facial-expression-recognition
本项目是一个基于深度学习的人脸检测与表情识别系统,使用YOLOv11进行人脸检测,并使用自定义训练的YOLO模型进行表情识别。系统支持图像、视频文件和实时摄像头输入,具有直观的图形用户界面,可以轻松进行人脸检测和表情分析。
Science Score: 44.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
○Academic publication links
-
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (1.2%) to scientific vocabulary
Repository
本项目是一个基于深度学习的人脸检测与表情识别系统,使用YOLOv11进行人脸检测,并使用自定义训练的YOLO模型进行表情识别。系统支持图像、视频文件和实时摄像头输入,具有直观的图形用户界面,可以轻松进行人脸检测和表情分析。
Basic Info
Statistics
- Stars: 8
- Watchers: 0
- Forks: 0
- Open Issues: 0
- Releases: 0
Metadata Files
README.md
- ## 引言
在人机交互和情感计算领域,人脸表情识别一直是一个备受关注的研究方向。随着深度学习技术的快速发展,特别是目标检测和图像分类算法的进步,实时、高精度的人脸表情识别系统已经成为可能。本文将详细介绍一个基于YOLOv11的人脸表情识别系统,该系统不仅能够实现实时人脸检测,还能准确识别多种表情状态,具有广泛的应用前景。
## 系统概述
本文介绍的人脸表情识别系统是一个完整的端到端解决方案,主要包含以下核心功能:
- 多输入源支持:系统可以处理静态图像、视频文件和实时摄像头输入
- 实时人脸检测:采用YOLOv11人脸检测模型,实现高效准确的人脸定位
- 多种表情识别:能够识别6种基本表情(愤怒、厌恶、高兴、中性、悲伤、惊讶)
- 友好的图形界面:基于PyQt5开发的现代化界面,支持暗色主题
- 多模型支持:集成了多个训练模型,包括综合数据集模型、FER2013增强模型等
- 结果可视化与保存:处理结果可以实时显示并保存为图像或视频文件
## CSDN链接: https://blog.csdn.net/apple_62565719/article/details/148848994?spm=1001.2014.3001.5501
## 系统截图(部分)
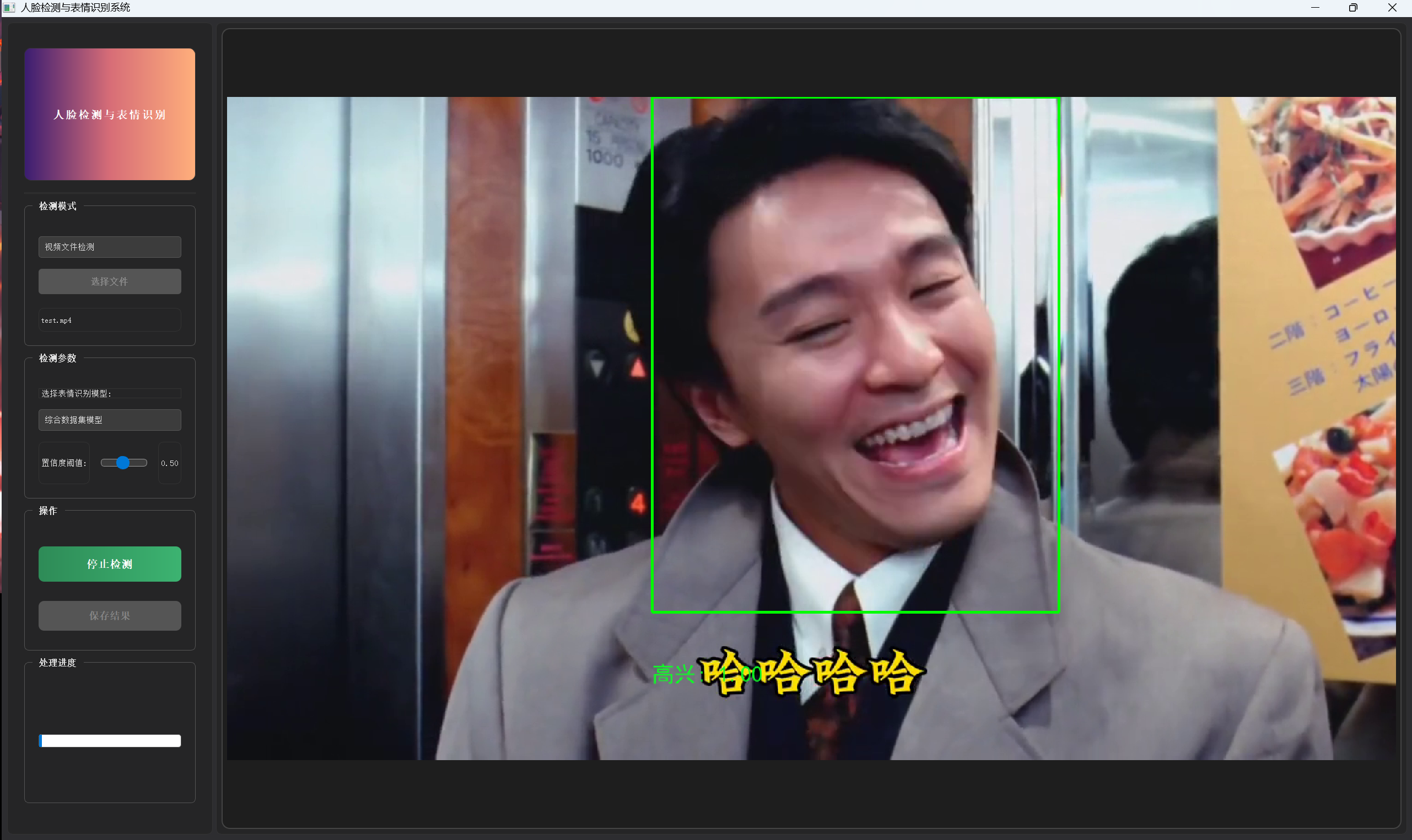
## 技术原理
### 1. 人脸检测
本系统采用YOLOv11(You Only Look Once)作为人脸检测的核心算法。YOLO系列算法是目前最先进的目标检测算法之一,具有速度快、精度高的特点,特别适合实时应用场景。
YOLOv11相比早期版本,在网络结构和训练策略上都有显著改进: - 使用更高效的骨干网络 - 优化的特征金字塔结构 - 改进的损失函数 - 更强大的数据增强策略
在本系统中,我们使用专门针对人脸检测任务微调的YOLOv11模型(yolov11n-face.pt),该模型能够在各种光照条件和角度下准确检测人脸。
### 2. 表情识别
表情识别采用基于YOLO架构的分类模型。我们训练了多个模型以适应不同场景:
- 综合数据集模型:使用多个数据集联合训练,具有较好的泛化能力
- FER2013增强模型:基于增强的FER2013数据集训练,该数据集包含约35,000张带标注的人脸表情图像
- AffectNet模型:使用AffectNet数据集训练,该数据集是目前最大的面部表情数据集之一
- 自定义数据集模型:使用自定义收集和标注的数据集训练,更适合特定应用场景
