create_study, delete_study, load_study, and copy_study to keyword-only arguments since the order of arguments were inconsistent. This is not yet a breaking-change, but if you use these features with positional arguments, then you will get a warning message to use them with keyword-only arguments.
In addition, we have fixed all of problems described in #2955, so we have stabled the Study APIs. Specifically, Study.add_trial, Study.add_trials, Study.enqueue_trial, and copy_study have been stabled.
See #3270 and #2955 for more details.
Improved Visualization
Several bugs in the visualization module have been resolved. For instance,
the parallel coordinates plot ignores trials with missing parameters (#3373) and the scale of the objective value is fixed (#3369). The edf plot filters trials with inf values (#3395 and #3435).
Before: Trials with missing parameters are wrongly connected to each other.

After: Trials with missing parameters are removed from the plot.

Breaking Changes
- Add option to exclude best trials from study summaries (#3109)
- Migrate to
{Float,Int}Distributionusingalembic(#3113) - Move validation logic from
_run_trialtostudy.tell(#3144) - Enable
FloatDistributionandIntDistribution(#3246) - Use an enqueued parameter that is out of range from suggest API (#3298)
- Convert deprecated distribution to new distribution internally (#3420)
New Features
- Add
CatBoostPruningCallback(#2734, thanks @tohmae!) - Create common API for all NSGA-II crossover operations (#3221)
- Add a history of retried trial numbers in
Trial.system_attrs(#3223, thanks @belltailjp!) - Convert all positional arguments to keyword-only (#3270, thanks @higucheese!)
- Stabilize
study.py(#3309) - Add
targetsand deprecateaxis_orderinoptuna.visualization.matplotlib.plot_pareto_front(#3341, thanks @shu65!)
Enhancements
- Enable cache for
study.tell()(#3265, thanks @masap!) - Warn if heartbeat is used with ask-and-tell (#3273)
- Make
optuna.study.get_all_study_summaries()ofRedisStoragefast (#3278, thanks @masap!) - Improve Ctrl-C interruption handling (#3374, thanks @CorentinNeovision!)
- Use same colormap among
plotlyvisualization methods (#3376) - Make EDF plots handle trials with nonfinite values (#3435)
- Make logger message optional in
filter_nonfinite(#3438)
Bug Fixes
- Make TPE work with a categorical variable with different choice types (#3190, thanks @keisukefukuda!)
- Fix axis range issue in
matplotlibcontour plot (#3249, thanks @harupy!) - Allow
fail_state_trialsshow warning when heartbeat is enabled (#3301) - Clip untransformed values sampled from int uniform distributions (#3319)
- Fix missing
user_attrsandsystem_attrsin study summaries (#3352) - Fix objective scale in parallel coordinate of Matplotlib (#3369)
- Fix
matplotlib.plot_parallel_coordinatewith log distributions (#3371) - Fix parallel coordinate with missing value (#3373)
- Add utility to filter trials with
infvalues from visualizations (#3395) - Return the best trial number, not worst trial number by
best_index_(#3410) - Avoid using
px.colors.sequential.Bluesthat introducespandasdependency (#3422) - Fix
_is_reverse_scale(#3424)
Installation
- Drop TensorFlow support for Python 3.6 (#3296)
- Pin AllenNLP version (#3367)
- Skip run
fastaijob on Python 3.6 (#3412) - Avoid latest
click==8.1.0that removed a deprecated feature (#3413) - Avoid latest PyTorch lightning until integration is updated (#3417)
- Revert "Avoid latest
click==8.1.0that removed a deprecated feature" (#3430)
Documentation
- Add reference to tutorial page in CLI (#3267, thanks @tsukudamayo!)
- Carry over notes on
stepbehavior to new distributions (#3276) - Correct the disable condition of
show_progress_bar(#3287) - Add a document to lead FAQ and example of heartbeat (#3294)
- Add a note for
copy_study: it creates a copy regardless of its state (#3295) - Add note to recommend Python 3.8 or later in documentation build with artifacts (#3312)
- Fix crossover references in
Raisesdoc section (#3315) - Add reference to
QMCSamplerin tutorial (#3320) - Fix layout in tutorial (with workaround) (#3322)
- Scikit-learn required for
plot_param_importances(#3332, thanks @ll7!) - Add a link to multi-objective tutorial from a pareto front page (#3339, thanks @kei-mo!)
- Add reference to tutorial page in visualization (#3340, thanks @Hiroyuki-01!)
- Mention tutorials of User-Defined Sampler/Pruner from the API reference pages (#3342, thanks @hppRC!)
- Add reference to saving/resuming study with RDB backend (#3345, thanks @Hiroyuki-01!)
- Fix a typo (#3360)
- Remove deprecated command
optuna study optimizein FAQ (#3364) - Fix nit typo (#3380)
- Add see also section for
best_trial(#3396, thanks @divyanshugit!) - Updates the tutorial page for re-use the best trial (#3398, thanks @divyanshugit!)
- Add explanation about
Study.best_trialsin multi-objective optimization tutorial (#3443)
Examples
- Remove Python 3.6 from
haiku's CI (https://github.com/optuna/optuna-examples/pull/83) - Apply
black22.1.0 & runchecksdaily (https://github.com/optuna/optuna-examples/pull/84) - Add
hiplotexample (https://github.com/optuna/optuna-examples/pull/86) - Stop running jobs using TF with Python3.6 (https://github.com/optuna/optuna-examples/pull/87)
- Pin AllenNLP version (https://github.com/optuna/optuna-examples/pull/89)
- Add Medium link (https://github.com/optuna/optuna-examples/pull/91)
- Use official
CatBoostPruningCallback(https://github.com/optuna/optuna-examples/pull/92) - Stop running
fastaijob on Python 3.6 (https://github.com/optuna/optuna-examples/pull/93) - Specify Python version using
strin workflow files (https://github.com/optuna/optuna-examples/pull/95) - Introduce upper version constraint of PyTorchLightning (https://github.com/optuna/optuna-examples/pull/96)
- Update
SimulatedAnnealingSamplerto supportFloatDistribution(https://github.com/optuna/optuna-examples/pull/97)
Tests
- Add plot value tests to
matplotlib_tests/test_param_importances(#3180, thanks @belldandyxtq!) - Make tests of
plot_optimization_historymethods consistent (#3234) - Add integration test for
RedisStorage(#3258, thanks @masap!) - Change the order of arguments in the
catalystintegration test (#3308) - Cleanup
MLflowCallbacktests (#3378) - Test serialize/deserialize storage on parametrized conditions (#3407)
- Add tests for parameter of 'None' for TPE (#3447)
Code Fixes
- Switch to
IntDistribution(#3181, thanks @nyanhi!) - Fix type hints for Python 3.8 (#3240)
- Remove
UniformDistribution,LogUniformDistributionandDiscreteUniformDistributioncode paths (#3275) - Merge
set_trial_state()andset_trial_values()into one function (#3323, thanks @masap!) - Follow up for
{Float, Int}Distributions(#3337, thanks @nyanhi!) - Move the
get_trial_xxxabstract functions to base (#3338, thanks @belldandyxtq!) - Update type hints of
states(#3359, thanks @BasLaa!) - Remove unused function from
RedisStorage(#3394, thanks @masap!) - Remove unnecessary string concatenation (#3406)
- Follow coding style and fix typos in
tests/integration_tests(#3408) - Fix log message formatting in
filter_nonfinite(#3436) - Add
RetryFailedTrialCallbacktooptuna.storages.*(#3441) - Unify
fail_stale_trialsin each storage implementation (#3442, thanks @knshnb!)
Continuous Integration
- Add performance benchmarks using
bayesmark(#3354) - Fix speed benchmarks (#3362)
- Pin
setuptools(#3427)
Other
- Bump up version to
v3.0.0b0.dev(#3289) - Add description field for
question-and-help-support(#3305) - Update README to inform
v3.0.0a2(#3314) - Add Optuna-related URLs for PyPi (#3355, thanks @andriyor!)
- Bump Optuna to
v3.0.0-b0(#3458)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@BasLaa, @CorentinNeovision, @HideakiImamura, @Hiroyuki-01, @andriyor, @belldandyxtq, @belltailjp, @contramundum53, @divyanshugit, @harupy, @higucheese, @himkt, @hppRC, @hvy, @kei-mo, @keisuke-umezawa, @keisukefukuda, @knshnb, @ll7, @masap, @not522, @nyanhi, @nzw0301, @shu65, @sile, @tohmae, @toshihikoyanase, @tsukudamayo, @xadrianzetx
- Python
Published by HideakiImamura about 4 years ago
optuna - v3.0.0-a2
This is the release note of v3.0.0-a2.
Highlights
Study.optimize Warning Configuration Fix
This is a small release that fixes a bug that the same warning message was emitted more than once when calling Study.optimize.
Bug Fixes
- [Backport] Allow
fail_state_trialsshow warning when heartbeat is enabled (#3303)
Other
- Bump Optuna (#3302)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@HideakiImamura, @himkt
- Python
Published by himkt over 4 years ago
optuna - v3.0.0-a1
This is the release note of v3.0.0-a1.
Highlights
Second alpha pre-release in preparation for the upcoming major version update v3.
Included are several new features, improved optimization algorithms, removals of deprecated interfaces and many quality of life improvements.
To read about the entire v3 roadmap, please refer to the Wiki.
While this is a pre-release, we encourage users to keep using the latest releases of Optuna, including this one, for a smoother transition to the coming major release. Early feedback is welcome!
A New Algorithm: Quasi-Monte Carlo Sampler
Now, you can utilize a new sampling algorithm based on the Quasi-Monte Carlo method, optuna.samplers.QMCSampler. This is oftentimes a good alternative to the existing optuna.samplers.RandomSampler. The generated (sampled) sequences have lower discrepancies compared to the standard random sequences, which are sampled uniformly. The following figures show the performance comparison to other existing samplers. Note that this algorithm is only supported for python >= 3.7.
See #2423 for more details.
Parkinson in HPOBench | Slice in HPOBench
-- | --
 |
| 
Constraints Support for Pareto-front plot
The Pareto front plot now supports visualization of constrained optimization. In Optuna, NSGAIISampler and BoTorchSampler allow constrained optimization by taking a function constraints_func as argument, then examine whether trials are feasible or not. The optuna.visualization.plot_pareto_front receives a similar function and uses this function to plot the trials in different colors depending on whether they violate the constraints or not.
See #3128 for more details.
```python def objective(trial): # Binh and Korn function with constraints. x = trial.suggestfloat("x", -15, 30) y = trial.suggestfloat("y", -15, 30)
# Store the constraints as user attributes so that they can be restored after optimization.
c0 = (x - 5) ** 2 + y ** 2 - 25
c1 = -((x - 8) ** 2) - (y + 3) ** 2 + 7.7
trial.set_user_attr("constraints", (c0, c1))
v0 = 4 * x ** 2 + 4 * y ** 2
v1 = (x - 5) ** 2 + (y - 5) ** 2
return v0, v1
def constraints(trial): return trial.user_attrs["constraints"]
if name == "main": sampler = optuna.samplers.NSGAIISampler( constraintsfunc=constraints, ) study = optuna.createstudy( directions=["minimize", "minimize"], sampler=sampler, ) study.optimize(objective, n_trials=1000)
optuna.visualization.plot_pareto_front(study, constraints_func=constraints).show()
```

Distribution Cleanup
We are actively working on cleaning up distributions for integer and floating-point. In Optuna v3, these distribution are unified to optuna.distributions.IntDistribution and optuna.distributions.FloatDistribution. v3.0.0-a1 contains several changes for this project and you will temporarily see UserWarning when you call Trial.suggest_int and Trial.suggest_float. We apologize for the inconvenience and the warning will be removed from the next release.
See #2941 for more information.
Stabilization of Experimental Modules
We make AllenNLP integration and FrozenTrial.create_trial stable.
See #3196 and #3228 for more information
Breaking Changes
- Remove
type_checking.py(#3235)
New Features
- Add QMC sampler (#2423, thanks @kstoneriv3!)
- Refactor pareto front and support
constraints_funcinplot_pareto_front(#3128, thanks @semiexp!) - Add
skip_if_finishedflag toStudy.tell(#3150, thanks @xadrianzetx!) - Add
user_attrsargument toStudy.enqueue_trial(#3185, thanks @knshnb!) - Option to inherit intermediate values in
RetryFailedTrialCallback(#3269, thanks @knshnb!) - Add setter method for
DiscreteUniformDistribution.q(#3283) - Stabilize allennlp integrations (#3228)
- Stabilize
create_trial(#3196)
Enhancements
- Reduce number of queries to fetch
directions,user_attrsandsystem_attrsof study summaries (#3108) - Support
FloatDistributionacross codebase (#3111, thanks @xadrianzetx!) - Use
json.loadsto decode pruner configuration loaded from environment variables (#3114) - Show progress bar based on
timeout(#3115, thanks @xadrianzetx!) - Support
IntDistributionacross codebase (#3126, thanks @nyanhi!) - Make progress bar available with n_jobs!=1 (#3138, thanks @masap!)
- Wrap
RedisStorageinCachedStorage(#3204, thanks @masap!) - Use
functools.wrapsintrack_in_mlflowdecorator (#3216) - Make
RedisStoragefast when running multiple trials (#3262, thanks @masap!) - Reduce database query result for
Study.ask()(#3274, thanks @masap!)
Bug Fixes
- Fix bug of nondeterministic behavior of
TPESamplerwhengroup=True(#3187, thanks @xuzijian629!) - Handle non-numerical params in
matplotlib.contour_plot(#3213, thanks @xadrianzetx!) - Fix log scale axes padding in
matplotlib.contour_plot(#3218, thanks @xadrianzetx!) - Handle
-infandinfvalues inRDBStorage(#3238, thanks @xadrianzetx!) - Skip limiting the value if it is
nan(#3286)
Installation
- Bump to
torchrelated packages (#3156) - Use
pytorch-lightning>=1.5.0(#3157) - Remove testoutput from doctest of
mlflowintegration (#3170) - Restrict
nltkversion (#3201) - Add version constraints of
setuptools(#3207) - Remove version constraint of
setuptools(#3231) - Remove Sphinx version constraint (#3237)
Documentation
- Add a note
logging_callbackonly works in single process situation (#3143) - Correct
FrozenTrial's docstring (#3161) - Promote to use of v3.0.0a0 in
README.md(#3167) - Mention tutorial of callback for
Study.optimizefrom API page (#3171, thanks @xuzijian629!) - Add reference to tutorial page in
study.enqueue_trial(#3172, thanks @knshnb!) - Fix typo in specify_params (#3174, thanks @knshnb!)
- Guide to tutorial of Multi-objective Optimization in visualization tutorial (#3182, thanks @xuzijian629!)
- Add explanation about Parallelize Optimization at FAQ (#3186, thanks @MasahitoKumada!)
- Add order in tutorial (#3193, thanks @makinzm!)
- Fix inconsistency in
distributionsdocumentation (#3222, thanks @xadrianzetx!) - Add FAQ entry for heartbeat (#3229)
- Replace AUC with accuracy in docs (#3242)
- Fix
Raisessection ofFloatDistributiondocstring (#3248, thanks @xadrianzetx!) - Add
{Float,Int}Distributionto docs (#3252) - Update explanation for metrics of
AllenNLPExecutor(#3253) - Add missing cli methods to the list (#3268)
- Add docstring for property
DiscreteUniformDistribution.q(#3279)
Examples
- Add pytorch-lightning DDP example (https://github.com/optuna/optuna-examples/pull/43, thanks @tohmae!)
- Install latest AllenNLP (https://github.com/optuna/optuna-examples/pull/73)
- Restrict
nltkversion (https://github.com/optuna/optuna-examples/pull/75) - Add version constraints of
setuptools(https://github.com/optuna/optuna-examples/pull/76) - Remove constraint of
setuptools(https://github.com/optuna/optuna-examples/pull/79)
Tests
- Add tests for transformer with upper bound parameter (#3163)
- Add tests in
visualization_tests/matplotlib_tests/test_slice.py(#3175, thanks @keisukefukuda!) - Add test case of the value in optimization history with matplotlib (#3176, thanks @TakuyaInoue-github!)
- Add tests for generated plots of
matplotlib.plot_edf(#3178, thanks @makinzm!) - Improve pareto front figure tests for matplotlib (#3183, thanks @akawashiro!)
- Add tests for generated plots of
plot_edf(#3188, thanks @makinzm!) - Match contour tests between Plotly and Matplotlib (#3192, thanks @belldandyxtq!)
- Implement missing
matplotlib.contour_plottest (#3232, thanks @xadrianzetx!) - Unify the validation function of edf value between visualization backends (#3233)
- Add test for default grace period (#3263, thanks @masap!)
- Add the missing tests of Plotly's
plot_parallel_coordinate(#3266, thanks @MasahitoKumada!) - Switch function order progbar tests (#3280, thanks @BasLaa!)
Code Fixes
- Black fix (#3147)
- Switch to
FloatDistribution(#3166, thanks @xadrianzetx!) - Remove
deprecateddecorator of the feature ofn_jobs(#3173, thanks @MasahitoKumada!) - Fix black and blackdoc errors (#3260, thanks @masap!)
- Remove experimental label from
MaxTrialsCallback(#3261, thanks @knshnb!) - Remove redundant
_check_trial_id(#3264, thanks @masap!) - Make existing int/float distributions wrapper of
{Int,Float}Distribution(#3244)
Continuous Integration
- Use python 3.8 for CI and docker (#3026)
- Add performance benchmarks using
kurobako(#3155) - Use Python 3.7 in checks CI job (#3239)
Other
- Bump up version to v3.0.0a1.dev (#3142)
- Introduce a form to make TODOs explicit when creating issues (#3169)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@BasLaa, @HideakiImamura, @MasahitoKumada, @TakuyaInoue-github, @akawashiro, @belldandyxtq, @g-votte, @himkt, @hvy, @keisuke-umezawa, @keisukefukuda, @knshnb, @kstoneriv3, @makinzm, @masap, @not522, @nyanhi, @nzw0301, @semiexp, @tohmae, @toshihikoyanase, @tupui, @xadrianzetx, @xuzijian629
- Python
Published by himkt over 4 years ago
optuna - v3.0.0-a0
This is the release note of v3.0.0-a0.
Highlights
First alpha pre-release in preparation for the upcoming major version update v3.
Included are several new features, improved optimization algorithms, removals of deprecated interfaces and many quality of life improvements.
To read about the entire v3 roadmap, please refer to the Wiki.
While this is a pre-release, we encourage users to keep using the latest releases of Optuna, including this one, for a smoother transition to the coming major release. Early feedback is welcome!
CLI Improvements
Optuna CLI speed and usability improvements. Previously, it took several seconds to launch a CLI command, #3000 significantly speeds up the commands by halving the module load time.
The usability of the ask-and-tell interface is also improved. The ask command allows users to define search space with short and simple JSON strings after #2905. The tell command supports --skip-if-finished which ignores duplicated reports of values and statuses instead of raising errors. It for instance improves robustness against pod retries on cluster environments. See #2905.
Before:
console
$ optuna ask --storage sqlite:///mystorage.db --study-name mystudy \
--search-space '{"x": {"name": "UniformDistribution", "attributes": {"low": 0.0, "high": 1.0}}}'
After:
console
$ optuna ask --storage sqlite:///mystorage.db --study-name mystudy \
--search-space '{"x": {"type": "float", "low": 0.0, "high": 1.0}}'
New NSGA-II Crossover Options
The optimization performance of NSGA-II has been greatly improved for real-valued problems. We introduce the crossover argument in NSGAIISampler. You can select several variants of the crossover option from uniform (default), blxalpha, sbx, vsbx, undx, and spx.
The following figure shows that the newly introduced crossover algorithms perform better than existing algorithms, that is, the uniform crossover algorithm and the Gaussian process based algorithm, in terms of biasness, convergence, and diversity. Note that the previous method, other implementations (in kurobako), and the default of the new method are based on uniform crossover.
See #2903 for more information.

New History Visualization with Multiple Studies
The optimization history plot now supports visualization of multiple studies. It receives a list of studies. If the error_bar option is False, it outputs those histories in one figure. If the error_bar option is True, it calculates and shows the means and the standard deviations of those histories.
See #2807 for more details.
```python import optuna
def objective(trial): return trial.suggest_float("x", 0, 1) ** 2
nstudies = 5 studies = [optuna.createstudy(studyname=f"{i}th-study") for i in range(nstudies)] for study in studies: study.optimize(objective, n_trials=20)
This generates the first figure.
fig = optuna.visualization.plotoptimizationhistory(studies) fig.write_image("./multiple.png")
This generates the second figure.
fig = optuna.visualization.plotoptimizationhistory(studies, errorbar=True) fig.writeimage("./error_bar.png") ```


AllenNLP Distributed Pruning
The AllenNLP integration supports pruning in distributed environments. This change enables users to use the optuna_pruner callback option along with the distributed option as can be seen in the following training configuration. See #2977.
yaml
...
trainer: {
optimizer: 'adam',
cuda_device: -1,
callbacks: [
{
type: 'optuna_pruner',
}
],
},
distributed: {
cuda_devices: [-1, -1],
},
Preparations for Unification of Distributions Classes
There are several implementations of BaseDistribution in Optuna, such as UniformDistribution, DiscreteUniformDistribution, IntUniformDistribution, CategoricalDistribution, This release includes part of ongoing work in reducing the number of these distribution classes to just FloatDistribution, IntDistribution, and CategoricalDistribution, aligning the classes to the trial suggest interface (suggest_float, suggest_int, and suggest_categorical). Please note that users are not recommended to use these distributions yet, because samplers haven’t been updated to support those. See #3063 for more details.
Breaking Changes
Some deprecated features including the optuna.structs module, LightGBMTuner.best_booster, and the optuna dashboard command are removed in #3057 and #3058. If you use such features please migrate to the new ones.
| Removed APIs | Corresponding active APIs |
| --- | --- |
| optuna.structs.StudyDirection | optuna.study.StudyDirection |
| optuna.structs.StudySummary | optuna.study.StudySummary |
| optuna.structs.FrozenTrial | optuna.trial.FrozenTrial |
| optuna.structs.TrialState | optuna.trial.TrialState |
| optuna.structs.TrialPruned | optuna.exceptions.TrialPruned |
| optuna.integration.lightgbm.LightGBMTuner.best_booster | optuna.integration.lightgbm.LightGBMTuner.get_best_booster |
| optuna dashboard | optuna-dashboard |
- Unify
suggestAPIs for floating-point parameters (#2990, thanks @xadrianzetx!) - Clean up deprecated features (#3057, thanks @nuka137!)
- Remove
optuna dashboard(#3058)
New Features
- Add interval for LightGBM callback (#2490)
- Allow multiple studies and add error bar option to
plot_optimization_history(#2807) - Support PyTorch-lightning DDP training (#2849, thanks @tohmae!)
- Add crossover operators for NSGA-II (#2903, thanks @yoshinobc!)
- Add abbreviated JSON formats of distributions (#2905)
- Extend
MLflowCallbackinterface (#2912, thanks @xadrianzetx!) - Support AllenNLP distributed pruning (#2977)
- Make
trial.user_attrslogging optional inMLflowCallback(#3043, thanks @xadrianzetx!) - Support multiple input of studies when plot with Matplotlib (#3062, thanks @TakuyaInoue-github!)
- Add
IntDistribution&FloatDistribution(#3063, thanks @nyanhi!) - Add
trial.user_attrstopareto_fronthover text (#3082, thanks @kasparthommen!) - Support error bar for Matplotlib (#3122, thanks @TakuyaInoue-github!)
- Add
optuna tellwith--skip-if-finished(#3131)
Enhancements
- Add single distribution support to
BoTorchSampler(#2928) - Speed up
import optuna(#3000) - Fix
_containsofIntLogUniformDistribution(#3005) - Render importance scores next to bars in
matplotlib.plot_param_importances(#3012, thanks @xadrianzetx!) - Make default value of
verbose_evalNoneN forLightGBMTuner/LightGBMTunerCV` to avoid conflict (#3014, thanks @chezou!) - Unify colormap of
plot_contour(#3017) - Relax
FixedTrialandFrozenTrialallowing not-contained parameters duringsuggest_*(#3018) - Raise errors if
optuna askCLI receives--sampler-kwargswithout--sampler(#3029) - Remove
_get_removed_version_from_deprecated_versionfunction (#3065, thanks @nuka137!) - Reformat labels for small importance scores in
plotly.plot_param_importances(#3073, thanks @xadrianzetx!) - Speed up Matplotlib backend
plot_contourusing SciPy'sspsolve(#3092) - Remove updates in cached storage (#3120, thanks @shu65!)
Bug Fixes
- Add tests of
sample_relativeand fix type of return values ofSkoptSamplerandPyCmaSampler(#2897) - Fix
GridSamplerwithRetryFailedTrialCallbackorenqueue_trial(#2946) - Fix the type of
trial.valuesin MLflow integration (#2991) - Fix to raise
ValueErrorfor invalidqinDiscreteUniformDistribution(#3001) - Do not call
trial.reportduring sanity check (#3002) - Fix
matplotlib.plot_contourbug (#3046, thanks @IEP!) - Handle
singledistributions infANOVAevaluator (#3085, thanks @xadrianzetx!)
