computer-vision-in-action
A computer vision closed-loop learning platform where code can be run interactively online. 学习闭环《计算机视觉实战演练:算法与应用》中文电子书、源码、读者交流社区(持续更新中 ...) 📘 在线电子书 https://charmve.github.io/computer-vision-in-action/ 👇项目主页
Science Score: 36.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Committers with academic emails
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (8.9%) to scientific vocabulary
Keywords
books
charmve
colab-notebook
computer-vision
computer-vision-algorithms
deep-learning
deep-learning-tutorial
handbook
in-action
ipynb
jupyter-notebook
machine-learning
neural-network
notebook
pytorch
transformer
tutorial
Last synced: 10 months ago
·
JSON representation
Repository
A computer vision closed-loop learning platform where code can be run interactively online. 学习闭环《计算机视觉实战演练:算法与应用》中文电子书、源码、读者交流社区(持续更新中 ...) 📘 在线电子书 https://charmve.github.io/computer-vision-in-action/ 👇项目主页
Basic Info
- Host: GitHub
- Owner: Charmve
- License: other
- Language: Jupyter Notebook
- Default Branch: main
- Homepage: https://charmve.github.io/L0CV-web
- Size: 289 MB
Statistics
- Stars: 2,767
- Watchers: 34
- Forks: 402
- Open Issues: 60
- Releases: 0
Topics
books
charmve
colab-notebook
computer-vision
computer-vision-algorithms
deep-learning
deep-learning-tutorial
handbook
in-action
ipynb
jupyter-notebook
machine-learning
neural-network
notebook
pytorch
transformer
tutorial
Created about 5 years ago
· Last pushed about 2 years ago
Metadata Files
Readme
Changelog
Contributing
Funding
License
Code of conduct
Citation
README.md
""

L0CV `` HTML
[Charmve](https://github.com/Charmve)
|











Index

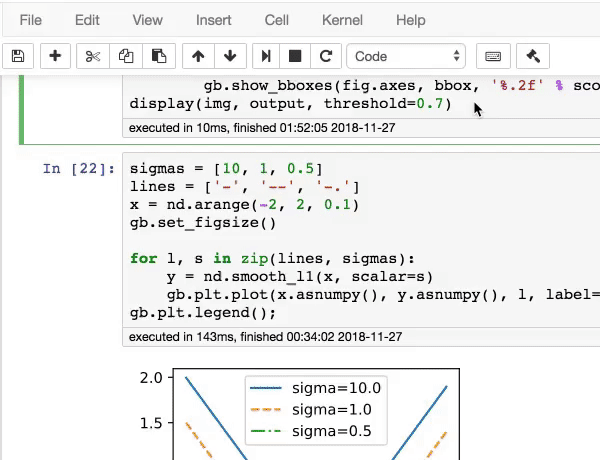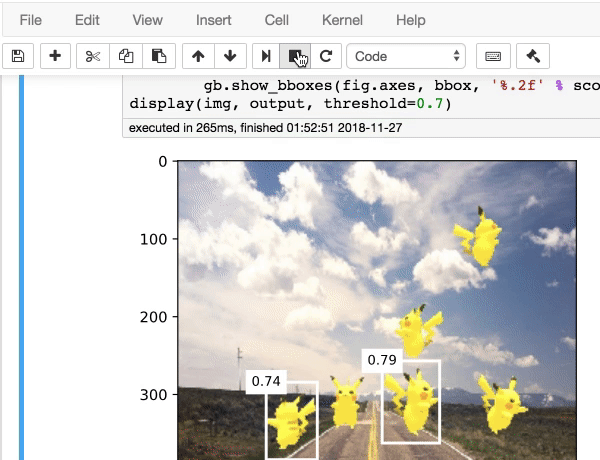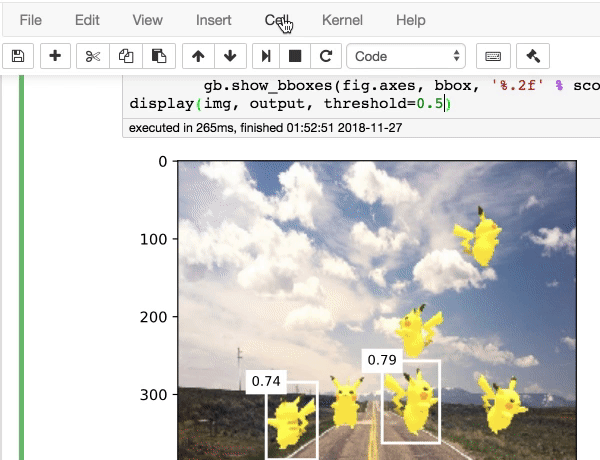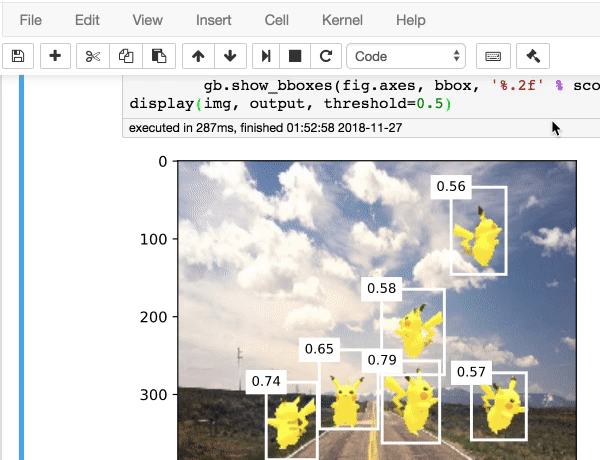
:label: sec_code 1 L0CV
:label: fig_book_org

