xnode2vec
Alternative data clustering method based on Node2Vec algorithm.
Science Score: 18.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
○codemeta.json file
-
○.zenodo.json file
-
○DOI references
-
○Academic publication links
-
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (10.3%) to scientific vocabulary
Keywords
Repository
Alternative data clustering method based on Node2Vec algorithm.
Basic Info
Statistics
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
- Releases: 0
Topics
Metadata Files
README.md
XNode2Vec - An Alternative Data Clustering Procedure
Description
This repository proposes an alternative method for data classification and clustering, based on the Node2Vec algorithm that is applied to a properly transformed N-dimensional dataset. The original Node2Vec algorithm was replaced with an extremely faster version, called FastNode2Vec. The application of the algorithm is provided by a function that works with networkx objects, that are quite user-friendly. At the moment there are few easy data transformations, but they will be expanded in more complex and effective ones.
Installation
In order to install the Xnode2vec package simply use pip:
pip install Xnode2vec
If there are some problems with the installation, please read the "Note" below.
How to Use
The idea behind is straightforward: 1. Take a dataset, or generate one. 2. Apply the proper transformation to the dataset. 3. Build a networkx object that embeds the dataset with its crucial properties. 4. Perform a node classification analysis with Node2Vec algorithm.
```python import numpy as np import Xnode2vec as xn2v import pandas as pd
x1 = np.random.normal(4, 1, 20) y1 = np.random.normal(5, 1, 20) x2 = np.random.normal(17, 2, 20) y2 = np.random.normal(13, 1, 20)
family1 = np.columnstack((x1, y1)) # REQUIRED ARRAY FORMAT family2 = np.columnstack((x2, y2)) # REQUIRED ARRAY FORMAT
dataset = np.concatenate((family1,family2),axis=0) # Generic dataset transfdataset = xn2v.bestline_projection(dataset) # Points transformation
df = xn2v.completeedgelist(transfdataset) # Pandas edge list generation edgelist = xn2v.generateedgelist(df) G = nx.Graph() G.addweightededgesfrom(edgelist) # Feed the graph with the edge list
nodes, similarity = xn2v.similarnodes(G, dim=128, walklength=20, context=5, picked=10, p=0.1, q=0.9, workers=4)
similarpoints = xn2v.recoverpoints(dataset,G,nodes) # Final cluster ``` Using the same setup as before, let's perform an even more complex analysis:
```python x1 = np.random.normal(16, 2, 100) y1 = np.random.normal(9, 2, 100) x2 = np.random.normal(25, 2, 100) y2 = np.random.normal(25, 2, 100) x3 = np.random.normal(2, 2, 100) y3 = np.random.normal(1, 2, 100) x4 = np.random.normal(30, 2, 100) y4 = np.random.normal(70, 2, 100)
family1 = np.columnstack((x1, y1)) # REQUIRED ARRAY FORMAT family2 = np.columnstack((x2, y2)) # REQUIRED ARRAY FORMAT family3 = np.columnstack((x3, y3)) # REQUIRED ARRAY FORMAT family4 = np.columnstack((x4, y4)) # REQUIRED ARRAY FORMAT dataset = np.concatenate((family1,family2,family3,family4),axis=0) # Generic dataset
df = xn2v.completeedgelist(dataset) # Pandas edge list generation df = xn2v.generateedgelist(df) # Networkx edgelist format G = nx.Graph() G.addweightededges_from(df)
nodesfamilies, unlabelednodes = xn2v.clustersdetection(G, clusterrigidity = 0.8, spacing = 15, dimfraction = 0.7, picked=len(G.nodes), dim=20, context=5, Epochs = 5, Weight=True, walklength=20) pointsfamilies = [] pointsunlabeled = []
for i in range(0,len(nodesfamilies)): pointsfamilies.append(xn2v.recoverpoints(dataset,G,nodesfamilies[i])) pointsunlabeled = xn2v.recoverpoints(dataset,G,unlabeled_nodes)
xn2v.summaryclusters(pointsfamilies, points_unlabeled)
for cluster in points_families: plt.scatter(cluster[:,0], cluster[:,1])
plt.scatter(pointsunlabeled[:,0], pointsunlabeled[:,1]) # if any
plt.xlabel('x')
plt.ylabel('y')
plt.title('Clustered Dataset', fontweight='bold')
plt.show()
Now the listpoints_families``` contains the four clusters -- clearly taking in account possible statistical errors. The results are however surprisingly good in many situations.
