vitpose
The official repo for [NeurIPS'22] "ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation" and [TPAMI'23] "ViTPose++: Vision Transformer for Generic Body Pose Estimation"
Science Score: 54.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Committers with academic emails
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (6.4%) to scientific vocabulary
Keywords
Repository
The official repo for [NeurIPS'22] "ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation" and [TPAMI'23] "ViTPose++: Vision Transformer for Generic Body Pose Estimation"
Basic Info
Statistics
- Stars: 1,614
- Watchers: 21
- Forks: 208
- Open Issues: 105
- Releases: 0
Topics
Metadata Files
README.md
ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
![]()
![]()
![]()
![]()
Results | Updates | Usage | Todo | Acknowledge


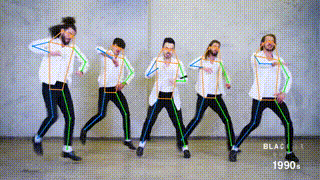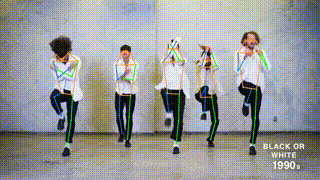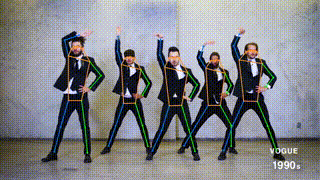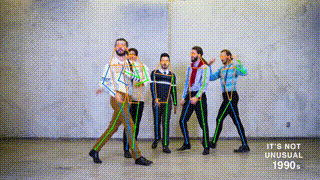
This branch contains the pytorch implementation of ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation and ViTPose+: Vision Transformer Foundation Model for Generic Body Pose Estimation. It obtains 81.1 AP on MS COCO Keypoint test-dev set.

Web Demo
- Integrated into Huggingface Spaces 🤗 using Gradio. Try out the Web Demo for video:
and images
MAE Pre-trained model
- The small size MAE pre-trained model can be found in Onedrive.
- The base, large, and huge pre-trained models using MAE can be found in the MAE official repo.
Results from this repo on MS COCO val set (single-task training)
Using detection results from a detector that obtains 56 mAP on person. The configs here are for both training and test.
With classic decoder
| Model | Pretrain | Resolution | AP | AR | config | log | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-S | MAE | 256x192 | 73.8 | 79.2 | config | log | Onedrive | | ViTPose-B | MAE | 256x192 | 75.8 | 81.1 | config | log | Onedrive | | ViTPose-L | MAE | 256x192 | 78.3 | 83.5 | config | log | Onedrive | | ViTPose-H | MAE | 256x192 | 79.1 | 84.1 | config | log | Onedrive |
With simple decoder
| Model | Pretrain | Resolution | AP | AR | config | log | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-S | MAE | 256x192 | 73.5 | 78.9 | config | log | Onedrive | | ViTPose-B | MAE | 256x192 | 75.5 | 80.9 | config | log | Onedrive | | ViTPose-L | MAE | 256x192 | 78.2 | 83.4 | config | log | Onedrive | | ViTPose-H | MAE | 256x192 | 78.9 | 84.0 | config | log | Onedrive |
Results with multi-task training
Note * There may exist duplicate images in the crowdpose training set and the validation images in other datasets, as discussed in issue #24. Please be careful when using these models for evaluation. We provide the results without the crowpose dataset for reference.
Human datasets (MS COCO, AIC, MPII, CrowdPose)
Results on MS COCO val set
Using detection results from a detector that obtains 56 mAP on person. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII | 256x192 | 77.1 | 82.2 | config | Onedrive | | ViTPose-L | COCO+AIC+MPII | 256x192 | 78.7 | 83.8 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII | 256x192 | 79.5 | 84.5 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII | 576x432 | 81.0 | 85.6 | | | | ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 77.5 | 82.6 | config |Onedrive | | ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.1 | 84.1 | config | Onedrive | | ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.8 | 84.8 | config | Onedrive | | ViTPose+-S | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.8 | 82.6 | config | log | Onedrive | | ViTPose+-B | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 77.0 | 82.6 | config | log | Onedrive | | ViTPose+-L | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.6 | 84.1 | config | log | Onedrive | | ViTPose+-H | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 79.4 | 84.8 | config | log | Onedrive |
Results on OCHuman test set
Using groundtruth bounding boxes. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII | 256x192 | 88.0 | 89.6 | config | Onedrive | | ViTPose-L | COCO+AIC+MPII | 256x192 | 90.9 | 92.2 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII | 256x192 | 90.9 | 92.3 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII | 576x432 | 93.3 | 94.3 | | | | ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 88.2 | 90.0 | config |Onedrive | | ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.5 | 92.8 | config | Onedrive | | ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.6 | 92.8 | config | Onedrive | | ViTPose+-S | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.4 | 80.6 | config | log | Onedrive | | ViTPose+-B | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.6 | 84.8 | config | log | Onedrive | | ViTPose+-L | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.5 | config | log | Onedrive | | ViTPose+-H | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.4 | config | log | Onedrive |
Results on MPII val set
Using groundtruth bounding boxes. Note the configs here are only for evaluation. The metric is PCKh.
