Recent Releases of argilla
argilla - v2.8.0
🔆 Release highlights
The v2.8.0 comes with a better OAuth integration, and some other improvements and bug fixes.
Better OAuth integration
Now, you can extend the supported providers by adding social backends classes in the configuration file:
```yaml
providers:
- name: apple-id
clientid: "<clientid>" # You can use the ARGILLAOAUTH2APPLEIDCLIENTID environment variable
clientsecret: "
extrabackends: - socialcore.backends.apple.AppleIdAuth # Register the Apple OAuth2 provider backend ... ```
Also, the KeyCloak provider is supported by default.
You can visit the docs for more info.
Some relevant improvements and bugfixes are:
- Add keycloak SSO by @paulbauriegel in https://github.com/argilla-io/argilla/pull/5711
- [BUGFIXES] Fixing error when using PostgreSQL by @frascuchon in https://github.com/argilla-io/argilla/pull/5795
- [BUGFIX] Redirect slash when defining
ARGILLA_BASE_URLby @frascuchon in https://github.com/argilla-io/argilla/pull/5796 - [BUGFIX] get dataset settings when using
client.datasets.list()by @frascuchon in https://github.com/argilla-io/argilla/pull/5810 - [FEAT][HELM] set ES SSL verification by @omarmoo5 in https://github.com/argilla-io/argilla/pull/5807
- feat: Add Japanese translation by @Tomoya-Matsubara in https://github.com/argilla-io/argilla/pull/5816
New Contributors
- @omarmoo5 made their first contribution in https://github.com/argilla-io/argilla/pull/5807
- @patrickfleith made their first contribution in https://github.com/argilla-io/argilla/pull/5806
- @Tomoya-Matsubara made their first contribution in https://github.com/argilla-io/argilla/pull/5816
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.7.1...v2.8.0
- Python
Published by frascuchon over 1 year ago
argilla - v2.7.0
🔆 Release highlights
The v2.7.0 release includes some minor improvements and bugfixes
Similarity score
Return similarity score when searching by similarity ```python
import argilla as rg
...
for record, score in dataset.records(similar=rg.Similar( name="vector", value=[0.1, 0.2, 0.3], )): ... ```
Other relevant improvements and bugfixes are:
- Create users and workspaces with predefined IDs (#5786)
- Prevent index errors with empty chat fields (#5787)
- Pass SSL verify parameter when configuring the Argilla client (#5789)
New Contributors
- @hamelsmu made their first contribution in https://github.com/argilla-io/argilla/pull/5784
- @louisbrulenaudet made their first contribution in https://github.com/argilla-io/argilla/pull/5766
- @Saikiranbonu1661 made their first contribution in https://github.com/argilla-io/argilla/pull/5778
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.6.0...v2.7.0
- Python
Published by frascuchon over 1 year ago
argilla - v2.6.0
🔆 Release highlights
Push to hub
Export your dataset to the Hugging Face Hub directly from the Argilla UI:
1️⃣ Go to your dataset 2️⃣ Click on Push to Hub 3️⃣ Make sure you include your username or organization and a Hub Access Token with write permissions
Share your progress
Share your annotation progress on any Argilla dataset with the world!
1️⃣ In your dataset, click on "Share progress" 2️⃣ Open your preferred social media platform 3️⃣ Start a post and paste the copied text 4️⃣ Publish and share with the world!
Update user data
You can update all information of a user. Here's an example of how to update the role of a user:
```python import argilla as rg
client = rg.Argilla(apiurl="<ARGILLAAPIURL>", apikey="
user = client.users("username") user.role = "admin" user.update() ```
Change record fields
You can now update the content of record fields.
```python import argilla as rg
client = rg.Argilla(apiurl="<ARGILLAAPIURL>", apikey="
dataset = client.datasets("my_dataset") record = next(dataset.records(limit=1)) record.fields["text"] = "this is my updated text" record.update()
or several records at once
records = list(dataset.records(...))
for record in records: record.fields["text"] = "this is my updated text"
dataset.records.log(records) ```
Changelog v2.6.0
- [ENHANCEMENT]
argilla server: Return users on dataset progress by @frascuchon in https://github.com/argilla-io/argilla/pull/5701 - [CI] Update base docker image by @frascuchon in https://github.com/argilla-io/argilla/pull/5705
- 🔥 Fix highlight on bulk by @damianpumar in https://github.com/argilla-io/argilla/pull/5698
- 🔥 Improve plugins loaders by @damianpumar in https://github.com/argilla-io/argilla/pull/5697
- fix: :bug: Send visible_options prop only when the questions has more… by @damianpumar in https://github.com/argilla-io/argilla/pull/5716
- [FEATURE] UI - update dataset list by @leiyre in https://github.com/argilla-io/argilla/pull/5684
- [Docs] configure issue form by @sdiazlor in https://github.com/argilla-io/argilla/pull/5703
- Assign field to a span question by @leiyre in https://github.com/argilla-io/argilla/pull/5717
- [FEATURE]: Adding Functionality To Update Users by @sean-hickey-wf in https://github.com/argilla-io/argilla/pull/5615
- [CI] Fix argilla-frontend build by adding the
package-lock.jsonfile by @frascuchon in https://github.com/argilla-io/argilla/pull/5731 - fix: UI - use
last_activity_atin the dataset list by @leiyre in https://github.com/argilla-io/argilla/pull/5741 - [CI] fix install deps using python.3.13 by @frascuchon in https://github.com/argilla-io/argilla/pull/5745
- [BUGFIX] prevent errors when updating user by @frascuchon in https://github.com/argilla-io/argilla/pull/5742
- [BUGFIX]
argilla: prevent enum literal validation errors by @frascuchon in https://github.com/argilla-io/argilla/pull/5679 - 🎉 Improve styles file weight by @leiyre in https://github.com/argilla-io/argilla/pull/5724
- [FEATURE] Add support to update record fields by @frascuchon in https://github.com/argilla-io/argilla/pull/5685
- 🚑 feat/check version by @damianpumar in https://github.com/argilla-io/argilla/pull/5738
- [BUGFIX] [TESTS] Remove custom isoformat parsing and let pydantic do the work by @frascuchon in https://github.com/argilla-io/argilla/pull/5752
- [BUGFIX] Fetch dataset setting when iterate
client.datasetsby @frascuchon in https://github.com/argilla-io/argilla/pull/5753 - [BUGFIX]
argilla: review datasest import with new export flow by @frascuchon in https://github.com/argilla-io/argilla/pull/5756 - [FEATURE-BRANCH] feat: dataset export to the Hub by @jfcalvo in https://github.com/argilla-io/argilla/pull/5730
- Feat/improve export hover by @damianpumar in https://github.com/argilla-io/argilla/pull/5764
- [CHORE] Add missing fixed entries by @frascuchon in https://github.com/argilla-io/argilla/pull/5765
- ✨ Add share component by @damianpumar in https://github.com/argilla-io/argilla/pull/5727
- [RELEASES] v2.6.0 by @jfcalvo in https://github.com/argilla-io/argilla/pull/5762
New Contributors
- @sean-hickey-wf made their first contribution in https://github.com/argilla-io/argilla/pull/5615
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.5.0...v2.6.0
- Python
Published by jfcalvo over 1 year ago
argilla - v2.5.0
🔆 Release highlights
Webhooks
You can now create and manage webhooks to support your workflows!
Webhooks allow you to submit real-time information to other applications whenever a specific event occurs within Argilla. Here's an example of how you can set up a webhook in Argilla:
```python
import argilla as rg
@rg.webhooklistener("record.completed") async def recordcompleted(record: rg.Record, **kwargs): print (f"Record {record.id} has been completed") ```
Visit the Argilla documentation for more information.
A redesigned home page
Argilla's home page has been redesigned to provide a better user experience. The new home page now shows a new dataset card view, which provides a better overview of the datasets and annotation progress.
Python 3.13 and Pydantic v2 support
The Argilla server (and SDK) now supports Python 3.13 and Pydantic 2.0.0. This means that you can now install and use both SDK and server with Python 3.13 in the same Python environment!
```bash pip install argilla pip install argilla-server
python -m argilla_server ```
Other improvements
- We've added a high contrast theme to help users with visual impairments. To change the theme go to "My settings" and choose your preferred theme. Thanks @paulbauriegel for this! 🎉
- You can select the language that you'd like to display in the Argilla UI, also from the "My settings" page. Your language isn't there? Visit the Argilla documentation to learn how you can add yours.