Results
The analysis prints out on the terminal automatically: - Number of clusters found. - Number of nodes analyzed. - Number of clustered nodes. - Number of non-clustered nodes. - Number of nodes in each cluster.
The output is something of this type:
properties
--------- Clusters Information ---------
- Number of Clusters: 5
- Total nodes: 400
- Clustered nodes: 251
- Number of unlabeled nodes: 149
- Nodes in cluster 1: 16
- Nodes in cluster 2: 52
- Nodes in cluster 3: 83
- Nodes in cluster 4: 64
- Nodes in cluster 5: 36
The clustered objects are stored into a list of numpy vectors that are returned by the function clusters_detection(). It's important to get used to the parameter selection that determines the criteria with which the nodes are labeled.
Objects Syntax
Here we report the list of structures required to use the Xnode2vec package:
- Dataset: dataset = np.array([[1,2,3,..], ..., [1,2,3,..]]); the rows corresponds to each point, while the coulumns to the coordinates.
- Edge List: edgelist = [(node_a,node_b,weight), ... , (node_c,node_d,weight)]; this is a list of tuples, structured as [startingnode, arrivingnode, weight]
- DataFrame: pandas.DataFrame(np.array([[1, 2, 3.7], ..., [2, 7, 12]]), columns=['node1', 'node2', 'weight'])
Functions Description
nx_to_Graph(): Performs a conversion from the networkx graph format to the fastnode2vec one, that is necessary to work with fastnode2vec objects.labels_modifier(): Changes the labels of the created networkx graph. It can be useful if we want to select rows from a dataframe that we can't recover only with their positions in the vector.generate_edgelist(): Read a pandas DataFrame and generates an edge list vector to eventually build a networkx graph. The syntax of the file header is rigidly controlled and can't be changed. The header format must be: (node1, node2, weight).edgelist_from_csv(): Read a .csv file using pandas dataframes and generates an edge list vector to eventually build a networkx graph. The syntax of the file header is rigidly controlled and can't be changed.complete_edgelist(): This function performs a data transformation from the space points to a network. It generates links between specific points and gives them weights according to the specified metric.stellar_edgelist(): This function performs a data transformation from the space points to a network. It generates links between specific points and gives them weights according to specific conditions.low_limit_network(): This function performs a network transformation. It sets the link weights of the network to 0 if their initial value was below a given threshold. The threshold is chosen to be a constant times the average links weight.best_line_projection(): Performs a linear best fit of the dataset points and projects them on the line itself.cluster_generation(): This function takes the nodes that have a similarity higher than the one set by cluster_rigidity.clusters_detection(): This function detects the clusters that compose a generic dataset. The dataset must be given as a networkx graph, using the proper data transformation. The clustering procedure uses Node2Vec algorithm to find the most similar nodes in the network.recover_points(): Recovers the spatial points from the analyzed network. It uses the fact that the order of the nodes that build the network is the same as the dataset one, therefore there is a one-to-one correspondence between nodes and points.similar_nodes(): Performs FastNode2Vec algorithm with full control on the crucial parameters. In particular, this function allows the user to keep working with networkx objects -- that are generally quite user-friendly -- instead of the ones required by the fastnode2vec algorithm.load_model(): Load the saved Gensim.Word2Vec model.draw_community(): Draws a networkx plot highlighting some specific nodes in that network. The last node is higlighted in red, the remaining nodes in "nodes_result" are in blue, while the rest of the network is green.
Potential Developments
- Possibility to add a dynamical cluster threshold by using the gradient (see image below). I've tried this, but the classification gets a bit messy on the border, so it should be properly optimized.

Note
- 9/17/2021: I had some issues when installing the fastnode2vec package; in particular, the example given by Louis Abraham gives an error. I noticed that after the installation, the declaration of the file "node2vec.py" wasn't the same as the latest version available on its GitHub (at the moment). My brutal solution was simply to just copy the whole content into the node2vec.py file. This solves the problem.
- 9/17/2021: Numba requires numpy <= 1.20 in order to work.
- 6/1/2022: All issues I found seem fixed.