AdaBoost
Transformer7PyTorch3D
notebook
L0CVimport L0CVTransformerAttention
chap_optimization
- https://charmve.github.io/computer-vision-in-action/
()
- [](/docs/book_preface.md)- - - 0 [](https://charmve.github.io/computer-vision-in-action/#/chapter0/chapter0) - 0.1 [](docs/0_/chapter0.1_.md) - 0.1.1 - 0.1.2 - 0.1.3 - 0.2 [](docs/0_/chapter0.2_.md) - 0.3 [](docs/0_/chapter0.3_.md) - 0.4 [](docs/0_/chapter0.4_.md) - - - - 3D - 0.5 [](docs/0_/chapter0.5_.md) - - - - - 1 [](https://charmve.github.io/computer-vision-in-action/#/chapter2/chapter2) - 1.1 [](/1_/chapter1_Neural-Networks/chapter1.1_line-regression.md) - 1.1.1 - 1.1.2 - 1.1.3 - 1.2 [Softmax ](./docs/1_/chapter3_Image-Classification/chapter1.2_Softmax.md) - 1.2.1 softmax - 1.2.2 softmax - 1.2.3 softmax - 1.3 [](./docs/1_/chapter1_Neural-Networks/chapter1.3_MLP.md) - 1.3.1 - 1.3.2 - 1.3.3 - 1.4 [](./docs/1_/chapter1_Neural-Networks/chapter1.4_Back-Propagation.md) - 1.5 [](./docs/1_/chapter1_Neural-Networks/chapter1.5_neural-networks.md) - 1.5.1 [](./docs/1_/chapter1_Neural-Networks/chapter1.5.1_.md) - 1.5.2 [1-](https://cs231n.github.io/neural-networks-1/) - 1.5.3 [2-](https://cs231n.github.io/neural-networks-2/) - 1.5.4 [3-](https://cs231n.github.io/neural-networks-3/) - 1.5.5 [-](https://cs231n.github.io/neural-networks-case-study/) - 1.6 [ 1 - ](https://blog.csdn.net/Charmve/article/details/108531735) - - - 2 [](docs/1_/chapter2_CNN/chapter2_CNN.md) - 2.1 [](docs/1_/chapter2_CNN/chapter2_CNN.md#21-) - 2.1.1 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#211-) - 2.1.2 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#212-) - 2.2 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#22-) - 2.2.1 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#221-) - 2.2.2 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#222-) - 2.2.3 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#223-) - 2.2.4 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#224-) - 2.2.5 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#225-) - 2.3 [](/docs/1_/chapter2_CNN/chapter2_CNN.md#23-) - 2.4 [ 2 - ](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md) - 2.4.1 [](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#271-) - 2.4.2 [](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#272-) - 2.4.3 [](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#273-) - [1. ](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#1-) - [2. ](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#2-) - [3. ](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#3-) - [4. ](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#4-) - [5. ](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#5-) - [6. MaxPooling](docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#6-MaxPooling) - 2.4.4 [PaddlePaddle](/docs/1_/chapter2_CNN/chapter2_CNN-in-Action.md#274-PaddlePaddle) - [](docs/1_/chapter2_CNN/chapter2_CNN.md#) - [](/docs/1_/chapter2_CNN/chapter2_CNN.md#) - 3 [](./docs/1_/chapter3_Image-Classification/) - 3.1 [](https://cs231n.github.io/classification/) - 3.1.1 - 3.1.2 - 3.1.3 - 3.2 [k ](./docs/1_/chapter3_Image-Classification/chapter3.2_knn.md) - 3.2.1 k - 3.2.2 k - 3.2.3 KNN - 3.2.4 k Python - - - 3.3 [](./docs/1_/chapter3_Image-Classification/chapter3.3_.md) - 3.3.1 - 3.3.2 - 3.3.3 - 3.3.4 - 3.4 [ LR](./docs/1_/chapter3_Image-Classification/chapter3.4_Logistic-Regression.md) - 3.4.1 - 3.4.2 - 3.4.3 - 3.5 [ 3 - ](https://blog.csdn.net/charmve/category_9754344.html) - 3.6 [ 4 - CIFAR10](http://mp.weixin.qq.com/s?