Installation
- Support scikit-learn v1.0.0 (#3003)
- Pin
tensorflowandtensorflow-estimatorversions to<2.7.0(#3059) - Add upper version constraint of PyTorchLightning (#3077)
- Pin
kerasversion to<2.7.0(#3078) - Remove version constraints of
tensorflow(#3084)
Documentation
- Add note of the behavior when calling multiple
trial.report(#2980) - Add note for DDP training of
pytorch-lightning(#2984) - Add note to
OptunaSearchCVabout direction (#3007) - Clarify
n_trialsin the docs (#3016, thanks @Rohan138!) - Add a note to use pickle with different optuna versions (#3034)
- Unify the visualization docs (#3041, thanks @sidshrivastav!)
- Fix a grammatical error in FAQ doc (#3051, thanks @belldandyxtq!)
- Less ambiguous documentation for
optuna tell(#3052) - Add example for
logging.set_verbosity(#3061, thanks @drumehiron!) - Mention the tutorial of
002_configurations.pyin theTrialAPI page (#3067, thanks @makkimaki!) - Mention the tutorial of
003_efficient_optimization_algorithms.pyin theTrialAPI page (#3068, thanks @makkimaki!) - Add link from
set_user_attrsinStudyto theuser_attrsentry in Tutorial (#3069, thanks @MasahitoKumada!) - Update description for missing samplers and pruners (#3087, thanks @masaaldosey!)
- Simplify the unit testing explanation (#3089)
- Fix range description in
suggest_floatdocstring (#3091, thanks @xadrianzetx!) - Fix documentation for the package installation procedure on different OS (#3118, thanks @masap!)
- Add description of
ValueErrorandTypeErorrtoRaisessection ofTrial.report(#3124, thanks @MasahitoKumada!)
Examples
- Use
RetryFailedTrialCallbackinpytorch_checkpointexample (https://github.com/optuna/optuna-examples/pull/59, thanks @xadrianzetx!) - Add Python 3.9 to CI yaml files (https://github.com/optuna/optuna-examples/pull/61)
- Replace
suggest_uniformwithsuggest_float(https://github.com/optuna/optuna-examples/pull/63) - Remove deprecated warning message in
lightgbm(https://github.com/optuna/optuna-examples/pull/64) - Pin
tensorflowandtensorflow-estimatorversions to<2.7.0(https://github.com/optuna/optuna-examples/pull/66) - Restrict upper version of
pytorch-lightning(https://github.com/optuna/optuna-examples/pull/67) - Add an external resource to
README.md(https://github.com/optuna/optuna-examples/pull/68, thanks @solegalli!)
Tests
- Add test case of samplers for conditional objective function (#2904)
- Test int distributions with default step (#2924)
- Be aware of trial preparation when checking heartbeat interval (#2982)
- Simplify the DDP model definition in the test of
pytorch-lightning(#2983) - Wrap data with
np.asarrayinlightgbmtest (#2997) - Patch calls to deprecated
suggestAPIs across codebase (#3027, thanks @xadrianzetx!) - Make
return_cvboosterofLightGBMTunerconsistent to the original value (#3070, thanks @abatomunkuev!) - Fix
parametrize_sampler(#3080) - Fix verbosity for
tests/integration_tests/lightgbm_tuner_tests/test_optimize.py(#3086, thanks @nyanhi!) - Generalize empty search space test case to all hyperparameter importance evaluators (#3096, thanks @xadrianzetx!)
- Check if texts in legend by order agnostic way (#3103)
- Add tests for axis scales to
matplotlib.plot_slice(#3121)
Code Fixes
- Add test case of samplers for conditional objective function (#2904)
- Fix #2949, remove
BaseStudy(#2986, thanks @twsl!) - Use
optuna.load_studyinoptuna askCLI to omitdirection/directionsoption (#2989) - Fix typo in
Trialwarning message (#3008, thanks @xadrianzetx!) - Replaces boston dataset with california housing dataset (#3011, thanks @avats-dev!)
- Fix deprecation version of
suggestAPIs (#3054, thanks @xadrianzetx!) - Add
remove_versionto the missing@deprecatedargument (#3064, thanks @nuka137!) - Add example of
optuna.logging.get_verbosity(#3066, thanks @MasahitoKumada!) - Support
{Float|Int}Distributionin NSGA-II crossover operators (#3139, thanks @xadrianzetx!)
Continuous Integration
- Install
botorchto CI jobs on mac (#2988) - Use libomp 11.1.0 for Mac (#3024)
- Run
mac-testsCI at a scheduled time (#3028) - Set concurrency to github workflows (#3095)
- Skip CLI tests when calculating the coverage (#3097)
- Migrate
mypyversion to 0.910 (#3123) - Avoid installing the latest MLfow to prevent doctests from failing (#3135)
Other
- Bump up version to 2.11.0dev (#2976)
- Add roadmap news to
README.md(#2999) - Bump up version number to 3.0.0a1.dev (#3006)
- Add Python 3.9 to
tox.ini(#3025) - Fix version number to 3.0.0a0 (#3140)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@Crissman, @HideakiImamura, @IEP, @MasahitoKumada, @Rohan138, @TakuyaInoue-github, @abatomunkuev, @avats-dev, @belldandyxtq, @chezou, @drumehiron, @g-votte, @himkt, @hvy, @kasparthommen, @keisuke-umezawa, @makkimaki, @masaaldosey, @masap, @not522, @nuka137, @nyanhi, @nzw0301, @shu65, @sidshrivastav, @sile, @solegalli, @tohmae, @toshihikoyanase, @twsl, @xadrianzetx, @yoshinobc, @ytsmiling
- Python
Published by HideakiImamura over 4 years ago
optuna - v2.10.0
This is the release note of v2.10.0.
Highlights
New CLI Subcommand for Analyzing Studies
New subcommands optuna trials, optuna best-trial and optuna best-trials have been introduced to Optuna’s CLI for listing trials in studies with RDB storages. It allows direct interaction with trial data from the command line in various formats including human readable tables, JSON or YAML. See the following examples:
Show all trials in a study.
console
$ optuna trials --storage sqlite:///example.db --study-name example
+--------+---------------------+---------------------+---------------------+----------------+---------------------+----------+
| number | value | datetime_start | datetime_complete | duration | params | state |
+--------+---------------------+---------------------+---------------------+----------------+---------------------+----------+
| 0 | 0.6098421143538713 | 2021-10-01 14:36:46 | 2021-10-01 14:36:46 | 0:00:00.026059 | {'x': 'A', 'y': 6} | COMPLETE |
| 1 | 0.6584108953598753 | 2021-10-01 14:36:46 | 2021-10-01 14:36:46 | 0:00:00.023447 | {'x': 'A', 'y': 10} | COMPLETE |
| 2 | 0.612883262548314 | 2021-10-01 14:36:46 | 2021-10-01 14:36:46 | 0:00:00.021577 | {'x': 'C', 'y': 3} | COMPLETE |
| 3 | 0.09326753798819143 | 2021-10-01 14:36:46 | 2021-10-01 14:36:46 | 0:00:00.024183 | {'x': 'A', 'y': 0} | COMPLETE |
| 4 | 0.7316749689191168 | 2021-10-01 14:36:46 | 2021-10-01 14:36:46 | 0:00:00.021994 | {'x': 'C', 'y': 4} | COMPLETE |
+--------+---------------------+---------------------+---------------------+----------------+---------------------+----------+
Show the best trial as YAML.
console
$ optuna best-trial --storage sqlite:///example.db --study-name example --format yaml
datetime_complete: '2021-10-01 14:36:46'
datetime_start: '2021-10-01 14:36:46'
duration: '0:00:00.024183'
number: 3
params:
x: A
y: 0
state: COMPLETE
value: 0.09326753798819143
Show the best trials of multi-objective optimization and train a neural network with one of the best parameters.
```console $ STORAGE=sqlite:///example.db $ STUDYNAME=example-mo $ optuna best-trials --storage $STORAGE --study-name $STUDYNAME +--------+-------------------------------------------+---------------------+---------------------+----------------+--------------------------------------------------+----------+ | number | values | datetimestart | datetimecomplete | duration | params | state | +--------+-------------------------------------------+---------------------+---------------------+----------------+--------------------------------------------------+----------+ | 0 | [0.23884292794146034, 0.6905832476748404] | 2021-10-01 15:02:32 | 2021-10-01 15:02:32 | 0:00:00.035815 | {'lr': 0.05318673615579818, 'optimizer': 'adam'} | COMPLETE | | 2 | [0.3157886300888031, 0.05110976427394465] | 2021-10-01 15:02:32 | 2021-10-01 15:02:32 | 0:00:00.030019 | {'lr': 0.08044012012204389, 'optimizer': 'sgd'} | COMPLETE | +--------+-------------------------------------------+---------------------+---------------------+----------------+--------------------------------------------------+----------+
$ optuna best-trials --storage $STORAGE --study-name $STUDY_NAME --format json > result.json
$ OPTIMIZER=jq '.[0].params.optimizer' result.json
$ LR=jq '.[0].params.lr' result.json
$ python train.py $OPTIMIZER $LR
```
See #2847 for more details.
Multi-objective Optimization Support of Weights & Biases and MLflow Integrations
Weights & Biases and MLflow integration modules support tracking multi-objective optimization. Now, they accept arbitrary numbers of objective values with metric names.
Weights & Biases
```python from optuna.integration import WeightsAndBiasesCallback
wandbc = WeightsAndBiasesCallback(metric_name=["mse", "mae"])
...
study = optuna.createstudy(directions=["minimize", "minimize"]) study.optimize(objective, ntrials=100, callbacks=[wandbc]) ```
MLflow
```python from optuna.integration import MLflowCallback
mlflc = MLflowCallback(metric_name=["accuracy", "latency"])
...
study = optuna.createstudy(directions=["minimize", "minimize"])
study.optimize(objective, ntrials=100, callbacks=[mlflc])
```
See #2835 and #2863 for more details.
Breaking Changes
- Align CLI output format (#2882)
- In particular, the return format of
optuna askhas been simplified. The first layer of nesting with the key “trial” is removed. Parsing can be simplified fromjq ‘.trial.params’tojq ‘.params’.
- In particular, the return format of
New Features
- Support multi-objective optimization in
WeightsAndBiasesCallback(#2835, thanks @xadrianzetx!) - Introduce trials CLI (#2847)
- Support multi-objective optimization in
MLflowCallback(#2863, thanks @xadrianzetx!)
Enhancements
- Add Plotly-like interpolation algorithm to
optuna.visualization.matplotlib.plot_contour(#2810, thanks @xadrianzetx!) - Sort values when the categorical values is numerical in
plot_parallel_coordinate(#2821, thanks @TakuyaInoue-github!) - Refactor
MLflowCallback(#2855, thanks @xadrianzetx!) - Minor refactoring of
plot_parallel_coordinate(#2856) - Update
sklearn.py(#2966, thanks @Garve!)
Bug Fixes
- Fix
datetime_completein_CachedStorage(#2846) - Hyperband no longer assumes it is the only pruner (#2879, thanks @cowwoc!)
- Fix method
untransformof_SearchSpaceTransformwithdistribution.single() == True(#2947, thanks @yoshinobc!)
Installation
- Avoid
keras2.6.0 (#2851) - Drop
tensorflowandkerasversion constraints (#2852) - Avoid latest
allennlp==2.7.0(#2894) - Introduce the version constraint of scikit-learn (#2953)
Documentation
- Fix
bounds' shape in the document (#2830) - Simplify documentation of
FrozenTrial(#2833) - Fix typo: replace CirclCI with CircleCI (#2840)
- Added alternative callback function #2844 (#2845, thanks @DeviousLab!)
- Update URL of cmaes repository (#2857)
- Improve the docstring of
MLflowCallback(#2883) - Fix
create_trialdocument (#2888) - Fix an argument in docstring of
_CachedStorage(#2917) - Use
:obj:forTrue,False, andNoneinstead of inline code (#2922) - Use inline code syntax for
constraints_func(#2930) - Add link to Weights & Biases example (#2962, thanks @xadrianzetx!)
Examples
- Do not use latest
keras==2.6.0(https://github.com/optuna/optuna-examples/pull/44) - Fix typo in Dask-ML GitHub Action workflow (https://github.com/optuna/optuna-examples/pull/45, thanks @jrbourbeau!)
- Support Python 3.9 for TensorFlow and MLFlow (https://github.com/optuna/optuna-examples/pull/47)
- Replace deprecated argument
lrwithlearning_ratein tf.keras (https://github.com/optuna/optuna-examples/pull/51) - Avoid latest
allennlp==2.7.0(https://github.com/optuna/optuna-examples/pull/52) - Save checkpoint to tmpfile and rename it (https://github.com/optuna/optuna-examples/pull/53)
- PyTorch checkpoint cosmetics (https://github.com/optuna/optuna-examples/pull/54)
- Add Weights & Biases example (https://github.com/optuna/optuna-examples/pull/55, thanks @xadrianzetx!)
- Use
MLflowCallbackin MLflow example (https://github.com/optuna/optuna-examples/pull/58, thanks @xadrianzetx!)
Tests
- Fixed relational operator not including
1(#2865, thanks @Yu212!) - Add scenario tests for samplers (#2869)
- Add test cases for storage upgrade (#2890)
- Add test cases for
show_progress_barofoptimize(#2900, thanks @xadrianzetx!) - Speed-up sampler tests by using random sampling of skopt (#2910)
- Fixes
namedtupletype name (#2961, thanks @sobolevn!)
Code Fixes
- Changed y-axis and x-axis access according to matplotlib docs (#2834, thanks @01-vyom!)
- Fix a BoTorch deprecation warning (#2861)
- Relax metric name type hinting in
WeightsAndBiasesCallback(#2884, thanks @xadrianzetx!) - Fix recent
alembic1.7.0 type hint error (#2887) - Remove old unused
Trial._after_funcmethod (#2899) - Fixes
namedtupletype name (#2961, thanks @sobolevn!)
Continuous Integration
- Enable act to run for other workflows (#2656)
- Drop
tensorflowandkerasversion constraints (#2852) - Avoid segmentation fault of
test_lightgbm.pyon macOS (#2896)
Other
- Preinstall RDB binding Python libraries in Docker image (#2818)
- Bump to v2.10.0.dev (#2829)
- Bump to v2.10.0 (#2975)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@01-vyom, @Crissman, @DeviousLab, @Garve, @HideakiImamura, @TakuyaInoue-github, @Yu212, @c-bata, @cowwoc, @himkt, @hvy, @jrbourbeau, @keisuke-umezawa, @not522, @nzw0301, @sobolevn, @toshihikoyanase, @xadrianzetx, @yoshinobc
- Python
Published by hvy over 4 years ago
optuna - v2.9.1
This is the release note of v2.9.1.
Highlights
Ask-and-Tell CLI Fix
The storage URI and the study name are no longer logged by optuna ask and optuna tell. The former could contain sensitive information.
Enhancements
- Remove storage URI from
askandtellCLI subcommands (#2838)
Other
- Bump to v2.9.1 (#2839)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@himkt, @hvy, @not522
- Python
Published by hvy almost 5 years ago
optuna - v2.9.0
This is the release note of v2.9.0.
Help us create the next version of Optuna! Please take a few minutes to fill in this survey, and let us know how you use Optuna now and what improvements you'd like. https://forms.gle/TtJuuaqFqtjmbCP67
Highlights
Ask-and-Tell CLI: Optuna from the Command Line
The built-in CLI which you can use to upgrade storages or check the installed version with optuna --version, now provides experimental subcommands for the Ask-and-Tell interface. It is now possible to optimize using Optuna entirely from the CLI, without writing a single line of Python.
Ask with optuna ask
Ask for parameters using optuna ask, specifying the search space, storage, study name, sampler and optimization direction. The parameters and the associated trial number can be output as either JSON or YAML.
The following is an example outputting and piping the results to a YAML file.
```console $ optuna ask --storage sqlite:///mystorage.db \ --study-name mystudy \ --sampler TPESampler \ --sampler-kwargs '{"multivariate": true}' \ --search-space '{"x": {"name": "UniformDistribution", "attributes": {"low": 0.0, "high": 1.0}}, "y": {"name": "CategoricalDistribution", "attributes": {"choices": ["foo", "bar"]}}}' \ --direction minimize \ --out yaml \ > out.yaml [I 2021-07-30 15:56:50,774] A new study created in RDB with name: mystudy [I 2021-07-30 15:56:50,808] Asked trial 0 with parameters {'x': 0.21492964898919975, 'y': 'foo'} in study 'mystudy' and storage 'sqlite:///mystorage.db'.
$ cat out.yaml trial: number: 0 params: x: 0.21492964898919975 y: foo ```
Specify multiple whitespace separated directions for multi-objective optimization.
Tell with optuna tell
After computing the objective value based on the output of ask, you can report the result back using optuna tell and it will be stored in the study.
console
$ optuna tell --storage sqlite:///mystorage.db \
--study-name mystudy \
--trial-number 0 \
--values 1.0
[I 2021-07-30 16:01:13,039] Told trial 0 with values [1.0] and state TrialState.COMPLETE in study 'mystudy' and storage 'sqlite:///mystorage.db'.
Specify multiple whitespace separated values for multi-objective optimization.
See https://github.com/optuna/optuna/pull/2817 for details.
Weights & Biases Integration
WeightsAndBiasesCallback is a new study optimization callback that allows logging with Weights & Biases. This allows utilizing Weight & Biases’ rich visualization features to analyze studies to complement Optuna’s visualization.
```python import optuna from optuna.integration.wandb import WeightsAndBiasesCallback
def objective(trial): x = trial.suggest_float("x", -10, 10)
return (x - 2) ** 2
wandbkwargs = {"project": "my-project"} wandbc = WeightsAndBiasesCallback(wandbkwargs=wandbkwargs) study = optuna.createstudy(studyname="mystudy") study.optimize(objective, ntrials=10, callbacks=[wandbc]) ```
See https://github.com/optuna/optuna/pull/2781 for details.
TPE Sampler Refactorings
The Tree-structured Parzen Estimator (TPE) sampler has always been the default sampler in Optuna. Both it’s API and internal code has over time grown to accomodate for various needs such as independent and join parameter sampling (the multivariate parameter) , and multi-objective optimization (the MOTPESampler sampler). In this release, the TPE sampler has been refactored and its code greatly reduced. The previously experimental multi-objective TPE Sampler MOTPESampler has also been deprecated and its capabilities are now absorbed by the standard TPESampler.
This change may break code that depends on fixed seeds with this sampler. The optimization algorithms otherwise have not been changed.
Following demonstrates how you can now use the TPESampler for multi-objective optimization.
```python import optuna
def objective(trial): x = trial.suggestfloat("x", 0, 5) y = trial.suggestfloat("y", 0, 3)
v0 = 4 * x ** 2 + 4 * y ** 2
v1 = (x - 5) ** 2 + (y - 5) ** 2
return v0, v1
sampler = optuna.samplers.TPESampler() # MOTPESampler used to be required for multi-objective optimization.
study = optuna.createstudy(
directions=["minimize", "minimize"],
sampler=sampler,
)
study.optimize(objective, ntrials=100)
```
Note that omitting the sampler argument or specifying None currently defaults to the NSGAIISampler for multi-objective studies instead of the TPESampler.
See https://github.com/optuna/optuna/pull/2618 for details.
Breaking Changes
- Unify the univariate and multivariate TPE (#2618)
New Features
- MLFlow decorator for optimization function (#2670, thanks @lucafurrer!)
- Redis Heartbeat (#2780, thanks @Turakar!)
- Introduce Weights & Biases integration (#2781, thanks @xadrianzetx!)
- Function for failing zombie trials and invoke their callbacks (#2811)
- Optuna ask and tell CLI options (#2817)
Enhancements
- Unify
MOTPESamplerandTPESampler(#2688) - Changed interpolation type to make numeric range consistent with Plotly (#2712, thanks @01-vyom!)
- Add the warning if an intermediate value is already reported at the same step (#2782, thanks @TakuyaInoue-github!)
- Prioritize grids that are not yet running in
GridSampler(#2783) - Fix
warn_independent_samplinginTPESampler(#2786) - Avoid applying
constraint_fnto non-COMPLETEtrials in NSGAII-sampler (#2791) - Speed up
TPESampler(#2816) - Enable CLI helps for subcommands (#2823)
Bug Fixes
- Fix
AllenNLPExecutorreproducibility (#2717, thanks @MagiaSN!) - Use
reprandevalto restore pruner parameters in AllenNLP integration (#2731) - Fix
Nancast bug inTPESampler(#2739) - Fix
infer_relative_search_spaceof TPE with the single point distributions (#2749)
Installation
- Avoid latest numpy 1.21 (#2766)
- Fix numpy 1.21 related mypy errors (#2767)
Documentation
- Add how to suggest proportion to FAQ (#2718)
- Explain how to add a user's own logging callback function (#2730)
- Add
copy_studyto the docs (#2737) - Fix link to kurobako benchmark page (#2748)
- Improve docs of constant liar (#2785)
- Fix the document of
RetryFailedTrialCallback.retried_trial_number(#2789) - Match the case of
ID(#2798, thanks @belldandyxtq!) - Rephrase
RDBStorageRuntimeErrordescription (#2802, thanks @belldandyxtq!)
Examples
- Add remaining examples to CI tests (https://github.com/optuna/optuna-examples/pull/26)
- Use hydra 1.1.0 syntax (https://github.com/optuna/optuna-examples/pull/28)
- Replace monitor value with accuracy (https://github.com/optuna/optuna-examples/pull/32)
Tests
- Count the number of calls of the wrapped method in the test of
MOTPEMultiObjectiveSampler(#2666) - Add specific test cases for
visualization.matplotlib.plot_intermediate_values(#2754, thanks @asquare100!) - Added unit tests for optimization history of matplotlib tests (#2761, thanks @01-vyom!)
- Changed unit tests for pareto front of matplotlib tests (#2763, thanks @01-vyom!)
- Added unit tests for slice of matplotlib tests (#2764, thanks @01-vyom!)
- Added unit tests for param importances of matplotlib tests (#2774, thanks @01-vyom!)
- Changed unit tests for parallel coordinate of matplotlib tests (#2778, thanks @01-vyom!)
- Use more specific assert in
tests/visualization_tests/matplotlib/test_intermediate_plot.py(#2803) - Added unit tests for contour of matplotlib tests (#2806, thanks @01-vyom!)
Code Fixes
- Create
studydirectory (#2721) - Dissect allennlp integration in submodules based on roles (#2745)
- Fix deprecated version of
MOTPESampler(#2770)
Continuous Integration
- Daily CI of
Checks(#2760) - Use default resolver in CI's pip installation (#2779)
Other
- Bump up version to v2.9.0dev (#2723)
- Add an optional section to ask reproducible codes (#2799)
- Add survey news to
README.md(#2801) - Add python code to issue templates for making reporting runtime information easy (#2805)
- Bump to v2.9.0 (#2828)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@ytsmiling, @harupy, @asquare100, @hvy, @c-bata, @nzw0301, @lucafurrer, @belldandyxtq, @not522, @TakuyaInoue-github, @01-vyom, @himkt, @Crissman, @toshihikoyanase, @sile, @vanpelt, @HideakiImamura, @MagiaSN, @keisuke-umezawa, @Turakar, @xadrianzetx, @ytsmiling, @harupy, @asquare100, @hvy, @c-bata, @nzw0301, @lucafurrer, @belldandyxtq, @not522, @TakuyaInoue-github, @01-vyom, @himkt, @Crissman, @toshihikoyanase, @sile, @vanpelt, @HideakiImamura, @MagiaSN, @keisuke-umezawa, @Turakar, @xadrianzetx
- Python
Published by hvy almost 5 years ago
optuna - v2.8.0
This is the release note of v2.8.0.
New Examples Repository
The number of Optuna examples has grown as the number of integrations have increased, and we’ve moved them to their own repository: optuna/optuna-examples.
Highlights
TPE Sampler Improvements
Constant Liar for Distributed Optimization
In distributed environments, the TPE sampler may sample many points in a small neighborhood, because it does not have knowledge that other trials running in parallel are sampling nearby. To avoid this issue, we’ve implemented the Constant Liar (CL) heuristic to return a poor value for trials which have started but are not yet complete, to reduce search effort.
python
study = optuna.create_study(sampler=optuna.samplers.TPESampler(constant_liar=True))
The following history plots demonstrate how optimization can be improved using this feature. Ten parallel workers are simultaneously trying to optimize the same function which takes about one second to compute. The first plot has constant_liar=False, and the second with constant_liar=True, uses the Constant Liar feature. We can see that with Constant Liar, the sampler does a better job of assigning different parameter configurations to different trials and converging faster.

See #2664 for details.
Tree-structured Search Space Support
The TPE sampler with multivariate=True now supports tree-structured search spaces. Previously, if the user split the search space with an if-else statement, as shown below, the TPE sampler with multivariate=True would fall back to random sampling. Now, if you set multivariate=True and group=True, the TPE sampler algorithm will be applied to each partitioned search space to perform efficient sampling.
See #2526 for more details.