训练过程中采用了多种先进技术以提高模型性能: - 优化器选择:使用AdamW优化器,结合自适应学习率和权重衰减 - 学习率调度:采用余弦退火策略,有效避免局部最优 - 正则化技术:使用权重衰减和Dropout防止过拟合 - 数据增强:应用多种增强方法,包括内置增强和Mixup技术 - 早停策略:设置耐心值为20,避免过度训练
## 系统架构
系统采用模块化设计,主要包含以下几个核心模块:
### 1. UI模块 (UI.py)
图形用户界面是系统的交互入口,基于PyQt5开发,主要功能包括: - 输入源选择(摄像头、图像文件、视频文件) - 模型选择和参数调整 - 结果显示和保存 - 多线程处理避免UI卡顿
核心类:
- VideoThread:视频处理线程,负责实时视频流的处理
- FaceDetectionApp:主应用窗口,提供用户界面和控制功能
### 2. 人脸检测模块 (yolofacedetection.py)
负责人脸检测的核心功能,包括: - 人脸检测模型加载和管理 - 实时视频人脸检测 - 图像人脸检测 - 视频文件人脸检测
主要函数:
- download_face_model():下载YOLOv11人脸检测模型
- detect_faces_video():视频人脸检测(摄像头)
- detect_faces_image():图像人脸检测
- detect_faces_video_file():视频文件人脸检测
### 3. 表情识别模块 (imageemotionrecognition.py)
负责表情识别的核心功能,包括: - 静态图像中的人脸检测 - 表情识别与分析 - 结果可视化与保存
主要函数:
- recognize_emotion():识别图片中的人脸表情
### 4. 模型训练模块 (train.py)
负责训练表情识别模型,主要特点: - 支持多种数据集(FER2013Plus、AffectNet、自定义数据集) - 高级优化器设置(AdamW) - 学习率调度(余弦退火) - 正则化技术(权重衰减、Dropout) - 数据增强(内置增强、Mixup)
## 实现细节
### 1. 人脸检测与预处理
人脸检测是表情识别的第一步,系统使用YOLOv11模型检测图像或视频中的人脸:
```python # 使用YOLOv11检测人脸 results = face_model(frame, conf=0.8)
# 处理检测结果 for result in results: boxes = result.boxes for box in boxes: # 获取边界框坐标 x1, y1, x2, y2 = box.xyxy[0].cpu().numpy().astype(int)
# 扩大边界框(调整人脸框大小)
frame_height, frame_width = frame.shape[:2]
# 计算边界框的扩展量(框的20%)
expand_x = int((x2 - x1) * 0.2)
expand_y = int((y2 - y1) * 0.2)
# 应用扩展,但确保不超出图像边界
x1_expanded = max(0, x1 - expand_x)
y1_expanded = max(0, y1 - expand_y)
x2_expanded = min(frame_width, x2 + expand_x)
y2_expanded = min(frame_height, y2 + expand_y)
# 绘制扩大后的人脸框
cv2.rectangle(frame, (x1_expanded, y1_expanded), (x2_expanded, y2_expanded), (0, 255, 0), 2)
```
值得注意的是,系统对检测到的人脸区域进行了扩展(约20%),这有助于捕获更完整的面部特征,提高表情识别的准确率。
### 2. 表情识别流程
表情识别采用以下步骤:
- 提取人脸区域:从原始图像中裁剪出人脸区域