Changelog v2.5.0
- [BUGFIX] argilla server: Prevent update
dataset.updated_atwhen updatingdataset.last_activity_atcolumn by @frascuchon in https://github.com/argilla-io/argilla/pull/5656 - Docs: Typo Fix by @RahulK4102 in https://github.com/argilla-io/argilla/pull/5642
- [Docs] : fix typos in docs by @FarukhS52 in https://github.com/argilla-io/argilla/pull/5612
- [CONFIG]
argilla server: Review and update dependencies by @frascuchon in https://github.com/argilla-io/argilla/pull/5649 - Improve German translation and some aria attributes by @paulbauriegel in https://github.com/argilla-io/argilla/pull/5658
- Add a high-contrast theme & improvements for the forced-colors mode by @paulbauriegel in https://github.com/argilla-io/argilla/pull/5661
- [BUGFIX]: argilla server: install default
psycopg2driver used by alembic by @frascuchon in https://github.com/argilla-io/argilla/pull/5672 - (Typo): Update README.md by @kaleaditya779 in https://github.com/argilla-io/argilla/pull/5655
- [CONFIG]
argilla: Add Python 3.13 support by @frascuchon in https://github.com/argilla-io/argilla/pull/5652 - [ENHANCEMENT][REFACTOR] SDK: allow to remove settings by @frascuchon in https://github.com/argilla-io/argilla/pull/5584
- fix: improve logic for detecting ChatFields by @leiyre in https://github.com/argilla-io/argilla/pull/5667
- [BUGFIX]
argilla frontend: Avoid call router.push when opening an external URL by @frascuchon in https://github.com/argilla-io/argilla/pull/5675 - [BUGFIX] visualisation of highlighted text by @leiyre in https://github.com/argilla-io/argilla/pull/5678
- Dataset Creation UI fixes & Improvements by @leiyre in https://github.com/argilla-io/argilla/pull/5670
- [BUGFIX] Show
Import dataif user is admin or owner by @leiyre in https://github.com/argilla-io/argilla/pull/5688 - docs: Add missing server configuration env vars by @frascuchon in https://github.com/argilla-io/argilla/pull/5676
- [REFACTOR]
argilla server: Remove passlib dependency by @frascuchon in https://github.com/argilla-io/argilla/pull/5674 - [FEATURE] UI - Add language selection in user settings by @leiyre in https://github.com/argilla-io/argilla/pull/5690
- ⚡️ Fix highlight text by @damianpumar in https://github.com/argilla-io/argilla/pull/5693
- [FEATURE] Add Webhooks by @jfcalvo in https://github.com/argilla-io/argilla/pull/5467
- 🚑 Add missing translation by @damianpumar in https://github.com/argilla-io/argilla/pull/5696
- Docs - Add docs for adding a language by @paulbauriegel in https://github.com/argilla-io/argilla/pull/5640
- [BUGFIX]
argilla server: Prevent passing non-string values to text fields by @frascuchon in https://github.com/argilla-io/argilla/pull/5682 - [REFACTOR]
argilla server: using pydantic v2 by @frascuchon in https://github.com/argilla-io/argilla/pull/5666 - fix: Resolve failing tests after pydantic V2 merge by @frascuchon in https://github.com/argilla-io/argilla/pull/5700
- [DOCS] Deploy on spaces review by @sdiazlor in https://github.com/argilla-io/argilla/pull/5704
- [REFACTOR]
argilla: Align questions toResourceAPI by @frascuchon in https://github.com/argilla-io/argilla/pull/5680 - [CHORE] Review changelogs by @frascuchon in https://github.com/argilla-io/argilla/pull/5707
- [EXAMPLES][DOCS] review basic webhooks example by @frascuchon in https://github.com/argilla-io/argilla/pull/5710
- [BUGFIX]
argilla: allow change default distribution values by @frascuchon in https://github.com/argilla-io/argilla/pull/5719 - [DOCS] review 2.5.0 docs by @frascuchon in https://github.com/argilla-io/argilla/pull/5723
- [RELEASES] v2.5.0 by @frascuchon in https://github.com/argilla-io/argilla/pull/5706
New Contributors
- @RahulK4102 made their first contribution in https://github.com/argilla-io/argilla/pull/5642
- @FarukhS52 made their first contribution in https://github.com/argilla-io/argilla/pull/5612
- @kaleaditya779 made their first contribution in https://github.com/argilla-io/argilla/pull/5655
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.4.1...v2.5.0
- Python
Published by frascuchon over 1 year ago
argilla - v2.4.1
This release includes some argilla-server fixes:
- Fixed redirection problems after users sign-in using HF OAuth. (#5635)
- Fixed highlighting of the searched text in text, span and chat fields (#5678)
- Fixed validation for rating question when creating a dataset (#5670)
- Fixed question name based on question type when creating a dataset (#5670)
- Fixed error so now
_touch_dataset_last_activity_atfunction is not updating dataset'supdated_atcolumn. (#5656)
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.4.0...v2.4.1
- Python
Published by frascuchon over 1 year ago
argilla - v2.4.0
🔆 Release highlights
Import Hub datasets from the UI
https://github.com/user-attachments/assets/3ccb808e-6242-480d-878a-7cbe26539619
In this release, we’ve focused all of our efforts in bringing you a new feature to import datasets from the Hugging Face Hub directly within our UI, making it easier and faster to get started with your AI projects.
To get started, click on the “Import dataset from Hugging Face” button and paste the repo id of the dataset you want to use. Argilla will process the columns of the dataset and map them to Fields or Questions. Then, you can add more questions or remove any unnecessary fields by selecting the “No mapping” options. All the changes you make will be automatically reflected in the preview.
Once you’re happy with the result you simply need to provide a name for your dataset, select a workspace and (if applicable) a split. Then, Argilla will start importing the dataset.
[!NOTE] If your dataset is bigger than 10k records, at this stage Argilla will only import the first 10k. You can import the rest of the dataset using the Argilla SDK: simply click on the “Import data” button in the dataset and use the code snippet provided.
If you want to make extra changes, like customizing the titles of your fields and questions, don’t worry, you can always go back to the Dataset Settings page after the dataset has been created.
Learn more about this new feature in our docs.
Deploy an Argilla Space directly from the SDK
If you're working from the SDK and don't want to leave to start your Argilla server, you can start an Argilla deployment on Spaces with a simple line of code:
```python import argilla as rg
client = rg.Argilla.deployonspaces(api_key="12345678") ````
Learn more in our docs.
Changelog v2.4.0
- Enhancement/improve-error-messaging-for-role-forbidden by @burtenshaw in https://github.com/argilla-io/argilla/pull/5554
- refactor: add
DatasetPublishValidatorclass by @jfcalvo in https://github.com/argilla-io/argilla/pull/5568 - feat: set CREATORUSERID to avoid difficulties with creation in orga… by @davidberenstein1957 in https://github.com/argilla-io/argilla/pull/5556
- [Refactor] remove name validations for dataset workspaces and usernames by @frascuchon in https://github.com/argilla-io/argilla/pull/5575
- fix: SPACESCREATORUSERID -> SPACECREATORUSERID by @davidberenstein1957 in https://github.com/argilla-io/argilla/pull/5590
- [FIX] Prevent duplicated field text by @leiyre in https://github.com/argilla-io/argilla/pull/5592
- feat: Add basic support to bool features by @frascuchon in https://github.com/argilla-io/argilla/pull/5576
- feat: Add support to other than str values for terms metadata properties by @frascuchon in https://github.com/argilla-io/argilla/pull/5594
- [BUGFIX] argilla server: parse fields for record schemas by @frascuchon in https://github.com/argilla-io/argilla/pull/5600
- correct phrase on docs: "a recod question" -> "a question" by @HeAndres in https://github.com/argilla-io/argilla/pull/5599
- docs: update filter_dataset.md by @eltociear in https://github.com/argilla-io/argilla/pull/5571
- feat: 5108 feature add method to deploy on spaces through huggingface hub by @davidberenstein1957 in https://github.com/argilla-io/argilla/pull/5547
- docs: add quickstart update for deploy on spaces by @davidberenstein1957 in https://github.com/argilla-io/argilla/pull/5550
- Typo: missing comma by @ACMCMC in https://github.com/argilla-io/argilla/pull/5565
- Typo fix by @ACMCMC in https://github.com/argilla-io/argilla/pull/5566
- Fix typo by @ACMCMC in https://github.com/argilla-io/argilla/pull/5567
- [REFACTOR] argilla server: moving all record validators by @frascuchon in https://github.com/argilla-io/argilla/pull/5603
- [BUGFIX] argilla server: Prevent convert
ChatFieldValueobjects by @frascuchon in https://github.com/argilla-io/argilla/pull/5605 - Introducing Argilla Guru on Gurubase.io by @kursataktas in https://github.com/argilla-io/argilla/pull/5608
- [PERF][IMPROVEMENT] argilla server: improve computation for dataset progress and metrics by @frascuchon in https://github.com/argilla-io/argilla/pull/5618
- [PERF] argilla server: Reduce general transaction time by @frascuchon in https://github.com/argilla-io/argilla/pull/5609
- fix: Prevent compute metrics for draft datasets by @frascuchon in https://github.com/argilla-io/argilla/pull/5624
- Refine German translations and update non-localized UI elements by @paulbauriegel in https://github.com/argilla-io/argilla/pull/5632
- [BUGFIX] Catch None in image feature columns by @burtenshaw in https://github.com/argilla-io/argilla/pull/5626
- feat: added support for
with_vectorswith query filter in sdk by @bharath97-git in https://github.com/argilla-io/argilla/pull/5638 - perf: Using search engine to compute the total number of records for user metrics by @frascuchon in https://github.com/argilla-io/argilla/pull/5641
- [IMPROVEMENT] feat(helm): add support for default storage class in PVCs by @dme86 in https://github.com/argilla-io/argilla/pull/5628
- Feature - Improve Accessibility for Screenreaders by @paulbauriegel in https://github.com/argilla-io/argilla/pull/5634
- [FEATURE-BRANCH] Argilla direct import from Hub by @jfcalvo in https://github.com/argilla-io/argilla/pull/5572
- fix: remove unnecesary exposed ports for Argilla Docker compose file by @jfcalvo in https://github.com/argilla-io/argilla/pull/5644
- Dataset creation feature final QA by @leiyre in https://github.com/argilla-io/argilla/pull/5646
- [CI] argilla frontend: Remove invalid workflow permissions by @frascuchon in https://github.com/argilla-io/argilla/pull/5647
- [CI] Configure workflow permissions by @frascuchon in https://github.com/argilla-io/argilla/pull/5648
- chore: update changelogs for release
2.4.0by @jfcalvo in https://github.com/argilla-io/argilla/pull/5650 - chore: small improvement installing dependencies for HF Spaces Dockerfile by @jfcalvo in https://github.com/argilla-io/argilla/pull/5651
- fix: skip
helmlintpre-commit hook on CI becausehelmcommand is not available by @jfcalvo in https://github.com/argilla-io/argilla/pull/5654 - Import from hub docs by @nataliaElv in https://github.com/argilla-io/argilla/pull/5631
- [RELEASE] 2.4.0 by @frascuchon in https://github.com/argilla-io/argilla/pull/5643
New Contributors
- @HeAndres made their first contribution in https://github.com/argilla-io/argilla/pull/5599
- @ACMCMC made their first contribution in https://github.com/argilla-io/argilla/pull/5565
- @kursataktas made their first contribution in https://github.com/argilla-io/argilla/pull/5608
- @bharath97-git made their first contribution in https://github.com/argilla-io/argilla/pull/5638
- @dme86 made their first contribution in https://github.com/argilla-io/argilla/pull/5628
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.3.1...v2.4.0
- Python
Published by frascuchon over 1 year ago
argilla - v2.3.1
What's Changed
This is a patch release fixing an error listing current user datasets:
- Fixed error listing current user datasets and not filtering by current user id. (#5583)
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.3.0...v2.3.1
- Python
Published by jfcalvo over 1 year ago
argilla - v2.3.0
🌟 Release highlights
Custom Fields: the most powerful way to build custom annotation tasks
We heard you. This new type of field gives you full control over how data is presented to annotators.