```python def objective(trial): classifiername = trial.suggestcategorical("classifier", ["SVC", "RandomForest"])
if classifier_name == "SVC":
# If `multivariate=True` and `group=True`, the following 2 parameters are sampled jointly by TPE.
svc_c = trial.suggest_float("svc_c", 1e-10, 1e10, log=True)
svc_kernel = trial.suggest_categorical("kernel", ["linear", "rbf", "sigmoid"])
classifier_obj = sklearn.svm.SVC(C=svc_c, kernel=svc_kernel)
else:
# If `multivariate=True` and `group=True`, the following 3 parameters are sampled jointly by TPE.
rf_n_estimators = trial.suggest_int("rf_n_estimators", 1, 20)
rf_criterion = trial.suggest_categorical("rf_criterion", ["gini", "entropy"])
rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32, log=True)
classifier_obj = sklearn.ensemble.RandomForestClassifier(n_estimators=rf_n_estimators, criterion=rf_criterion, max_depth=rf_max_depth)
...
sampler = optuna.samplers.TPESampler(multivariate=True, group=True) ```
Copying Studies
Studies can now be copied across storages. The trial history as well as Study.user_attrs and Study.system_attrs are preserved.
For instance, this allows dumping a study in an MySQL RDBStorage into an SQLite file. Serializing the study this way, it can be shared with other users who are unable to access the original storage.
```python study = optuna.createstudy( studyname=”my-study”, storage=”mysql+pymysql://root@localhost/optuna" ) study.optimize(..., n_trials=100)
Creates a copy of the study “my-study” in an MySQL RDBStorage to a local file named optuna.db.
optuna.copystudy( fromstudyname="my-study", fromstorage="mysql+pymysql://root@localhost/optuna", to_storage="sqlite:///optuna.db", )
study = optuna.loadstudy(studyname=”my-study”, storage=”sqlite:///optuna.db”) assert len(study.trials) >= 100 ```
See #2607 for details.
Callbacks
optuna.storages.RetryFailedTrialCallback Added
Used as a callback in RDBStorage, this allows a previously pre-empted or otherwise aborted trials that are detected by a failed heartbeat to be re-run.
python
storage = optuna.storages.RDBStorage(
url="sqlite:///:memory:",
heartbeat_interval=60,
grace_period=120,
failed_trial_callback=optuna.storages.RetryFailedTrialCallback(max_retry=3),
)
study = optuna.create_study(storage=storage)
See #2694 for details.
optuna.study.MaxTrialsCallback Added
Used as a callback in study.optimize, this allows setting of a maximum number of trials of a particular state, such as setting the maximum number of failed trials, before stopping the optimization.
python
study.optimize(
objective,
callbacks=[optuna.study.MaxTrialsCallback(10, states=(optuna.trial.TrialState.COMPLETE,))],
)
See #2636 for details.
Breaking Changes
- Allow
Noneasstudy_namewhen there is only a single study inload_study(#2608) - Relax
GridSamplerallowing not-contained parameters duringsuggest_*(#2663)
New Features
- Make
LightGBMTunerandLightGBMTunerCVreproducible (#2431, thanks @tetsuoh0103!) - Add
visualization.matplotlib.plot_pareto_front(#2450, thanks @tohmae!) - Support a group decomposed search space and apply it to TPE (#2526)
- Add
__str__for samplers (#2539) - Add
n_min_trialsargument forPercentilePrunerandMedianPruner(#2556) - Copy study (#2607)
- Allow
Noneasstudy_namewhen there is only a single study inload_study(#2608) - Add
MaxTrialsCallbackclass to enable stopping after fixed number of trials (#2612) - Implement
PatientPruner(#2636) - Support multi-objective optimization in CLI (
optuna create-study) (#2640) - Constant liar for
TPESampler(#2664) - Add automatic retry callback (#2694)
- Sorts categorical values on axis that contains only numerical values in
visualization.matplotlib.plot_slice(#2709, thanks @Muktan!)
Enhancements
PyTorchLightningPruningCallbackto warn when an evaluation metric does not exist (#2157, thanks @bigbird555!)- Pareto front visualization to visualize study progress with color scales (#2563)
- Sort categorical values on axis that contains only numerical values in
visualization.plot_contour(#2569) - Improve
param_importances(#2576) - Sort categorical values on axis that contains only numerical values in
visualization.matplotlib.plot_contour(#2593) - Show legend of
optuna.visualization.matplotlib.plot_edf(#2603) - Show legend of
optuna.visualization.matplotlib.plot_intermediate_values(#2606) - Make
MOTPEMultiObjectiveSamplera thin wrapper forMOTPESampler(#2615) - Do not wait for next heartbeat on study completion (#2686, thanks @Turakar!)
- Change colour scale of contour plot by
matplotlibfor consistency with plotly results (#2711, thanks @01-vyom!)
Bug Fixes
- Add type conversion for reference point and solution set (#2584)
- Fix contour plot with multi-objective study and
targetbeing specified (#2589) - Fix distribution's
_contains(#2652) - Read environment variables in
dump_best_config(#2681) - Update version info entry on RDB storage upgrade (#2687)
- Fix results not reproducible when running
AllenNLPExecutormultiple t… (Backport of #2717) (#2728)
Installation
- Replace
sklearnconstraint (#2634) - Add constraint of Sphinx version (#2657)
- Add
click==7.1.2to GitHub workflows to solve AllenNLP import error (#2665) - Avoid
tensorflow2.5.0 (#2674) - Remove
examplefromsetup.py(#2676)
Documentation
- Add example to
optuna.logging.disable_propagation(#2477, thanks @jeromepatel!) - Add documentation for hyperparameter importance target parameter (#2551)
- Remove the news section in
README.md(#2586) - Documentation updates to
CmaEsSampler(#2591, thanks @turian!) - Rename
ray-joblib.pyto snakecase with underscores (#2594) - Replace
Ifwithifin a sentence (#2602) - Use
CmaEsSamplerinstead ofTPESamplerin the batch optimization example (#2610) - README fixes (#2617, thanks @Scitator!)
- Remove wrong returns description in docstring (#2619)
- Improve document on
BoTorchSamplerpage (#2631) - Add the missing colon (#2661)
- Add missing parameter
WAITINGdetails in docstring (#2683, thanks @jeromepatel!) - Update URLs to
optuna-examples(#2684) - Fix indents in the ask-and-tell tutorial (#2690)
- Join sampler examples in
README.md(#2692) - Fix typo in the tutorial (#2704)
- Update command for installing auto-formatters (#2710, thanks @01-vyom!)
- Some edits for
CONTRIBUTING.md(#2719)
Examples
- Split GitHub Actions workflows (https://github.com/optuna/optuna-examples/pull/1)
- Cherry pick #2611 of
optuna/optuna(https://github.com/optuna/optuna-examples/pull/2) - Add checks workflow (https://github.com/optuna/optuna-examples/pull/5)
- Add
MaxTrialsCallbackclass to enable stopping after fixed number of trials (https://github.com/optuna/optuna-examples/pull/9) - Update
README.md(https://github.com/optuna/optuna-examples/pull/10) - Add an example of warm starting CMA-ES (https://github.com/optuna/optuna-examples/pull/11, thanks @nmasahiro!)
- Replace old links to example files (https://github.com/optuna/optuna-examples/pull/12)
- Avoid
tensorflow2.5.0 (https://github.com/optuna/optuna-examples/pull/13) - Avoid
tensorflow2.5 (https://github.com/optuna/optuna-examples/pull/15) - Test
multi_objectivein CI (https://github.com/optuna/optuna-examples/pull/16) - Use only one GPU for PyTorch Lightning example by default (https://github.com/optuna/optuna-examples/pull/17)
- Remove example of CatBoost in pruning section (https://github.com/optuna/optuna-examples/pull/18, #2702)
- Add issues and pull request templates (https://github.com/optuna/optuna-examples/pull/20)
- Add
CONTRIBUTING.mdfile ((https://github.com/optuna/optuna-examples/pull/21) - Change PR approvers from two to one (https://github.com/optuna/optuna-examples/pull/22)
- Improved search space XGBoost (#2346, thanks @jeromepatel!)
- Remove
n_jobsforstudy.optimizeinexamples/(#2588, thanks @jeromepatel!) - Using the "log" key is deprecated in
pytorch_lightning(#2611, thanks @sushi30!) - Move examples to a new repository (#2655)
- Remove remaining examples (#2675)
optuna-examples(https://github.com/optuna/optuna-examples/pull/11 follow up (#2689)
Tests
- Remove assertions for supported dimensions from
test_plot_pareto_front_unsupported_dimensions(#2578) - Update a test function of
matplotliv.plot_pareto_frontfor consistency (#2583) - Add
deterministicparameter to make LightGBM training reproducible (#2623) - Add
force_col_wiseparameter of LightGBM in test cases ofLightGBMTunerandLightGBMTunerCV(#2630, thanks @tetsuoh0103!) - Remove
CudaCallbackfrom the fastai test (#2641) - Add test cases in
optuna/visualization/matplotlib/edf.py(#2642) - Refactor a unittest in
test_median.py(#2644) - Refactor
pruners_test(#2691, thanks @tsumli!)
Code Fixes
- Remove redundant lines in CI settings of
examples(#2554) - Remove the unused argument of functions in
matplotlib.contour(#2571) - Fix axis labels of
optuna.visualization.matplotlib.plot_pareto_frontwhenaxis_orderis specified (#2577) - Remove list casts (#2601)
- Remove
_get_distributionfromvisualization/matplotlib/_param_importances.py(#2604) - Fix grammatical error in failure message (#2609, thanks @agarwalrounak!)
- Separate
MOTPESamplerfromTPESampler(#2616) - Simplify
add_distributionsin_SearchSpaceGroup(#2651) - Replace old example URLs in
optuna.integrations(#2700)
Continuous Integration
- Supporting Python 3.9 with integration modules and optional dependencies (#2530, thanks @0x41head!)
- Upgrade pip in PyPI and Test PyPI workflow (#2598)
- Fix PyPI publish workflow (#2624)
- Introduce speed benchmarks using
asv(#2673)
Other
- Bump
masterversion to2.8.0dev(#2562) - Upload to TestPyPI at the time of release as well (#2573)
- Install blackdoc in
formats.sh(#2637) - Use
commandto check the existence of the libraries to avoid partially matching (#2653) - Add an example section to the README (#2667)
- Fix formatting in contribution guidelines (#2668)
- Update
CONTRIBUTING.mdwithoptuna-examples(#2669)
Thanks to All the Contributors!
This release was made possible by the authors and the people who participated in the reviews and discussions.
@toshihikoyanase, @himkt, @Scitator, @tohmae, @crcrpar, @c-bata, @01-vyom, @sushi30, @tsumli, @not522, @tetsuoh0103, @jeromepatel, @bigbird555, @hvy, @g-votte, @nzw0301, @turian, @Crissman, @sile, @agarwalrounak, @Muktan, @Turakar, @HideakiImamura, @keisuke-umezawa, @0x41head, @toshihikoyanase, @himkt, @Scitator, @tohmae, @crcrpar, @c-bata, @01-vyom, @sushi30, @tsumli, @not522, @tetsuoh0103, @jeromepatel, @bigbird555, @hvy, @g-votte, @nzw0301, @turian, @nmasahiro, @Crissman, @sile, @agarwalrounak, @Muktan, @Turakar, @HideakiImamura, @keisuke-umezawa, @0x41head
- Python
Published by hvy about 5 years ago
optuna - v2.7.0
This is the release note for v2.7.0.
Highlights
New optuna-dashboard Repository
A new dashboard optuna-dashboard is being developed in a separate repository under the Optuna organization. Install it with pip install optuna-dashboard and run it with optuna-dashboard $STORAGE_URL.
The previous optuna dashboard command is now deprecated.
Deprecate n_jobs Argument of Study.optimize
The GIL has been an issue when using the n_jobs argument for multi-threaded optimization. We decided to deprecate this option in favor of the more stable process-level parallelization. Details available in the tutorial. Users who have been parallelizing at the thread level using the n_jobs argument are encouraged to refer to the tutorial for process-level parallelization.
If the objective function is not affected by the GIL, thread-level parallelism may be useful. You can achieve thread-level parallelization in the following way.
python
with ThreadPoolExecutor(max_workers=5) as executor:
for _ in range(5):
executor.submit(study.optimize, objective, 100)
New Tutorial and Examples
Tutorial pages about the usage of the ask-and-tell interface (#2422) and best_trial (#2427) have been added, as well as an example that demonstrates parallel optimization using Ray (#2298) and an example to explain how to stop the optimization based on the number of completed trials instead of the total number of trials (#2449).
Improved Code Quality
The code quality was improved in terms of bug fixes, third party library support, and platform support.
For instance, the bugs on warm starting CMA-ES and visualization.matplotlib.plot_optimization_history were resolved by #2501 and #2532, respectively.
Third party libraries such as PyTorch, fastai, and AllenNLP were updated. We have updated the corresponding integration modules and examples for the new versions. See #2442, #2550 and #2528 for details.
From this version, we are expanding the platform support. Previously, changes were tested in Linux containers. Now, we also test changes merged into the master branch in macOS containers as well (#2461).
Breaking Changes
- Deprecate dashboard (#2559)
- Deprecate
n_jobsinStudy.optimize(#2560)
New Features
- Support object representation of
StudyDirectionforcreate_studyarguments (#2516)
Enhancements
- Change caching implementation of MOTPE (#2406, thanks @y0z!)
- Fix to replace
numpy.append(#2419, thanks @nyanhi!) - Modify
after_trialforNSGAIISampler(#2436, thanks @jeromepatel!) - Print a URL of a related release note in the warning message (#2496)
- Add log-linear algorithm for 2d Pareto front (#2503, thanks @parsiad!)
- Concatenate the argument text after the deprecation warning (#2558)
Bug Fixes
- Use 2.0 style delete API of SQLAlchemy (#2487)
- Fix Warm Starting CMA-ES with a maximize direction (#2501)
- Fix
visualization.matplotlib.plot_optimization_historyfor multi-objective (#2532)
Installation
- Bump
torchto 1.8.0 (#2442) - Remove Cython from
install_requires(#2466) - Fix Cython installation for Python 3.9 (#2474)
- Avoid catalyst 21.3 (#2480, thanks @crcrpar!)
Documentation
- Add ask and tell interface tutorial (#2422)
- Add tutorial for re-use of the
best_trial(#2427) - Add explanation for get_storage in the API reference (#2430)
- Follow-up of the user-defined pruner tutorial (#2446)
- Add a new example
max_trial_callbacktooptuna/examples(#2449, thanks @jeromepatel!) - Standardize on 'hyperparameter' usage (#2460)
- Replace MNIST with Fashion MNIST in multi-objective optimization tutorial (#2468)
- Fix links on
SuccessiveHalvingPrunerpage (#2489) - Swap the order of
load_if_existsanddirectionsfor consistency (#2491) - Clarify
n_jobsforOptunaSearchCV(#2545) - Mention the paper is in Japanese (#2547, thanks @crcrpar!)
- Fix typo of the paper's author name (#2552)
Examples
- Add an example of
Raywithjoblibbackend (#2298) - Added RL and Multi-Objective examples to
examples/README.md(#2432, thanks @jeromepatel!) - Replace
shwithbashin README of kubernetes examples (#2440) - Apply #2438 to pytorch examples (#2453, thanks @crcrpar!)
- More Examples Folders after #2302 (#2458, thanks @crcrpar!)
- Apply
urllibpatch for MNIST download (#2459, thanks @crcrpar!) - Update
Dockerfileof MLflow Kubernetes examples (#2472, thanks @0x41head!) - Replace Optuna's Catalyst pruning callback with Catalyst's Optuna pruning callback (#2485, thanks @crcrpar!)
- Use whitespace tokenizer instead of spacy tokenizer (#2494)
- Use Fashion MNIST in example (#2505, thanks @crcrpar!)
- Update
pytorch_lightning_distributed.pyto remove MNIST and PyTorch Lightning errors (#2514, thanks @0x41head!) - Use
OptunaPruningCallbackincatalyst_simple.py(#2546, thanks @crcrpar!) - Support fastai 2.3.0 (#2550)
Tests
- Add
MOTPESamplerinparametrize_multi_objective_sampler(#2448) - Extract test cases regarding Pareto front to
test_multi_objective.py(#2525)
Code Fixes
- Fix
mypyerrors produced bynumpy==1.20.0(#2300, thanks @0x41head!) - Simplify the code to find best values (#2394)
- Use
_SearchSpaceTransforminRandomSampler(#2410, thanks @sfujiwara!) - Set the default value of
stateofcreate_trialasCOMPLETE(#2429)
Continuous Integration
- Run TensorFlow related examples on Python3.8 (#2368, thanks @crcrpar!)
- Use legacy resolver in CI's pip installation (#2434, thanks @crcrpar!)
- Run tests and integration tests on Mac & Python3.7 (#2461, thanks @crcrpar!)
- Run Dask ML example on Python3.8 (#2499, thanks @crcrpar!)
- Install OpenBLAS for mxnet1.8.0 (#2508, thanks @crcrpar!)
- Add ray to requirements (#2519, thanks @crcrpar!)
- Upgrade AllenNLP to
v2.2.0(#2528) - Add Coverage for ChainerMN in codecov (#2535, thanks @jeromepatel!)
- Skip fastai2.3 tentatively (#2548, thanks @crcrpar!)
Other
- Add
-foption tomake cleancommand idempotent (#2439) - Bump
masterversion to2.7.0dev(#2444) - Document how to write a new tutorial in
CONTRIBUTING.md(#2463, thanks @crcrpar!) - Bump up version number to 2.7.0 (#2561)
Thanks to All the Contributors!
This release was made possible by authors, and everyone who participated in reviews and discussions.
@0x41head, @AmeerHajAli, @Crissman, @HideakiImamura, @c-bata, @crcrpar, @g-votte, @himkt, @hvy, @jeromepatel, @keisuke-umezawa, @not522, @nyanhi, @nzw0301, @parsiad, @sfujiwara, @sile, @toshihikoyanase, @y0z
- Python
Published by HideakiImamura about 5 years ago
optuna - v2.6.0
This is the release note of v2.6.0.
Highlights
Warm Starting CMA-ES and sep-CMA-ES Support
Two new CMA-ES variants are available. Warm starting CMA-ES enables transferring prior knowledge on similar tasks. More specifically, CMA-ES can be initialized based on existing results of similar tasks. sep-CMA-ES is an algorithm which constrains the covariance matrix to be diagonal and is suitable for separable objective functions. See #2307 and #1951 for more details.
Example of Warm starting CMA-ES:
```python study = optuna.loadstudy(storage=”...”, studyname=”existing-study”)
study.sampler = CmaEsSampler(sourcetrials=study.trials) study.optimize(objective, ntrials=100) ```

Example of sep-CMA-ES:
python
study = optuna.create_study(sampler=CmaEsSampler(use_separable_cma=True))
study.optimize(objective, n_trials=100)

PyTorch Distributed Data Parallel
Hyperparameter optimization for distributed neural-network training using PyTorch Distributed Data Parallel is supported. A new integration moduleTorchDistributedTrial, synchronizes the hyperparameters among all nodes. See #2303 for further details.
Example:
python
def objective(trial):
distributed_trial = optuna.integration.TorchDistributedTrial(trial)
lr = distributed_trial.suggest_float("lr", 1e-5, 1e-1, log=True)
…
RDBStorage Improvements
The RDBStorage now allows longer user and system attributes, as well as choices for categorical distributions (e.g. choices spanning thousands of bytes/characters) to be persisted. Corresponding column data types of the underlying SQL tables have been changed from VARCHAR to TEXT. If you want to upgrade from an older version of Optuna and keep using the same storage, please migrate your tables as follows. Please make sure to create any backups before the migration and note that databases that don’t support TEXT will not work with this release.
```console
Alter table columns from VARCHAR to TEXT to allow storing larger data.
optuna storage upgrade --storage
For more details, see #2395.
Heartbeat Improvements
The heartbeat feature was introduced in v2.5.0 to automatically mark stale trials as failed. It is now possible to not only fail the trials but also execute user-specified callback functions to process the failed trials. See #2347 for more details.
Example:
```python def objective(trial): … # Very time-consuming computation.
Adding a failed trial to the trial queue.
def failedtrialcallback(study, trial): study.addtrial( optuna.createtrial( state=optuna.trial.TrialState.WAITING, params=trial.params, distributions=trial.distributions, userattrs=trial.userattrs, systemattrs=trial.systemattrs, ) )
storage = optuna.storages.RDBStorage( url=..., heartbeatinterval=60, graceperiod=120, failedtrialcallback=failedtrialcallback, ) study = optuna.createstudy(storage=storage) study.optimize(objective, ntrials=100)
```
Pre-defined Search Space with Ask-and-tell Interface
The ask-and-tell interface allows specifying pre-defined search spaces through the new fixed_distributions argument. This option will keep the code short when the search space is known beforehand. It replaces calls to Trial.suggest_…. See #2271 for more details.
```python study = optuna.create_study()
For example, the distributions are previously defined when using create_trial.
distributions = { "optimizer": optuna.distributions.CategoricalDistribution(["adam", "sgd"]), "lr": optuna.distributions.LogUniformDistribution(0.0001, 0.1), } trial = optuna.trial.createtrial( params={"optimizer": "adam", "lr": 0.0001}, distributions=distributions, value=0.5, ) study.addtrial(trial)
You can pass the distributions previously defined.
trial = study.ask(fixed_distributions=distributions)
optimizer and lr are already suggested and accessible with trial.params.
print(trial.params) ```
Breaking Changes
RDBStorage data type updates
Databases must be migrated for storages that were created with earlier versions of Optuna. Please refer to the highlights above.
For more details, see #2395.
datatime_start of enqueued trials.
The datetime_start property of Trial, FrozenTrial and FixedTrial shows when a trial was started. This property may now be None. For trials enqueued with Study.enqueue_trial, the timestamp used to be set to the time of queue. Now, the timestamp is first set to None when enqueued, and later updated to the timestamp when popped from the queue to run. This has implications on StudySummary.datetime_start as well which may be None in case trials have been enqueued but not popped.
For more details, see #2236.
joblib internals removed
joblib was partially supported as a backend for parallel optimization via the n_jobs parameter to Study.optimize. This support has now been removed and internals have been replaced with concurrent.futures.
For more details, see #2269.
AllenNLP v2 support
Optuna now officially supports AllenNLP v2. We also dropped the AllenNLP v0 support and the pruning support for AllenNLP v1. If you want to use AllenNLP v0 or v1 with Optuna, please install Optuna v2.5.0.
For more details, see #2412.
New Features
- Support sep-CMA-ES algorithm (#1951)
- Add an option to the
Study.askmethod that allows define-and-run parameter suggestion (#2271) - Add integration module for PyTorch Distributed Data Parallel (#2303)
- Support Warm Starting CMA-ES (#2307)
- Add callback argument for heartbeat functionality (#2347)
- Support
IntLogUniformDistributionfor TensorBoard (#2362, thanks @nzw0301!)
Enhancements
- Fix the wrong way to set
datetime_start(clean) (#2236, thanks @chenghuzi!) - Multi-objective error messages from
Studyto suggest solutions (#2251) - Adds missing
LightGBMTunermetrics for the case of higher is better (#2267, thanks @mavillan!) - Color Inversion to make contour plots more visually intuitive (#2291, thanks @0x41head!)
- Close sessions at the end of with-clause in
Storage(#2345) - Improve "plotparetofront" (#2355, thanks @0x41head!)
- Implement
after_trialmethod inCmaEsSampler(#2359, thanks @jeromepatel!) - Convert
lowandhighto float explicitly in distributions (#2360) - Add
after_trialforPyCmaSampler(#2365, thanks @jeromepatel!) - Implement
after_trialforBoTorchSamplerandSkoptSampler(#2372, thanks @jeromepatel!) - Implement
after_trialforTPESampler(#2376, thanks @jeromepatel!) - Support
BoTorch >= 0.4.0(#2386, thanks @nzw0301!) - Mitigate string-length limitation of
RDBStorage(#2395) - Support AllenNLP v2 (#2412)
- Implement
after_trialforMOTPESampler(#2425, thanks @jeromepatel!)
Bug Fixes
- Add test and fix for relative sampling failure in multivariate TPE (#2055, thanks @alexrobomind!)
- Fix
optuna.visualization.plot_contourof subplot case with categorical axes (#2297, thanks @nzw0301!) - Only fail trials associated with the current study (#2330)
- Fix TensorBoard integration for
suggest_float(#2335, thanks @nzw0301!) - Add type conversions for upper/lower whose values are integers (#2343)
- Fix improper stopping with the combination of
GridSamplerandHyperbandPruner(#2353) - Fix
matplotlib.plot_parallel_coordinatewith only one suggested parameter (#2354, thanks @nzw0301!) - Create
model_dirby_LightGBMBaseTuner(#2366, thanks @nyanhi!) - Fix assertion in cached storage for state update (#2370)
- Use
lowin_transform_from_uniformfor TPE sampler (#2392, thanks @nzw0301!) - Remove indices from
optuna.visualization.plot_parallel_coordinatewith categorical values (#2401, thanks @nzw0301!)
Installation
mypyhotfix voiding latest NumPy 1.20.0 (#2292)- Remove
jaxfromsetup.py(#2308, thanks @nzw0301!) - Install
torchfrom PyPI for ReadTheDocs (#2361) - Pin
botorchversion (#2379)
Documentation
- Fix broken links in
README.md(#2268) - Provide
docs/source/tutorialfor faster local documentation build (#2277) - Remove specification of
n_trialsfrom example ofGridSampler(#2280) - Fix typos and errors in document (#2281, thanks @belldandyxtq!)
- Add tutorial of multi-objective optimization of neural network with PyTorch (#2305)
- Add explanation for local verification (#2309)
- Add
sphinx.ext.imgconverterextension (#2323, thanks @KoyamaSohei!) - Include
highin the documentation ofUniformDistributionandLogUniformDistribution(#2348) - Fix typo; Replace dimentional with dimensional (#2390, thanks @nzw0301!)
