omnimage
Natural images dataset for continual and few-shots learning. 📚
Science Score: 44.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
○Academic publication links
-
○Committers with academic emails
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (9.1%) to scientific vocabulary
Repository
Natural images dataset for continual and few-shots learning. 📚
Statistics
- Stars: 0
- Watchers: 2
- Forks: 0
- Open Issues: 0
- Releases: 0
Metadata Files
README.md

OmnImage 
The OmniImage dataset contains a 1000 classes with 20|100 images each, downsized to 84x84 pixels.
Download
- We provide images resized to 84x84 at https://www.uvm.edu/~lfrati/omnimage.html
- If you'd rather use different resolution we provide a list of the images used here for 20 samples and here for 100 samples
- We provide some PyTorch Dataloaders here (that also download the data) and examples on how to use them here
Why?
- MNIST has 10 classes and thousands of examples for each class.
- ImageNet has 1000 classes with thousands of example each.
- Omniglot has 1623 classes with tens of examples each.
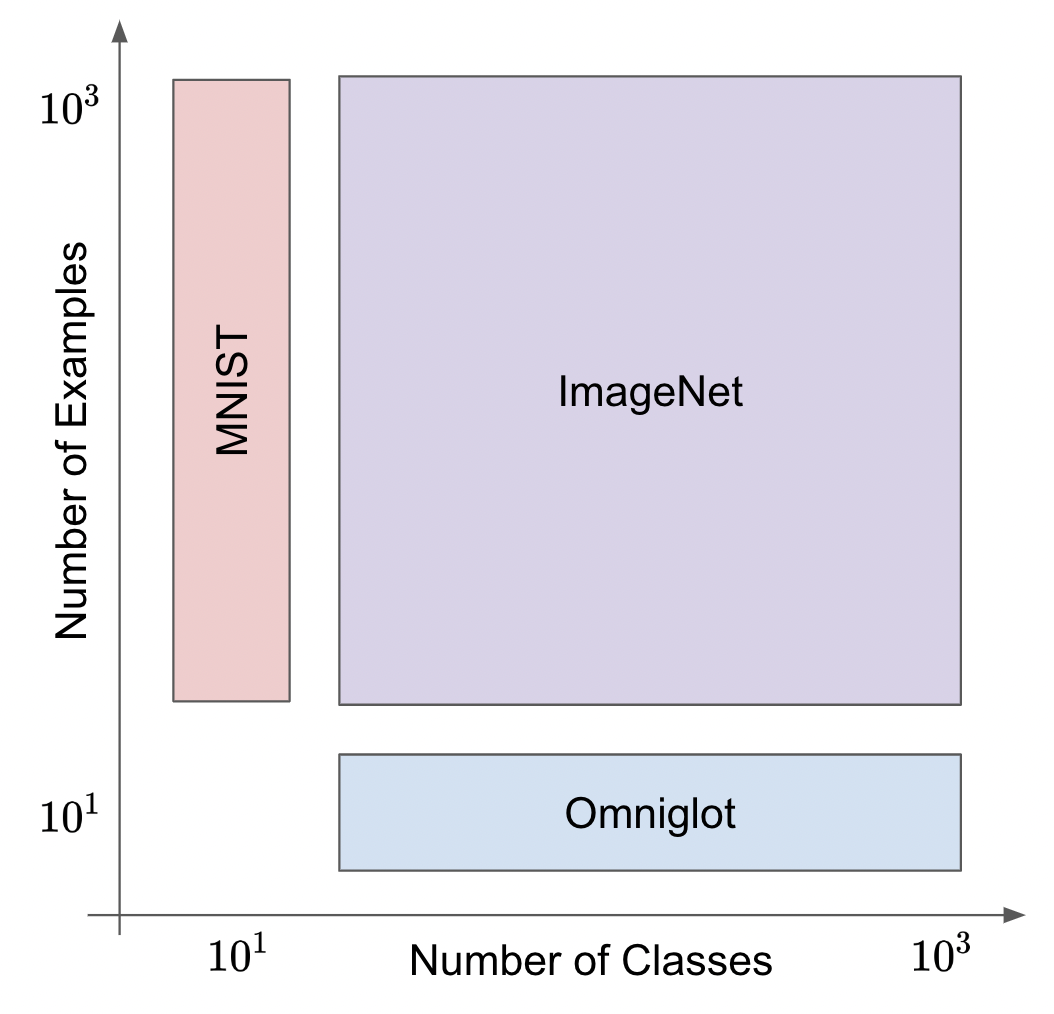
However, while ImageNet contains natural images MNIST and Omniglot only contain examples of handwritten digits/characters.
OmniImage is a class-consistent subset of ImageNet images that mirrors the shallow-and-wide dataset shape of Omniglot.
How?
While characters are fairly easy to "characterize" (barring some bad handwriting) natural images can vary wildly. We try to reduce the noise in our dataset by extracting the 20|100 subset of each class that is most similar to each other. We do this by using evolutionary pairwise cosines subset minimization. For each of the 1000 classes we compute the pairwise cosine distance between all the the examples (features extracted using a pretrained VGG model). We then evolve the minimal subset for each class and add those examples to our dataset.
Cite
bibtex
@inproceedings{frati2023omnimage,
title={OmnImage: Evolving 1k Image Cliques for Few-Shot Learning},
author={Frati, Lapo and Traft, Neil and Cheney, Nick},
booktitle={Proceedings of the Genetic and Evolutionary Computation Conference},
pages={476--484},
year={2023}
}
Owner
- Name: Lapo Frati
- Login: lfrati
- Kind: user
- Company: University of Vermont
- Repositories: 10
- Profile: https://github.com/lfrati
Citation (CITATION.cff)
cff-version: 1.2.0 type: dataset message: "If you use this dataset, please cite it as below." authors: - family-names: "Frati" given-names: "Lapo" orcid: "https://orcid.org/0000-0002-9839-1163" - family-names: "Traft" given-names: "Neil" orcid: "https://orcid.org/0009-0007-9297-4628" - family-names: "Cheney" given-names: "Nicholas" orcid: "https://orcid.org/0000-0002-7140-2213" title: "OmnImage: Evolving 1k Image Cliques for Few-Shot Learning." version: 2.0.4 date-released: 2021-12-13 url: "https://github.com/lfrati/OmnImage"
GitHub Events
Total
Last Year
Issues and Pull Requests
Last synced: 11 months ago
All Time
- Total issues: 0
- Total pull requests: 0
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Total issue authors: 0
- Total pull request authors: 0
- Average comments per issue: 0
- Average comments per pull request: 0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 0
- Pull requests: 0
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Issue authors: 0
- Pull request authors: 0
- Average comments per issue: 0
- Average comments per pull request: 0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
Pull Request Authors
Top Labels
Issue Labels
Pull Request Labels
Dependencies
- actions/checkout v3 composite
- actions/setup-python v4 composite
- actions/checkout v3 composite
- actions/setup-python v4 composite