With custom fields, you can use your own CSS, HTML, and even Javascript (welcome interactive fields!). Moreover, you can populate your fields with custom structures like custom_field={"image1": ..., "image_2": ..., etc.}.
Here's an example:
Imagine you want to show two images and a prompt to your users.
With a custom field
With the new custom field, you can configure something like this:
And you can set this up with a few lines of code:
```python css_template = """ """
htmltemplate = """

customfield = rg.CustomField( name="images", template=csstemplate + html_template, )
and the log records like this
rg.Record( fields={ "prompt": prompt, "image1": schnelluri, "image2": devuri, } ) ```
Before the custom field
Before this release, you were forced to use two ImageField and a TextField, which would be displayed sequentially, limiting the ability to compare the images side-by-side, with clear labels, prompt text, etc. It would look like this:
How to get started with custom fields
Here we've shown a basic presentation-oriented custom field but you can set up anything you can think of, leveraging JS, html, and css. Imagination is the limit!
To get started check the docs: https://docs.argilla.io/v2.3/howtoguides/custom_fields/
Other features
- Support for similarity search from the SDK and other search and filtering improvements.
- New Helm chart deployment configuration.
- Support credentials from colab secrets.
An other changes and fixes
Changed
- Changed the repr method for
SettingsPropertiesto display the details of all the properties inSettingobject. (#5380) - Changed error messages when creating datasets with insufficient permissions. (#5540)
Fixed
- Fixed serialization of
ChatFieldwhen collecting records from the hub and exporting todatasets. (#5554) - Fixed error when creating default user with existing default workspace. (#5558)
- Fixed the deployment yaml used to create a new Argilla server in K8s. Added
USERNAMEandPASSWORDto the environment variables of pod template. (#5434) - Fix autofill form on sign-in page #5522
- Support copy on clipboard for no secure context #5535
New Contributors
- @not-lain made their first contribution in https://github.com/argilla-io/argilla/pull/5541
Thanks to
- @bikash119 for Helm chart in https://github.com/argilla-io/argilla/pull/5512
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.2.2...v2.3.0
- Python
Published by frascuchon over 1 year ago
argilla - v2.2.2
What's Changed
This is a patch release with certain fixes to the SDK
Fixed
- Fixed
from_hubwith unsupported column names. (#5524) - Fixed
from_hubwith missing datasetsubsetconfiguration value. (#5524)
Changed
- Changed
from_hubto only generate fields not questions for strings in the dataset. (#5524)
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.2.1...v2.2.2
- Python
Published by frascuchon almost 2 years ago
argilla - v2.2.1
What's Changed
This is a patch release with certain fixes to the SDK:
- Fixed
from_huberrors when columns names contain uppercase letters. (#5523) - Fixed
from_huberrors when class feature values contains unlabelled values. (#5523) - Fixed
from_huberrors when loading cached datasets. (#5523)
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.2.0...v2.2.1
- Python
Published by jfcalvo almost 2 years ago
argilla - v2.2.0
🌟 Release highlights
[!IMPORTANT] Argilla server
2.2.0adds support for background jobs. These background jobs allow us to run jobs that might take a long time at request time. For this reason we now rely on Redis and Python RQ workers.So to upgrade your Argilla instance to version
2.2.0you need to have an available Redis server. See the Redis get-started documentation for more information or the Argilla server configuration documentation.If you have deployed Argilla server using the docker-compose.yaml, you should download the docker-compose.yaml file again to bring the latest changes to set Redis and Argilla workers
Workers are needed to process Argilla's background jobs. You can run Argilla workers with the following command:
sh python -m argilla_server worker
ChatField: working with text conversations in Argilla
https://github.com/user-attachments/assets/563dd57e-6f99-4b04-9bfa-c930b2a1625c
You can now work with text conversations natively in Argilla using the new ChatField. It is especially designed to make it easier to build datasets for conversational Large Language Models (LLMs), displaying conversational data in the form of a chat.
Here's how you can create a dataset with a ChatField:
```python
import argilla as rg
client = rg.Argilla(apiurl="<apiurl>", apikey="<apikey>")
settings = rg.Settings( fields=[rg.ChatField(name="chat")], questions=[...] )
dataset = rg.Dataset( name="chatdataset", settings=settings, workspace="myworkspace", client=client )
dataset.create()
record = rg.Record( fields={ "chat": [ {"role": "user", "content": "Hello World, how are you?"}, {"role": "assistant", "content": "I'm doing great, thank you!"} ] } )
dataset.records.log([record]) ``` Read more about how to use this new field type here and here.
Adjust task distribution settings
You can now modify task distribution settings at any time, and Argilla will automatically recalculate the completed and pending records. When you update this setting, records will be removed from or added to the pending queues of your team accordingly.
You can make this change in the dataset settings page or using the SDK: ```python import argilla as rg
client = rg.Argilla(apiurl="<apiurl>", apikey="<apikey>")
dataset = client.datasets("mydataset") dataset.settings.distribution.minsubmitted = 2 dataset.update() ````
Track team progress from the SDK
The Argilla SDK now provides a way to retrieve data on annotation progress. This feature allows you to monitor the number of completed and pending records in a dataset and also the number of responses made by each user: ```python import argilla as rg
client = rg.Argilla(apiurl="<apiurl>", apikey="<apikey>")
dataset = client.datasets("my_dataset")
progress = dataset.progress(withusersdistribution=True)
The expected output looks like this:
```json
{
"total": 100,
"completed": 50,
"pending": 50,
"users": {
"user1": {
"completed": { "submitted": 10, "draft": 5, "discarded": 5},
"pending": { "submitted": 5, "draft": 10, "discarded": 10},
},
"user2": {
"completed": { "submitted": 20, "draft": 10, "discarded": 5},
"pending": { "submitted": 2, "draft": 25, "discarded": 0},
},
...
}
Read more about this feature here.
Automatic settings inference
When you import a dataset using the from_hub method, Argilla will automatically infer the settings, such as the fields and questions, based on the dataset Features. This will save you time and effort when working with datasets from the Hub.
```python import argilla as rg
client = rg.Argilla(apiurl="<apiurl>", apikey="<apikey>")
dataset = rg.Dataset.from_hub("yahma/alpaca-cleaned") ````
Task templates
We've added pre-built templates for common dataset types, including text classification, ranking, and rating tasks. These templates provide a starting point for your dataset creation, with pre-configured settings. You can use these templates to get started quickly, without having to configure everything from scratch. ```python import argilla as rg
client = rg.Argilla(apiurl="<apiurl>", apikey="<apikey>")
settings = rg.Settings.for_classification(labels=["positive", "negative"])
dataset = rg.Dataset( name="mydataset", settings=settings, client=client, workspace="myworkspace", )
dataset.create() ```` Read more about templates here.
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.1.0...v2.2.0
- Python
Published by jfcalvo almost 2 years ago
argilla - Release 2.1.0
🌟 Release highlights
Image Field
Argilla now supports multimodal datasets with the introduction of a native
ImageField. This new type of field allows you to work seamlessly with image data, making it easier to annotate and curate datasets that combine text and images.
Here's an example of a dataset with an image field: ```python
import argilla as rg
client = rg.Argilla(...)
settings = rg.Settings( fields = [ rg.ImageField(name="image"), rg.TextField(name="caption") ], questions = [ rg.LabelQuestion( name="goodorbad", title="Is the caption good or bad", labels=["good", "bad"] ), rg.TextQuestion(name="comments") ] )
dataset = rg.Dataset(name="image_captions", settings=settings) dataset.create()
record = rg.Record( fields= { "image": "https://docs.argilla.io/dev/assets/logo.svg", "caption": "This is the Argilla logo" } ) dataset.records.log([record])
``` Read more
Dark Mode
Argilla seems too bright for you? You can now try our new Dark Mode: a theme designed to reduce eye strain and give a new modern look to the app. You can enable Dark Mode under "My Settings".
Spanish Translation
We're committed to making Argilla accessible to a broader audience. With the addition of Spanish translation, we're taking another step towards breaking language barriers and enabling more teams to collaborate on data curation projects. There's nothing you need to do to enable it: Argilla will automatically switch to Spanish when your browser's main language is set to Spanish. ¡Disfrutadla!
Import any dataset from the Hugging Face Hub
The from_hub method just got a major boost! You can now input your own settings, allowing you to use this method with almost any dataset from the Hugging Face Hub, not just Argilla datasets.