- Fix outdated docstring of
TFKerasPruningCallback(#2399, thanks @sfujiwara!) - Call
fig.show()in visualization code examples (#2403, thanks @harupy!) - Explain the backend of parallelisation (#2428, thanks @nzw0301!)
- Navigate with left/right arrow keys in the document (#2433, thanks @ydcjeff!)
- Hotfix for MNIST download in tutorial (#2438)
Examples
- Provide a user-defined pruner example (#2140, thanks @tktran!)
- Add Hydra example (#2290, thanks @nzw0301!)
- Use
trainer.callback_metricsin the Pytorch Lightning example (#2294, thanks @TezRomacH!) - Example folders (#2302)
- Update PL example with typing and
DataModule(#2332, thanks @TezRomacH!) - Remove unsupported argument from PyTorch Lightning example (#2357)
- Update
examples/kubernetes/mlflow/check_study.shto match whole words (#2363, thanks @twolffpiggott!) - Add PyTorch checkpoint example using
failed_trial_callback(#2373) - Update
Dockerfileof Kubernetes simple example (#2375, thanks @0x41head!)
Tests
- Refactor test of
GridSampler(#2285) - Replace
parametrize_storagewithStorageSupplier(#2404, thanks @nzw0301!)
Code Fixes
- Replace
joblibwithconcurrent.futuresfor parallel optimization (#2269) - Make trials stale only when succeeded to fail (#2284)
- Apply code-fix to
LightGBMTuner(Follow-up #2267) (#2299) - Inherit
PyTorchLightningPruningCallbackfrom Callback (#2326, thanks @TezRomacH!) - Consistently use
suggest_float(#2344) - Fix typo (#2352, thanks @nzw0301!)
- Increase API request limit for stale bot (#2369)
- Fix typo; replace
contraintswithconstraints(#2378, thanks @nzw0301!) - Fix typo (#2383, thanks @nzw0301!)
- Update examples for
study.get_trialsfor states filtering (#2393, thanks @jeromepatel!) - Fix - remove arguments of python2
super().__init__(#2402, thanks @nyanhi!)
Continuous Integration
- Turn off RDB tests on circleci (#2255)
- Allow allennlp in py3.8 integration tests (#2367)
- Color pytest logs (#2400, thanks @harupy!)
- Remove
-foption from doctest pip installation (#2418)
Other
- Bump up version number to
v2.6.0.dev(#2283) - Enable automatic closing of stale issues and pull requests by github actions (#2287)
- Add setup section to
CONTRIBUTING.md(#2342) - Fix the local
mypyerror on Pytorch Lightning integration (#2349) - Update the link to the
botorchexample (#2377, thanks @nzw0301!) - Remove
-foption from documentation installation (#2407)
Thanks to All the Contributors!
This release was made possible by authors, and everyone who participated in reviews and discussions.
@0x41head, @Crissman, @HideakiImamura, @KoyamaSohei, @TezRomacH, @alexrobomind, @belldandyxtq, @c-bata, @chenghuzi, @crcrpar, @g-votte, @harupy, @himkt, @hvy, @jeromepatel, @keisuke-umezawa, @mavillan, @not522, @nyanhi, @nzw0301, @sfujiwara, @sile, @tktran, @toshihikoyanase, @twolffpiggott, @ydcjeff, @ytsmiling
- Python
Published by HideakiImamura over 5 years ago
optuna - v2.5.0
This is the release note of v2.5.0.
Highlights
Ask-and-Tell
The ask-and-tell interface is a new complement to Study.optimize. It allows users to construct Trial instances without the need of an objective function callback, giving more flexibility in how to define search spaces, ask for suggested hyperparameters and how to evaluate objective functions. The interface is made out of two methods, Study.ask and Study.tell.
Study.askreturns a newTrialobject.Study.telltakes either aTrialobject or a trial number along with the result of that trial, i.e. a value and/or the state, and saves it. SinceStudy.tellaccepts a trial number, a trial object can be disposed after parameters have been suggested. This allows objective function evaluations on a different thread or process.
```python import optuna from optuna.trial import TrialState
study = optuna.create_study()
Use a Python for-loop to iteratively optimize the study.
for _ in range(100):
trial = study.ask() # trial is a Trial and not a FrozenTrial.
# Objective function, in this case not as a function but at global scope.
x = trial.suggest_float("x", -1, 1)
y = x ** 2
study.tell(trial, y)
# Or, tell by trial number. This is equivalent to `study.tell(trial, y)`.
# study.tell(trial.number, y)
# Or, prune if the trial seems unpromising.
# study.tell(trial, state=TrialState.PRUNED)
assert len(study.trials) == 100 ```
Heartbeat
Now, Optuna supports monitoring trial heartbeats with RDB storages. For example, if a process running a trial is killed by a scheduler in a cluster environment, Optuna will automatically change the state of the trial that was running on that process to TrialState.FAIL from TrialState.RUNNING.
```python
Consider running this script on several processes.
import optuna
def objective(trial): (Very time-consuming computation)
Recording heartbeats every 60 seconds.
Other processes' trials where more than 120 seconds have passed
since the last heartbeat was recorded will be automatically failed.
storage = optuna.storages.RDBStorage(url=..., heartbeatinterval=60, graceperiod=120) study = optuna.createstudy(storage=storage) study.optimize(objective, ntrials=100) ```
Constrained NSGA-II
NSGA-II experimentally supports constrained optimization. Users can introduce constraints with the new constraints_func argument of NSGAIISampler.__init__.
The following is an example using this argument, a bi-objective version of the knapsack problem. We have 100 pairs of items and two knapsacks, and would like to maximize the profits of items within the weight limitation.
```python import numpy as np import optuna
Define bi-objective knapsack problem.
nitems = 100 nknapsacks = 2 feasible_rate = 0.5 seed = 1
rng = np.random.RandomState(seed=seed) weights = rng.randint(10, 101, size=(nknapsacks, nitems)) profits = rng.randint(10, 101, size=(nknapsacks, nitems)) constraints = (np.sum(weights, axis=1) * feasible_rate).astype(np.int)
def objective(trial): xs = np.array([trial.suggestcategorical(f"x{i}", (0, 1)) for i in range(weights.shape[1])]) totalweights = np.sum(weights * xs, axis=1) totalprofits = np.sum(profits * xs, axis=1)
# Constraints which are considered feasible if less than or equal to zero. constraintsviolation = totalweights - constraints trial.setuserattr("constraint", constraints_violation.tolist())
return total_profits.tolist()
def constraintsfunc(trial): return trial.userattrs["constraint"]
sampler = optuna.samplers.NSGAIISampler(populationsize=10, constraintsfunc=constraints_func)
study = optuna.createstudy(directions=["maximize"] * nknapsacks, sampler=sampler) study.optimize(objective, n_trials=200) ```
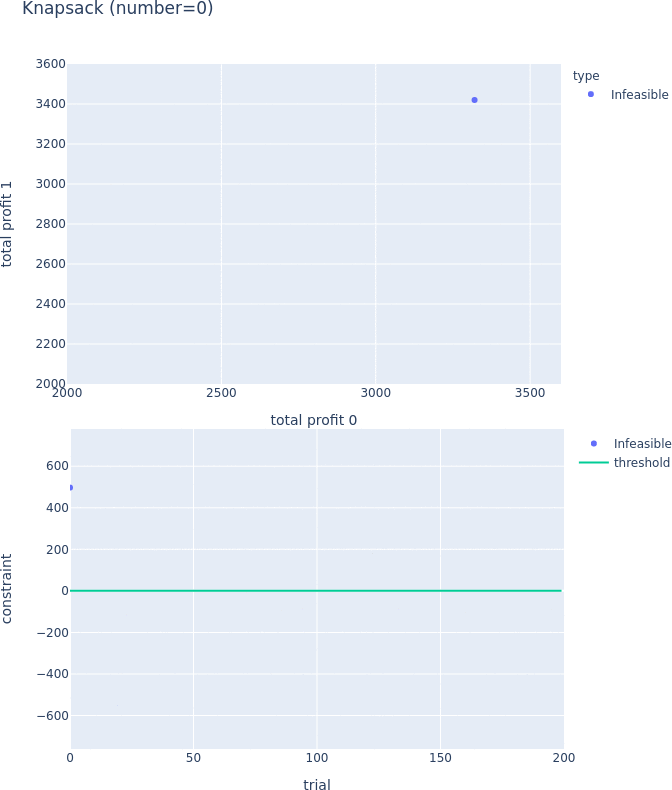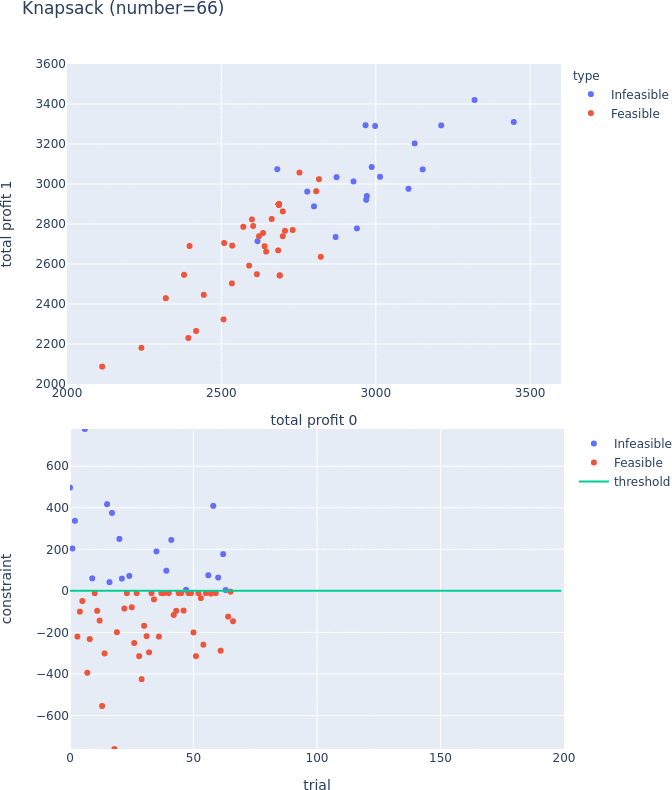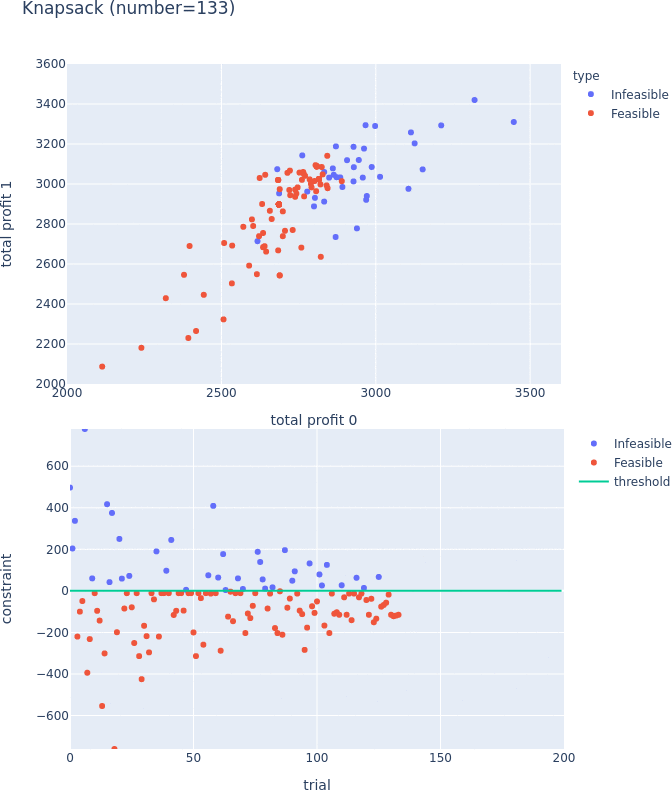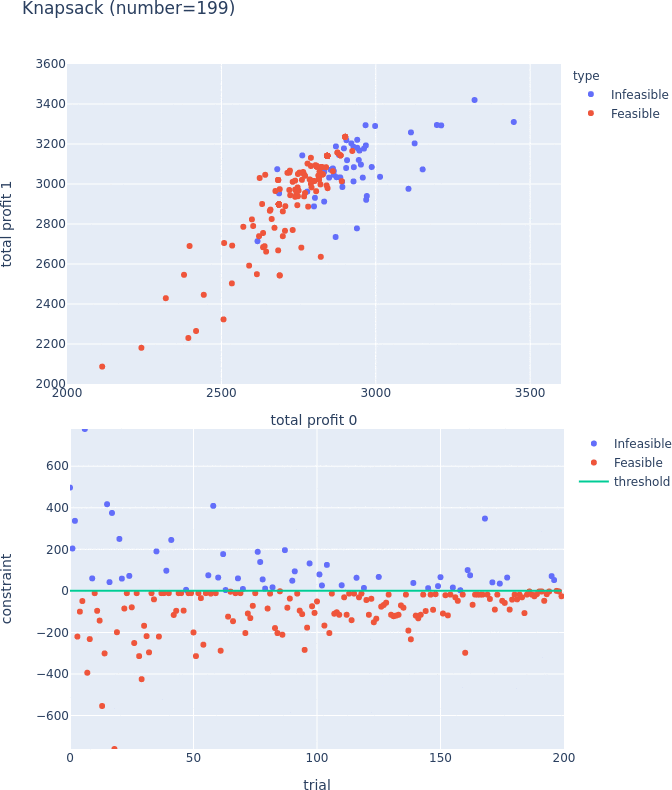
New Features
- Ask-and-Tell API (
Study.ask,Study.tell) (#2158) - Add
constraints_funcargument to NSGA-II (#2175) - Add heartbeat functionality using
threading(#2190) - Add
Study.add_trialsto simplify creating customized study (#2261)
Enhancements
- Support log scale in parallel coordinate (#2164, thanks @tohmae!)
- Warn if constraints are missing in constrained NSGA-II (#2205)
- Immediately persist suggested parameters with
_CachedStorage(#2214) - Include the upper bound of uniform/loguniform distributions (#2223)
Bug Fixes
- Call base sampler's
after_trialinPartialFixedSampler(#2209) - Fix
trials_dataframefor multi-objective optimization with fail or pruned trials (#2265) - Fix
calculate_weights_belowmethod ofMOTPESampler(#2274, thanks @y0z!)
Installation
- Remove version constraint for AllenNLP and run
allennlp_*.pyon GitHub Actions (#2226) - Pin
mypy==0.790(#2259) - Temporarily avoid AllenNLP v2 (#2276)
Documentation
- Add
callback&(add|enqueue)_trialrecipe (#2125) - Make
create_trial's documentation and tests richer (#2126) - Move import lines of the callback recipe (A follow-up of #2125) (#2221)
- Fix
optuna/samplers/_base.pytypo (#2239) - Introduce optuna-dashboard on README (#2224)
Examples
- Refactor
examples/multi_objective/pytorch_simple.py(#2230) - Move BoTorch example to
examples/multi_objectivedirectory (#2244) - Refactor
examples/multi_objective/botorch_simple.py(#2245, thanks @nzw0301!) - Fix typo in
examples/mlflow(#2258, thanks @nzw0301!)
Tests
- Make
create_trial's documentation and tests richer (#2126) - Fix unit test of median pruner (#2171)
SkoptSampleracquisition function in test to more likely converge (#2194)- Diet
tests/test_study.py(#2218) - Diet
tests/test_trial.py(#2219) - Shorten the names of trial tests (#2228)
- Move
STORAGE_MODEStotesting/storage.py(#2231) - Remove duplicate test on
study_tests/test_optimize.py(#2232) - Add init files in test directories (#2257)
Code Fixes
- Code quality improvements (#2009, thanks @srijan-deepsource!)
- Refactor CMA-ES sampler with search space transform (#2193)
BoTorchSamplerminor code fix reducing dictionary lookup and clearer type behavior (#2195)- Fix bad warning message in
BoTorchSampler(#2197) - Use
study.get_trialsinstead ofstudy._storage.get_all_trials(#2208) - Ensure uniform and loguniform distributions less than high boundary (#2243)
Continuous Integration
- Add
RDBStoragetests in github actions (#2200) - Publish distributions to TestPyPI on each day (#2220)
- Rename GitHub Actions jobs for (Test)PyPI uploads (#2254)
Other
- Fix the syntax of
pypi-publish.yml(#2187) - Fix
mypylocal fails intests/test_deprecated.pyandtests/test_experimental.py(#2191) - Add an explanation of "no period in the PR title" to
CONTRIBUTING.md(#2192) - Bump up version number to 2.5.0.dev (#2238)
- Fix mypy version to 0.790 (Follow-up of 2259) (#2260)
- Bump up version number to v2.5.0 (#2282)
Thanks to All the Contributors!
This release was made possible by authors, and everyone who participated in reviews and discussions.
@Crissman, @HideakiImamura, @c-bata, @crcrpar, @g-votte, @himkt, @hvy, @keisuke-umezawa, @not522, @nzw0301, @sile, @srijan-deepsource, @tohmae, @toshihikoyanase, @y0z, @ytsmiling
- Python
Published by hvy over 5 years ago
optuna - v2.4.0
This is the release note of v2.4.0.
Highlights
Python 3.9 Support
This is the first version to officially support Python 3.9. Everything is tested with the exception of certain integration modules under optuna.integration. We will continue to extend the support in the coming releases.
Multi-objective Optimization
Multi-objective optimization in Optuna is now a stable first-class citizen. Multi-objective optimization allows optimizing multi objectives at the same time such as maximizing model accuracy while minimizing model inference time.
Single-objective optimization can be extended to multi-objective optimization by
- specifying a sequence (e.g. a tuple) of
directionsinstead of a singledirectioninoptuna.create_study. Both parameters are supported for backwards compatibility - (optionally) specifying a sampler that supports multi-objective optimization in
optuna.create_study. If skipped, will default to theNSGAIISampler - returning a sequence of values instead of a single value from the objective function
Multi-objective Sampler
Samplers that support multi-objective optimization are currently the NSGAIISampler, the MOTPESampler, the BoTorchSampler and the RandomSampler.
Example
```python import optuna
def objective(trial): # The Binh and Korn function. It has two objectives to minimize. x = trial.suggestfloat("x", 0, 5) y = trial.suggestfloat("y", 0, 3)
v0 = 4 * x ** 2 + 4 * y ** 2
v1 = (x - 5) ** 2 + (y - 5) ** 2
return v0, v1
sampler = optuna.samplers.NSGAIISampler() study = optuna.createstudy(directions=["minimize", "minimize"], sampler=sampler) study.optimize(objective, ntrials=100)
Get a list of the best trials.
besttrials = study.besttrials
Visualize the best trials (i.e. Pareto front) in blue.
fig = optuna.visualization.plotparetofront(study, target_names=["v0", "v1"]) fig.show() ```

Migrating from the Experimental optuna.multi_objective
optuna.multi_objective, used to be an experimental submodule for multi-objective optimization. This submodule is now deprecated. Changes required to migrate to the new interfaces are subtle as described by the steps in the previous section.
Database Storage Schema Upgrade
With the introduction of multi-objective optimization, the database storage schema for the RDBStorage has been changed. To continue to use databases from v2.3, run the following command to upgrade your tables. Please create a backup of the database before.
bash
optuna storage upgrade --storage <URL to the storage, e.g. sqlite:///example.db>
BoTorch Sampler
BoTorchSampler is an experimental sampler based on BoTorch. BoTorch is a library for Bayesian optimization using PyTorch. See example for an example usage.
Constrained Optimization
For the first time in Optuna, BoTorchSampler allows constrained optimization. Users can impose constraints on hyperparameters or objective function values as follows.
```python import optuna
def objective(trial): x = trial.suggestfloat("x", -15, 30) y = trial.suggestfloat("y", -15, 30)
# Constraints which are considered feasible if less than or equal to zero.
# The feasible region is basically the intersection of a circle centered at (x=5, y=0)
# and the complement to a circle centered at (x=8, y=-3).
c0 = (x - 5) ** 2 + y ** 2 - 25
c1 = -((x - 8) ** 2) - (y + 3) ** 2 + 7.7
# Store the constraints as user attributes so that they can be restored after optimization.
trial.set_user_attr("constraint", (c0, c1))
return x ** 2 + y ** 2
def constraints(trial): return trial.user_attrs["constraint"]
Specify the constraint function when instantiating the BoTorchSampler.
sampler = optuna.integration.BoTorchSampler(constraintsfunc=constraints) study = optuna.createstudy(sampler=sampler) study.optimize(objective, n_trials=32) ```
Multi-objective Optimization
BoTorchSampler supports both single- and multi-objective optimization. By default, the sampler selects the appropriate sampling algorithm with respect to the number of objectives.
Customizability
BoTorchSampler is customizable via the candidates_func callback parameter. Users familiar with BoTorch can change the surrogate model, acquisition function, and its optimizer in this callback to utilize any of the algorithms provided by BoTorch.
Visualization with Callback Specified Target Values
Visualization functions can now plot values other than objective values, such as inference time or evaluation by other metrics. Users can specify the values to be plotted by specifying the target argument. Even in multi-objective optimization, visualization functions can be available with the target argument along a specific objective.
New Tutorials
The tutorial has been improved and new content for each Optuna’s key feature have been added. More contents will be added in the future. Please look forward to it!
Breaking Changes
- Allow filtering trials from
StudyandBaseStoragebased onTrialState(#1943) - Stop storing error stack traces in
fail_reasonin trialsystem_attr(#1964) - Importance with target values other than objective value (#2109)
New Features
- Implement
plot_contourand_get_contour_plotwith Matplotlib backend (#1782, thanks @ytknzw!) - Implement
plot_param_importancesand_get_param_importance_plotwith Matplotlib backend (#1787, thanks @ytknzw!) - Implement
plot_sliceand_get_slice_plotwith Matplotlib backend (#1823, thanks @ytknzw!) - Add
PartialFixedSampler(#1892, thanks @norihitoishida!) - Allow filtering trials from
StudyandBaseStoragebased onTrialState(#1943) - Add rung promotion limitation in ASHA/Hyperband to enable arbitrary unknown length runs (#1945, thanks @alexrobomind!)
- Add Fastai V2 pruner callback (#1954, thanks @hal-314!)
- Support options available on AllenNLP except to
node_rankanddry_run(#1959) - Universal data transformer (#1987)
- Introduce
BoTorchSampler(#1989) - Add axis order for
plot_pareto_front(#2000, thanks @okdshin!) plot_optimization_historywith target values other than objective value (#2064)plot_contourwith target values other than objective value (#2075)plot_parallel_coordinatewith target values other than objective value (#2089)plot_slicewith target values other than objective value (#2093)plot_edfwith target values other than objective value (#2103)- Importance with target values other than objective value (#2109)
- Migrate
optuna.multi_objective.visualization.plot_pareto_front(#2110) - Raise
ValueErroriftargetisNoneandstudyis for multi-objective optimization forplot_contour(#2112) - Raise
ValueErroriftargetisNoneandstudyis for multi-objective optimization forplot_edf(#2117) - Raise
ValueErroriftargetisNoneandstudyis for multi-objective optimization forplot_optimization_history(#2118) plot_param_importanceswith target values other than objective value (#2119)- Raise
ValueErroriftargetisNoneandstudyis for multi-objective optimization forplot_parallel_coordinate(#2120) - Raise
ValueErroriftargetisNoneandstudyis for multi-objective optimization forplot_slice(#2121) - Trial post processing (#2134)
- Raise
NotImplementedErrorfortrial.reportandtrial.should_pruneduring multi-objective optimization (#2135) - Raise
ValueErrorin TPE and CMA-ES ifstudyis being used for multi-objective optimization (#2136) - Raise
ValueErroriftargetisNoneandstudyis for multi-objective optimization forget_param_importances,BaseImportanceEvaluator.evaluate, andplot_param_importances(#2137) - Raise
ValueErrorin integration samplers ifstudyis being used for multi-objective optimization (#2145) - Migrate NSGA2 sampler (#2150)
- Migrate MOTPE sampler (#2167)
- Storages to query trial IDs from numbers (#2168)
Enhancements
- Use context manager to treat session correctly (#1628)
- Integrate multi-objective optimization module for the storages, study, and frozen trial (#1994)
- Pass
include_packageto AllenNLP for distributed setting (#2018) - Change the RDB schema for multi-objective integration (#2030)
- Update pruning callback for xgboost 1.3 (#2078, thanks @trivialfis!)
- Fix log format for single objective optimization to include best trial (#2128)
- Implement
Study._is_multi_objective()to check whether study has multiple objectives (#2142, thanks @nyanhi!) TFKerasPruningCallbackto warn when an evaluation metric does not exist (#2156, thanks @bigbird555!)- Warn default target name when target is specified (#2170)
Study.trials_dataframefor multi-objective optimization (#2181)
Bug Fixes
- Make always compute
weights_belowinMOTPEMultiObjectiveSampler(#1979) - Fix the range of categorical values (#1983)
- Remove circular reference of study (#2079)
- Fix flipped colormap in
matplotlibbackendplot_parallel_coordinate(#2090) - Replace builtin
isnumericalto capture float values inplot_contour(#2096, thanks @nzw0301!) - Drop unnecessary constraint from upgraded
trial_valuestable (#2180)
Installation
- Ignore
testsdirectory on install (#2015, thanks @130ndim!) - Clean up
setup.pyrequirements (#2051) - Pin
xgboost<1.3(#2084) - Bump up PyTorch version (#2094)
Documentation
- Update tutorial (#1722)
- Introduce plotly directive (#1944, thanks @harupy!)