__biz=MzIxMjg1Njc3Mw%3D%3D&chksm=97bef597a0c97c813e185e1bbf987b93d496c6ead8371364fd175d9bac46e6dcf7059cf81cb2&idx=1&mid=2247487293&scene=21&sn=89684d1c107177983dc1b4dca8c20a5b#wechat_redirect) - [](./docs/1_/chapter3_Image-Classification/README.md#) - [](./docs/1_/chapter3_Image-Classification/README.md#) - 4 - [4.1 RNN](/docs/1_/chapter4_/chapter4.1_.md) - [4.2 ](/docs/1_/chapter4_/chapter4.1_.md) - [4.3 ](/docs/1_/chapter4_/chapter4.1_.md) - [4.4 LSTM](/docs/1_/chapter4_/chapter4.4_LSTM.md) - [4.5 GRU](/docs/1_/chapter4_/chapter4.5_.md) - - - - 5 [](/docs/1_/chapter5_/chapter5_.md) - 5.1 [](/docs/1_/chapter5_/chapter5_.md#51-) - 5.2 [(Graph Neural Network)](https://www.cnblogs.com/SivilTaram/p/graph_neural_network_1.html) - 5.2.1 [](/docs/1_/chapter5_/chapter5_.md#51-) - 5.2.2 [](/docs/2_/chapter8_/chapter8.1_.md#812-pytorch) - 5.2.3 [](/docs/2_/chapter8_/chapter8.1_.md#813-) - 5.2.4 []() - 5.2.5 [GNNRNN](/docs/2_/chapter8_/chapter8.2_BenchMark.md) - 5.2.6 [GNN]() - 5.3 [(Gated Graph Neural Network)]() - 5.3.1 - 5.3.2 1: - 5.3.3 2: - 5.3.4 GNNGGNN - 5.4 [(GCNN)](https://www.cnblogs.com/SivilTaram/p/graph_neural_network_2.html) - 5.4.1 - 5.4.2 (Framework) - 5.4.3 - 5.4.4 (Spatial Convolution) - 5.4.5 (Message Passing Neural Network) - 5.4.6 (Graph Sample and Aggregate) - 5.4.7 (PATCHY-SAN) - 5.4.8 (Spectral Convolution) - 5.5 [](https://www.cnblogs.com/SivilTaram/p/graph_neural_network_3.html) - 5.5.1 (ReadOut) - 5.5.2 (Statistics Category) - 5.5.3 (Learning Category) - 5.5.4 - 5.6 [](https://www.cnblogs.com/SivilTaram/p/graph_neural_network_3.html) - 5.6.1 [](https://arxiv.org/abs/1904.03751) - 5.6.2 [](https://openreview.net/forum?id=SJeXSo09FQ) - 5.6.3 [RGBD](https://www.cs.toronto.edu/~urtasun/publications/qi_etal_iccv17.pdf) - 5.6.4 [VQA](https://visualqa.org/) - 5.6.5 [ZSL](https://arxiv.org/pdf/1803.08035.pdf) - - - 5 [](/notebooks/) - 5.1 [](/notebooks/) - 5.2 [](/notebooks/) - 5.3 [](/notebooks/) - 5.4 [](/notebooks/) - 5.5 [](/notebooks/) - - - 6 [](/notebooks/chapter07_optimization/) - 6.1 [](/notebooks/chapter07_optimization/7.1_optimization-intro.ipynb) - 6.2 [](/notebooks/chapter07_optimization/7.2_gd-sgd.ipynb) - 6.3 [](/notebooks/chapter07_optimization/7.3_minibatch-sgd.ipynb) - 6.4 [](/notebooks/chapter07_optimization/7.4_momentum.ipynb) - 6.5 [AdaGrad](/notebooks/chapter07_optimization/7.5_adagrad.ipynb) - 6.6 [RMSProp](/notebooks/chapter07_optimization/7.6_rmsprop.ipynb) - 6.7 [AdaDelta](/notebooks/chapter07_optimization/7.7_adadelta.ipynb) - 6.8 [Adam](/notebooks/chapter07_optimization/7.8_adam.ipynb) - - - - 6 [](https://charmve.github.io/computer-vision-in-action/#/chapter6/chapter6) - 6.1 [](docs/2_/chapter6_/chapter6.1_.md) - 6.2 [Pytorch ](docs/2_/chapter6_/chapter6.2_Pytorch-.md) - 6.2.1 [Tensors](docs/2_/chapter6_/chapter6.2_Pytorch-.md#621-tensors) - 6.2.2 [Operations](docs/2_/chapter6_/chapter6.2_Pytorch-.md#622-operations) - 6.2.3 [Numpy](docs/2_/chapter6_/chapter6.2_Pytorch-.md#623-numpy) - 6.2.4 [CUDA Tensors](docs/2_/chapter6_/chapter6.2_Pytorch-.md#624-cuda-tensors) - 6.3 [Python](./notebooks/chapter08_environment-setup-and-tool-use/02_Python.ipynb) - 6.4 [Numpy ](./notebooks/chapter08_environment-setup-and-tool-use/03_NumPy.ipynb) - 6.5 [Pandas ](./notebooks/chapter08_environment-setup-and-tool-use/04_Pandas.ipynb) - 6.6 [OpenCV ](./notebooks/chapter08_environment-setup-and-tool-use/OpenCV-ImageStitching.ipynb) - 6.7 [Jupyter Notebook ](./notebooks/chapter08_environment-setup-and-tool-use/01_Notebooks.ipynb) - 6.8 [](docs/2_/chapter6_/chapter6.8_.md) - 6.8.1 [PILPython](docs/2_/chapter6_/chapter6.8_.md#781-pil-python) - 6.8.2 [Matplotlib](docs/2_/chapter6_/chapter6.8_.md#782-matplotlib) - 6.8.3 [NumPy](docs/2_/chapter6_/chapter6.8_.md#783-numpy) - 6.8.4 [SciPy](docs/2_/chapter6_/chapter6.8_.md#784-scipy) - 6.8.5 [](docs/2_/chapter6_/chapter6.8_.md#785--) - 6.9 [ 5 - OpenCV](https://blog.csdn.net/Charmve/article/details/107897468) - - - 7 [PyTorch](https://github.com/Charmve/Semantic-Segmentation-PyTorch) - 7.1 [LeNet](docs/2_/chapter7_-PyTorch/7.1%20LeNet.md) - 7.2 [AlexNet](docs/2_/chapter7_-PyTorch/7.2%20AlexNet.md) - 7.3 [VGG](docs/2_/chapter7_-PyTorch/7.3%20VGG.md) - 7.4 [GoogLeNet](docs/2_/chapter7_-PyTorch/7.4%20GoogLeNet.md) - 7.5 [ResNet](docs/2_/chapter7_-PyTorch/chapter7.6_-ResNet.md) - 7.6 [U-Net](docs/2_/chapter7_-PyTorch/chapter7.7_-UNet.md) - 7.7 [DenseNet](docs/2_/chapter7_-PyTorch/chapter7.8_-DenseNet.md) - 7.8 [SegNet](docs/2_/chapter7_-PyTorch/chapter7.9_-SegNet.md) - 7.9 [Mask-RCNN](docs/2_/chapter7_-PyTorch/chapter7.9_-Mask-RCNN.md) - 7.10 [R-CNN](docs/2_/chapter7_-PyTorch/chapter7.10_-RCNN.md) - 7.11 [FCN](docs/2_/chapter7_-PyTorch/chapter7.11_-FCN.md) - 7.12 [YOLO: ](https://pjreddie.com/darknet/yolo/) - - - 8 [](docs/2_/chapter8_) - 8.1 [](/docs/2_/chapter8_/chapter8.1_.md) - 8.1.1 [](/docs/2_/chapter8_/chapter8.1_.md#811-) - 8.1.1.1 [ImageNet](https://image-net.org/) - 8.1.1.2 [MNIST](http://yann.lecun.com/exdb/mnist/) - 8.1.1.3 [COCO](https://cocodataset.org/) - 8.1.1.4 [CIFAR-10](http://www.cs.toronto.edu/~kriz/cifar.html) - 8.1.2 [Pytorch](/docs/2_/chapter8_/chapter8.1_.md#812-pytorch) - 8.1.3 [](/docs/2_/chapter8_/chapter8.1_.md#813-) - [](/docs/2_/chapter8_/chapter8.1_.md#) - 8.2 [](/docs/2_/chapter8_/chapter8.2_BenchMark.md) - 8.3 [](/chapter8.3_.md) - 8.4 [ 6 - KaggleCIFAR-10](docs/2_/chapter7_-PyTorch/7.12%20KaggleCIFAR-10.md) - 8.5 [ 7 - KaggleImageNet Dogs](docs/2_/chapter7_-PyTorch/7.13%20KaggleImageNet%20Dogs.md) - - - 9 [](https://charmve.github.io/computer-vision-in-action/#/chapter9/chapter9) - 9.1 - 9.1.1 [ PyTorch ](https://github.com/Charmve/Semantic-Segmentation-PyTorch) - 9.1.2 [ 8 - PolarNet]() - 9.2 - 9.2.1 - 9.2.2 [ 9 - PyTorchYOLO5]() - 9.3 [](/docs/2_/chapter9_/9.3%20.md) - 9.3.1 [](/docs/2_/chapter9_/9.3%20.md#931-) - 9.3.2 [ 10 - ](/docs/2_/chapter9_/9.3%20.md#932--8-) - 9.3.3 [](https://blog.csdn.net/Charmve/article/details/108915225), [PointRend](https://blog.csdn.net/Charmve/article/details/108892076), [PolarMask](https://github.com/xieenze/PolarMask) - - - 10 [](https://charmve.github.io/computer-vision-in-action/#/chapter10/chapter10) - 10.1 [](https://blog.csdn.net/Charmve/article/details/108531735) - 10.2 [](https://github.com/Charmve/Scene-Text-Detection) - 10.3 [](https://github.com/Charmve/Awesome-Lane-Detection) - 10.3.1 [](https://github.com/Charmve/Awesome-Lane-Detection) - 10.3.2 [ 11 - ](https://blog.csdn.net/Charmve/article/details/116678477) - 10.4 [](https://github.com/Charmve/Mirror-Glass-Detection) - 10.5 [ Matting](/docs/2_/chapter10_/charpter10_5-.md) - 10.6 [](/docs/2_/chapter10_/charpter10_6-.md) - 10.7 [3D ](/docs/2_/chapter10_/charpter10_7-3D.md) - - - - 11 [](/docs/3_/chapter11-/) - 11.1 - 11.2 - 11.3 - 11.4 [Embeddings](https://nbviewer.jupyter.org/format/slides/github/Charmve/computer-vision-in-action/blob/main/notebooks/chapter13_Understanding-and-Visualizing/Embeddings.ipynb) - 11.5 - 11.6 [DeepDream ](/docs/3_/chapter12-/chapter12.3.3_neural-style.md) - 11.7 [ 12: PyTorch TensorBoard](/docs/3_/chapter11-/chapter11-.md) - 11.4.1 [ TensorBoard](/docs/3_/chapter11-/chapter11-.md#1141--tensorboard) - 11.4.2 [ TensorBoard](/docs/3_/chapter11-/chapter11-.md#1142--tensorboard) - 11.4.3 [ TensorBoard ](/docs/3_/chapter11-/chapter11-.md#1143--tensorboard-) - 11.4.4 [ TensorBoard "Projector"](/docs/3_/chapter11-/chapter11-.md#1144--tensorboard--projector) - 11.4.5 [ TensorBoard ](/docs/3_/chapter11-/chapter11-.md#1145--tensorboard-) - 11.4.6 [ TensorBoard ](/docs/3_/chapter11-/chapter11-.md#1146--tensorboard-) - 11.4.7 [](/docs/3_/chapter11-/chapter11-.md#) - - - 12 [](https://charmve.github.io/computer-vision-in-action/#/chapter6/chapter6) - 12.1 Pixel RNN/CNN - 12.2 [ Auto-encoder](/docs/3_/chapter12-/chapter12_2-Auto-encoder.md) - 12.3 [ GAN](/docs/3_/chapter12-/chapter12.3_GAN.md) - 12.3.1 [](/docs/3_/chapter12-/chapter12.3_GAN.md#1231-) - 12.3.2 [GAN](/docs/3_/chapter12-/chapter12.3_GAN.md#1232-gan) - 12.3.3 [GAN](/docs/3_/chapter12-/chapter12.3_GAN.md#1233-gan) - 12.3.3.1 [GAN](/docs/3_/chapter12-/chapter12.3_GAN.md#12331-gan) - 12.3.3.2 [GAN](/docs/3_/chapter12-/chapter12.3_GAN.md#12332-gan) - [](/docs/3_/chapter12-/chapter12.3_GAN.md#) - [](/docs/3_/chapter12-/chapter12.3_GAN.md#) - [](/docs/3_/chapter12-/chapter12.3_GAN.md#) - 12.3.4 [](/docs/3_/chapter12-/chapter12.3_GAN.md#1234) - 12.3.5 StyleGAN - [StyleGAN](https://github.com/Charmve/VOGUE-Try-On) - [StyleGAN 2.0](https://blog.csdn.net/Charmve/article/details/115315353) - 12.3.6 [11 - ](/docs/3_/chapter12-/chapter12.3.3_neural-style.md) - [](/docs/3_/chapter12-/chapter12.3_GAN.md#) - [](/docs/3_/chapter12-/chapter12.3_GAN.md#) - 12.4 [ Variational Auto-encoder, VAE](docs/3_/chapter12-/chapter12_4-VAE.md) - 12.4.1 [](docs/3_/chapter12-/chapter12_4-VAE.md#1241-) - 12.4.2 [](docs/3_/chapter12-/chapter12_4-VAE.md#1242-) - 12.4.2.1 [](docs/3_/chapter12-/chapter12_4-VAE.md#1-) - 12.4.2.2 [](docs/3_/chapter12-/chapter12_4-VAE.md#2-) - 12.4.2.3 [](docs/3_/chapter12-/chapter12_4-VAE.md#3-) - 12.4.3 [VAE v.s. AE ](docs/3_/chapter12-/chapter12_4-VAE.md#1243-vae-vs-ae-) - 12.4.4 [](docs/3_/chapter12-/chapter12_4-VAE.md#1244-) - 12.4.5 [](docs/3_/chapter12-/chapter12_4-VAE.md#1245-) - 12.4.6 [ 13 - ](https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life) - - [](docs/3_/chapter12-/chapter12_4-VAE.md#) - - 13 [](/docs/3_/chapter13-/chapter13-.md) - 13.1 [-](/docs/3_/chapter13-/chapter13-.md#141--) - 13.2 [](/docs/3_/chapter13-/chapter13-.md#142-) - 13.2.1 [](/docs/3_/chapter13-/chapter13-.md#1421-) - 13.2.2 [](/docs/3_/chapter13-/chapter13-.md#1422-) - 13.2.3 [](/docs/3_/chapter13-/chapter13-.md#1423-) - 13.3 [](/docs/3_/chapter13-/chapter13-.md#143-) - 13.3.1 [Policy-based DRL](/docs/3_/chapter13-/chapter13-.md#1431-policy-based-drl) - 13.3.2 [Value-based DRL](/docs/3_/chapter13-/chapter13-.md#1432-value-based-drl) - 13.3.3 [Model-based DRL](/docs/3_/chapter13-/chapter13-.md#1433-model-based-drl) - 13.4 [](#144-) - [](/docs/3_/chapter13-/chapter13-.md#) - [](/docs/3_/chapter13-/chapter13-.md#) - 14 [](/docs/3_/chapter14-/chapter14-.md) - 14.1 [](/docs/3_/chapter14-/chapter14-.md#141-) - 14.2 [](/docs/3_/chapter14-/chapter14-.md#142-) - 14.3 [](/docs/3_/chapter14-/chapter14-.md#143-) - 14.4 [](/docs/3_/chapter14-/chapter14-.md#144-) - 14.5 [ METRICS](/docs/3_/chapter14-/chapter14-.md#145--metrics) - 14.6 [](/docs/3_/chapter14-/chapter14-.md#146-) - [](/docs/3_/chapter14-/chapter14-.md#) - [](/docs/3_/chapter14-/chapter14-.md#) - 15 [](./docs/3_/chapter15_) - 15.1 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#151-) - 15.1.1 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#1511-) - 15.1.2 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#1512-) - 15.1.3 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#1513-) - 15.2 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#152-) - 15.3 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#153-) - 15.4 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#154-) - 15.5 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#155-) - 15.7 [ 14 - ](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md) - 15.7.1 [](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#1571-) - 15.7.2 [: ](https://github.com/Charmve/computer-vision-in-action/tree/main/docs/3_/chapter15_/chapter15_.md#1572--) - [](#) - [](#) - 16 [ Attention is All You Need](./notebooks/chapter16_Attention/1_Attention.ipynb) - 16.1 - 16.2 Attention with RNNs - 16.3 [Self-attention ](https://mp.weixin.qq.com/s/nUd7YtCci1_AwQ4nOwK9bA) - 16.4 soft-attention - 16.4.1 - 16.4.2 - 16.4.3 Positional encoding - 16.4.4 - 16.4.5 Masked attention - 16.4.6 Multi-head attention - 16.5 hard attention - 16.6 [Attention - ](/docs/3_/chapter16-%20Attention%20is%20All%20You%20Need/chapter16_Attention-is-All-You-Need.md) - - - 17 [ Transformer](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md) - 17.1 [](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#%E4%B8%80%E6%80%9D%E6%83%B3%E5%92%8C%E6%A1%86%E5%9B%BE) - 17.2 [](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#) - [17.2.1 