- 预处理:将人脸区域转换为灰度图像,以与训练数据保持一致
- 模型推理:使用YOLO分类模型进行表情识别
- 结果处理:获取预测结果,包括表情类别和置信度
- 可视化:在图像上显示预测结果
```python # 提取扩大后的人脸区域 faceroi = frame[y1expanded:y2expanded, x1expanded:x2_expanded]
# 将人脸区域转换为灰度图像,与训练数据保持一致 faceroigray = cv2.cvtColor(faceroi, cv2.COLORBGR2GRAY)
# 将灰度图像转换为3通道,因为YOLO模型需要3通道输入 faceroigray3ch = cv2.cvtColor(faceroigray, cv2.COLORGRAY2BGR)
# 使用YOLO模型进行表情识别 emotionresults = emotionmodel(faceroigray_3ch)
# 获取预测结果 probs = emotionresults[0].probs.data.tolist() classid = probs.index(max(probs)) confidence = max(probs)
# 获取表情标签 emotion = emotionlabels[classid]
# 在图像上显示预测结果 text = f"{emotion}: {confidence:.2f}" ```
### 3. 多线程处理
为了避免UI卡顿,系统使用多线程处理视频流:
```python class VideoThread(QThread): """视频处理线程,避免UI卡顿""" changepixmapsignal = pyqtSignal(np.ndarray) progress_signal = pyqtSignal(int)
def __init__(self, mode='camera', file_path=None):
super().__init__()
self.mode = mode
self.file_path = file_path
self.running = True
self.face_model = None
self.emotion_model = None
self.conf_threshold = 0.5
```
这种设计使得UI保持响应,同时后台进行计算密集型的视频处理任务。
### 4. 模型训练
表情识别模型的训练采用ultralytics库,配置了一系列高级参数以优化模型性能:
```python results = model.train( data="fer2013plus", epochs=200, batch=256, imgsz=224, workers=6,
# 优化器设置
optimizer="AdamW", # 使用具有自适应动量的现代优化器
lr0=0.001, # 初始学习率
lrf=0.001, # 最终学习率因子
warmup_epochs=5, # 逐渐预热以防止早期不稳定
cos_lr=True, # 余弦退火学习率调度
# 正则化
weight_decay=0.0005, # L2正则化
dropout=0.2, # 添加dropout以提高泛化能力
# 数据增强
augment=True, # 启用内置增强
mixup=0.1, # 应用mixup增强
# 训练管理
patience=20, # 早停耐心值
save_period=10, # 每10个epoch保存一次检查点
) ```
## 系统优势与创新点
- 高效的实时处理:采用YOLOv11算法,实现了高效的实时人脸检测和表情识别
- 多模型集成:提供多个预训练模型,适应不同场景需求
- 友好的用户界面:直观的图形界面,支持暗色主题,操作简便
- 多线程架构:采用多线程设计,保证UI响应性能
- 中文支持:完善的中文界面和文本渲染