- Check everything by
blackdoc(#1982) - Remove
codecovfromCONTRIBUTING.md(#2005) - Make the visualization examples deterministic (#2022, thanks @harupy!)
- Use plotly directive in
plot_pareto_front(#2025) - Remove plotly scripts and unused generated files (#2026)
- Add mandarin link to ReadTheDocs layout (#2028)
- Document about possible duplicate parameter configurations in
GridSampler(#2040) - Fix
MOTPEMultiObjectiveSampler's example (#2045, thanks @norihitoishida!) - Fix Read the Docs build failure caused by
pip install --find-links(#2065) - Fix
ltsymbol (#2068, thanks @KoyamaSohei!) - Fix parameter section of
RandomSamplerin docs (#2071, thanks @akihironitta!) - Add note on the behavior of
suggest_floatwithstepargument (#2087) - Tune build time of #2076 (#2088)
- Add
matplotlib.plot_parallel_coordinateexample (#2097, thanks @nzw0301!) - Add
matplotlib.plot_param_importancesexample (#2098, thanks @nzw0301!) - Add
matplotlib.plot_sliceexample (#2099, thanks @nzw0301!) - Add
matplotlib.plot_contourexample (#2100, thanks @nzw0301!) - Bump Sphinx up to 3.4.0 (#2127)
- Additional docs about
optuna.multi_objectivedeprecation (#2132) - Move type hints to description from signature (#2147)
- Add copy button to all the code examples (#2148)
- Fix wrong wording in distributed execution tutorial (#2152)
Examples
- Add MXNet Gluon example (#1985)
- Update logging in PyTorch Lightning example (#2037, thanks @pbmstrk!)
- Change return type of
training_stepof PyTorch Lightning example (#2043) - Fix dead links in
examples/README.md(#2056, thanks @nai62!) - Add
enqueue_trialexample (#2059) - Skip FastAI v2 example in examples job (#2108)
- Move
examples/multi_objective/plot_pareto_front.pytoexamples/visualization/plot_pareto_front.py(#2122) - Use latest multi-objective functionality in multi-objective example (#2123)
- Add haiku and jax simple example (#2155, thanks @nzw0301!)
Tests
- Update
parametrize_sampleroftest_samplers.py(#2020, thanks @norihitoishida!) - Change
trail_id + 123->trial_id(#2052) - Fix
scipy==1.6.0test failure withLogisticRegression(#2166)
Code Fixes
- Introduce plotly directive (#1944, thanks @harupy!)
- Stop storing error stack traces in
fail_reasonin trialsystem_attr(#1964) - Check everything by blackdoc (#1982)
- HPI with
_SearchSpaceTransform(#1988) - Fix TODO comment about orders of
dicts (#2007) - Add
__all__to reexport modules explicitly (#2013) - Update
CmaEsSampler's warning message (#2019, thanks @norihitoishida!) - Put up an alias for
structs.StudySummaryagainststudy.StudySummary(#2029) - Deprecate
optuna.type_checkingmodule (#2032) - Remove
py35from black config inpyproject.toml(#2035) - Use model methods instead of
session.query()(#2060) - Use
find_or_raise_by_idinstead offind_by_idto raise if a study does not exist (#2061) - Organize and remove unused model methods (#2062)
- Leave a comment about RTD compromise (#2066)
- Fix ideographic space (#2067, thanks @KoyamaSohei!)
- Make new visualization parameters keyword only (#2082)
- Use latest APIs in
LightGBMTuner(#2083) - Add
matplotlib.plot_sliceexample (#2099, thanks @nzw0301!) - Deprecate previous multi-objective module (#2124)
_run_trialrefactoring (#2133)- Cosmetic fix of
xgboostintegration (#2143)
Continuous Integration
- Partial support of python 3.9 (#1908)
- Check everything by blackdoc (#1982)
- Avoid
set-envin GitHub Actions (#1992) - PyTorch and AllenNLP (#1998)
- Remove
checksfrom circleci (#2004) - Migrate tests and coverage to GitHub Actions (#2027)
- Enable blackdoc
--diffoption (#2031) - Unpin mypy version (#2069)
- Skip FastAI v2 example in examples job (#2108)
- Fix CI examples for Py3.6 (#2129)
Other
- Add
tox.ini(#2024) - Allow passing additional arguments when running tox (#2054, thanks @harupy!)
- Add Python 3.9 to README badge (#2063)
- Clarify that generally pull requests need two or more approvals (#2104)
- Release wheel package via PyPI (#2105)
- Adds news entry about the Python 3.9 support (#2114)
- Add description for tox to
CONTRIBUTING.md(#2159) - Bump up version number to 2.4.0 (#2183)
- [Backport] Fix the syntax of
pypi-publish.yml(#2188)
Thanks to All the Contributors!
This release was made possible by authors, and everyone who participated in reviews and discussions.
@130ndim, @Crissman, @HideakiImamura, @KoyamaSohei, @akihironitta, @alexrobomind, @bigbird555, @c-bata, @crcrpar, @eytan, @g-votte, @hal-314, @harupy, @himkt, @hvy, @keisuke-umezawa, @nai62, @norihitoishida, @not522, @nyanhi, @nzw0301, @okdshin, @pbmstrk, @sdaulton, @sile, @toshihikoyanase, @trivialfis, @ytknzw, @ytsmiling
- Python
Published by hvy over 5 years ago
optuna - v2.3.0
This is the release note of v2.3.0.
Highlights
Multi-objective TPE sampler
TPE sampler now supports multi-objective optimization. This new algorithm is implemented in optuna.multi_objective and used viaoptuna.multi_objective.samplers.MOTPEMultiObjectiveSampler. See #1530 for the details.

LightGBMTunerCV returns the best booster
The best booster of LightGBMTunerCV can now be obtained in the same way as the LightGBMTuner. See #1609 and #1702 for details.
PyTorch Lightning v1.0 support
The integration with PyTorch Lightning v1.0 is available. The pruning feature of Optuna can be used with the new version of PyTorch Lightning using optuna.integration.PyTorchLightningPruningCallback. See #597 and #1926 for details.
RAPIDS + Optuna example
An example to illustrate how to use RAPIDS with Optuna is available. You can use this example to harness the computational power of the GPU along with Optuna.
New Features
- Introduce Multi-objective TPE to
optuna.multi_objective.samplers(#1530, thanks @y0z!) - Return
LGBMTunerCVbooster (#1702, thanks @nyanhi!) - Implement
plot_intermediate_valuesand_get_intermediate_plotwith Matplotlib backend (#1762, thanks @ytknzw!) - Implement
plot_optimization_historyand_get_optimization_history_plotwith Matplotlib backend (#1763, thanks @ytknzw!) - Implement
plot_parallel_coordinateand_get_parallel_coordinate_plotwith Matplotlib backend (#1764, thanks @ytknzw!) - Improve MLflow callback functionality: allow nesting, and attached study attrs (#1918, thanks @drobison00!)
Enhancements
- Copy datasets before objective evaluation (#1805)
- Fix 'Mean of empty slice' warning (#1927, thanks @carefree0910!)
- Add
reseed_rngtoNSGAIIMultiObjectiveSampler(#1938) - Add RDB support to
MoTPEMultiObjectiveSampler(#1978)
Bug Fixes
- Add some jitters in
_MultivariateParzenEstimators(#1923, thanks @kstoneriv3!) - Fix
plot_contour(#1929, thanks @carefree0910!) - Fix return type of the multivariate TPE samplers (#1955, thanks @nzw0301!)
- Fix
StudyDirectionofmapeinLightGBMTuner(#1966)
Documentation
- Add explanation for most module-level reference pages (#1850, thanks @tktran!)
- Revert module directives (#1873)
- Remove
with_tracemethod from docs (#1882, thanks @i-am-jeetu!) - Add CuPy to projects using Optuna (#1889)
- Add more sphinx doc comments (#1894, thanks @yuk1ty!)
- Fix a broken link in
matplotlib.plot_edf(#1899) - Fix broken links in
README.md(#1901) - Show module paths in
optuna.visualizationandoptuna.multi_objective.visualization(#1902) - Add a short description to the example in FAQ (#1903)
- Embed
plot_edffigure in documentation by using matplotlib plot directive (#1905, thanks @harupy!) - Fix plotly figure iframe paths (#1906, thanks @harupy!)
- Update docstring of
CmaEsSampler(#1909) - Add
matplotlib.plot_intermediate_valuesfigure to doc (#1933, thanks @harupy!) - Add
matplotlib.plot_optimization_historyfigure to doc (#1934, thanks @harupy!) - Make code example of
MOTPEMultiObjectiveSamplerexecutable (#1953) - Add
Raisescomments to samplers (#1965, thanks @yuk1ty!)
Examples
- Make src comments more descriptive in
examples/pytorch_lightning_simple.py(#1878, thanks @iamshnoo!) - Add an external project in Optuna examples (#1888, thanks @resnant!)
- Add RAPIDS + Optuna simple example (#1924, thanks @Nanthini10!)
- Apply follow-up of #1924 (#1960)
Tests
- Fix RDB test to avoid deadlock when creating study (#1919)
- Add a test to verify
nest_trialsforMLflowCallbackworks properly (#1932, thanks @harupy!) - Add a test to verify
tag_study_user_attrsforMLflowCallbackworks properly (#1935, thanks @harupy!)
Code Fixes
- Fix typo (#1900)
- Refactor
Study.optimize(#1904) - Refactor
Study.trials_dataframe(#1907) - Add variable annotation to
optuna/logging.py(#1920, thanks @akihironitta!) - Fix duplicate stack traces (#1921, thanks @akihironitta!)
- Remove
_log_normal_cdf(#1922, thanks @kstoneriv3!) - Convert comment style type hints (#1950, thanks @akihironitta!)
- Align the usage of type hints and instantiation of dictionaries (#1956, thanks @akihironitta!)
Continuous Integration
- Run documentation build and doctest in GitHub Actions (#1891)
- Resolve conflict of
job-idof GitHub Actions workflows (#1898) - Pin
mypy==0.782(#1913) - Run
allennlp_jsonnet.pyon GitHub Actions (#1915) - Fix for PyTorch Lightning 1.0 (#1926)
- Check blackdoc in CI (#1958)
- Fix path for
store_artifactsstep indocumentCircleCI job (#1962, thanks @harupy!)
Other
- Fix how to check the format, coding style, and type hints (#1755)
- Fix typo (#1968, thanks @nzw0301!)
Thanks to All the Contributors!
This release was made possible by authors, and everyone who participated in reviews and discussions.
@Crissman, @HideakiImamura, @Nanthini10, @akihironitta, @c-bata, @carefree0910, @crcrpar, @drobison00, @harupy, @himkt, @hvy, @i-am-jeetu, @iamshnoo, @keisuke-umezawa, @kstoneriv3, @nyanhi, @nzw0301, @resnant, @sile, @smly, @tktran, @toshihikoyanase, @y0z, @ytknzw, @yuk1ty
- Python
Published by HideakiImamura over 5 years ago
optuna - v2.2.0
This is the release note of v2.2.0.
In this release, we drop support for Python 3.5. If you are using Python 3.5, please consider upgrading your Python environment to Python 3.6 or newer, or install older versions of Optuna.
Highlights
Multivariate TPE sampler
TPESampler is updated with an experimental option to enable multivariate sampling. This algorithm captures dependencies among hyperparameters better than the previous algorithm. See #1767 for more details.


Improved AllenNLP support
AllenNLPExecutor supports pruning. It is introduced in the official hyperparameter search guide by AllenNLP. Both AllenNLPExecutor and the guide were written by @himkt. See #1772.

New Features
- Create
optuna.visualization.matplotlib(#1756, thanks @ytknzw!) - Add multivariate TPE sampler (#1767, thanks @kstoneriv3!)
- Support
AllenNLPPruningCallbackforAllenNLPExecutor(#1772)
Enhancements
KerasPruningCallbackto warn when an evaluation metric does not exist (#1759, thanks @bigbird555!)- Implement
plot_edfand_get_edf_plotwith Matplotlib backend (#1760, thanks @ytknzw!) - Fix exception chaining all over the codebase (#1781, thanks @akihironitta!)
- Add metric alias of rmse for
LightGBMTuner(#1807, thanks @upura!) - Update PyTorch-Lighting minor version (#1813, thanks @nzw0301!)
- Improve
TensorBoardCallback(#1814, thanks @sfujiwara!) - Add metric alias for
LightGBMTuner(#1822, thanks @nyanhi!) - Introduce a new argument to plot all evaluation points by
optuna.multi_objective.visualization.plot_pareto_front(#1824, thanks @nzw0301!) - Add
reseed_rngtoRandomMultiobjectiveSampler(#1831, thanks @y0z!)
Bug Fixes
- Fix fANOVA for
IntLogUniformDistribution(#1788) - Fix
mypyin an environment where some dependencies are installed (#1804) - Fix
WFG._compute()(#1812, thanks @y0z!) - Fix contour plot error for categorical distributions (#1819, thanks @zchenry!)
- Store CMAES optimizer after splitting into substrings (#1833)
- Add maximize support on
CmaEsSampler(#1849) - Add
matplotlibdirectory tooptuna.visualization.__init__.py(#1867)
Installation
- Update
setup.pyto drop Python 3.5 support (#1818, thanks @harupy!) - Add Matplotlib to
setup.py(#1829, thanks @ytknzw!)
Documentation
- Fix
plot_pareto_frontpreview path (#1808) - Fix indents of the example of
multi_objective.visualization.plot_pareto_front(#1815, thanks @nzw0301!) - Hide
__init__from docs (#1820, thanks @upura!) - Explicitly omit Python 3.5 from
README.md(#1825) - Follow-up #1832: alphabetical naming and fixes (#1841)
- Mention
isortin the contribution guidelines (#1842) - Add news sections about introduction of
isort(#1843) - Add
visualization.matpltlibto docs (#1847) - Add sphinx doc comments regarding exceptions in the optimize method (#1857, thanks @yuk1ty!)
- Avoid global study in
Study.stoptestcode (#1861) - Fix documents of
visualization.is_available(#1869) - Improve
ThresholdPrunerexample (#1876, thanks @fsmosca!) - Add logging levels to
optuna.logging.set_verbosity(#1884, thanks @nzw0301!)
Examples
- Add XGBoost cross-validation example (#1836, thanks @sskarkhanis!)
- Minor code fix of XGBoost examples (#1844)
Code Fixes
- Add default implementation of
get_n_trials(#1568) - Introduce
isortto automatically sort import statements (#1695, thanks @harupy!) - Avoid using experimental decorator on
CmaEsSampler(#1777) - Remove
loggermember attributes fromPyCmaSamplerandCmaEsSampler(#1784) - Apply
blackdoc(#1817) - Remove TODO (#1821, thanks @sfujiwara!)
- Fix Redis example code (#1826)
- Apply
isorttovisualization/matplotlib/andmulti_objective/visualization(#1830) - Move away from
.scoringimports (#1864, thanks @norihitoishida!) - Add experimental decorator to
matplotlib.*(#1868)
Continuous Integration
- Disable
--cache-fromif trigger of docker image build isrelease(#1791) - Remove Python 3.5 from CI checks (#1810, thanks @harupy!)
- Update python version in docs (#1816, thanks @harupy!)
- Migrate
checksto GitHub Actions (#1838) - Add option
--diffto black (#1840)
Thanks to All the Contributors!
This release was made possible by authors, and everyone who participated in reviews and discussions.
@HideakiImamura, @akihironitta, @bigbird555, @c-bata, @crcrpar, @fsmosca, @g-votte, @harupy, @himkt, @hvy, @keisuke-umezawa, @kstoneriv3, @norihitoishida, @nyanhi, @nzw0301, @sfujiwara, @sile, @sskarkhanis, @toshihikoyanase, @upura, @y0z, @ytknzw, @yuk1ty, @zchenry
- Python
Published by toshihikoyanase over 5 years ago
optuna - v2.1.0
This is the release note of v2.1.0.
Optuna v2.1.0 will be the last version to support Python 3.5. See #1067.
Highlights
Allowing objective(study.best_trial)
FrozenTrial used to subclass object but now implements BaseTrial. It can be used in places where a Trial is expected, including user-defined objective functions.
Re-evaluating the objective functions with the best parameter configuration is now straight forward. See #1503 for more details.
python
study.optimize(objective, n_trials=100)
best_trial = study.best_trial
best_value = objective(best_trial) # Did not work prior to v2.1.0.
IPOP-CMA-ES Sampling Algorithm
CmaEsSampler comes with an experimental option to switch to IPOP-CMA-ES. This algorithm restarts the strategy with an increased population size after premature convergence, allowing a more explorative search. See #1548 for more details.

Comparing the new option with the previous CmaEsSampler and RandomSampler.
Optuna & MLFlow on Kubernetes Example
Optuna can be easily integrated with MLFlow on Kubernetes clusters. The example contained here is a great introduction to get you started with a few lines of commands. See #1464 for more details.
Providing Type Hinting to Applications
Type hint information is packaged following PEP 561. Users of Optuna can now run style checkers against the framework. Note that the applications which ignore missing imports may raise new type-check errors due to this change. See #1720 for more details.
Breaking Changes
Configuration files for AllenNLPExecutor may need to be updated. See #1544 for more details.
- Remove
allennlp.common.params.infer_and_castfrom AllenNLP integrations (#1544) - Deprecate
optuna.integration.KerasPruningCallback(#1670, thanks @VamshiTeja!) - Make Optuna PEP 561 Compliant (#1720, thanks @MarioIshac!)
New Features
- Add sampling functions to
FrozenTrial(#1503, thanks @nzw0301!) - Add modules to compute hypervolume (#1537)
- Add IPOP-CMA-ES support in
CmaEsSampler(#1548) - Implement skorch pruning callback (#1668)
Enhancements
- Make sampling from trunc-norm efficient in
TPESampler(#1562) - Add trials to cache when awaking
WAITINGtrials in_CachedStorage(#1570) - Add log in
create_new_studymethod of storage classes (#1629, thanks @tohmae!) - Add border to markers in contour plot (#1691, thanks @zchenry!)
- Implement hypervolume calculator for two-dimensional space (#1771)
Bug Fixes
- Avoid to sample the value which equals to upper bound (#1558)
- Exit thread after session is destroyed (#1676, thanks @KoyamaSohei!)
- Disable
feature_pre_filterinLightGBMTuner(#1774) - Fix fANOVA for
IntLogUniformDistribution(#1790)
Installation
- Add
packagingininstall_requires(#1551) - Fix failure of Keras integration due to TF2.3 (#1563)
- Install
fsspec<0.8.0for Python 3.5 (#1596) - Specify the version of
packagingto>= 20.0(#1599, thanks @Isa-rentacs!) - Install
lightgbm<3.0.0to circumvent error withfeature_pre_filter(#1773)
Documentation
- Fix link to the definition of
StudySummary(#1533, thanks @nzw0301!) - Update log format in docs (#1538)
- Integrate Sphinx Gallery to make tutorials easily downloadable (#1543)
- Add AllenNLP pruner to list of pruners in tutorial (#1545)
- Refine the help of
study-name(#1565, thanks @belldandyxtq!) - Simplify contribution guidelines by removing rule about PR title naming (#1567)
- Remove license section from
README.md(#1573) - Update key features (#1582)
- Simplify documentation of
BaseDistribution.single(#1593) - Add navigation links for contributors to
README.md(#1597) - Apply minor changes to
CONTRIBUTING.md(#1601) - Add list of projects using Optuna to
examples/README.md(#1605) - Add a news section to
README.md(#1606) - Avoid the latest stable
sphinx(#1613) - Add link to examples in tutorial (#1625)
- Add the description of default pruner (
MedianPruner) to the documentation (#1657, thanks @Chillee!) - Remove generated directories with
make clean(#1658) - Delete a useless auto generated directory (#1708)
- Divide a section for each integration repository (#1709)
- Add example to
optuna.study.create_study(#1711, thanks @Ruketa!) - Add example to
optuna.study.load_study(#1712, thanks @bigbird555!) - Fix broken doctest example code (#1713)
- Add some notes and usage example for the hypervolume computing module (#1715)
- Fix issue where doctests are not executed (#1723, thanks @harupy!)
- Add example to
optuna.study.Study.optimize(#1726, thanks @norihitoishida!) - Add target for doctest to
Makefile(#1732, thanks @harupy!) - Add example to
optuna.study.delete_study(#1741, thanks @norihitoishida!) - Add example to
optuna.study.get_all_study_summaries(#1742, thanks @norihitoishida!) - Add example to
optuna.study.Study.set_user_attr(#1744, thanks @norihitoishida!) - Add example to
optuna.study.Study.user_attrs(#1745, thanks @norihitoishida!) - Add example to
optuna.study.Study.get_trials(#1746, thanks @norihitoishida!) - Add example to
optuna.multi_objective.study.MultiObjectiveStudy.optimize(#1747, thanks @norihitoishida!) - Add explanation for
optuna.trial(#1748) - Add example to
optuna.multi_objective.study.create_study(#1749, thanks @norihitoishida!) - Add example to
optuna.multi_objective.study.load_study(#1750, thanks @norihitoishida!) - Add example to
optuna.study.Study.stop(#1752, thanks @Ruketa!) - Re-generate contour plot example with padding (#1758)
Examples
- Add an example of Kubernetes, PyTorchLightning, and MLflow (#1464)
- Create study before multiple workers are launched in Kubernetes MLflow example (#1536)
- Fix typo in
examples/kubernetes/mlflow/README.md(#1540) - Reduce search space for AllenNLP example (#1542)
- Introduce
plot_param_importancesin example (#1555) - Removing references to deprecated
optuna study optimizecommands from examples (#1566, thanks @ritvik1512!) - Add scripts to run
examples/kubernetes/*(#1584, thanks @VamshiTeja!) - Update Kubernetes example of "simple" to avoid potential errors (#1600, thanks @Nishikoh!)
- Implement
skorchpruning callback (#1668) - Add a
tf.kerasexample (#1681, thanks @sfujiwara!) - Update
examples/pytorch_simple.py(#1725, thanks @wangxin0716!) - Fix Binh and Korn function in MO example (#1757)
Tests
- Test
_CachedStorageintest_study.py(#1575) - Rename
tests/multi_objectiveastests/multi_objective_tests(#1586) - Do not use deprecated
pytorch_lightning.data_loaderdecorator (#1667) - Add test for hypervolume computation for solution sets with duplicate points (#1731)
Code Fixes
- Match the order of definition in
trial(#1528, thanks @nzw0301!) - Add type hints to storage (#1556)
- Add trials to cache when awaking
WAITINGtrials in_CachedStorage(#1570) - Use
packagingto check the library version (#1610, thanks @VamshiTeja!) - Fix import order of
packaging.version(#1623) - Refactor TPE's
sample_from_categorical_dist(#1630) - Fix error messages in
TPESampler(#1631, thanks @kstoneriv3!) - Add code comment about
n_ei_candidatesfor categorical parameters (#1637) - Add type hints into
optuna/integration/keras.py(#1642, thanks @airyou!) - Fix how to use
blackinCONTRIBUTING.md(#1646) 1- Add type hints intooptuna/cli.py(#1648, thanks @airyou!) - Add type hints into
optuna/dashboard.py,optuna/integration/__init__.py(#1653, thanks @airyou!) - Add type hints
optuna/integration/_lightgbm_tuner(#1655, thanks @upura!) - Fix LightGBM Tuner import code (#1659)
- Add type hints to
optuna/storages/__init__.py(#1661, thanks @akihironitta!) - Add type hints to
optuna/trial(#1662, thanks @upura!) - Enable flake8 E231 (#1663, thanks @harupy!)
- Add type hints to
optuna/testing(#1665, thanks @upura!) - Add type hints to
tests/storages_tests/rdb_tests(#1666, thanks @akihironitta!) - Add type hints to
optuna/samplers(#1673, thanks @akihironitta!) - Fix type hint of
optuna.samplers._random(#1678, thanks @nyanhi!) - Add type hints into
optuna/integration/mxnet.py(#1679, thanks @norihitoishida!) - Fix type hint of
optuna/pruners/_nop.py(#1680, thanks @Ruketa!) - Update Type Hints:
prunes/_percentile.pyandprunes/_median.py(#1682, thanks @ytknzw!) - Fix incorrect type annotations for
argsandkwargs(#1684, thanks @harupy!) - Update type hints in
optuna/pruners/_base.pyandoptuna/pruners/_successive_halving.py(#1685, thanks @ytknzw!) - Add type hints to
test_optimization_history.py(#1686, thanks @yosupo06!) - Fix type hint of
tests/pruners_tests/test_median.py(#1687, thanks @polyomino-24!) - Type hint and reformat of files under
visualization_tests(#1689, thanks @gasin!) - Remove unused argument
trialfromoptuna.samplers._tpe.sampler._get_observation_pairs(#1692, thanks @ytknzw!) - Add type hints into
optuna/integration/chainer.py(#1693, thanks @norihitoishida!) - Add type hints to
optuna/integration/tensorflow.py(#1698, thanks @uenoku!) - Add type hints into
optuna/integration/chainermn.py(#1699, thanks @norihitoishida!) - Add type hints to
optuna/integration/xgboost.py(#1700, thanks @Ruketa!) - Add type hints to files under
tests/integration_tests(#1701, thanks @gasin!) - Use
Optionalfor keyword arguments that default toNone(#1703, thanks @harupy!) - Fix type hint of all the rest files under
tests/(#1704, thanks @gasin!) - Fix type hint of
optuna/integration(#1705, thanks @akihironitta!) - Add l2 metric aliases to
LightGBMTuner(#1717, thanks @thigm85!) - Convert type comments in
optuna/study.pyinto type annotations (#1724, thanks @harupy!) - Apply
black==20.8b1(#1730) - Fix type hint of
optuna/integration/sklearn.py(#1735, thanks @akihironitta!) - Add type hints into
optuna/structs.py(#1743, thanks @norihitoishida!) - Fix typo in
optuna/samplers/_tpe/parzen_estimator.py(#1754, thanks @akihironitta!)