Here's how easy it is to import a dataset from the Hub: ```python import argilla as rg
client = rg.Argilla(...)
settings = rg.Settings( fields=[ rg.TextField(name="input"), ], questions=[ rg.TextQuestion(name="output"), ], )
dataset = rg.Dataset.fromhub( repoid="yahma/alpaca-cleaned", settings=settings, )
``` Read more
Other Notable Fixes and Improvements
- Adaptable text areas for
TextQuestion's, providing a better user experience in the UI. - Enhanced messaging for empty queues, keeping you informed when no records are available in the UI.
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.0.1...v2.1.0
- Python
Published by frascuchon almost 2 years ago
argilla - v2.0.1
What's Changed
🧹 Patch release of bug fixes and minor documentation and messaging improvements. Enjoy your summer while we change the world in v2.1.0.
Fixed
- Fixed error when creating optional fields. (#5362)
- Fixed error creating integer and float metadata with
visible_for_annotators. (#5364) - Fixed error when logging records with
suggestionsorresponsesfor non-existent questions. (#5396 by @maxserras) - Fixed error from conflicts in testing suite when running tests in parallel. (#5349)
- Fixed error in response model when creating a response with a
Nonevalue. (#5343)
Changed
- Changed
from_hubmethod to raise an error when a dataset with the same name exists. (#5258) - Changed
logmethod when ingesting records with no known keys to raise a descriptive error. (#5356) - Changed
code snippetsto add new datasets (#5395)
Added
- Added Google Analytics to the documentation site. (#5366)
- Added frontend skeletons to progress metrics to optimise load time and improve user experience. (#5391)
- Added documentation in methods in API references for the Python SDK. (#5400)
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.0.0...v2.0.1
- Python
Published by burtenshaw almost 2 years ago
argilla - v2.0.0
🔆 Release highlights
One Dataset to rule them all
The main difference between Argilla 1.x and Argilla 2.x is that we've converted the previous dataset types tailored for specific NLP tasks into a single highly-configurable Dataset class.
With the new Dataset you can combine multiple fields and question types, so you can adapt the UI for your specific project. This offers you more flexibility, while making Argilla easier to learn and maintain.
[!IMPORTANT] If you want to continue using your legacy datasets in Argilla 2.x, you will need to convert them into v2
Dataset's as explained in this migration guide. This includes:DatasetForTextClassification,DatasetForTokenClassification, andDatasetForText2Text.
FeedbackDataset's do not need to be converted as they are already compatible with the Argilla v2 format.
New SDK & documentation
We've redesigned our SDK with the idea to adapt it to the new single Dataset and Record classes and, most importantly, improve the user and developer experience.
The main goal of the new design is to make the SDK easier to use and learn, making it simpler and faster to configure your dataset and get it up and running.
Here's an example of what creating a Dataset looks like:
```python
import argilla as rg
from datasets import load_dataset
log to the Argilla client
client = rg.Argilla( apiurl="<apiurl>", apikey="<apikey>" # headers={"Authorization": f"Bearer {HF_TOKEN}"} )
configure dataset settings
settings = rg.Settings( guidelines="Classify the reviews as positive or negative.", fields=[ rg.TextField( name="review", title="Text from the review", usemarkdown=False, ), ], questions=[ rg.LabelQuestion( name="mylabel", title="In which category does this article fit?", labels=["positive", "negative"], ) ], )
create the dataset in your Argilla instance
dataset = rg.Dataset( name=f"myfirstdataset", settings=settings, client=client, ) dataset.create()
get some data from the hugging face hub and load the records
data = loaddataset("imdb", split="train[:100]").tolist() dataset.records.log(records=data, mapping={"text": "review"}) ```
To learn more about this SDK and how it works, check out our revamped documentation: https://argilla-io.github.io/argilla/latest
We made this new documentation site from scratch, applying the Diátaxis framework and UX principles with the hope to make this version cleaner and the information easier to find.
New UI layout
We have also redesigned part of our UI for Argilla 2.0:
- We've redistributed the information in the Home page.
- Datasets don't have Tasks, but Questions.
- A clearer way to see your team's progress over each dataset.
- Annotation guidelines and your progress are now accessible at all times within the dataset page.
- Dataset pages also have a new flexible layout, so you can change the size of different panels and expand or collapse the guidelines and progress.
- SpanQuestion's are now supported in the bulk view.
https://github.com/user-attachments/assets/2d959c8a-b4ac-446b-8326-bd66daa28816
Automatic task distribution
Argilla 2.0 also comes with an automated way to split the task of annotating a dataset among a team. Here's how it works in a nutshell:
- An owner or an admin can set the minimum number of submitted responses expected for each record.
- When a record reaches that threshold, its status changes to complete and it's automatically removed from the pending queue of all team members.
- A dataset is 100% complete when all records have the status complete.
By default, the minimum submitted answers is 1, but you can create a dataset with a different value:
python
settings = rg.Settings(
guidelines="These are some guidelines.",
fields=[
rg.TextField(
name="text",
),
],
questions=[
rg.LabelQuestion(
name="label",
labels=["label_1", "label_2", "label_3"]
),
],
distribution=rg.TaskDistribution(min_submitted=3)
)
You can also change the value of an existing dataset as long as it has no responses. You can do this from the General tab inside the Dataset Settings page in the UI or from the SDK:
```python
import argilla as rg
client = rg.Argilla(...)
dataset = client.datasets("my_dataset")
dataset.settings.distribution.min_submitted = 4
dataset.update() ```
To learn more, check our guide on how to distribute the annotation task.
Easily deploy in Hugging face Spaces
We've streamlined the deployment of an Argilla Space in the Hugging Face Hub. Now, there's no need to manage users and passwords. Follow these simple steps to create your Argilla Space:
- Select the Argilla template.
- Choose your hardware and persistent storage options (if you prefer others than the recommended ones).
- If you are creating a space inside an organization, enter your Hugging Face Hub username under username to get the owner role.
- Leave password empty if you'd like to use Hugging Face OAuth to sign in to Argilla.
- Select if the space will be public or private.
- Create Space ! 🎉
Now you and your team mates can simply sign in to Argilla using Hugging Face OAuth!
Learn more about deploying Argilla in Hugging Face Spaces.
https://github.com/user-attachments/assets/a57a8712-ef4e-45f3-8c38-7bbc47adf02b
New Contributors
- @bikash119 made their first contribution in https://github.com/argilla-io/argilla/pull/5294
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.29.1...v2.0.0
- Python
Published by jfcalvo almost 2 years ago
argilla - v1.29.1
What's Changed
- 🙏 Update community link for v1.29.1 by @damianpumar in https://github.com/argilla-io/argilla/pull/5257
- bug: 5123 metrics by @sdiazlor in https://github.com/argilla-io/argilla/pull/5245
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.29.0...v1.29.1
- Python
Published by frascuchon almost 2 years ago
argilla - v2.0.0rc2
What's Changed
- Docs: new review UI guide by @nataliaElv in https://github.com/argilla-io/argilla/pull/5083
- [ENHANCEMENT] ci: Review event triggers to reduce CI runs by @frascuchon in https://github.com/argilla-io/argilla/pull/5075
- docs: fix minor warning by @sdiazlor in https://github.com/argilla-io/argilla/pull/5089
- 🔥 Fix reorder labels by @damianpumar in https://github.com/argilla-io/argilla/pull/5084
- ✨ Refactor CSS by @damianpumar in https://github.com/argilla-io/argilla/pull/5085
- ✨ Fix issue on iterator by @damianpumar in https://github.com/argilla-io/argilla/pull/5099
- [ENHANCEMENT] CI: Allow to publish hidden version for docs/ branches by @frascuchon in https://github.com/argilla-io/argilla/pull/5088
- [ENHANCEMENT / BUGFIX] CI: publish version docs on tag creation by @frascuchon in https://github.com/argilla-io/argilla/pull/5092
- [DOCS] swap extra_headers for headers in updated sdk docs by @burtenshaw in https://github.com/argilla-io/argilla/pull/5100
- docs: change references slack by @sdiazlor in https://github.com/argilla-io/argilla/pull/5101
- [BUGFIX] remove name as default description in settings models by @burtenshaw in https://github.com/argilla-io/argilla/pull/5081
- 🐛 Fix banner by @damianpumar in https://github.com/argilla-io/argilla/pull/5127
- ✨ Improve docs by @damianpumar in https://github.com/argilla-io/argilla/pull/5094
- change: delete on cascade responses when associated user is deleted by @jfcalvo in https://github.com/argilla-io/argilla/pull/5126
- ✨ Add LaTex support by @damianpumar in https://github.com/argilla-io/argilla/pull/5129
- docs: small clarifications by @sdiazlor in https://github.com/argilla-io/argilla/pull/5131
- fix: UI - scrollable records in bulk view by @leiyre in https://github.com/argilla-io/argilla/pull/5143
- fix: copy the dataset name by clicking the copy button by @leiyre in https://github.com/argilla-io/argilla/pull/5142
- [ENHANCEMENT]
argilla: simplify structure for flatten records to list by @frascuchon in https://github.com/argilla-io/argilla/pull/5137 - [ENHANCEMENT]
argilla: define argilla-v1 as optional dependency by @frascuchon in https://github.com/argilla-io/argilla/pull/5120 - refactor: improve get pop issues by @sdiazlor in https://github.com/argilla-io/argilla/pull/5135
- [BUGFIX]
argilla: normalize records when exporting flatten by @frascuchon in https://github.com/argilla-io/argilla/pull/5138 - [BUGFIX]
argilla: support read draft response models without values by @frascuchon in https://github.com/argilla-io/argilla/pull/5124 - [REFACTOR] Redefine some property methods by @frascuchon in https://github.com/argilla-io/argilla/pull/5114
- fix: conditional checking SQLite connection so connection configuration is correctly executed by @jfcalvo in https://github.com/argilla-io/argilla/pull/5149
- chore: update SQLAlchemy dependencies by @jfcalvo in https://github.com/argilla-io/argilla/pull/5154
- [ENHANCEMENT/REFACTOR]
argilla: lazy resolution for dataset workspaces by @frascuchon in https://github.com/argilla-io/argilla/pull/5152 - [REFACTOR]:
argilla: Renamestatustoresponse.statusfor filtering using the SDK by @frascuchon in https://github.com/argilla-io/argilla/pull/5145 - [ENHANCEMENT] [REFACTOR] optimise and refactor SDK ingestion methods by @burtenshaw in https://github.com/argilla-io/argilla/pull/5107
- [BUGFIX]
argilla-server:awaiton similarity search when filtering response values without user by @frascuchon in https://github.com/argilla-io/argilla/pull/5159 - [BUGFIX] rename optional deps v1 by @frascuchon in https://github.com/argilla-io/argilla/pull/5164
- [REVERT] Rename
sdk-v1tolegacyby @frascuchon in https://github.com/argilla-io/argilla/pull/5168 - [RELEASES] 2.0.0rc2 by @frascuchon in https://github.com/argilla-io/argilla/pull/5160
Full Changelog: https://github.com/argilla-io/argilla/compare/v2.0.0rc1...v2.0.0rc2
- Python
Published by frascuchon almost 2 years ago
argilla - v2.0.0rc1
🔆 Release highlights
One Dataset to rule them all
The main difference between Argilla 1.x and Argilla 2.x is that we've converted the previous dataset types tailored for specific NLP tasks into a single highly-configurable Dataset class.