Encoder](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#2-1-Encoder) - [17.2.2 Decoder](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#2-2-Decoder) - [17.2.3 Self-Attention](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#2-3-Self-Attention) - [17.2.4 Multi-Headed Attention](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#2-4-Multi-Headed-Attention) - [17.2.5 Positional Encoding](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#2-5-Positional-Encoding) - 17.3 [](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#-) - 17.3.1 [NLP](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#3-1-NLP) - 17.3.2 [CV](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#3-2-CV) - 17.3.2.1 [DETR](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#3-2-1-DETR) - 17.3.2.2 [ViT](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#3-2-2-ViT) - 17.3.2.3 [SETR](https://github.com/Charmve/computer-vision-in-action/blob/main/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#3-2-3-SETR) - 17.3.2.4 [Deformable-DETR](https://github.com/Charmve/computer-vision-in-action/blob/main/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#3-2-4-Deformable-DETR) - 17.4 [](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#-) - 17.5 [](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#-) - [ 15 - TransformerVisTR (CVPR2021)](https://blog.csdn.net/Charmve/article/details/115339803) - - [](/docs/3_%E8%BF%9B%E9%98%B6%E7%AF%87/chapter17-%E8%B7%A8%E7%95%8C%E6%A8%A1%E5%9E%8B%20Transformer/chapter17_Transformer.md#-) - 18 [](https://mp.weixin.qq.com/s/e3c_-rs2rncmWhbm-cU5rA) - 18.1 - 18.2 KD - 18.2.1 Logits(Response)-based Knowledge - 18.2.2 Feature-based Knowledge - 18.2.3 Relation-based Knowledge - 18.3 NLP-BERT - 18.4 - [ 16 - CVPR](https://mp.weixin.qq.com/s/RTkBQJ7Uj86Wxt7HmwWKzA) - - [](#) - 19 [Normalization ](https://blog.csdn.net/Charmve/article/details/107650487) - 19.1 Mini-Batch SGD - 19.2 Normalization - 19.3 Batch Normalization - 19.3.1 BN - 19.3.2 CNNBN - 19.3.3 Batch Norm - 19.4 Layer NormalizationInstance NormalizationGroup Normalization - 19.4.1 Layer Normalization - 19.4.2 Instance Normalization - 19.4.3 Group Normalization - 19.4.4 - 19.5 NormalizationRe-Scaling - 19.6 Batch Normalization - - [](#) - 20 [](https://mp.weixin.qq.com/s/e3c_-rs2rncmWhbm-cU5rA) - 20.1 - 20.2 - 20.2.1 1990~2014 - - 20.2.2 1989~2014 - - 20.2.3 2016 - - 20.2.4 - 20.2.5 2014- - 20.3 - 20.3.1 Op-Level - 20.3.2 Layer0-level - 20.3.3 - CPUGPUNPU - ASIC FPGA - PIMNDP - 20.4 - 20.4.1 TensorRT Nvidia) - 20.4.2 TVM (Tensor Virtual Machine) - 20.4.3 Tensor Comprehension (Facebook) - 20.4.4 Distiller (Intel) - - [](#-) - - A - B [](https://mp.weixin.qq.com/s?__biz=MzIxMjg1Njc3Mw==&mid=2247484495&idx=1&sn=0bbb2094d93169baf20eedb284bc668f) - C [](https://blog.csdn.net/Charmve/article/details/106089198) - D [](https://blog.csdn.net/Charmve/article/details/107650479) -[](/docs/book_postscript.md)-[](#-1)- ... [](#-) |
docs/ 1 code/ 2 Colab notebooks/ 3
L0CV/-L0CVcode/-datasets/-
images/-docs/-
0_/-1_/-2_/-3_/- CV/-img/-models/-notebooks/- Colab notebook
chapter01_neural-networks/- 1 - Jupyter Notebookchapter02_CNN/- 2 - Jupyter Notebookchapter03_Image-Classification- 3 - Jupyter Notebookchapter04_recurrent-neural-networks/- 4 - Jupyter Notebookchapter05_graph-neural-network/- 5 - Jupyter Notebookchapter07_optimization/- 6 - Jupyter Notebookchapter08_environment-setup-and-tool-use/- 7 - Jupyter Notebookchapter09_convolutional-neural-networks/- 8 - PyTorch Jupyter Notebookchapter12_practice-projects- 12 - Jupyter Notebookchapter13_Understanding-and-Visualizing/- 13 - Jupyter Notebookchapter14_GAN/- 14 - Jupyter Notebookchapter15_Transfer-Learning/- 15 - Jupyter Notebookchapter16_Attention/- 16 - Jupyter Notebookchapter17_Transformers/- 17 - Transformers Jupyter Notebook- ...
imgs/- Jupyter Notebookdocker/-res/- ui PDFREADME.md-
L0CV DemoDay