- 模块化设计:系统各组件高度模块化,便于扩展和维护
## 应用场景
该系统可应用于多种场景:
- 人机交互:提升智能设备对用户情绪的感知能力
- 教育领域:分析学生在学习过程中的情绪变化
- 安防监控:识别异常情绪状态,提前预警
- 医疗健康:辅助心理健康评估和情绪障碍诊断
- 市场调研:分析消费者对产品的情感反应
- 娱乐游戏:根据玩家情绪调整游戏难度或剧情
## 系统使用指南
### 1. 环境配置
系统需要以下环境: - Python 3.8+ - PyQt5 - OpenCV - PyTorch - Ultralytics - Pillow - NumPy
可以使用以下命令安装依赖:
bash
pip install ultralytics opencv-python PyQt5 pillow numpy torch torchvision
### 2. 运行系统
启动图形界面:
bash
python UI.py
命令行使用(单张图片表情识别):
bash
python image_emotion_recognition.py 图片路径
命令行使用(人脸检测):
bash
python yolo_face_detection.py --image 图片路径 # 图片模式
python yolo_face_detection.py --video 视频路径 # 视频模式
python yolo_face_detection.py --camera # 摄像头模式
### 3. 界面操作
- 选择输入源(摄像头、图像文件或视频文件)
- 选择表情识别模型
- 调整置信度阈值(影响检测灵敏度)
- 点击"开始检测"按钮
- 查看实时结果
- 点击"保存结果"保存处理后的图像或视频
## 性能优化技巧
- 预处理优化:将人脸区域转换为灰度图像,减少计算量
- 边界框扩展:扩展人脸检测边界框,捕获更完整的面部特征
- 多线程处理:使用QThread处理视频流,避免UI卡顿
- 置信度阈值:提供可调整的置信度阈值,平衡检测速度和准确率
- 模型选择:提供多个预训练模型,可根据需要选择轻量级或高精度模型
## 未来展望
该系统还有很大的改进和扩展空间:
- 更多表情类别:增加更细粒度的表情分类,如困惑、专注等
- 跨平台支持:开发移动端和Web版本
- 情绪变化分析:实现对情绪变化趋势的追踪和分析
- 多模态融合:结合语音、文本等多模态信息进行更全面的情绪分析
- 边缘设备部署:优化模型以适应边缘计算设备
- 个性化适应:根据用户特点自适应调整模型参数
## 结论
本文介绍的基于YOLOv11的人脸表情识别系统,通过深度学习技术实现了高效准确的人脸检测和表情识别。系统采用模块化设计,提供友好的用户界面,支持多种输入源和多个预训练模型,具有广泛的应用前景。
随着人工智能技术的不断发展,人脸表情识别将在人机交互、情感计算等领域发挥越来越重要的作用。我们期待这个系统能为相关研究和应用提供有价值的参考。
## 参考资料
- YOLOv11: https://github.com/ultralytics/ultralytics
- FER2013数据集: https://www.kaggle.com/datasets/msambare/fer2013
- AffectNet数据集: http://mohammadmahoor.com/affectnet/
- PyQt5文档: https://doc.qt.io/qtforpython/
- OpenCV文档: https://docs.opencv.org/
## 联系方式 有问题可以在csdn留言:https://blog.csdn.net/apple_62565719/article/details/148848994?spm=1001.2014.3001.5501
以上就是基于YOLOv11的实时人脸表情识别系统的详细介绍。如果您对该系统有任何疑问或建议,欢迎在评论区留言交流!