With the new Dataset you can combine multiple fields and question types, so you can adapt the UI for your specific project. This offers you more flexibility, while making Argilla easier to learn and maintain.
[!IMPORTANT] If you want to continue using legacy datasets in Argilla 2.x, you will need to convert them into v2
Dataset's as explained in this migration guide. This includes:DatasetForTextClassification,DatasetForTokenClassification, andDatasetForText2Text.
FeedbackDataset's do not need to be converted as they are already compatible with the Argilla v2 format.New SDK
We've redesigned our SDK with the idea to adapt it to the new single
Datasetclass and, most importantly, improve the user and developer experience.
The main goal of the new design is to make the SDK easier to use and learn, making the process to configure your dataset and get it up and running much simpler and faster.
To learn more about this new SDK, you can check: - our new documentation: https://argilla-io.github.io/argilla/latest/ - @burtenshaw's blog post: https://argilla.io/blog/introducing-argilla-new-sdk - this community meetup: https://www.youtube.com/watch?v=G3lZBtPrtgU
New UI layout
We have also revamped our UI for Argilla 2.0:
- We've redistributed the information in the Home page
- Datasets don't have Tasks, but Questions.
- Annotation guidelines and your progress are now accessible at all times within the dataset page.
- Dataset pages also have a new flexible layout, so you can change the size of different panes and expand or collapse the guidelines and progress.
- SpanQuestion's are now supported in the bulk view.
https://github.com/argilla-io/argilla/assets/126158523/f77e60de-5824-44ad-8b68-a087b223aa9d
New documentation
This new version of Argilla comes hand-in-hand with a revamped documentation: https://argilla-io.github.io/argilla/latest
We have applied the Diátaxis framework and UX principles with the hope to make this version cleaner and the information easier to find. Let us know what you think!
Share your thoughts with us!
[!NOTE] This is a release candidate ahead of the official Argilla 2.0 release. Try it out and let us know what you think. Find us in Discord or open a Github issue here.
What's Changed
- change: deleted unused API v0 code by @jfcalvo in https://github.com/argilla-io/argilla/pull/4852
- [RELEASE] 1.29.0 by @frascuchon in https://github.com/argilla-io/argilla/pull/4896
- 💀 feat/remove older datasets by @damianpumar in https://github.com/argilla-io/argilla/pull/4903
- feat: update sign-in page UI by @leiyre in https://github.com/argilla-io/argilla/pull/4915
- ✨ Endpoint migration by @damianpumar in https://github.com/argilla-io/argilla/pull/4883
- [FEATURE-BRANCH] refactor: improve API v1 error handling by @jfcalvo in https://github.com/argilla-io/argilla/pull/4887
- [FEAT BRANCH] Add
argilla-sdkproject by @frascuchon in https://github.com/argilla-io/argilla/pull/4891 - 💀 feat/improve dataset table by @damianpumar in https://github.com/argilla-io/argilla/pull/4917
- [REFACTOR] Remove old API calls for
argilla-sdkby @frascuchon in https://github.com/argilla-io/argilla/pull/4937 - feat: UI table styles by @leiyre in https://github.com/argilla-io/argilla/pull/4953
- docs: fastfit tutorial by @sdiazlor in https://github.com/argilla-io/argilla/pull/4958
- [DOCS] [FIX] Fix logging, typing and docstrings based on feedback by @burtenshaw in https://github.com/argilla-io/argilla/pull/4968
- [BUGFIX] ci: Configure argilla server deps properly by @frascuchon in https://github.com/argilla-io/argilla/pull/4962
- Fix/add-checked-types-to-io by @burtenshaw in https://github.com/argilla-io/argilla/pull/4974
- [CI] Configure build on push feat/ branches by @frascuchon in https://github.com/argilla-io/argilla/pull/4960
- refactor: API folder structure improvements by @jfcalvo in https://github.com/argilla-io/argilla/pull/4959
- feat: UI - remove sidebar components by @leiyre in https://github.com/argilla-io/argilla/pull/4978
- docs: add changelog by @sdiazlor in https://github.com/argilla-io/argilla/pull/4983
- docs: popular issues file generator by @sdiazlor in https://github.com/argilla-io/argilla/pull/4971
- 🚄 feat/improve performance metrics by @damianpumar in https://github.com/argilla-io/argilla/pull/4981
- Update ACCESS_TOKEN naming and documentation hierarchy guides by @davidberenstein1957 in https://github.com/argilla-io/argilla/pull/4990
- feat: UI - update colors and small screen padding by @leiyre in https://github.com/argilla-io/argilla/pull/4999
- feat: UI - remove all train components by @leiyre in https://github.com/argilla-io/argilla/pull/4998
- [FEATURE] SDK - Add support for response status by @frascuchon in https://github.com/argilla-io/argilla/pull/4977
- chore: add new argilla-server folder structure to README.md by @jfcalvo in https://github.com/argilla-io/argilla/pull/4976
- chore: set logger level to error to reduce noise from Elasticsearch and OpenSearch client libraries by @jfcalvo in https://github.com/argilla-io/argilla/pull/4979
- [FEATURE] remove random password generation when creating a user and password is not provided by @jfcalvo in https://github.com/argilla-io/argilla/pull/4993
- [ENHANCEMENT] stop warning on existing datasets by @burtenshaw in https://github.com/argilla-io/argilla/pull/4987
- feat: delete records by @sdiazlor in https://github.com/argilla-io/argilla/pull/4980
- docs: fastfit tutorial contains link to copied blog post by @sdiazlor in https://github.com/argilla-io/argilla/pull/4995
- [BUGFIX]
argilla-server: Query on response values without an user by @frascuchon in https://github.com/argilla-io/argilla/pull/5003 - [FIX] [ENHANCEMENT] logging records in notebook without ipython by @burtenshaw in https://github.com/argilla-io/argilla/pull/4988
- [FEATURE] Prepare new argilla package by @frascuchon in https://github.com/argilla-io/argilla/pull/5006
- [FIX] Docs: fix missing conflicts resolution by @frascuchon in https://github.com/argilla-io/argilla/pull/5007
- docs: 4920 v1 docs add banner with link to the new docs post refactor by @davidberenstein1957 in https://github.com/argilla-io/argilla/pull/5008
- [CHORE] Argilla server: Add missing CHANGELOG entry by @frascuchon in https://github.com/argilla-io/argilla/pull/5024
- [CHORE] Review and fix commit hooks by @frascuchon in https://github.com/argilla-io/argilla/pull/5027
- chore: execute pre-commit autoupdate manually by @jfcalvo in https://github.com/argilla-io/argilla/pull/5029
- [BUGFIX] Argilla server: looking for records with
external_idoridon bulk operations by @frascuchon in https://github.com/argilla-io/argilla/pull/5014 - [CI] Remove all tag and release events by @frascuchon in https://github.com/argilla-io/argilla/pull/5036
- ↔ feat/resizable layout by @damianpumar in https://github.com/argilla-io/argilla/pull/4921
- [CI] Prepare workflow for
argilla-v1- 1.29.0 by @frascuchon in https://github.com/argilla-io/argilla/pull/5032 - [CI] Prepare
argillarelease job by @frascuchon in https://github.com/argilla-io/argilla/pull/5037 - fix: UI - remove duplicated flexible border by @leiyre in https://github.com/argilla-io/argilla/pull/5038
- [CHORE] Argilla: remove pydantic warnings by @frascuchon in https://github.com/argilla-io/argilla/pull/5025
- fix: UI - border radius in progress bar by @leiyre in https://github.com/argilla-io/argilla/pull/5041
- 🎯 feat/enable bulk span by @damianpumar in https://github.com/argilla-io/argilla/pull/4986
- [ENHANCEMENTE]
argilla: support python 3.12 by @frascuchon in https://github.com/argilla-io/argilla/pull/5040 - [ENHANCEMENT] Argilla SDK: Updating record fields and vectors by @frascuchon in https://github.com/argilla-io/argilla/pull/5026
- [BUGFIX]
argilla: Prevent errors checkingDatasetinstances whendatasetsis not installed. by @frascuchon in https://github.com/argilla-io/argilla/pull/5045 - [CI] Prepare the
argilla-serverpackage release by @frascuchon in https://github.com/argilla-io/argilla/pull/5039 - [ENHANCEMENT] argilla: Remove attribute-like access by @frascuchon in https://github.com/argilla-io/argilla/pull/5048
- feat: UI - flexible layout QA by @leiyre in https://github.com/argilla-io/argilla/pull/5046
- [ENHANCEMENT] docs: Add howto update record vectors by @frascuchon in https://github.com/argilla-io/argilla/pull/5052
- [BUGFIX] argilla: Support export action with filtered records by @frascuchon in https://github.com/argilla-io/argilla/pull/5054
- feat: New illustraton and styles for login page by @leiyre in https://github.com/argilla-io/argilla/pull/5030
- [CI] docs: Configure docs publish for releases by @frascuchon in https://github.com/argilla-io/argilla/pull/5047
- [CI] Point dev version for docs to develop branch by @frascuchon in https://github.com/argilla-io/argilla/pull/5060
- [BUGFIX] ci: Define conditions to publish the release properly by @frascuchon in https://github.com/argilla-io/argilla/pull/5061