![]()

|

|

|

|

|

|
V1.2 *

| | | Binder | Google Colab |
| :-- | :---| :---:| :---: |
| 1 - | 1 - | | |
| 2 - | 2 - | | |
| 3 - | 3 - | | |
| 4 - CIFAR10 | 3 - | | |
| 5 - OpenCV | 6 - | ![]() |
| ![]() |
| 6 - KaggleCIFAR-10 | 8 - |
|
| 6 - KaggleCIFAR-10 | 8 - | ![]() |
| ![]() |
| 7 - KaggleImageNet Dogs | 8 - |
|
| 7 - KaggleImageNet Dogs | 8 - | ![]() |
| ![]() |
| 8 - PolarNet | 9 - || |
| 9 - PyTorchYOLO5 | 9 - || |
| 10 - | 9 - || |
| 11 - | 10 - | | |
| 12 - PyTorch TensorBoard | 13 - | | |
| 13 - | 14 |
|
| 8 - PolarNet | 9 - || |
| 9 - PyTorchYOLO5 | 9 - || |
| 10 - | 9 - || |
| 11 - | 10 - | | |
| 12 - PyTorch TensorBoard | 13 - | | |
| 13 - | 14 | ![]() |
| ![]() |
| 14 - | 14 - |
|
| 14 - | 14 - | ![]() |
| ![]() |
| 15 - | 14 - |
|
| 15 - | 14 - | ![]() |
| ![]() |
| 16 - SlowFast + Multi-Moments in Time | 16 - |
|
| 16 - SlowFast + Multi-Moments in Time | 16 - | ![]() |
| ![]() |
| 17 - | 17 - |
|
| 17 - | 17 - | ![]() |
| ![]() |
| 18 - TransformerVisTR (CVPR2021) | 19 - Transformer | | |
| 19 - CVPR| 20 - | | |
| ... | ... | ... |
|
| 18 - TransformerVisTR (CVPR2021) | 19 - Transformer | | |
| 19 - CVPR| 20 - | | |
| ... | ... | ... |
### Jupyter Notebook ( ) #### 1. - ``` pip3 install -r requirements.txt ``` - Jupyter ``` python3 -m pip install --upgrade pip python3 -m pip install jupyter ``` - jupyter Mac / LinuxWindows ```shell cd notebooks jupyter notesbook ``` #### 2. -