Citing
If you used XNode2Vec in your research, please consider citing it as below:
@software{XNode2Vec,
author = {Stefano Bianchi},
title = {XNode2Vec - An Alternative Data Clustering Procedure},
year = 2021,
url = {https://github.com/Stefano314/Xnode2vec}
}
Examples
Generic Applications
| Most Similar Nodes | Similar Nodes Distribution | Community Network | Hi-C Translocation Detection |
| :---: | :----: | :---: | :---: |
|  |
|  |
|  |
|  |
|
Clustering Test
| Blobs | Moons | Circles | Swiss Roll |
| :---: | :----: | :---: | :---: |
|  |
| 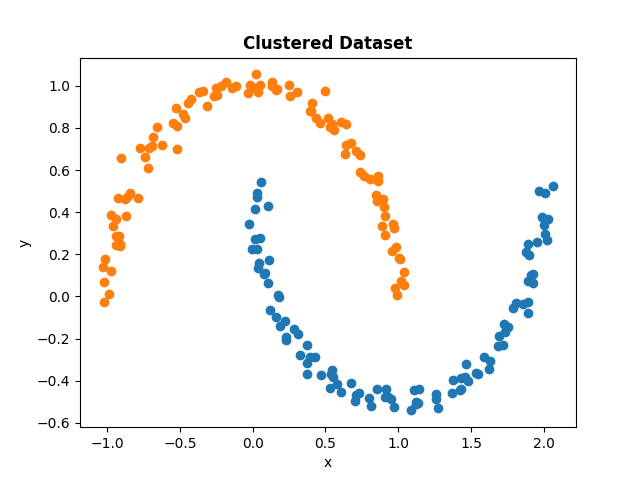 |
| 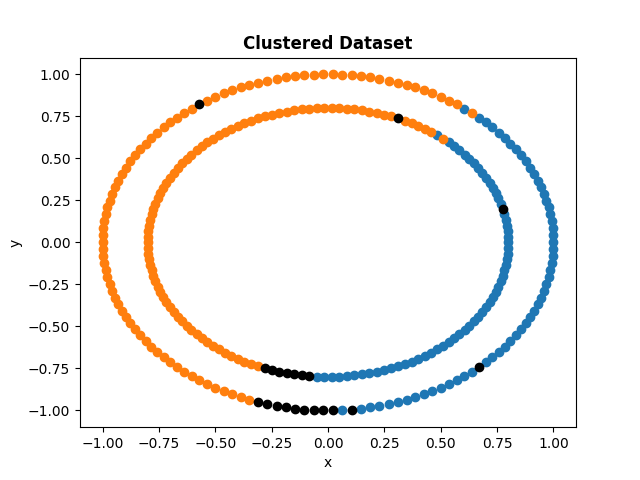 |
|  |
|
Owner
- Name: Stefano Bianchi
- Login: Stefano314
- Kind: user
- Location: Bologna, Italy
- Company: Alma Mater Studiorum, Physics
- Website: https://www.unibo.it/sitoweb/stefano.bianchi22/
- Repositories: 2
- Profile: https://github.com/Stefano314
♪♪♪ I'm a Research Fellow in mathematics at Alma Mater Studiorum, Bologna. Particularly interested in complex systems, machine learning and music
Citation (CITATION.bib)
@software{XNode2Vec,
author = {Stefano Bianchi},
title = {XNode2Vec - An Alternative Data Clustering Procedure},
year = 2021,
url = {https://github.com/Stefano314/Xnode2vec}
}
GitHub Events
Total
Last Year
Issues and Pull Requests
Last synced: 10 months ago
All Time
- Total issues: 0
- Total pull requests: 0
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Total issue authors: 0
- Total pull request authors: 0
- Average comments per issue: 0
- Average comments per pull request: 0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 0
- Pull requests: 0
- Average time to close issues: N/A
- Average time to close pull requests: N/A
- Issue authors: 0
- Pull request authors: 0
- Average comments per issue: 0
- Average comments per pull request: 0
- Merged pull requests: 0
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
Pull Request Authors
Top Labels
Issue Labels
Pull Request Labels
Packages
- Total packages: 1
-
Total downloads:
- pypi 17 last-month
- Total dependent packages: 0
- Total dependent repositories: 1
- Total versions: 16
- Total maintainers: 1
pypi.org: xnode2vec
Alternative method for data clustering using Node2Vec algorithm.
- Homepage: https://github.com/Stefano314/XNode2Vec
- Documentation: https://xnode2vec.readthedocs.io/
- License: agpl-3.0
-
Latest release: 0.11.8
published about 4 years ago
Rankings
Maintainers (1)
Dependencies
- fastnode2vec *