- [FEATURE-BRANCH] v2.0.0 changes by @jfcalvo in https://github.com/argilla-io/argilla/pull/4869
- [ENHANCEMENT] ci: remove paths for builds by @frascuchon in https://github.com/argilla-io/argilla/pull/5063
- [ENHANCEMENT] ci: Build docker images on PRs, release, and develop by @frascuchon in https://github.com/argilla-io/argilla/pull/5064
- [ENHANCEMENT] ci: Remove push branch patterns and PR trigger for
argillaandargilla-v1projects by @frascuchon in https://github.com/argilla-io/argilla/pull/5065 - docs: textcat tutorial and small doc fixes by @sdiazlor in https://github.com/argilla-io/argilla/pull/5055
- [CHORE] Set dev versions for argilla and argilla-server by @frascuchon in https://github.com/argilla-io/argilla/pull/5072
- docs: Documentation updates prior to release candidate 2.0 release by @davidberenstein1957 in https://github.com/argilla-io/argilla/pull/5068
- docs: how to use UI features by @sdiazlor in https://github.com/argilla-io/argilla/pull/5067
- [FEAT] Make adding and accessing suggestion and response from a record consistent by @burtenshaw in https://github.com/argilla-io/argilla/pull/5056
- [DOCS] add migration notebook to docs format by @burtenshaw in https://github.com/argilla-io/argilla/pull/5002
- [BUGFIX] docs: Set quickstart image tag fixed to 2.0 rc by @frascuchon in https://github.com/argilla-io/argilla/pull/5077
- docs: add note by @sdiazlor in https://github.com/argilla-io/argilla/pull/5078
- docs: final documentation changes by @davidberenstein1957 in https://github.com/argilla-io/argilla/pull/5080
- [RELEASE] 2.0.0rc1 by @frascuchon in https://github.com/argilla-io/argilla/pull/5074
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.29.0...v2.0.0rc1
- Python
Published by frascuchon about 2 years ago
argilla - v1.29.0
🔆 Release highlights
[!WARNING]
This will be the last release of Argilla v1. Starting from Argilla 2.0.0, we will only supportFeedbackDatasets which will be renamed toDataset. All other dataset types (DatasetForTextClassification,DatasetForTokenClassification, andDatasetForText2Text) will be deprecated. In the next release, we will provide more information and documentation on how to migrate all your datasets into Argilla 2.0Datasets.
Improved record search
Your search matches are now highlighted so you can see easily the result of your search. We’ve also added a selector for datasets with more than one record fields so you can choose whether to do the search on All fields or a specific one.
https://github.com/argilla-io/argilla/assets/126158523/b9af3313-a5c3-46b6-83b7-6624662dba04
Record information and metadata in the UI
You can now check all the information and metadata associated for each record directly in the UI.
https://github.com/argilla-io/argilla/assets/126158523/4a3cc4e0-8be7-4927-8d80-8cf84a0dce8b
What's Changed in v1.29.0
- feat: small UI improvements by @leiyre in https://github.com/argilla-io/argilla/pull/4770
- feat:update UI for settings page by @leiyre in https://github.com/argilla-io/argilla/pull/4767
- Fix: "cannot import name 'formatargspec' from 'inspect'" with Python 3.11 by @walter-hernandez in https://github.com/argilla-io/argilla/pull/4693
- 🐛 Ranking component not showing rankings by @damianpumar in https://github.com/argilla-io/argilla/pull/4775
- Adding LlamaIndex docs to integrations by @ignacioct in https://github.com/argilla-io/argilla/pull/4803
- docs: use FeedbackDataset in HF example by @sdiazlor in https://github.com/argilla-io/argilla/pull/4805
- docs: clarification/typo in tutorial by @sdiazlor in https://github.com/argilla-io/argilla/pull/4810
- Log if a dataset is deleted by @paulbauriegel in https://github.com/argilla-io/argilla/pull/4752
- ✨ Search text filtering by field by @damianpumar in https://github.com/argilla-io/argilla/pull/4771
- ✨ Add text search for fields by @damianpumar in https://github.com/argilla-io/argilla/pull/4831
- ✨ Fix shift issue and Letter S on issue reported by @damianpumar in https://github.com/argilla-io/argilla/pull/4836
- 🚑 Fix issue for intentional submission by @damianpumar in https://github.com/argilla-io/argilla/pull/4840
- ci: Mono repo setup by @frascuchon in https://github.com/argilla-io/argilla/pull/4742
- fix: add branches and tags to argilla-server.yml GitHub workflow by @jfcalvo in https://github.com/argilla-io/argilla/pull/4854
- fix: GitHub action names with typos by @jfcalvo in https://github.com/argilla-io/argilla/pull/4850
- fix: remove non necessary conditional to build argilla-server docker images by @jfcalvo in https://github.com/argilla-io/argilla/pull/4855
- chore: update datasets.py by @eltociear in https://github.com/argilla-io/argilla/pull/4842
- docs: Fix typo Argila -> Argilla by @louisguitton in https://github.com/argilla-io/argilla/pull/4870
- fix: add error code when searching for a record missing specific vector by @jfcalvo in https://github.com/argilla-io/argilla/pull/4856
- 🐛 Fix highlight multiple fields by @damianpumar in https://github.com/argilla-io/argilla/pull/4866
- feat: add support for value zero on rating questions by @jfcalvo in https://github.com/argilla-io/argilla/pull/4864
- fix(import): remove non-existent server module by @frascuchon in https://github.com/argilla-io/argilla/pull/4874
- 🐛 Fix pre selection by @damianpumar in https://github.com/argilla-io/argilla/pull/4872
- support for Python 3.12 by @nicoloboschi in https://github.com/argilla-io/argilla/pull/4837
- Search bar and highlight docs by @nataliaElv in https://github.com/argilla-io/argilla/pull/4882
- feat: UI Metadata info component by @leiyre in https://github.com/argilla-io/argilla/pull/4851
- [IMPROVEMENT] Update pip when building docker image by @frascuchon in https://github.com/argilla-io/argilla/pull/4907
- [BUGFIX] Filter record metadata value based on metadata property policies by @frascuchon in https://github.com/argilla-io/argilla/pull/4906
- feat: UI - metadata adjustments by @leiyre in https://github.com/argilla-io/argilla/pull/4905
- [REVIEW] Add missing entries in CHANGELOG files by @frascuchon in https://github.com/argilla-io/argilla/pull/4910
New Contributors
- @walter-hernandez made their first contribution in https://github.com/argilla-io/argilla/pull/4693
- @eltociear made their first contribution in https://github.com/argilla-io/argilla/pull/4842
- @louisguitton made their first contribution in https://github.com/argilla-io/argilla/pull/4870
- @nicoloboschi made their first contribution in https://github.com/argilla-io/argilla/pull/4837
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.28.0...v1.29.0
- Python
Published by frascuchon about 2 years ago
argilla - v1.28.0
🔆 Release highlights
Improved suggestions
https://github.com/argilla-io/argilla/assets/126158523/380004e0-28cb-409f-b11c-71d0e3b6e8bf
Multiple scores support for MultiLabelQuestion and RankingQuestion
MultiLabelQuestion and RankingQuestion now take one score per suggested label / value, making the scores easier to interpret. Learn more about suggestions and their scores here.
[!WARNING]
If you upgrade to this version all previous scores in suggestions for MultiLabelQuestion, RankingQuestion and SpanQuestion will turn to NULL, as they will not be valid in the new schema. Please, make sure you upload scores again if you want to use them.
See scores next to its label / value
Scores are now shown next to its label / value in all questions. This makes them more visible and easier to interpret.
Suggestions first
Now you can order labels in MultiLabelQuestion so that suggestions are always shown first. This will help you make sure that the most relevant labels are always at hand. Plus, if you’ve added scores to your labels, these will be ordered in descending order. To enable this, go to the Dataset Settings page > Questions and enable “Suggestions first” for the desired question.
SpanQuestion improvements
https://github.com/argilla-io/argilla/assets/126158523/fad7b9ca-3890-45ed-acc8-5b038a81db06
Pre-selection highlight
We’ve improved the way selections are shown. You can now see a highlight that represents what the final selection will look like while you’re dragging your mouse. This will help you with the selection speed and show you the difference between the token vs character selection.
[!NOTE] Remember that character-level spans are activated by holding
Shiftwhile doing the selection.
New label selector
We’ve improved the way the label selector works in the SpanQuestion when overlapping spans are enabled so it’s easier to add or correct labels. Simply click on the desired span to activate the selector and click on the label(s) that you want to add or remove.
Persistent storage warning
We’ve added a warning for Argilla instances deployed on Hugging Face Spaces to alert of data loss when the persistent storage is not enabled.
To learn more about this warning and how to disable it, go to our docs.