Owner
- Name: Zhengyang
- Login: AND-Q
- Kind: user
- Repositories: 1
- Profile: https://github.com/AND-Q
Citation (CITATION.cff)
# This CITATION.cff file was generated with https://bit.ly/cffinit
cff-version: 1.2.0
title: Ultralytics YOLO
message: >-
If you use this software, please cite it using the
metadata from this file.
type: software
authors:
- given-names: Glenn
family-names: Jocher
affiliation: Ultralytics
orcid: "https://orcid.org/0000-0001-5950-6979"
- family-names: Qiu
given-names: Jing
affiliation: Ultralytics
orcid: "https://orcid.org/0000-0003-3783-7069"
- given-names: Ayush
family-names: Chaurasia
affiliation: Ultralytics
orcid: "https://orcid.org/0000-0002-7603-6750"
repository-code: "https://github.com/ultralytics/ultralytics"
url: "https://ultralytics.com"
license: AGPL-3.0
version: 8.0.0
date-released: "2023-01-10"
GitHub Events
Total
- Watch event: 12
- Issue comment event: 4
- Push event: 11
- Pull request event: 4
- Fork event: 1
- Create event: 4
Last Year
- Watch event: 12
- Issue comment event: 4
- Push event: 11
- Pull request event: 4
- Fork event: 1
- Create event: 4
Issues and Pull Requests
Last synced: 10 months ago
All Time
- Total issues: 0
- Total pull requests: 4
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Total issue authors: 0
- Total pull request authors: 2
- Average comments per issue: 0
- Average comments per pull request: 1.0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 3
Past Year
- Issues: 0
- Pull requests: 4
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Issue authors: 0
- Pull request authors: 2
- Average comments per issue: 0
- Average comments per pull request: 1.0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 3
Top Authors
Issue Authors
Pull Request Authors
- dependabot[bot] (3)
- liangxiurui (1)
Top Labels
Issue Labels
Pull Request Labels
Dependencies
- actions/checkout v4 composite
- actions/setup-python v5 composite
- astral-sh/setup-uv v6 composite
- codecov/codecov-action v5 composite
- conda-incubator/setup-miniconda v3 composite
- eviden-actions/clean-self-hosted-runner v1 composite
- slackapi/slack-github-action v2.1.0 composite
- ultralytics/actions/cleanup-disk main composite
- contributor-assistant/github-action v2.6.1 composite
- actions/checkout v4 composite
- docker/login-action v3 composite
- docker/setup-buildx-action v3 composite
- slackapi/slack-github-action v2.1.0 composite
- ultralytics/actions/cleanup-disk main composite
- ultralytics/actions/retry main composite
- actions/checkout v4 composite
- actions/setup-python v5 composite
- astral-sh/setup-uv v6 composite
- ultralytics/actions main composite
- actions/checkout v4 composite
- ultralytics/actions/retry main composite
- actions/checkout v4 composite
- actions/setup-python v5 composite
- actions/checkout v4 composite
- actions/checkout v4 composite
- actions/download-artifact v4 composite
- actions/setup-python v5 composite
- actions/upload-artifact v4 composite
- astral-sh/setup-uv v6 composite
- pypa/gh-action-pypi-publish release/v1 composite
- slackapi/slack-github-action v2.1.0 composite
- actions/stale v9 composite
- pytorch/pytorch 2.7.0-cuda12.6-cudnn9-runtime build
- matplotlib >=3.3.0
- numpy >=1.23.0
- opencv-python >=4.6.0
- pandas >=1.1.4
- pillow >=7.1.2
- psutil *
- py-cpuinfo *
- pyyaml >=5.3.1
- requests >=2.23.0
- scipy >=1.4.1
- torch >=1.8.0
- torch >=1.8.0,!=2.4.0; sys_platform == 'win32'
- torchvision >=0.9.0
- tqdm >=4.64.0
- ultralytics-thop >=2.0.0