Continuous Integration
- Temporarily skip
allennlp_jsonnet.pyexample in CI (#1527) - Run TensorFlow on Python 3.8 (#1564)
- Bump PyTorch to 1.6 (#1572)
- Skip entire
allennlpexample directory in CI (#1585) - Use
actions/setup-python@v2(#1594) - Add
cacheto GitHub Actions Workflows (#1595) - Run example after docker build to ensure that built image is setup properly (#1635, thanks @harupy!)
- Use cache-from to build docker image faster (#1638, thanks @harupy!)
- Fix issue where doctests are not executed (#1723, thanks @harupy!)
Other
- Remove Swig installation from Dockerfile (#1462)
- Add: How to run examples with our Docker images (#1554)
- GitHub Action labeler (#1591)
- Do not trigger labeler on push (#1624)
- Fix invalid YAML syntax (#1626)
- Pin
sphinxversion to3.0.4(#1627, thanks @harupy!) - Add
.dockerignore(#1633, thanks @harupy!) - Fix how to use
blackinCONTRIBUTING.md(#1646) - Add
pyproject.tomlfor easier use of black (#1649) - Fix
docs/Makefile(#1650) - Ignore vscode configs (#1660)
- Make Optuna PEP 561 Compliant (#1720, thanks @MarioIshac!)
- Python
Published by HideakiImamura almost 6 years ago
optuna - v2.0.0
This is the release note of v2.0.0.
Highlights
The second major version of Optuna 2.0 is released. It accommodates a multitude of new features, including Hyperband pruning, hyperparameter importance, built-in CMA-ES support, grid sampler, and LightGBM integration. Storage access is also improved, significantly speeding up optimization. Documentation has been revised and navigation is made easier. See the blog for details.
Hyperband Pruner
The stable version of HyperbandPruner is available with a simpler interface and improved performance.

Hyperparameter Importance
The stable version of the hyperparameter importance module is available.
- Our implementation of fANOVA, FanovaImportanceEvaluator is now the default importance evaluator. This replaces the previous requirement for fanova with scikit-learn.
- A new importance visualization function visualization.plot_param_importances.

Built-in CMA-ES Sampler
The stable version of CmaEsSampler is available. This new CmaEsSampler can be used with pruning for major performance improvements.
Grid Sampler
The stable version of GridSampler is available through an intuitive interface for users familiar with Optuna. When the entire grid is exhausted, the optimization stops automatically, so you can specify n_trials=None.
LightGBM Tuner
The stable version of LightGBMTuner is available. The behavior regarding verbosity option has been improved. The random seed was fixed unexpectedly if the verbosity level is not zero, but now the user given seed is used correctly.
Experimental Features
- New integration modules: TensorBoard integration, Catalyst integration, and AllenNLP pruning integration are available as experimental.
- A new visualization function for multi-objective optimization:
multi_objective.visualization.plot_pareto_frontis available as an experimental feature. - New methods to manually create/add trials:
trial.create_trialandstudy.Study.add_trialare available as experimental features.
Breaking Changes
Several deprecated features (e.g., Study.study_id and Trial.trial_id) are removed. See #1346 for details.
- Remove deprecated features in
optuna.trial(#1371) - Remove deprecated arguments from
LightGBMTuner(#1374) - Remove deprecated features in
integration/chainermn.py(#1375) - Remove deprecated features in
optuna/structs.py(#1377) - Remove deprecated features in
optuna/study.py(#1379)
Several features are deprecated.
- Deprecate
optuna study optimizecommand (#1384) - Deprecate
stepargument inIntLogUniformDistribution(#1387, thanks @nzw0301!)
Other.
BaseStorage.set_trial_paramto returnNoneinstead ofbool(#1327)- Match
suggest_floatandsuggest_intspecifications onstepandlogarguments (#1329) BaseStorage.set_trial_intermediate_valuteto returnNoneinstead ofbool(#1337)- Make
optuna.integration.lightgbm_tunerprivate (#1378) - Fix pruner index handling to 0-indexing (#1430, thanks @bigbird555!)
- Continue to allow using
IntLogUnioformDistribution.stepduring deprecation (#1438) - Align
LightGBMTunerverbosity level to the original LightGBM (#1504)
New Features
- Add snippet of API for integration with Catalyst (#1056, thanks @VladSkripniuk!)
- Add pruned trials to trials being considered in
CmaEsSampler(#1229) - Add pruned trials to trials being considered in
SkoptSampler(#1431) - Add TensorBoard integration (#1244, thanks @VladSkripniuk!)
- Add deprecation decorator (#1382)
- Add
plot_pareto_frontfunction (#1303) - Remove experimental decorator from
HyperbandPruner(#1435) - Remove experimental decorators from hyperparameter importance (HPI) features (#1440)
- Remove experimental decorator from
Study.stop(#1450) - Remove experimental decorator from
GridSampler(#1451) - Remove experimental decorators from
LightGBMTuner(#1452) - Introducing
optuna.visualization.plot_param_importances(#1299) - Rename
integration/CmaEsSamplertointegration/PyCmaSampler(#1325) - Match
suggest_floatandsuggest_intspecifications onstepandlogarguments (#1329) optuna.create_trialandStudy.add_trialto create custom studies (#1335)- Allow omitting the removal version in
deprecated(#1418) - Mark
CatalystPruningCallbackintegration as experimental (#1465) - Followup TensorBoard integration (#1475)
- Implement a pruning callback for AllenNLP (#1399)
- Remove experimental decorator from HPI visualization (#1477)
- Add
optuna.visualization.plot_edffunction (#1482) FanovaImportanceEvaluatoras default importance evaluator (#1491)- Reduce HPI variance with default args (#1492)
Enhancements
- Support automatic stop of
GridSampler(#1026) - Implement fANOVA using
sklearninstead offanova(#1106) - Add a caching mechanism to make
NSGAIIMultiObjectiveSamplerfaster (#1257) - Add
logargument support forsuggest_intof skopt integration (#1277, thanks @nzw0301!) - Add
read_trials_from_remote_storagemethod to Storage implementations (#1298) - Implement
logargument forsuggest_intof pycma integration (#1302) - Raise
ImportErrorifbokehversion is 2.0.0 or newer (#1326) - Fix the x-axis title of the hyperparameter importances plot (#1336, thanks @harupy!)
BaseStorage.set_trial_intermediate_valuteto returnNoneinstead ofbool(#1337)- Simplify log messages (#1345)
- Improve layout of
plot_param_importancesfigure (#1355) - Do not run the GC after every trial by default (#1380)
- Skip storage access if logging is disabled (#1403)
- Specify
stacklevelforwarnings.warnfor more helpful warning message (#1419, thanks @harupy!) - Replace
DeprecationWarningwithFutureWarningin@deprecated(#1428) - Fix pruner index handling to 0-indexing (#1430, thanks @bigbird555!)
- Load environment variables in
AllenNLPExecutor(#1449) - Stop overwriting seed in
LightGBMTuner(#1461) - Suppress progress bar of
LightGBMTunerifverbosity== 1 (#1460) - RDB storage to do eager backref "join"s when fetching all trials (#1501)
- Overwrite intermediate values correctly (#1517)
- Overwrite parameters correctly (#1518)
- Always cast choices into tuple in
CategoricalDistribution(#1520)
Bug Fixes
RDB Storage Bugs on Distributed Optimization are Fixed
Several critical bugs are addressed in this release with the RDB storage, most related to distributed optimization.
- Fix CMA-ES boundary constraints and initial mean vector of LogUniformDistribution (#1243)
- Temporary hotfix for
sphinxupdate breaking existing type annotations (#1342) - Fix for PyTorch Lightning v0.8.0 (#1392)
- Fix exception handling in
ChainerMNStudy.optimize(#1406) - Use
stepto calculate range ofIntUniformDistributioninPyCmaSampler(#1456) - Avoid exploding queries with large exclusion sets (#1467)
- Temporary fix for problem with length limit of 5000 in MLflow (#1481, thanks @PhilipMay!)
- Fix race condition for trial number computation (#1490)
- Fix
CachedStorageskipping trial param row insertion on cache miss (#1498) - Fix
_CachedStorageandRDBStoragedistribution compatibility check race condition (#1506) - Fix frequent deadlock caused by conditional locks (#1514)
Installation
- [Backport] Add
packagingin install_requires (#1561) - Set
python_requiresinsetup.pyto clarify supported Python version (#1350, thanks @harupy!) - Specify
classifiersin setup.py (#1358) - Hotfix to avoid latest
keras2.4.0 (#1386) - Hotfix to avoid PyTorch Lightning 0.8.0 (#1391)
- Relax
sphinxversion (#1393) - Update version constraints of
cmaes(#1404) - Align
sphinx-rtd-themeand Python versions used on Read the Docs to CircleCI (#1434, thanks @harupy!) - Remove checking and alerting installation
pfnopt(#1474) - Avoid latest
sphinx(#1485) - Add
packagingin install_requires (#1561)
Documentation
- Fix experimental decorator (#1248, thanks @harupy!)
- Create a documentation for the root namespace
optuna(#1278) - Add missing documentation for
BaseStorage.set_trial_param(#1316) - Fix documented exception type in
BaseStorage.get_best_trialand add unit tests (#1317) - Add hyperlinks to key features (#1331)
- Add
.readthedocs.ymlto use the same document dependencies on the CI and Read the Docs (#1354, thanks @harupy!) - Use
Colabto demonstrate a notebook instead ofnbviewer(#1360) - Hotfix to allow building the docs by avoiding latest
sphinx(#1369) - Update layout and color of docs (#1370)
- Add FAQ section about OOM (#1385)
- Rename a title of reference to a module name (#1390)
- Add a list of functions and classes for each module in reference doc (#1400)
- Use
.. warning::instead of.. note::for the deprecation decorator (#1407) - Always use Sphinx RTD theme (#1414)
- Fix color of version/build in documentation sidebar (#1415)
- Use a different font color for argument names (#1436, thanks @harupy!)
- Move css from
_templates/footer.htmlto_static/css/custom.css(#1439) - Add missing commas in FAQ (#1458)
- Apply auto-formatting to
custom.cssto make it pretty and consistent (#1463, thanks @harupy!) - Update
CONTRIBUTING.md(#1466) - Add missing
CatalystPruningCallbackin the documentation (#1468, thanks @harupy!) - Fix incorrect type annotations for
catch(#1473, thanks @harupy!) - Fix double
FrozenTrial(#1478) - Wider main content container in the documentation (#1483)
- Add
TensorBoardCallbackto docs (#1486) - Add description about zero-based numbering of
step(#1489) - Add links to examples from the integration references (#1507)
- Fix broken link in
plot_edf(#1510) - Update docs of default importance evaluator (#1524)
Examples
- Set
timeoutfor relatively long-running examples (#1349) - Fix broken link to example and add README for AllenNLP examples (#1397)
- Add whitespace before opening parenthesis (#1398)
- Fix GPU run for PyTorch Ignite and Lightning examples (#1444, thanks @arisliang!)
- Add Stable-Baselines3 RL Example (#1420, thanks @araffin!)
- Replace
suggest_*uniformin examples withsuggest_(int|float)(#1470)
Tests
- Fix
plot_param_importancestest (#1328) - Fix incorrect test names in
test_experimental.py(#1332, thanks @harupy!) - Simplify decorator tests (#1423)
- Add a test for
CmaEsSampler._get_trials()(#1433) - Use argument of
pytorch_lightning.Trainerto disablecheckpoint_callback(#1453) - Install RDB servers and their bindings for storage tests (#1497)
- Upgrade versions of
pytorchandtorchvision(#1502) - Make HPI tests deterministic (#1505)
Code Fixes
- Introduces
optuna._imports.try_importto DRY optional imports (#1315) - Friendlier error message for unsupported
plotlyversions (#1338) - Rename private modules in
optuna.visualization(#1359) - Rename private modules in
optuna.pruners(#1361) - Rename private modules in
optuna.samplers(#1362) - Change
loggerto_trial's module variable (#1363) - Remove deprecated features in
HyperbandPruner(#1366) - Add missing
__init__.pyfiles (#1367, thanks @harupy!) - Fix double quotes from Black formatting (#1372)
- Rename private modules in
optuna.storages(#1373) - Add a list of functions and classes for each module in reference doc (#1400)
- Apply deprecation decorator (#1413)
- Remove unnecessary exception handling for
GridSampler(#1416) - Remove either
warnings.warn()oroptuna.logging.Logger.warning()from codes which have both of them (#1421) - Simplify usage of
deprecatedby omitting removed version (#1422) - Apply experimental decorator (#1424)
- Fix the experimental warning message for
CmaEsSampler(#1432) - Remove
optuna.structsfrom MLflow integration (#1437) - Add type hints to
slice.py(#1267, thanks @bigbird555!) - Add type hints to
intermediate_values.py(#1268, thanks @bigbird555!) - Add type hints to
optimization_history.py(#1269, thanks @bigbird555!) - Add type hints to
utils.py(#1270, thanks @bigbird555!) - Add type hints to
test_logging.py(#1284, thanks @bigbird555!) - Add type hints to
test_chainer.py(#1286, thanks @bigbird555!) - Add type hints to
test_keras.py(#1287, thanks @bigbird555!) - Add type hints to
test_cma.py(#1288, thanks @bigbird555!) - Add type hints to
test_fastai.py(#1289, thanks @bigbird555!) - Add type hints to
test_integration.py(#1293, thanks @bigbird555!) - Add type hints to
test_mlflow.py(#1322, thanks @bigbird555!) - Add type hints to
test_mxnet.py(#1323, thanks @bigbird555!) - Add type hints to
optimize.py(#1364, thanks @bigbird555!) - Replace
suggest_*uniformin examples withsuggest_(int|float)(#1470) - Add type hints to
distributions.py(#1513) - Remove unnecessary
FloatingPointDistributionType(#1516)
Continuous Integration
- Add a step to push images to Docker Hub (#1295)
- Check code coverage in
tests-python37on CircleCI (#1348) - Stop building Docker images in Pull Requests (#1389)
- Prevent
doc-linkfrom running on unrelated status update events (#1410, thanks @harupy!) - Avoid latest
ConfigSpacewhere Python 3.5 is dropped (#1471) - Run unit tests on GitHub Actions (#1352)
- Use
circleci/pythonfor dev image and install RDB servers (#1495) - Install RDB servers and their bindings for storage tests (#1497)
- Fix
dockerimage.ymlformat (#1511) - Revert #1495 and #1511 (#1512)
- Run daily unit tests (#1515)
Other
- Add TestPyPI release to workflow (#1291)
- Add PyPI release to workflow (#1306)
- Exempt issues with
no-stalelabel from stale bot (#1321) - Remove stale labels from Issues or PRs when they are updated or commented on (#1409)
- Exempt PRs with
no-stalelabel from stale bot (#1427) - Update the documentation section in
CONTRIBUTING.md(#1469, thanks @harupy!) - Bump up version to
2.0.0(#1525)
- Python
Published by hvy almost 6 years ago
optuna - v2.0.0-rc0
A release candidate for the second major version of Optuna v2.0.0-rc0 is released! This release includes a lot of new features, cleaned up interfaces, performance improvements, internal refactorings and more. If you find any problems with this release candidate, please feel free to report them via GitHub Issues or Gitter.
Highlights
Hyperband Pruner
The stable version of HyperbandPruner is available. It has a more simple interface and has seen performance improvement.
Hyperparameter Importance
The stable version of the hyperparameter importance module is available.
- Our own implemented fANOVA, FanovaImportanceEvaluator. While the previous implementation required fanova, this new FanovaImportanceEvaluator can be used with only scikit-learn.
- A new importance visualization function visualization.plot_param_importances.
Built-in CMA-ES Sampler
The stable version of CmaEsSampler is available. This new CmaEsSampler can be used with pruning, one of the Optuna’s important features, for great performance improvements.
Grid Sampler
The stable version of GridSampler is available and can be through an intuitive interface for users familiar with Optuna. When the entire grid is exhausted, the optimization also automatically stops so you can specify n_trials=None.
LightGBM Tuner
The stable version of LightGBMTuner is available. The behavior regarding verbosity option has been improved. The random seed was fixed unexpectedly if the verbosity level is not 0, but now the user given seed is used correctly.
Experimental Features
- New integration modules: TensorBoard integration and Catalyst integration are available as experimental.
- A new visualization function for multi-objective optimization:
multi_objective.visualization.plot_pareto_frontis available as an experimental feature. - New methods to manually create/add trials:
trial.create_trialandstudy.Study.add_trialare available as experimental features.
Breaking Changes
Several deprecated features (e.g., Study.study_id and Trial.trial_id) are removed. See #1346 for details.
- Remove deprecated features in
optuna.trial. (#1371) - Remove deprecated arguments from
LightGBMTuner. (#1374) - Remove deprecated features in
integration/chainermn.py. (#1375) - Remove deprecated features in
optuna/structs.py. (#1377) - Remove deprecated features in
optuna/study.py. (#1379)
Several features are deprecated.
- Deprecate
optuna study optimizecommand. (#1384) - Deprecate
stepargument inIntLogUniformDistribution. (#1387, thanks @nzw0301!)
Other.
BaseStorage.set_trial_paramto returnNoneinstead ofbool. (#1327)- Match
suggest_floatandsuggest_intspecifications onstepandlogarguments. (#1329) BaseStorage.set_trial_intermediate_valuteto returnNoneinstead ofbool. (#1337)- Make
optuna.integration.lightgbm_tunerprivate. (#1378) - Fix pruner index handling to 0-indexing. (#1430, thanks @bigbird555!)
- Continue to allow using
IntLogUnioformDistribution.stepduring deprecation. (#1438)
New Features
- Add snippet of API for integration with Catalyst. (#1056, thanks @VladSkripniuk!)
- Add pruned trials to trials being considered in
CmaEsSampler. (#1229) - Add pruned trials to trials being considered in
SkoptSampler. (#1431) - Add TensorBoard integration. (#1244, thanks @VladSkripniuk!)
- Add deprecation decorator. (#1382)
- Add
plot_pareto_frontfunction. (#1303) - Remove experimental decorator from
HyperbandPruner. (#1435) - Remove experimental decorators from hyperparameter importance (HPI) features. (#1440)
- Remove experimental decorator from
Study.stop. (#1450) - Remove experimental decorator from
GridSampler. (#1451) - Remove experimental decorators from
LightGBMTuner. (#1452) - Introducing
optuna.visualization.plot_param_importances. (#1299) - Rename
integration/CmaEsSamplertointegration/PyCmaSampler. (#1325) - Match
suggest_floatandsuggest_intspecifications onstepandlogarguments. (#1329) optuna.create_trialandStudy.add_trialto create custom studies. (#1335)- Allow omitting the removal version in
deprecated. (#1418) - Mark
CatalystPruningCallbackintegration as experimental. (#1465) - Followup TensorBoard integration. (#1475)
Enhancements
- Support automatic stop of
GridSampler. (#1026) - Implement fANOVA using
sklearninstead offanova. (#1106) - Add a caching mechanism to make
NSGAIIMultiObjectiveSamplerfaster. (#1257) - Add
logargument support forsuggest_intof skopt integration. (#1277, thanks @nzw0301!) - Add
read_trials_from_remote_storagemethod to Storage implementations. (#1298) - Implement
logargument forsuggest_intof pycma integration. (#1302) - Raise
ImportErrorifbokehversion is 2.0.0 or newer. (#1326) - Fix the x-axis title of the hyperparameter importances plot. (#1336, thanks @harupy!)
BaseStorage.set_trial_intermediate_valuteto returnNoneinstead ofbool. (#1337)- Simplify log messages. (#1345)
- Improve layout of
plot_param_importancesfigure. (#1355) - Do not run the GC after every trial by default. (#1380)
- Skip storage access if logging is disabled. (#1403)
- Specify
stacklevelforwarnings.warnfor more helpful warning message. (#1419, thanks @harupy!) - Replace
DeprecationWarningwithFutureWarningin@deprecated. (#1428) - Fix pruner index handling to 0-indexing. (#1430, thanks @bigbird555!)
- Load environment variables in
AllenNLPExecutor. (#1449) - Stop overwriting seed in
LightGBMTuner. (#1461)
Bug Fixes
- Fix CMA-ES boundary constraints and initial mean vector of LogUniformDistribution. (#1243)
- Temporary hotfix for
sphinxupdate breaking existing type annotations. (#1342) - Fix for PyTorch Lightning v0.8.0. (#1392)
- Fix exception handling in
ChainerMNStudy.optimize. (#1406) - Use
stepto calculate range ofIntUniformDistributioninPyCmaSampler. (#1456)
Installation
- Set
python_requiresinsetup.pyto clarify supported Python version. (#1350, thanks @harupy!) - Specify
classifiersin setup.py. (#1358) - Hotfix to avoid latest
keras2.4.0. (#1386) - Hotfix to avoid PyTorch Lightning 0.8.0. (#1391)
- Relax
sphinxversion. (#1393) - Update version constraints of
cmaes. (#1404) - Align
sphinx-rtd-themeand Python versions used on Read the Docs to CircleCI. (#1434, thanks @harupy!) - Remove checking and alerting installation
pfnopt. (#1474)
Documentation
- Fix experimental decorator. (#1248, thanks @harupy!)
- Create a documentation for the root namespace
optuna. (#1278) - Add missing documentation for
BaseStorage.set_trial_param. (#1316) - Fix documented exception type in
BaseStorage.get_best_trialand add unit tests. (#1317) - Add hyperlinks to key features. (#1331)
- Add
.readthedocs.ymlto use the same document dependencies on the CI and Read the Docs. (#1354, thanks @harupy!) - Use
Colabto demonstrate a notebook instead ofnbviewer. (#1360) - Hotfix to allow building the docs by avoiding latest
sphinx. (#1369) - Update layout and color of docs. (#1370)
- Add FAQ section about OOM. (#1385)
- Rename a title of reference to a module name. (#1390)
- Add a list of functions and classes for each module in reference doc. (#1400)
- Use
.. warning::instead of.. note::for the deprecation decorator. (#1407) - Always use Sphinx RTD theme. (#1414)
- Fix color of version/build in documentation sidebar. (#1415)
- Use a different font color for argument names. (#1436, thanks @harupy!)
- Move css from
_templates/footer.htmlto_static/css/custom.css. (#1439) - Add missing commas in FAQ. (#1458)
- Apply auto-formatting to
custom.cssto make it pretty and consistent. (#1463, thanks @harupy!) - Update
CONTRIBUTING.md. (#1466) - Add missing
CatalystPruningCallbackin the documentation. (#1468, thanks @harupy!) - Fix incorrect type annotations for
catch. (#1473, thanks @harupy!)
Examples
- Set
timeoutfor relatively long-running examples. (#1349) - Fix broken link to example and add README for AllenNLP examples. (#1397)
- Add whitespace before opening parenthesis. (#1398)
- Fix GPU run for PyTorch Ignite and Lightning examples. (#1444, thanks @arisliang!)
Tests
- Fix
plot_param_importancestest. (#1328) - Fix incorrect test names in
test_experimental.py. (#1332, thanks @harupy!) - Simplify decorator tests. (#1423)
- Add a test for
CmaEsSampler._get_trials(). (#1433) - Use argument of
pytorch_lightning.Trainerto disablecheckpoint_callback. (#1453)
Code Fixes
- Introduces
optuna._imports.try_importto DRY optional imports. (#1315) - Friendlier error message for unsupported
plotlyversions. (#1338) - Rename private modules in
optuna.visualization. (#1359) - Rename private modules in
optuna.pruners. (#1361) - Rename private modules in
optuna.samplers. (#1362) - Change
loggerto_trial's module variable. (#1363) - Remove deprecated features in
HyperbandPruner. (#1366) - Add missing
__init__.pyfiles. (#1367, thanks @harupy!) - Fix double quotes from Black formatting. (#1372)
- Rename private modules in
optuna.storages. (#1373) - Add a list of functions and classes for each module in reference doc. (#1400)
- Apply deprecation decorator. (#1413)
- Remove unnecessary exception handling for
GridSampler. (#1416) - Remove either
warnings.warn()oroptuna.logging.Logger.warning()from codes which have both of them. (#1421) - Simplify usage of
deprecatedby omitting removed version. (#1422) - Apply experimental decorator. (#1424)
- Fix the experimental warning message for
CmaEsSampler. (#1432) - Remove
optuna.structsfrom MLflow integration. (#1437) - Add type hints to
slice.py. (#1267, thanks @bigbird555!) - Add type hints to
intermediate_values.py. (#1268, thanks @bigbird555!) - Add type hints to
optimization_history.py. (#1269, thanks @bigbird555!) - Add type hints to
utils.py. (#1270, thanks @bigbird555!) - Add type hints to
test_logging.py. (#1284, thanks @bigbird555!) - Add type hints to
test_chainer.py. (#1286, thanks @bigbird555!) - Add type hints to
test_keras.py. (#1287, thanks @bigbird555!) - Add type hints to
test_cma.py. (#1288, thanks @bigbird555!) - Add type hints to
test_fastai.py. (#1289, thanks @bigbird555!) - Add type hints to
test_integration.py. (#1293, thanks @bigbird555!) - Add type hints to
test_mlflow.py. (#1322, thanks @bigbird555!) - Add type hints to
test_mxnet.py. (#1323, thanks @bigbird555!) - Add type hints to
optimize.py. (#1364, thanks @bigbird555!)