Changelog 1.28.0
Added
- Added suggestion multi score attribute. (#4730)
- Added order by suggestion first. (#4731)
- Added multi selection entity dropdown for span annotation overlap. (#4735)
- Added pre selection highlight for span annotation. (#4726)
- Added banner when persistent storage is not enabled. (#4744)
- Added support on Python SDK for new multi-label questions
labels_orderattribute. (#4757)
Changed
- Changed the way how Hugging Face space and user is showed in sign in. (#4748)
Fixed
- Fixed Korean character reversed. (#4753)
Fixed
- Fixed requirements for version of wrapt library conflicting with Python 3.11 (#4693)
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.27.0...v1.28.0
- Python
Published by jfcalvo about 2 years ago
argilla - v1.28.0
🔆 Release highlights
Improved suggestions
https://github.com/argilla-io/argilla/assets/126158523/380004e0-28cb-409f-b11c-71d0e3b6e8bf
Multiple scores support for MultiLabelQuestion and RankingQuestion
MultiLabelQuestion and RankingQuestion now take one score per suggested label / value, making the scores easier to interpret. Learn more about suggestions and their scores here.
[!WARNING]
If you upgrade to this version all previous scores in suggestions for MultiLabelQuestion, RankingQuestion and SpanQuestion will turn to NULL, as they will not be valid in the new schema. Please, make sure you upload scores again if you want to use them.
See scores next to its label / value
Scores are now shown next to its label / value in all questions. This makes them more visible and easier to interpret.
Suggestions first
Now you can order labels in MultiLabelQuestion so that suggestions are always shown first. This will help you make sure that the most relevant labels are always at hand. Plus, if you’ve added scores to your labels, these will be ordered in descending order. To enable this, go to the Dataset Settings page > Questions and enable “Suggestions first” for the desired question.
SpanQuestion improvements
https://github.com/argilla-io/argilla/assets/126158523/fad7b9ca-3890-45ed-acc8-5b038a81db06
Pre-selection highlight
We’ve improved the way selections are shown. You can now see a highlight that represents what the final selection will look like while you’re dragging your mouse. This will help you with the selection speed and show you the difference between the token vs character selection.
[!NOTE] Remember that character-level spans are activated by holding
Shiftwhile doing the selection.
New label selector
We’ve improved the way the label selector works in the SpanQuestion when overlapping spans are enabled so it’s easier to add or correct labels. Simply click on the desired span to activate the selector and click on the label(s) that you want to add or remove.
Persistent storage warning
We’ve added a warning for Argilla instances deployed on Hugging Face Spaces to alert of data loss when the persistent storage is not enabled.
To learn more about this warning and how to disable it, go to our docs.
Changelog 1.28.0
Added
- Added suggestion multi score attribute. (#4730)
- Added order by suggestion first. (#4731)
- Added multi selection entity dropdown for span annotation overlap. (#4735)
- Added pre selection highlight for span annotation. (#4726)
- Added banner when persistent storage is not enabled. (#4744)
- Added support on Python SDK for new multi-label questions
labels_orderattribute. (#4757)
Changed
- Changed the way how Hugging Face space and user is showed in sign in. (#4748)
Fixed
- Fixed Korean character reversed. (#4753)
Fixed
- Fixed requirements for version of wrapt library conflicting with Python 3.11 (#4693)
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.27.0...v1.28.0
- Python
Published by jfcalvo about 2 years ago
argilla - v1.27.0
🔆 Release highlights
Overlapping spans
We are finally releasing a much expected feature: overlapping spans. This allows you to draw more than one span over the same token(s)/character(s).
https://github.com/argilla-io/argilla/assets/126158523/3aeb6c6c-b348-4b3d-be67-483636c76293
To try them out, set up a SpanQuestion with the argument allow_overlap=True like this:
python
dataset = rg.FeedbackDataset(
fields = [rg.TextField(name="text")]
questions = [
rg.SpanQuestion(
name="spans",
labels=["label1", "label2", "label3"],
field="text"
)
]
)
Learn more about configuring this and other question types here.
Global progress bars
We’ve included a new column in our home page that offers the global progress of your datasets, so that you can see at a glance what datasets are closer to completion.
These bars show progress by grouping records based on the status of their responses:
- Submitted: Records where all responses have the
submittedstatus. - Discarded: Records where all responses have the
discardedstatus. - Conflicting: Records with at least one
submittedand onediscardedresponse. - Left: All other records that have no
submittedordiscardedresponses. These may be inpendingordraft.
Suggestions got a new look
We’ve improved the way suggestions are shown in the UI to make their purpose clearer: now you can identify each suggestion with a sparkle icon ✨ .
The behavior is still the same:
- suggested values will appear pre-filled responses and marked with the sparkle icon.
- make changes the the incorrect suggestions, then save as a draft or submit.
- the icon will stay to mark the suggestions so you can compare the final response with the suggested one.
Increased label limits
We’ve increased the limit of labels you can use in Label, Multilabel and Span questions to 500. If you need to go beyond that number, you can set up a custom limit using the following environment variables:
ARGILLA_LABEL_SELECTION_OPTIONS_MAX_ITEMSto set the limits in label and multi label questions.ARGILLA_SPAN_OPTIONS_MAX_ITEMSto set the limit in span questions.
[!WARNING] The UI has been optimized to support up to 1000 labels. If you go beyond this limit, the UI may not be as responsive.
Learn more about this and other environment variables here.
Argilla auf Deutsch!
Thanks to our contributor @paulbauriegel you can now use Argilla fully in German! If that is the main language of your browser, there is nothing you need to do, the UI will automatically detect that and switch to German.
Would you like to translate Argilla to your own language? Reach out to us and we'll help you!
Changelog 1.27.0
Added
- Added Allow overlap spans in the
FeedbackDataset(#4668) - Added
allow_overlappingparameter for span questions. (#4697) - Added overall progress bar on
Datasetstable (#4696) - Added German language translation (#4688)
Changed
- New UI design for suggestions (#4682)
Fixed
- Improve performance for more than 250 labels (#4702)
New Contributors
- @stevengans made their first contribution in https://github.com/argilla-io/argilla/pull/4646
- @tim-win made their first contribution in https://github.com/argilla-io/argilla/pull/4672
- @strickvl made their first contribution in https://github.com/argilla-io/argilla/pull/4675
- @paulbauriegel made their first contribution in https://github.com/argilla-io/argilla/pull/4688
- @davanstrien made their first contribution in https://github.com/argilla-io/argilla/pull/4687
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.26.1...v1.27.0
- Python
Published by damianpumar about 2 years ago
argilla - v1.26.0
🔆 Release highlights
Spans question
We've added a new type of question to Feedback Datasets: the SpanQuestion. This type of question allows you to highlight portions of text in a specific field and apply a label. It is specially useful for token classification (like NER or POS tagging) and information extraction tasks.
https://github.com/argilla-io/argilla/assets/126158523/d3821d49-6da0-4488-99e2-068d7411268a
With this type of question you can:
✨ Provide suggested spans with a confidence score, so your team doesn't need to start from scratch.
⌨️ Choose a label using your mouse or with the keyboard shortcut provided next to the label.
🖱️ Draw a span by dragging your mouse over the parts of the text you want to select or if it's a single token, just double-click on it.
🪄 Forget about mistakes with token boundaries. The UI will snap your spans to token boundaries for you.
🔎 Annotate at character-level when you need more fine-grained spans. Hold the Shift key while drawing the span and the resulting span will start and end in the exact boundaries of your selection.
✔️ Quickly change the label of a span by clicking on the label name and selecting the correct one from the dropdown.
🖍️ Correct a span at the speed of light by simply drawing the correct span over it. The new span will overwrite the old one.
🧼 Remove labels by hovering over the label name in the span and then click on the 𐢫 on the left hand side.
Here's an example of what your dataset would look like from the SDK:
```python import argilla as rg from argilla.client.feedback.schemas import SpanValueSchema
connect to your Argilla instance
rg.init(...)
create a dataset with a span question
dataset = rg.FeedbackDataset( fields=[rg.TextField(name="text"), questions=[ rg.SpanQuestion( name="entities", title="Highlight the entities in the text:", labels={"PER": "Person", "ORG": "Organization", "EVE": "Event"}, # or ["PER", "ORG", "EVE"] field="text", # the field where you want to do the span annotation required=True ) ] )
create a record with suggested spans
record = rg.FeedbackRecord( fields={"text": "This is the text of the record"} suggestions = [ { "questionname": "entities", "value": [ SpanValueSchema( start=0, # position of the first character of the span end=10, # position of the character right after the end of the span label="ORG", score=1.0 ) ], "agent": "mymodel", } ] )
add records to the dataset and push to Argilla
dataset.addrecords([record]) dataset.pushto_argilla(...) ```
To learn more about this and all the other questions available in Feedback Datasets, check out our documentation on: - Defining questions - Working with suggestions and responses - Annotating Feedback Datasets
Changelog 1.26.0
Added
- If you expand the labels of a
single or multilabel Question, the state is maintained during the entire annotation process. (#4630) - Added support for span questions in the Python SDK. (#4617)
- Added support for span values in suggestions and responses. (#4623)
- Added
spanquestions forFeedbackDataset. (#4622) - Added
ARGILLA_CACHE_DIRenvironment variable to configure the client cache directory. (#4509)
Fixed
- Fixed contextualized workspaces. (#4665)
- Fixed prepare for training when passing
RankingValueSchemainstances to suggestions. (#4628) - Fixed parsing ranking values in suggestions from HF datasets. (#4629)
- Fixed reading description from API response payload. (#4632)
- Fixed pulling (n*chunk_size)+1 records when using
ds.pullor iterating over the dataset. (#4662) - Fixed client's resolution of enum values when calling the Search and Metrics api, to support Python >=3.11 enum handling. (#4672)
New Contributors
- @davidefiocco made their first contribution in https://github.com/argilla-io/argilla/pull/4639
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.25.0...v1.26.0
- Python
Published by jfcalvo over 2 years ago
argilla - v1.25.0
🔆 Release highlights
Reorder labels
admin and owner users can now change the order in which labels appear in the question form. To do this, go to the Questions tab inside Dataset Settings and move the labels until they are in the desired order.
https://github.com/argilla-io/argilla/assets/126158523/40f382a5-35c6-4bea-b15c-f001f539940d
Aligned SDK status filter
The missing status has been removed from the SDK filters. To filter records that don't have responses you will now need to use the pending status like so:
python
filtered_dataset = dataset.filter_by(response_status="pending")
Learn more about how to use this filter in our docs
Pandas 2.0 support
We’ve removed the limitation to use pandas <2.0.0 so you can now use Argilla with pandas v1 or v2 safely.