| Model | Dataset | Resolution | Mean | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII | 256x192 | 93.3 | config | Onedrive | | ViTPose-L | COCO+AIC+MPII | 256x192 | 94.0 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII | 256x192 | 94.1 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII | 576x432 | 94.3 | | | | ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.4 | config |Onedrive | | ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.9 | config | Onedrive | | ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 94.1 | config | Onedrive | | ViTPose+-S | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.7 | config | log | Onedrive | | ViTPose+-B | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.8 | config | log | Onedrive | | ViTPose+-L | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.0 | config | log | Onedrive | | ViTPose+-H | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.2 | config | log | Onedrive |
Results on AI Challenger test set
Using groundtruth bounding boxes. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B | COCO+AIC+MPII | 256x192 | 32.0 | 36.3 | config | Onedrive | | ViTPose-L | COCO+AIC+MPII | 256x192 | 34.5 | 39.0 | config | Onedrive | | ViTPose-H | COCO+AIC+MPII | 256x192 | 35.4 | 39.9 | config | Onedrive | | ViTPose-G | COCO+AIC+MPII | 576x432 | 43.2 | 47.1 | | | | ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 31.9 | 36.3 | config |Onedrive | | ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 34.6 | 39.0 | config | Onedrive | | ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 35.3 | 39.8 | config | Onedrive | | ViTPose+-S | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 29.7 | 34.3 | config | log | Onedrive | | ViTPose+-B | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 31.8 | 36.3 | config | log | Onedrive | | ViTPose+-L | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.3 | 38.9 | config | log | Onedrive | | ViTPose+-H | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.8 | 39.1 | config | log | Onedrive |
Results on CrowdPose test set
Using YOLOv3 human detector. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AP(H) | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 74.7 | 63.3 | config |Onedrive | | ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.6 | 65.9 | config | Onedrive | | ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.3 | 65.6 | config | Onedrive |
Animal datasets (AP10K, APT36K)
Results on AP-10K test set
| Model | Dataset | Resolution | AP | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose+-S | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 71.4 | config | log | Onedrive | | ViTPose+-B | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.5 | config | log | Onedrive | | ViTPose+-L | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.4 | config | log | Onedrive | | ViTPose+-H | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.4 | config | log | Onedrive |
Results on APT-36K val set
| Model | Dataset | Resolution | AP | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose+-S | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.2 | config | log | Onedrive | | ViTPose+-B | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.9 | config | log | Onedrive | | ViTPose+-L | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.8 | config | log | Onedrive | | ViTPose+-H | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.3 | config | log | Onedrive |
WholeBody dataset
| Model | Dataset | Resolution | AP | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose+-S | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 54.4 | config | log | Onedrive | | ViTPose+-B | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 57.4 | config | log | Onedrive | | ViTPose+-L | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 60.6 | config | log | Onedrive | | ViTPose+-H | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 61.2 | config | log | Onedrive |
Transfer results on the hand dataset (InterHand2.6M)
| Model | Dataset | Resolution | AUC | config | weight | | :----: | :----: | :----: | :----: | :----: | :----: | | ViTPose+-S | COCO+AIC+MPII+WholeBody | 256x192 | 86.5 | config | Coming Soon | | ViTPose+-B | COCO+AIC+MPII+WholeBody | 256x192 | 87.0 | config | Coming Soon | | ViTPose+-L | COCO+AIC+MPII+WholeBody | 256x192 | 87.5 | config | Coming Soon | | ViTPose+-H | COCO+AIC+MPII+WholeBody | 256x192 | 87.6 | config | Coming Soon |
Updates
[2023-01-10] Update ViTPose+! It uses MoE strategies to jointly deal with human, animal, and wholebody pose estimation tasks.
[2022-05-24] Upload the single-task training code, single-task pre-trained models, and multi-task pretrained models.
[2022-05-06] Upload the logs for the base, large, and huge models!
[2022-04-27] Our ViTPose with ViTAE-G obtains 81.1 AP on COCO test-dev set!
Applications of ViTAE Transformer include: image classification | object detection | semantic segmentation | animal pose segmentation | remote sensing | matting | VSA | ViTDet
Usage
We use PyTorch 1.9.0 or NGC docker 21.06, and mmcv 1.3.9 for the experiments.
bash
git clone https://github.com/open-mmlab/mmcv.git
cd mmcv
git checkout v1.3.9
MMCV_WITH_OPS=1 pip install -e .
cd ..
git clone https://github.com/ViTAE-Transformer/ViTPose.git
cd ViTPose
pip install -v -e .
After install the two repos, install timm and einops, i.e.,
bash
pip install timm==0.4.9 einops
After downloading the pretrained models, please conduct the experiments by running
```bash
for single machine
bash tools/dist_train.sh
for multiple machines
python -m torch.distributed.launch --nnodes
To test the pretrained models performance, please run
bash
bash tools/dist_test.sh <Config PATH> <Checkpoint PATH> <NUM GPUs>
For ViTPose+ pre-trained models, please first re-organize the pre-trained weights using
bash
python tools/model_split.py --source <Pretrained PATH>
Todo
This repo current contains modifications including:
[x] Upload configs and pretrained models
[x] More models with SOTA results
[x] Upload multi-task training config
Acknowledge
We acknowledge the excellent implementation from mmpose and MAE.