Continuous Integration
- Add a step to push images to Docker Hub. (#1295)
- Check code coverage in
tests-python37on CircleCI. (#1348) - Stop building Docker images in Pull Requests. (#1389)
- Prevent
doc-linkfrom running on unrelated status update events. (#1410, thanks @harupy!) - Avoid latest
ConfigSpacewhere Python 3.5 is dropped. (#1471)
Other
- Add TestPyPI release to workflow. (#1291)
- Add PyPI release to workflow. (#1306)
- Exempt issues with
no-stalelabel from stale bot. (#1321) - Remove stale labels from Issues or PRs when they are updated or commented on. (#1409)
- Exempt PRs with
no-stalelabel from stale bot. (#1427)
- Python
Published by hvy almost 6 years ago
optuna - v1.5.0
This is the release note of v1.5.0.
Highlights
LightGBM Tuner with Cross-validation
LightGBM tuner, which provides efficient stepwise parameter tuning for LightGBM, supports cross-validation as an experimental feature with LightGBMTunerCV. See #1156 for details.

NSGA-II
A sampler based on NSGA-II, a well-known multi-objective optimization algorithm, is now available as the default multi-objective sampler. The following benchmark result, on the ZDT1 function, shows that NSGA-II outperforms random sampling. Please refer to #1163 for further details.

Mean Decrease Impurity (MDI) Hyperparameter Importance Evaluator
The default hyperparameter importance evaluator is replaced with a naive mean decrease impurity algorithm. It uses the random forest feature importances in Scikit-learn and therefore requires this package. See #1253 for more details.

optuna.TrialPruned Alias
optuna.TrialPruned is a new alias for optuna.exceptions.TrialPruned. It is now possible to write shorter and more readable code when pruning trials. See #1204 for details.
New Features
- Add a method to stop
study.optimize. (#1025) - Use
--study-nameinstead of--studyin CLI commands. (#1079, thanks @seungjaeryanlee!) - Add cross-validation support for
LightGBMTuner. (#1156) - Add NSGA-II based multi-objective sampler. (#1163)
- Implement log argument for
suggest_int. (#1201, thanks @nzw0301!) - Import
optuna.exceptions.TrialPrunedin__init__.py. (#1204) - Mean Decrease Impurity (MDI) hyperparameter importance evaluator. (#1253)
Enhancements
- Add storage cache. (#1140)
- Fix
_get_observation_pairsfor conditional parameters. (#1166, thanks @y0z!) - Alternative implementation to hide the interface so that all samplers can use
HyperbandPruner. (#1196) - Fix for O(N) queries being produced if even a single trial is cached. (#1259, thanks @zzorba!)
- Move caching mechanism from
RDBStorageto_CachedStorage. (#1263) - Cache study-related info in
_CachedStorage. (#1264) - Move deep-copies for optimization speed improvement. (#1274)
- Implement
logargument forsuggest_intof ChainerMN integration. (#1275, thanks @nzw0301!) - Add warning when
Trial.suggest_intmodifieshigh. (#1276) - Input validation for
IntLogUniformDistribution. (#1279, thanks @himkt!)
Bug Fixes
- Support multiple studies in
InMemoryStorage. (#1228) - Fix out of bounds error of CMA-ES. (#1231)
- Fix
sklearn-skoptversion incompatibility. (#1236) - Fix a type casting error when using
CmaEsSampler. (#1240) - Upgrade the version of
cmaes. (#1242)
Documentation
- Rename
test_tovalid_in docs and docstring. (#1167, thanks @himkt!) - Add storage specification to
BaseStorageclass doc. (#1174) - Add docstring to
BaseStoragemethod interfaces. (#1175) - Add an explanation of failed trials from samplers' perspective. (#1214)
- Add
LightGBMTunerreference. (#1217) - Modifying code examples to include training data. (#1221)
- Ask optuna tag in Stack Overflow question. (#1249)
- Add notes for
autoargument values inHyperbandPrunerandSuccessiveHalvingPruner. (#1252) - Add description of
observation_keyinXGBoostPruningCallback. (#1260) - Cosmetic fixes to documentation in
BaseStorage. (#1261) - Modify documentation and fix file extension in the test for AllenNLP integration. (#1265, thanks @himkt!)
- Fix
experimentaldecorator to decorate a class properly. (#1285, thanks @harupy!)
Examples
- Add pruning to PyTorch example. (#1119)
- Use
dump_best_configin example. (#1225, thanks @himkt!) - Stop suggesting using deprecated option in AllenNLP example. (#1282)
- Add link to regression example in the header of
keras_integration.py. (#1301, thanks @zishiwu123!)
Tests
- Increase test coverage of storage tests for single worker cases. (#1191)
- Fix
sklearn-skoptversion incompatibility. (#1236)
Code Fixes
- Dissect
trial.py. (#1210, thanks @himkt!) - Rename
trial/*.pytotrial/_*.py. (#1239) - Add type hints to contour.py. (#1254, thanks @bigbird555!)
- Consistent Hyperband bracket ID variable names. (#1262)
- Apply minor code fix to #1201. (#1273)
- Avoid mutable default argument in
AllenNLPExecutor.__init__. (#1280) - Reorder arguments of
Trial.suggest_float. (#1292) - Fix unintended change on calculating
n_bracketsinHyperbandPruner. (#1294) - Add experimental decorator to
LightGBMTunerandLightGBMTunerCV. (#1305)
Continuous Integration
- Add GitHub action that posts link to documentation. (#1247, thanks @harupy!)
- Add a workflow to create distribution packages. (#1283)
- Stop setting environment variables for GitHub Package. (#1296)
- Python
Published by hvy about 6 years ago
optuna - v1.4.0
This is the release note of v1.4.0.
Highlights
Experimental Multi-objective Optimization
Multi-objective optimization is available as an experimental feature. Currently, it only provides random sampling, but it will be continuously developed in the following releases. Feedback is highly welcomed. See #1054 for details.
Enhancement of Storages
A new Redis-based storage is available. It is a fast and flexible in-memory storage. It can also persist studies on-disk without having to configure relational databases. It is still an experimental feature, and your feedback is highly welcomed. See #974 for details.
Performance tuning has been applied to RDBStorage. For instance, it speeds up creating study lists by over 3000 times (i.e., 7 minutes to 0.13 seconds). See #1109 for details.
Experimental Integration Modules for MLFlow and AllenNLP
A new callback function is provided for MLFlow users. It reports Optuna’s optimization results (i.e., parameter values and metric values) to MLFlow. See #1028 for details.
A new integration module for AllenNLP is available. It enables you to reuse your jsonnet configuration files for hyperparameter tuning. See #1086 for details.
Breaking Changes
- Delete the argument
is_higher_betterfromTensorFlowPruningHook. (#1083, thanks @nuka137!) - Applied
@abc.abstractmethoddecorator to the abstract methods ofBaseTrialand fixedChainerMNTrial. (#1087, thanks @gorogoroumaru!) - Input validation for
LogUniformDistributionfor negative domains. (#1099)
New Features
- Added
RedisStorageclass to support storing activity on Redis. (#974, thanks @pablete!) - Add MLFlow integration callback. (#1028, thanks @PhilipMay!)
- Add
studyargument tooptuna.integration.lightgbm.LightGBMTuner. (#1032) - Support multi-objective optimization. (#1054)
- Add duration into
FrozenTrialandDataFrame. (#1071) - Support parallel execution of
LightGBMTuner. (#1076) - Add
numberproperty toFixedTrialandBaseTrial. (#1077) - Support
DiscreteUniformDistributioninsuggest_float. (#1081, thanks @himkt!) - Add AllenNLP integration. (#1086, thanks @himkt!)
- Add an argument of
max_resourcetoHyperbandPrunerand deprecaten_brackets. (#1138) - Improve the trial allocation algorithm of
HyperbandPruner. (#1141) - Add
IntersectionSearchSpaceto speed up the search space calculation. (#1142) - Implement AllenNLP config exporter to save training config with
best_paramsin study. (#1150, thanks @himkt!) - Remove redundancy from
HyperbandPrunerby deprecatingmin_early_stopping_rate_low. (#1159) - Add pruning interval for
KerasPruningCallback. (#1161, thanks @VladSkripniuk!) suggest_floatwith step inmulti_objective. (#1205, thanks @nzw0301!)
Enhancements
- Reseed sampler's random seed generator in Study. (#968)
- Apply lazy import for
optuna.dashboard. (#1074) - Applied
@abc.abstractmethoddecorator to the abstract methods ofBaseTrialand fixedChainerMNTrial. (#1087, thanks @gorogoroumaru!) - Refactoring of
StudyDirection. (#1090) - Refactoring of
StudySummary. (#1095) - Refactoring of
TrialStateandFrozenTrial. (#1101) - Apply lazy import for
optuna.structsto raiseDeprecationWarningwhen using. (#1104) - Optimize
get_all_strudy_summariesfunction for RDB storages. (#1109) single()returns True whensteporqis greater thanhigh-low. (#1111)- Return
trial_idatstudy._append_trial(). (#1114) - Use
scipyfor sampling from truncated normal in TPE sampler. (#1122) - Remove unnecessary deep-copies. (#1135)
- Remove unnecessary shape-conversion and a loop from TPE sampler. (#1145)
- Support Optuna callback functions at LightGBM Tuner. (#1158)
- Fix the default value of
max_resourcetoHyperbandPruner. (#1171) - Fix the method to calculate
n_bracketsinHyperbandPruner. (#1188)
Bug Fixes
- Support Copy-on-Write for thread safety in in-memory storage. (#1139)
- Fix the range of sampling in TPE sampler. (#1143)
- Add figure title to contour plot. (#1181, thanks @harupy!)
- Raise
ValueErrorthat is not raised. (#1208, thanks @harupy!) - Fix a bug that occurs when multiple callbacks are passed to
MultiObjectiveStudy.optimize. (#1209)
Installation
- Set version constraint on the
cmaeslibrary. (#1082) - Stop installing PyTorch Lightning if Python version is 3.5. (#1193)
- Install PyTorch without CPU option on macOS. (#1215, thanks @himkt!)
Documentation
- Add an Example and Variable Explanations to
HyperBandPruner. (#972) - Add a reference of cli in the sphinx docs. (#1065)
- Fix docstring on
optuna/integration/*.py. (#1070, thanks @nuka137!) - Fix docstring on
optuna/distributions.py. (#1089) - Remove duplicate description of
FrozenTrial.distributions. (#1093) - Optuna Read the Docs top page addition. (#1098)
- Update the outputs of some examples in
first.rst. (#1100, thanks @A03ki!) - Fix
plot_intermediate_valuesexample. (#1103)- Thanks @barneyhill for creating the original pull request #1050!
- Use latest
sphinxversion on RTD. (#1108) - Add class doc to
TPESampler. (#1144) - Fix a markup in pruner page. (#1172, thanks @nzw0301!)
- Add examples for doctest to
optuna/storages/rdb/storage.py. (#1212, thanks @nuka137!)
Examples
- Update PyTorch Lightning example for 0.7.1 version. (#1013, thanks @festeh!)
- Add visualization example script. (#1085)
- Update
pytorch_simple.pyto suggestlrfromsuggest_loguniform. (#1112) - Rename test datasets in examples. (#1164, thanks @VladSkripniuk!)
- Fix the metric name in
KerasPruningCallbackexample. (#1218)
Tests
- Add TPE tests. (#1126)
- Bundle allennlp test data in the repository. (#1149, thanks @himkt!)
- Add test for deprecation error of
HyperbandPruner. (#1189) - Add examples for doctest to optuna/storages/rdb/storage.py. (#1212, thanks @nuka137!)
Code Fixes
- Update type hinting of
GridSampler.__init__. (#1102) - Replace
mockwithunittest.mock. (#1121) - Remove unnecessary
is_loglogic in TPE sampler. (#1123) - Remove redundancy from
HyperbandPrunerby deprecatingmin_early_stopping_rate_low. (#1159) - Use
Trial.system_attrsto storeLightGBMTuner's results. (#1177) - Remove
_TimeKeeperand usetimeoutofStudy.optimize. (#1179) - Define key names of
system_attrsas variables inLightGBMTuner. (#1192) - Minor fixes. (#1203, thanks @nzw0301!)
- Move
colorlogafterthreading. (#1211, thanks @himkt!) - Pass
IntUniformDistribution's step toUniformIntegerHyperparameter'sq. (#1222, thanks @nzw0301!)
Continuous Integration
- Create dockerimage.yml. (#901)
- Add notebook verification for visualization examples. (#1088)
- Avoid installing
torchwith CUDA in CI. (#1118) - Avoid installing
torchwith CUDA in CI by locking version. (#1124) - Constraint
llvmliteversion for Python 3.5. (#1152) - Skip GitHub Actions builds on forked repositories. (#1157, thanks @himkt!)
- Fix
--covoption for pytest. (#1187, thanks @harupy!) - Unique GitHub Actions step name. (#1190)
Other
- GitHub Actions to automatically label PRs. (#1068)
- Revert "GitHub Actions to automatically label PRs.". (#1094)
- Remove settings for yapf. (#1110, thanks @himkt!)
- Update pull request template. (#1113)
- GitHub Actions to automatically label stale issues and PRs. (#1116)
- Upgrade
actions/staleto never close ticket. (#1131) - Run
actions/staleon weekday mornings Tokyo time. (#1132) - Simplify pull request template. (#1147)
- Use major version instead of semver for stale. (#1173, thanks @hross!)
- Do not label
contribution-welcomeandbugissues as stale. (#1216)
- Python
Published by toshihikoyanase about 6 years ago
optuna - v1.3.0
This is the release note of v1.3.0.
Highlights
Experimental CMA-ES
A new built-in CMA−ES sampler is available. It is still an experimental feature, but we recommend trying it because it is much faster than the existing CMA-ES sampler from the integration submodule. See #920 for details.
Experimental Hyperparameter Importance
Hyperparameter importances can be evaluated using optuna.importance.get_param_importances. This is an experimental feature that currently requires fanova. See #946 for details.
Breaking Changes
Changes to the Per-Trial Log Format
The per-trial log now shows the parameter configuration for the last trial instead of the so far best trial. See #965 for details.
New Features
- Add
stepparameter onIntUniformDistribution. (#910, thanks @hayata-yamamoto!) - Add CMA-ES sampler. (#920)
- Add experimental hyperparameter importance feature. (#946)
- Implement
ThresholdPruner. (#963, thanks @himkt!) - Add initial implementation of
suggest_float. (#1021, thanks @himkt!)
Enhancements
- Log parameters from last trial instead of best trial. (#965)
- Fix overlap of labels in parallel coordinate plots. (#979, thanks @VladSkripniuk!)
Bug Fixes
- Support metric aliases for LightGBM Tuner #960. (#977, thanks @VladSkripniuk!)
- Use
SELECT FOR UPDATEwhile updating trial state. (#1014)
Documentation
- Add FAQ entry on how to save/resume studies using in-memory storage. (#869, thanks @victorhcm!)
- Fix pruning
n_warmup_stepsdocumentation. (#980, thanks @PhilipMay!) - Apply gray background for
code-block:: console. (#983) - Add syntax highlighting and fixed spelling variants. (#990, thanks @daikikatsuragawa!)
- Add examples for doctest to
optuna/samplers/*.pyandoptuna/integration/*.py. (#999, thanks @nuka137!) - Embed plotly figures in documentation. (#1003, thanks @harupy!)
- Improve callback docs for optimize function. (#1016, thanks @PhilipMay!)
- Fix docstring on
optuna/integration/tensorflow.py. (#1019, thanks @nuka137!) - Fix docstring in
RDBStorage. (#1022) - Fix direction in doctest. (#1036, thanks @himkt!)
- Add a link to the AllenNLP example in README.md. (#1040)
- Apply document code formatting with Black. (#1044, thanks @PhilipMay!)
- Remove obsolete description from contribution guidelines. (#1047)
- Improve contribution guidelines. (#1052)
- Document
intersection_search_spaceparameters. (#1053) - Add descriptions to cli commands. (#1064)
Examples
- Add
allennlpexample. (#949, thanks @himkt!)
Code Fixes
- Add number field in trials table. (#939)
- Implement some methods almost compatible with Scikit-learn private methods. (#952, thanks @himkt!)
- Use function annotation syntax for type hints. (#989, #993, #996, thanks @bigbird555!)
- Add RDB storage
numbercolumn comment. (#1006) - Sort dependencies in setup.py (fix #1005). (#1007, thanks @VladSkripniuk!)
- Fix
mypy==0.770errors. (#1009) - Fix a validation error message. (#1010)
- Remove python version check. (#1023)
- Fix a typo on
optuna/integration/pytorch_lightning.py. (#1024, thanks @nai62!) - Add a todo comment in
GridSampler. (#1027) - Change formatter from
autopep8toblack(string normalization separate commit). (#1030) - Update module import of
sklearn.utils.safe_indexingforscikit-learn==0.24. (#1031, thanks @kuroko1t!) - Fix
blackerror. (#1034) - Remove duplicate import of
FATAL. (#1035) - Fix import order and plot label truncation. (#1046)
Continuous Integration
- Add version restriction to
pytorch_lightningandbokeh. (#998) - Relax PyTorch Lightning version constraint to fix daily CI build. (#1002)
- Store documentation as an artifact on CircleCI. (#1008, thanks @harupy!)
- Introduce GitHub Action to execute CI for examples. (#1011)
- Ignore allennlp in Python3.5 and Python3.8. (#1042, thanks @himkt!)
- Remove daily CircleCI builds. (#1048)
Other
- Refactor Mypy configuration into
setup.cfg. (#985, thanks @pablete!) - Ignore
.pytest_cache. (#991, thanks @harupy!)
- Python
Published by hvy about 6 years ago
optuna - v1.2.0
This is the release note of v1.2.0.
Highlights
Trial Queue
Study.enqueue_trial allows the user to specify fixed parameter values to be tried next instead of values from the suggestion algorithms. An example is available in the reference. See #520.
Note that this feature introduced an RDB schema change. If you have stored studies created by Optuna v1.1.0 or less in RDBs, please execute $ optuna storage upgrade --storage $URL after updating Optuna.
Experimental Grid Search
Grid search has been introduced as an experimental feature through GridSampler. See #665.
Breaking Changes
Trial.reportto not update the trial value. (#854)
New Features
- Add trial queue. (#520)
- Add a sampler class based on grid search. (#665)
- Display progress bar in optimization process. (#844)
Trial.reportto not update the trial value. (#854)- Add
experimentalwarning. (#884) experimentaldecorator to accept optionalnameand apply to progress bar. (#918)- Add a
n_startup_trialsoption toSkoptSampler. (#951)
Enhancements
- Fix
OptunaSearchCVby adding the method that was implemented inscikit-learn>=0.22.1. (#881, thanks @himkt!) - User-friendly error message for fixed categorical parameter not found in choices. (#900)
- Trial level suggest for same variable with different parameters give warning. (#908, thanks @PhilipMay!)
- More verbose warning message in
Trial._check_distribution. (#934, thanks @PhilipMay!)
Bug Fixes
- Fix
LightGBMTunerto handle metrics with evaluation positions. (#912) - Fix a TPE implementation on
DiscreteUniformDistribution. (#917)- If you use
Trial.suggest_discrete_uniformwith the default sampler (i.e.,TPESampler), optimization performance may degrade due to the issue (#916). Please update Optuna to this version or later.
- If you use
- Use
weakref.finalizeinstead of__del__forRDBStorage. (#941)
Documentation
- Add examples for
doctesttooptuna/trial.py. (#882, thanks @nuka137!) - Add an example of
enqueue_trial. (#927) - Fix typo for
cma.EvotionStrategy. (#929) - Explain installing local Optuna explicitly. (#932, thanks @keisuke-umezawa!)
- Documentation of algorithm behind Optuna. (#940, thanks @arpitkh101!)
- Run a doctest of pycma sampler. (#944)
- Fix doctest in logging. (#953, thanks @keisuke-umezawa!)
- Fix doctest in
parallel_coordinate. (#955, thanks @keisuke-umezawa!) - Add examples for
doctesttooptuna/exceptions.py. (#958, thanks @nuka137!) - Remove description and example of
optuna.structs.TrialPruned(followup of #958). (#959) - Add examples for
doctesttooptuna/prunes/*.py. (#964, thanks @nuka137!) - Fix doctest in visualization. (#973, thanks @keisuke-umezawa!)
Examples
- Add an example of
xgboost.cvusingXGBoostPruningCallback. (#907, thanks @yutayamazaki!) - TensorFlow estimator example with only v2 APIs. (#924, thanks @nuka137!)
- TensorFlow estimator integration example with only v2 APIs. (#935, thanks @nuka137!)
- Simplify PyTorch Ignite example by removing an evaluator. (#971)
Tests
- Add
__init__.pytotests/samplers_tests/tpe_tests. (#945, thanks @keisuke-umezawa!) - Cast to
numpy.ndarrayas Python lists are no longer accepted inxgboost==1.0. (#947)
Code Fixes
- Simplified
_check_distribution. (#937, thanks @PhilipMay!)
Continuous Integration
- Remove version constraints of PyTorch and its related libraries. (#893)
- Bump up pip version. (#911)
- Fix sphinx version to avoid build error. (#942)
- Apply Python3-style of type hinting to
optuna.integration.lightgbm_tuner.train. (#943)
- Python
Published by hvy over 6 years ago
optuna - v1.1.0
This is the release note of v1.1.0.
New Features
Experimental Hyperband
Hyperband, an extension of the successive halving pruning algorithm, has been introduced as an experimental feature through HyperbandPruner. It is compatible with RandomSampler and TPESampler. See #809.
Breaking Changes
SuccessiveHalvingPruner minimum resource heuristic
When min_resource is omitted, instead of defaulting to 1, the SuccessiveHalvingPruner now uses a heuristic to guess a suitable value. See #812.
Enhancements
- Set
pool_pre_ping=Truefor MySQL to avoid connection errors. (#806) - Initial implementation of 'auto' for
min_resourceinSuccessiveHalvingPruner. (#812) - Update
TPESamplerto supportHyperbandPruner. (#828) - Fix
XGBoostPruningCallbackto be compatible withxgboost.cv. (#865, thanks @yutayamazaki!)
Bug Fixes
- Make
PyTorchIgnitePruningHandlerreport correct epoch. (#847) - Fix LightGBM tuner raises exception when
max_depth=-1. (#872) - Sort intermediate values in
plot_intermediate_values. (#889)
Installation
- Update SciPy version. (#838, thanks @yasuyuky!)
Documentation
- Fix
KerasPruningCallbackpruning example code. (#832, thanks @harupy!) - Fix docstrings of visualization functions. (#833, thanks @harupy!)
- Update a badge image for Python 3.8. (#836)
- Add a note for JupyterLab users. (#843)
- FAQ documentation bullet list. (#856)
- Add to FAQ dynamically altering search spaces. (#857)
- Elaborate on details of
HyperbandPruner. (#875) - Update FAQ about trials raising exceptions and returning NaN. (#880)
- Add Neptune to the list of external libraries which use Optuna. (#890)
- Add OptGBM to the
examples/README.md. (#896) - Add link to examples. (#897)
Examples
- Add
--pruningoption topytorch_lightning_simple.py. (#794, thanks @yutayamazaki!) - Add FastAI example with
FastAIPruningCallback. (#848) - Fix TensorFlow eager example with TensorFlow 2.X. (#855, thanks @nuka137!)
- Update the PyTorch Lightning example to support
pytorch_lightning==0.6.0. (#858) - Add an example for LightGBM Tuner. (#860, thanks @jinnaiyuu!)
- Convert None to NaN before reporting to MLFlow. (#863)
- Remove description about CLI execution of MLFlow example. (#864)
- Fix TensorFlow estimator example with TensorFlow 2.X. (#868, thanks @nuka137!)
- Fix TensorFlow estimator pruning example with TensorFlow 2.X. (#871)
Code Fixes
- Remove
typingexternal dependency. (#840, thanks @hbredin!) - RDB storage module level logger. (#866)
Other
- Git ignore
.DS_Store. (#829) - Require
torchvision>=0.5.0with Pillow version fix. (#839, thanks @hugovk!)
- Python
Published by hvy over 6 years ago
optuna - v1.0.0
This is the release note of v1.0.0. See here for the complete list of solved issues and merged PRs.
Highlights
The first major version of Optuna v1.0 is released. It includes a stable API, significant performance improvements by reduced memory allocations and database storage accesses. Documentation has been revised and Jupyter Notebook examples are available on Google Colab. The visualization API has become customizable such that layouts can be modified.