2 12.3.3

3 12.3.3 Colab ![]()
[](#-)
|


+ + |
||

|
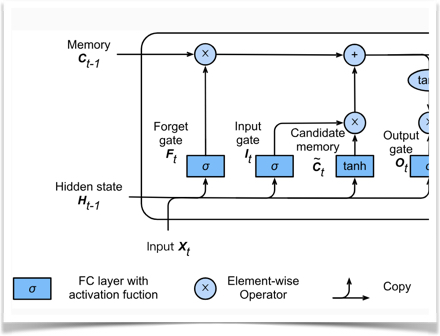
|

|
host
: host


GitHubMarkdownLATEXChrome
MathJax Plugin for GithubdocsdocsifyGitHub Pagesclonecode
*Jupyter Notebook GitHub * nbviewer
![]()
![]()
![]()
![]()
LICENSE
L0CVApache 2.0 L0CV/code/notebook- ****
- ****
Apache 2.0
L0CV4.0- ****
- ****
- **** 4.0
Q&AL0CVtag
#L0CVL0CV (Yida_Zhang2L0CV-/-)
Support this project
Donating to help me continue working on this project. I'm appreciate all you in backer list. ![]()

CONTRIBUTION
Help us make these docs great!All VC-action docs are open source. See something that's wrong or unclear? Submit a pull request. Make a contribution |
Citation
Use this bibtex to cite this repository:
@misc{computer-vision-in-action,
title={Computer Vision in Action},
author={Charmve},
year={2021.06},
publisher={Github},
journal={GitHub repository},
howpublished={\url{https://github.com/Charmve/computer-vision-in-action}},
}
Stargazers Over Time
Awesome! Charmve/computer-vision-in-action was created 2 months ago and now has 1546 stars.


Feel free to ask any questions, open a PR if you feel something can be done differently!
Star this repository
Created by Charmve & maiwei.ai Community | Deployed on GitHub Page
Owner
- Name: Wei ZHANG
- Login: Charmve
- Kind: user
- Location: Suzhou, Beijing, Shanghai, Hongkong
- Company: 公众号: 迈微AI研习社
- Website: charmve.github.io
- Repositories: 80
- Profile: https://github.com/Charmve
Founder of @MaiweiAI Lab, @UFund-Me and @DeepVTuber. My research interests lie at AI Infra, Machine Learning and Computer Vision.
GitHub Events
Total
- Watch event: 234
- Issue comment event: 5
- Fork event: 27
Last Year
- Watch event: 234
- Issue comment event: 5
- Fork event: 27
Committers
Last synced: about 1 year ago
Top Committers
| Name | Commits | |
|---|---|---|
| Wei ZHANG | y****1@g****m | 516 |
| Charmve | z****3@3****n | 57 |
| 张益达 | z****a@z****l | 1 |
| xetdata[bot] | 1****] | 1 |
Committer Domains (Top 20 + Academic)
360.cn: 1
Issues and Pull Requests
Last synced: about 1 year ago
All Time
- Total issues: 75
- Total pull requests: 1
- Average time to close issues: 4 days
- Average time to close pull requests: N/A
- Total issue authors: 11
- Total pull request authors: 1
- Average comments per issue: 0.64
- Average comments per pull request: 0.0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 0
- Pull requests: 0
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Issue authors: 0
- Pull request authors: 0
- Average comments per issue: 0
- Average comments per pull request: 0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
- Charmve (65)
- wyyaa123 (1)
- YJHnu (1)
- jinzhedu (1)
- yuan243212790 (1)
- fyzm (1)
- Zhong-master (1)
- DoveJing (1)
- ezio1320 (1)
- jackiehym (1)
- XiaYuanxiang (1)
Pull Request Authors
- TrellixVulnTeam (1)
Top Labels
Issue Labels
Gitalk (63)
chapter0.1_概述 (3)
📑/README (3)
👐 open-question (3)
chapter0.3_发展历史回顾 (2)
📑 /book_preface (2)
book_preface (2)
📁 documentation (2)
chapter0.2_基本概念辨析 (2)
📘 book (2)
🏇wontfix (2)
README (2)
🐞 bug (2)
📑 /0_绪论/README (2)
chapter0.4_典型的计算机视觉任务 (1)
chapter3.2_knn (1)
REFERENCE (1)
chapter2_CNN-in-Action (1)
chapter13-深度增强学习 (1)
chapter8.1_著名数据集 (1)
7.1 卷积神经网络(LeNet) (1)
chapter1.4_Back-Propagation (1)
chapter2_CNN (1)
chapter14-视频理解 (1)
📑 /1_理论篇/chapter2_CNN/README (1)
📚 书籍推荐 (1)
👽 interesting things (1)
🐍Python (1)
chapter0.1_%E6%A6%82%E8%BF%B0 (1)
home (1)
Pull Request Labels
Dependencies
.github/workflows/codeql-analysis.yml
actions
- actions/checkout v2 composite
- github/codeql-action/analyze v1 composite
- github/codeql-action/autobuild v1 composite
- github/codeql-action/init v1 composite