Citing ViTPose
For ViTPose
@inproceedings{
xu2022vitpose,
title={Vi{TP}ose: Simple Vision Transformer Baselines for Human Pose Estimation},
author={Yufei Xu and Jing Zhang and Qiming Zhang and Dacheng Tao},
booktitle={Advances in Neural Information Processing Systems},
year={2022},
}
For ViTPose+
@article{xu2022vitpose+,
title={ViTPose+: Vision Transformer Foundation Model for Generic Body Pose Estimation},
author={Xu, Yufei and Zhang, Jing and Zhang, Qiming and Tao, Dacheng},
journal={arXiv preprint arXiv:2212.04246},
year={2022}
}
For ViTAE and ViTAEv2, please refer to: ``` @article{xu2021vitae, title={Vitae: Vision transformer advanced by exploring intrinsic inductive bias}, author={Xu, Yufei and Zhang, Qiming and Zhang, Jing and Tao, Dacheng}, journal={Advances in Neural Information Processing Systems}, volume={34}, year={2021} }
@article{zhang2022vitaev2, title={ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond}, author={Zhang, Qiming and Xu, Yufei and Zhang, Jing and Tao, Dacheng}, journal={arXiv preprint arXiv:2202.10108}, year={2022} } ```
Owner
- Name: ViTAE-Transformer
- Login: ViTAE-Transformer
- Kind: organization
- Repositories: 10
- Profile: https://github.com/ViTAE-Transformer
Citation (CITATION.cff)
cff-version: 1.2.0 message: "If you use this software, please cite it as below." authors: - name: "MMPose Contributors" title: "OpenMMLab Pose Estimation Toolbox and Benchmark" date-released: 2020-08-31 url: "https://github.com/open-mmlab/mmpose" license: Apache-2.0
GitHub Events
Total
- Issues event: 11
- Watch event: 338
- Issue comment event: 44
- Pull request event: 2
- Fork event: 30
Last Year
- Issues event: 11
- Watch event: 338
- Issue comment event: 44
- Pull request event: 2
- Fork event: 30
Committers
Last synced: about 1 year ago
Top Committers
| Name | Commits | |
|---|---|---|
| Yufei | a****s@g****m | 15 |
| seaman1900 | 4****0 | 1 |
| AK391 | 8****1 | 1 |
Issues and Pull Requests
Last synced: 10 months ago
All Time
- Total issues: 115
- Total pull requests: 10
- Average time to close issues: about 2 months
- Average time to close pull requests: 9 days
- Total issue authors: 98
- Total pull request authors: 8
- Average comments per issue: 1.9
- Average comments per pull request: 0.9
- Merged pull requests: 2
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 14
- Pull requests: 5
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Issue authors: 13
- Pull request authors: 3
- Average comments per issue: 0.5
- Average comments per pull request: 1.0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
- gsrujana (4)
- Lingyun97 (4)
- EEWenbinWu (3)
- hotelbread (3)
- afsharshamsi (2)
- MaxTeselkin (2)
- cheesezoella (2)
- mls1999725 (2)
- mariolew (2)
- MikuuGithub (2)
- bs97 (2)
- louislva (1)
- BorenZhang (1)
- DongHappyyy (1)
- Pukei-Pukei (1)
Pull Request Authors
- waylonflinn (2)
- ErikValle (2)
- fantaosha (2)
- Obafemi-Jinadu (1)
- behr9s16 (1)
- kulits (1)
- dcaustin33 (1)
- AK391 (1)
- seaman1900 (1)
- tornikeo (1)
- TrellixVulnTeam (1)
Top Labels
Issue Labels
Pull Request Labels
Dependencies
- pytorch/pytorch ${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel build
- pytorch/pytorch ${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel build
- numpy *
- torch >=1.3
- docutils ==0.16.0
- myst-parser *
- sphinx ==4.0.2
- sphinx_copybutton *
- sphinx_markdown_tables *
- mmcv-full >=1.3.8
- mmdet >=2.14.0
- mmtrack >=0.6.0
- albumentations >=0.3.2
- onnx *
- onnxruntime *
- pyrender *
- requests *
- smplx >=0.1.28
- trimesh *
- mmcv-full *
- munkres *
- regex *
- scipy *
- titlecase *
- torch *
- torchvision *
- xtcocotools >=1.8
- chumpy *
- dataclasses *
- json_tricks *
- matplotlib *
- munkres *
- numpy *
- opencv-python *
- pillow *
- scipy *
- torchvision *
- xtcocotools >=1.8
- coverage * test
- flake8 * test
- interrogate * test
- isort ==4.3.21 test
- pytest * test
- pytest-runner * test
- smplx >=0.1.28 test
- xdoctest >=0.10.0 test
- yapf * test