Python 2 Support Drop
Due to the end-of-life (EOL) of Python 2 in January 1, 2020, Optuna has dropped the support for Python 2 and has now shifted to support Python 3.5.1 and above.
Blog
A developer blog has started. The first post is about this release and future roadmaps.
New Features
- Use Joblib to parallelize optimization. (#692, thanks @AnesBenmerzoug!)
trials_dataframeto allow returningDataFramewith flattened columns. (#736)- Make plot functions return Plotly graph object. (#704)
Enhancements
- Add options to disable trials deep copy. (#696)
- Slice plot to dynamically resize figure width depending on number of parameters. (#720)
- Fix implementations of
__eq__. (#726) - Speed up
study.best_trialfor RDB. (#729, thanks @chris-chris!) - Use the preferred module level logger in
structs.py. (#768) - Use
SourceFileLoaderinstead ofimpmodule. (#778) - Add warning about use of
InMemoryStoragewith multi-processing. (#780) - Avoid redundant sort (reverse) in successive halving. (#807)
Bug Fixes
- Use default parameter when tuned parameter doesn't improve. (#721)
Documents
- Introduce
doctest. (#702) - Comment out notes for contributors in GitHub templates. (#738, thanks @crcrpar!)
- Add installation via
conda. (#739, thanks @crcrpar!) - Add badges to README. (#740, thanks @crcrpar!)
- First Contribution clarity edits. (#744)
- Clarity edits to
configurations.rst. (#747) - Add Gitter badge to README.md. (#749)
- Replace Slack with Gitter in the issue template. (#750)
- Setup
intersphinx. (#754) - Follow Google Analytics Privacy Disclosure Policy. (#776)
- Update example dataframe in tutorial. (#784)
- Document
BasePrunerin docs. (#788, thanks @crcrpar!) - Update docstring of
BasePruner.prune. (#793, thanks @crcrpar!) - Add favicon to doc. (#796, thanks @harupy!)
- Fix indentation in
tutorial/index.rst. (#816, thanks @harupy!) - Fix warnings in the documentation build. (#819, thanks @harupy!)
- Add integration modules list to README. (#830)
Examples
- Add an example for
OptunaSearchCV. (#722, thanks @yutayamazaki!) - Add
scikit-imageexample. (#730, thanks @tohmae!) - Merge visualization examples. (#735)
- Add "Open In Colab" badge to visualization example. (#737, thanks @crcrpar!)
- Add badge on README that launches starter notebook. (#741, thanks @harupy!)
- Consistent import of
optunain examples. (#746) - Remove Google Colab preinstalled library from
quickstart.ipynb. (#753) - Refactor model definition of
examples/pytorch_simple.py. (#779, thanks @crcrpar!) - Fix Colab badge on visualization example notebook. (#789, thanks @harupy!)
- Add MLflow example. (#795, thanks @harupy!)
- Use callback to report results to MLflow. (#799)
- Add README with gif to MLflow example. (#802, thanks @harupy!)
- Revise quickstart Jupyter notebook. (#804)
Tests
- Stop passing step to
should_pruneinchainermn. (#764, thanks @crcrpar!) - Remove a temporary workaround in the
test_callbacksfunction. (#769) - Add lock acquisition to make
test_callbackstest thread-safe. (#773) - Simplify
Studyunit test parameterizations. (#774) - Remove
cache_modeargument to fix a broken test. (#790)
Code Fixes
- Dissect
optuna/visualization.py. (#681, thanks @crcrpar!) - Refactor
setup.py. (#742) - Fix deprecated property access. (#751)
- Remove
StudySummary.__ne__. (#756) - Remove redundant trailing commas. (#757)
- Fix a typo in
RDBStorage. (#765) - Change
loggerto study's module variable. (#770, thanks @crcrpar!) - Separate standard library imports from third party imports. (#777, thanks @yutayamazaki!)
- Early commit after RDB session creation. (#792)
- Refactoring of successive halving. (#808)
Installation
- Remove
cythonfrom requirements. (#781) - Add version restriction of
scipy. (#801) - Add version constraint of
scikit-learn(<=0.22.0). (#826) - Add version constraint of
pillowto avoidtorchvision's issue. (#827)
Breaking Changes
- Prefix '_' to private functions in
optuna.dashboard. (#698) - Prefix '_' to private classes and attributes in
optuna.samplers. (#699) - Prefix '_' to private attributes of pruners. (#703)
- Make plot functions return Plotly graph object. (#704)
- Prefix '_' to private attributes of classes in
optuna.integration. (#705) - Remove
enable_cacheoption fromRDBStorage. (#706) - Remove Python 2 version check from
integration.__init__.pycondition. (#712) - Remove
six. (#714) - Remove
__future__. (#715) - Make
bokeh-allow-websocket-originsrequired. (#716) - Make
study_idprivate. (#718) - Add
FrozenTrial.__lt__to sort trials without key. (#719) - Remove version checks from
setup.py. (#724) trials_dataframeto allow returningDataFramewith flattened columns. (#736)BaseDistribution.__hash__to take__class__into account. (#743)- Only allow
float,strand castable tofloatin categorical distribution. (#758) - Improving usability of
TrialStatein trials dataframes. (#771) - Remove deprecated
product_search_spacefunction. (#772) - Add 'attrs' option to
Study.trials_dataframe(). (#775)
Continuous Integration
- Drop CI jobs for Python 2.7. (#710)
- Add CI jobs for Python 3.8. (#759)
- Merge with master branch in CI jobs. (#791)
- Python
Published by hvy over 6 years ago
optuna - v0.19.0
This is the release note of v0.19.0. See here for the complete list of solved issues and merged PRs.
Highlights
The GitHub organization of this repository has been changed from pfnet, the organization for Preferred Networks, Inc. to optuna in order to widen the community, growing the project as an open source software.
optuna.exceptions has been introduced. Now, all exceptions defined in Optuna, including TrialPruned, have been moved out from optuna.structs to this new submodule. This is a part of a larger refactoring that we are currently working on to clean up the interfaces and make Optuna even easier to use. To avoid breaking existing code however, optuna.structs.TrialPruned is still available but marked as deprecated.
Upcoming Python 2 Support Drop
Due to the end-of-life (EOL) of Python 2 in January 2020, Optuna will drop Python 2 support in December 2019. This decision was made considering the following facts: - Python 2 goes end-of-life (EOL) in January 2020. - Many scientific computation packages, including NumPy, which is one of the core dependency of Optuna, are planning or already started to drop support for Python 2. We plan to drop Python 2 support in the first release in December 2019.
Compatibility
- Disallow negative step numbers in
Trial.report. (#701) - Disallow erroneous arguments to
PercentilePruner. (#693) - Extract exception classes to
optuna.exceptionsmodule. (#691) - Make
{FrozenTrial,Trial}.trial_idprivate. (#663)
New Features
- Allow specifying step interval for
{Median,Percentile}Pruner. (#660)
Enhancements
- Make distribution classes single inheritance. (#573)
Bug Fixes
- Fix the handling of
time_budgetoption onlightgbm_tuner.train(). (#684, thanks @momijiame!)
Documents
- Improve documentation of
Trial.should_prune. (#690) - Expose
RDBStorageconstructor. (#689) - Add a note about type casting of reported values to
trial.report()doc. (#687) - Add punctuation to copyright in docs. (#682)
- Replace the company name with
Optuna Contributorsin the docs. (#676) - Update the documentation of
Trialclass. (#668) - Add Code of Conduct. (#675, thanks @Crissman!)
Examples
- Improve visualization examples. (#667, thanks @Crissman!)
- Update PyTorch Lightning example for
pytorch-lightning==0.5.3. (#700)
Tests
- Add more
optuna.visualizationtests. (#630, thanks @crcrpar!) - Remove the version constraint for
pytorch_lightning. (#694)
- Python
Published by sile over 6 years ago
optuna - v0.18.1
This is the release note of v0.18.1. See here for the complete list of solved issues and merged PRs.
Bug Fixes
- Fix
import optunafailure on Python2.7 environment without LightGBM installed. (#674)
Examples
- Change subsample's low value from 0 to 0.1 in the catboost example. (#678)
- Python
Published by sile over 6 years ago
optuna - v0.18.0
This is the release note of v0.18.0. See here for the complete list of solved issues and merged PRs.
Upcoming Python 2 Support Drop
Due to the end-of-life (EOL) of Python 2 in January 2020, Optuna will drop Python 2 support in December 2019.
This decision was made considering the following facts: - Python 2 will become end-of-life (EOL) in January 2020. - Many scientific computation packages, including NumPy, which is one of the core dependency of Optuna, are planning or already started to drop support for Python 2.
We plan to drop Python 2 support in the first release in December 2019.
Compatibility
- Remove
OptunaConfig. (#653) - Catch no exceptions in
optimizeby default. (#638)
New Features
- Add function for high-dimensional parameter relationships visualization. (#594, thanks @suecharo!)
- Add function for parameter relationships visualization as slice plot. (#540, thanks @suecharo!)
- Add function for parameter relationships visualization as contour plot. (#539, thanks @suecharo!)
- Add a PyTorch Ignite handler for pruning. (#561)
- Add PyTorch Lightning pruning integration. (#597)
- Add FastAI Callback for pruning. (#585, thanks @crcrpar!)
- Add public APIs for checking visualization availability. (#607)
- [Experimental] Add a prototype version of automatic LightGBM tuner with stepwise logic. (#549)
Enhancements
- Improve handling of reported values. (#659)
- Avoid iterating through all trials unnecessarily. (#641, thanks @dwiel!)
- Remove
TrialModel.where_study_id. (#640) - Record all error raising trials as failures. (#637)
- Speed up Parzen Estimator. (#554, thanks @oda!)
- Cache best
trial_id. (#535, thanks @oda!) - Add an option to
force_garbage_collectionfor every trial. (#533, thanks @oda!) - Fix plotoptimizationhistory. (#631, thanks @cafeal!)
Bug Fixes
- Add type casting to float. (#644)
- Add missing call to check function. (#598)
Documents
- Add
PULL_REQUEST_TEMPLATE.mdfile. (#651) - Update issue template. (#652)
- Update
CONTRIBUTING.mdfile. (#649) - Update the experimental warning of
OptunaSearchCV. (#639) - Update
BaseStudy.trialsdoc to specify order constraint. (#634) - Add visualization functions to API reference doc. (#615)
- Apply a small fix to the docstring of
Study. (#591) - Add links to nbviewer. (#590, thanks @upura!)
Examples
- Add a distributed optimization example on Kubernetes. (#643, thanks @AnesBenmerzoug!)
- Add
--pruningoption to the PyTorch Ignite example. (#633) - Fix an example for
tensorflow==1.15.0. (#620) - Add pruning to Chainer example. (#614, thanks @Crissman!)
- Enclose
plot_slice()of slice plot example in backquotes. (#608, thanks @crcrpar!) - Add PyTorch Lightning example. (#584)
Tests
- Fix assertions in
test_optimize_with_catch. (#650) - Fix the module of type variables. (#636)
- Add
ValueErrortest totest_get_contour_plot(). (#616, thanks @crcrpar!)
Continuous Integration
- Skip XGBoost tests and examples with Python 2.7 in CircleCI. (#654)
- Hide
pipprogress bar from CircleCI log. (#648) - Align CircleCI
install-examplesstep name to anchor. (#618)
Code Fixes
- Use indices to align with the others. (#621, thanks @crcrpar!)
- Replace useless
Nonecheck with assertion. (#610)
- Python
Published by hvy over 6 years ago
optuna - v0.17.0
This is the release note of v0.17.0. See here for the complete list of solved issues and merged PRs.
Dropping Support of Python 2
Due to the end-of-life (EOL) of Python 2 in January 2020, Optuna will drop Python 2 support in December 2019.
This decision was made considering the following facts: - Python 2 will become end-of-life (EOL) in January 2020. - Many scientific computation packages, including NumPy, which is one of the core dependency of Optuna, are planning or already started to drop support for Python 2.
We plan to drop Python 2 support in December 2019, but the date has not been determined yet. The detailed schedule will be published in the next release.
New Features
- Add
NopPruner. (#555, thanks @Muragaruhae) - Add pruning callback for
tf.keras. (#530, thanks @sfujiwara!) - Add
delete_studyAPI for storage package. (#524, thanks @c-bata!) - Add function for optimization history visualization. (#513, thanks @suecharo!)
- Add user-defined callbacks. (#480)
- Add
Study._append_trialmethod. (#464) - Add
OptunaSearchCVthat provides sklearn compatible API (experimental). (#357, thanks @Y-oHr-N!)
Enhancements
- Add maximize support at dashboard. (#587, thanks @c-bata!)
- Make study returns an empty dataframe if no trials. (#574, thanks @crcrpar!)
- Support TensorFlow 2.0. (#562)
- Add a function to delete a study object. (#558, thanks @c-bata!)
- Fix type hints for mypy==0.730. (#553)
- Add
datetime_startproperty to FixedTrial. (#548) - Update high value using Decimal. (#546)
- Apply small fixes to history and intermediate plots. (#541, thanks @suecharo!)
- Fix
test_keras_pruning_callbackto be compatible withkeras==2.3.0. (#537) - Change the deprecated
product_search_spacetointersection_search_space. (#532, thanks @oda!) - Add
datetime_startto ChainerMN integration. (#528, thanks @tanapiyo!) - Remove dependency on pandas. (#527, thanks @henry0312!)
- Add Python3.4 version check to
RDBStorage. (#525, thanks @tadan18!) - Add
datetime_startduring a trial. (#523, thanks @tanapiyo!) - Move example's setup to setup.py. (#522, thanks @tanapiyo!)
- Change class to use for type checking. (#519, thanks @suecharo!)
- Support plotly version 4.0.0. (#511, thanks @suecharo!)
- Fix round-off errors by using decimal module #503. (#505, thanks @A03ki!)
- Add cascade settings. (#422, thanks @c-bata!)
Bug Fixes
- Fix package of
TracebackType. (#547)
Documents
- Remove init arguments from study docs. (#579, thanks @scouvreur!)
- Update explanation of the effect of round-off errors on
suggest_discrete_uniform. (#544)
Examples
- Update
.gitignoreto ignore files related to examples. (#578, thanks @crcrpar!) - Make LightGBM examples more practical. (#575)
- Add an example of
MXNetPruningCallback. (#570, thanks @crcrpar!) - Improve clarity of MXNet example. (#569, thanks @crcrpar!)
- Add PyTorch Ignite example. (#559)
- Fix OOM errors during execution of TF Keras example on CircleCI. (#545)
- Apply maximize direction. (#526, thanks @r-soga!)
- Simplify LightGBM examples. (#580)
- Python
Published by toshihikoyanase over 6 years ago
optuna - v0.16.0
This is the release note of v0.16.0. See here for the complete list of solved issues and merged PRs.
New Features
- Introduce new pruner interface. (#493, thanks @c-bata!)
Compatibility
- Remove
_idsuffix fromBaseStorage.create_new_{study,trial}_idmethods. (#506) - Remove
InTrialStudyclass. (#491)
Bug Fixes
- Call session commit after read access. (#504)
Documents
- Add
keras_simple.pytoexamples/README.md. (#508) - Add TPESampler docs to
create_studyfunction. (#502, thanks @scouvreur!) - Add link to KDD paper in README. (#500)
Examples
- Add Keras example. (#489, thanks @scouvreur!)
- Python
Published by sile almost 7 years ago
optuna - v0.15.0
This is the release note of v0.15.0. See here for the complete list of solved issues and merged PRs.
Compatibility
- Remove
FronzenTrial.params_in_internal_reprfield. (#462)
Enhancements
- Fix type hints and typo. (#494, thanks @c-bata!)
- Change types.py to type_checking.py. (#492, thanks @oda!)
- Reduce a query count of PercentilePruner and MedianPruner. (#482, thanks @c-bata!)
- Add empty distribution check. (#473)
- Make
BaseStudy.storagefield private. (#472) - Reduce redundant code common to
StudyandInTrialStudy. (#470)
Bug Fixes
- Prevent TensorFlowPruningHook from reporting None. (#481)
- Add NaN intermediate value handling to
TPESampler. (#476)
Documents
- Fix typo in keras integration example. (#488, thanks @scouvreur!)
- Add
TPESamplerdocument. (#474) - Update
BaseSamplerdocument. (#456) - Add a tutorial page about user-defined sampler. (#451)
- Set long_description in setup.py. (#420, thanks @c-bata!)
Examples
- Add a simple Dask-ML example. (#487, thanks @AnesBenmerzoug!)
- Add a catboost example. (#477, thanks @scouvreur!)
- Add an example that implements simulated annealing based sampler. (#446)
- Python
Published by sile almost 7 years ago
optuna - v0.14.0
This is the release note of v0.14.0. See here for the complete list of solved issues and merged PRs.
New Features
- Add CMA-ES Sampler. (#447)
Enhancements
- Make
TPESamplerfaster. (#466, thanks @oda!) - Add
intersection_search_spacefunction. (#461) - Change property access in TrialState for Python 3.4. (#460)
- Change the default gamma function for
TPESampler. (#445) - Make
TPESamplerpruning aware. (#439)
Bug Fixes
- Fix a bug when
suggest_categoricalis called withchoicescontaining int and str. (#449)
Documents
- Fix typo in
cma.pyandtrial.py. (#463, thanks @nmasahiro and @c-bata!)
Examples
- Apply maximize to examples. (#410, thanks @nmasahiro!)
Tests
- Reduce CI time. (#467)
- Python
Published by toshihikoyanase almost 7 years ago
optuna - v0.13.0
This is the release note of v0.13.0. See here for the complete list of solved issues and merged PRs.
New Features
- Introduce new sampler interface. (#380)
- Add SkoptSampler. (#399)
Compatibility
- Disable log propagation. (#442)
Enhancements
- Disable log propagation. (#442)
- Add
BaseDistribution.singlemethods. (#431) - Add
product_search_spacefunction. (#430) - Replace
connect_argsinRDBStorageconstructor withengine_kwargsargument. (#425) - Support TensorFlow 1.14.0. (#432)
Documents
- Update README.md. (#443)
- Add reference for distributions. (#440)
- Add reference for BaseSampler. (#437)
- Add reference for InTrialStudy. (#436)
Examples
- Add TensorFlow eager execution example. (#369, thanks @Rishav1!)
- Python
Published by sile almost 7 years ago
optuna - v0.12.0
This is the release note of v0.12.0. See here for the complete list of solved issues and merged PRs.
New Features
- Implement PercentilePruner. (#397, thanks @c-bata!)
Bug Fixes
- Fix the error that occurs when using a study that contains old trials. (#415)
- Synchronize when _ChainerMNTrial sets values. (#413)
- Fix a bug that
FixedTrialcannot handle categorical parameters correctly. (#402)
Compatibility
- Make the step argument of should_prune method optional. (#398, thanks @c-bata!)
Documents
- Fix typo of LightGBM. (#409, thanks @nmasahiro!)
- Use
optuna.load_study()function instead ofoptuna.Study()constructor. (#407)
Examples
- Fix FutureWarnings of scikit-learn. (#418, thanks @c-bata!)
Others
- Update flake8 exclude option in setup.cfg. (#405, thanks @c-bata!)
- Python
Published by g-votte about 7 years ago
optuna - v0.11.0
This is the release note of v0.11.0. See here for the complete list of solved issues and merged PRs.
New Features
- Add pruning callback for MXNet. (#363, thanks @Rishav1!)
Enhancements
- Support suggestion ranges whose endpoints take the same value. (#384)
- Add
distributionsproperty to trial classes. (#383)
Bug Fixes
- Fix installation failure with Python-3.5.2. (#396)
- Escape '%' character in storage URL. (#395)
- Fix type of suggest APIs. (#393)
Examples
- Add PyTorch example. (#366, thanks @Rishav1!)
- Python
Published by sile about 7 years ago
optuna - v0.10.0
This is the release note of v0.10.0. See here for the complete list of solved issues and merged PRs.
Enhancements
- Add GC call after evaluating an objective function. (#377)
- Change order of checking code. (#374, thanks @okdshin!)
- Restrict data load to worker 0. (#362)
- Add cache to
RDBStorage. (#349) - Inhibit storage access of samplers in
ChainerMNStudy. (#348) - Introduce Alembic. (#336)
Bug Fixes
- Fix minor problems of
TPESamplerandParzenEstimator. (#373) - Fix an issue in parallel execution where inconsistent
FronzenTrialcould be created with low probability. (#361)
Documents
- Add an issue template. (#378, thanks @crcrpar!)
- Add
KerasPruningCallbackandTensorFlowPruningHookto document. (#371) - Rewrite formulas using mathjax. (#367, thanks @crcrpar!)
Examples
- Add Keras pruning example. (#364, thanks @Rishav1!)
- Add simple MXNet example for MNIST. (#359, thanks @Rishav1!)
Tests
- Enable tensorflow in Python 3.7. (#360)
- Python
Published by toshihikoyanase about 7 years ago
optuna - v0.9.0
This is the release note of v0.9.0. See here for the complete list of solved issues and merged PRs.
New Features
- Add implementation of
maximize. (#331) - Add
load_studyfunction. (#330) - Add
Trial.number. (#285)
Compatibility
- Replace
Trial.trial_idwithTrial.numberin dashboard. (#345) - Deprecate
Trial.trial_idattribute. (#344) - Replace
Trial.trial_idwithTrial.numberin reference, tutorial, and examples. (#342, #341, #340, #339, #338, #337) - Remove direction argument from
Study.__init__. (#335)
Examples
- Add TensorFlow examples. (#323)
Enhancements
- Apply lazy import in
optuna.integrationfor Python 3.x. (#334)
Documents
- Fix code block for resuming study in
rdb.rst. (#328, thanks @usernameandme!)
Bug Fixes
- Fix import errors in Python3.5.0 and Python3.5.1. (#326)
- Fix the range of return values of
Trial.suggest_discrete_uniform(). (#321)
- Python
Published by g-votte over 7 years ago
optuna - v0.8.0
This is the release note of v0.8.0. See here for the complete list of solved issues and merged PRs.
Enhancements
- Support pruning when using ChainerMN. (#286, thanks @MannyKayy, @rcalland!)
- Add queries to retrieve information of trials. (#284)
Documents
- Update configurations.rst with grammar fix. (#316, thanks @d1vanloon!)
- Fix PEP8 errors on README.md. (#314, thanks @nai62!)
- Add a blank line to show code example. (#311)
- Python
Published by sile over 7 years ago
optuna - v0.7.0
This is the release note of v0.7.0. See here for the complete list of solved issues and merged PRs.
Compatibility
- Remove support of Python3.4. (#305)
New Features
- Add integration for TensorFlow's Estimator API. (#292, thanks @sfujiwara!)
- Add an argument to show internal field of dataframe. (#283)
- Add visualization utility for learning curves. (#281)
Enhancements
- Enable
--disallow-untyped-defsmypy flag. (#296)
Documents
- Fix typo in FAQ. (#306)
- Add supplementary comments in integration modules. (#300)
Examples
- Fix warning issue on recent sklearn version. (#304, thanks @djKooks!)
- Fix the parameter value of "number of boosting iterations" in GBDT examples. (#280)
- Python
Published by toshihikoyanase over 7 years ago
optuna - v0.6.0
This is the release note of v0.6.0. See here for the complete list of solved issues and merged PRs.
New Features
- Support cross validation in lightgbm.py (#260, thanks @shikiponn!)
- Implement Keras integration. (#256, thanks @higumachan!)
- Add a pruner based on Successive Halving. (#236)
Examples
- Add an example and FAQ about object functions that take additional arguments. (#277)
Documents
- Add instruction sentences for RDB URL setup in the tutorial. (#295)
- Add an FAQ page about unit tests of objective functions. (#291)
Enhancements
- Address integrity errors caused by timing issues when setting attributes in RDBStorage. (#290)
- Optimize query of count trials. (#282)
- Apply autopep8. (#274)
- Fix dashboard access problem from remote host. (#254, thanks @higumachan!)
- Python
Published by g-votte over 7 years ago
optuna - v0.5.0
This is the release note of v0.5.0. See here for the complete list of solved issues and merged PRs.
Bug Fixes
- Make samplers/tpe/parzen_estimator.py adaptive. (#261, thanks @HideakiImamura!)
Tests
- Add test cases to check NaN handling of MedianPruner. (#264)
New Features
- Add FixedTrial. (#250)
- Add
load_if_existsoption. (#242)
Examples
- Fix a typo in pruning example of xgboost. (#266)
- Fix an invalid parameter,
ets, in xgboost example. (#265, thanks @higumachan!) - Use list for choice argument instead of tuple. (#252)
Documents
- Fix a style error in FAQ. (#267)
- Add an FAQ about the way to specify the GPU with CUDAVISIBLEDEVICES. (#263)
- Add an FAQ about NaN returned by objective functions. (#258)
- Add an FAQ about the way to save machine learning models. (#255)
- Add an FAQ about random seed. (#253)
- Add an FAQ about logging levels. (#251)
Enhancements
- Fix typo. (#269, thanks @RossyWhite!)
- Overwrite sigma of prior distributions. (#268, thanks @fofof200!)
- Make TYPE_CHECKING work before Python 3.5.2. (#262, thanks @okapies!)
- Make
ChainerPruningExtensionreport NaN to pruner. (#259) - Fix mypy's version constraint. (#257, thanks @okapies!)
- Python
Published by sile over 7 years ago