Changelog 1.25.0
[!NOTE] For changes in the argilla-server module, visit the argilla-server release notes
Added
- Reorder labels in
dataset settings pagefor single/multi label questions (#4598) - Added pandas v2 support using the python SDK. (#4600)
Removed
- Removed
missingresponse for status filter. Usependinginstead. (#4533)
Fixed
- Fixed FloatMetadataProperty: value is not a valid float (#4570)
- Fixed redirect to
user-settingsinstead of 404user_settings(#4609)
New Contributors
- @julien-c made their first contribution in https://github.com/argilla-io/argilla/pull/4582
- @7flash made their first contribution in https://github.com/argilla-io/argilla/pull/4504
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.24.0....v1.25.0
- Python
Published by frascuchon over 2 years ago
argilla - v1.24.0
[!Note] This release does not contain any new features, but it includes a major change in the argilla server. The package is using the
argilla-serverdependency defined here.
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.23.1...v1.24.0
- Python
Published by frascuchon over 2 years ago
argilla - v1.23.1
1.23.1
Fixed
- Fixed Responsive view for Feedback Datasets. (#4579)
New Contributors
- @CpHaddock made their first contribution at https://github.com/argilla-io/argilla/pull/4484
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.23.0...v1.23.1
- Python
Published by frascuchon over 2 years ago
argilla - v1.23.0
🔆 Release highlights
Hugging Face OAuth
You can now set up OAuth in your Argilla Hugging Face spaces. This is a simple way to have your team members or collaborators in crowdsourced projects sign in and log in to your space using their Hugging face accounts.
To learn how to set up Hugging Face OAuth for your Argilla Space, go to our docs.
Bulk actions for filter results
We’ve added an improvement for our bulk view so you can perform actions on all results from a filter (or a combination of them!).
To use this, go to the bulk view and apply some filter(s) of your choice. If the results are more than the records seen in the current page, when you click the checkbox you will see the option to select all of the results. Then, you can give responses, discard, save a draft and even submit all of the records at once!
Embed PDFs in a TextField
We’ve added the pdf_to_html function in our utilities so you can easily embed a PDF reader within a TextField using markdown.
This function accepts either the file path, the URLs or the file's byte data and returns the corresponding HTML to render the PDF within the Argilla user interface.
Learn more about how to use this feature here.
Changelog 1.23.0
Added
- Added bulk annotation by filter criteria. (#4516)
- Automatically fetch new datasets on focus tab. (#4514)
- API v1 responses returning
Recordschema now always includedataset_idas attribute. (#4482) - API v1 responses returning
Responseschema now always includerecord_idas attribute. (#4482) - API v1 responses returning
Questionschema now always includedataset_idattribute. (#4487) - API v1 responses returning
Fieldschema now always includedataset_idattribute. (#4488) - API v1 responses returning
MetadataPropertyschema now always includedataset_idattribute. (#4489) - API v1 responses returning
VectorSettingsschema now always includedataset_idattribute. (#4490) - Added
pdf_to_htmlfunction to.html_utilsmodule that convert PDFs to dataURL to be able to render them in tha Argilla UI. (#4481) - Added
ARGILLA_AUTH_SECRET_KEYenvironment variable. (#4539) - Added
ARGILLA_AUTH_ALGORITHMenvironment variable. (#4539) - Added
ARGILLA_AUTH_TOKEN_EXPIRATIONenvironment variable. (#4539) - Added
ARGILLA_AUTH_OAUTH_CFGenvironment variable. (#4546) - Added OAuth2 support for HuggingFace Hub. (#4546)
Deprecated
- Deprecated
ARGILLA_LOCAL_AUTH_*environment variables. Will be removed in the release v1.25.0. (#4539)
Changed
- Changed regex pattern for
usernameattribute inUserCreate. Now uppercase letters are allowed. (#4544)
Removed
- Remove sending
Authorizationheader from python SDK requests. (#4535)
Fixed
- Fixed keyboard shortcut for label questions. (#4530)
New Contributors
- @gardner made their first contribution in https://github.com/argilla-io/argilla/pull/4527
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.22.0...v1.23.0
- Python
Published by jfcalvo over 2 years ago
argilla - v1.22.0
🔆 Release Highlights
Bulk actions in Feedback Task datasets
Our signature bulk actions are now available for Feedback datasets!
https://user-images.githubusercontent.com/126158523/297772506-97d83a54-ea3f-4700-acd6-ff9e349ade63.mp4
Switch between Focus and Bulk depending on your needs:
- In the Focus view, you can navigate and respond to records individually. This is ideal for closely examining and giving responses to each record.
- The Bulk view allows you to see multiple records on the same page. You can select all or some of them and perform actions in bulk, such as applying a label, saving responses, submitting, or discarding. You can use this feature along with filters and similarity search to process a list of records in bulk.
For now, this is only available in the Pending queue, but rest assured, bulk actions will be improved and extended to other queues in upcoming releases.
Read more about our Focus and Bulk views here.
Sorting rating values
We now support sorting records in the Argilla UI based on the values of Rating questions (both suggestions and responses):

Learn about this and other filters in our docs.
Out-of-the-box embedding support
It’s now easier than ever to add vector embeddings to your records with the new Sentence Transformers integration.
Just choose a model from the Hugging Face hub and use our SentenceTransformersExtractor to add vectors to your dataset:
```python import argilla as rg from argilla.client.feedback.integrations.sentencetransformers import SentenceTransformersExtractor
Connect to Argilla
rg.init( apiurl="http://localhost:6900", apikey="owner.apikey", workspace="my_workspace" )
Initialize the SentenceTransformersExtractor
ste = SentenceTransformersExtractor( model = "TaylorAI/bge-micro-v2", # Use a model from https://huggingface.co/models?library=sentence-transformers show_progress = False, )
Load a dataset from your Argilla instance
dsremote = rg.FeedbackDataset.fromargilla("my_dataset")
Update the dataset
ste.updatedataset( dataset=dsremote, fields=["context"], # Only update the context field update_records=True, # Update the records in the dataset overwrite=False, # Overwrite existing fields ) ```
Learn more about this functionality in this tutorial.
Changelog 1.22.0
Added
- Added Bulk annotation support. (#4333)
- Restore filters from feedback dataset settings. (#4461)
- Warning on feedback dataset settings when leaving page with unsaved changes. (#4461)
- Added pydantic v2 support using the python SDK. (#4459)
- Added
vector_settingsto the__repr__method of theFeedbackDatasetandRemoteFeedbackDataset. (#4454) - Added integration for
sentence-transformersusingSentenceTransformersExtractorto configurevector_settingsinFeedbackDatasetandFeedbackRecord. (#4454)
Changed
- Module
argilla.cli.serverdefinitions have been moved toargilla.server.climodule. (#4472) - [breaking] Changed
vector_settings_by_namefor genericproperty_by_nameusage, which will returnNoneinstead of raising an error. (#4454) - The constant definition
ES_INDEX_REGEX_PATTERNin moduleargilla._constantsis now private. (#4472) nanvalues in metadata properties will raise a 422 error when creating/updating records. (#4300)Nonevalues are now allowed in metadata properties. (#4300)
Fixed
- Paginating to a new record, automatically scrolls down to selected form area. (#4333)
Deprecated
- The
missingresponse status for filtering records is deprecated and will be removed in the release v1.24.0. Usependinginstead. (#4433)
Removed
- The deprecated
python -m argilla databasecommand has been removed. (#4472)
New Contributors
- @Piyush-Kumar-Ghosh made their first contribution in https://github.com/argilla-io/argilla/pull/4463
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.21.0...v1.22.0
- Python
Published by frascuchon over 2 years ago
argilla - v1.21.0
1.21.0
Added
- Added new draft queue for annotation view (#4334)
- Added annotation metrics module for the
FeedbackDataset(argilla.client.feedback.metrics). (#4175). - Added strategy to handle and translate errors from the server for
401HTTP status code` (#4362) - Added integration for
textdescriptivesusingTextDescriptivesExtractorto configuremetadata_propertiesinFeedbackDatasetandFeedbackRecord. (#4400). Contributed by @m-newhauser - Added
POST /api/v1/me/responses/bulkendpoint to create responses in bulk for current user. (#4380) - Added list support for term metadata properties. (Closes #4359)
- Added new CLI task to reindex datasets and records into the search engine. (#4404)
- Added
httpx_extra_kwargsargument torg.initandArgillato allow passing extra arguments tohttpx.Clientused byArgilla. (#4440)
Changed
- More productive and simpler shortcuts system (#4215)
- Move
ArgillaSingleton,initandactive_clientto a new modulesingleton. (#4347) - Updated
argilla.loadfunctions to also work withFeedbackDatasets. (#4347) - [breaking] Updated
argilla.deletefunctions to also work withFeedbackDatasets. It now raises an error if the dataset does not exist. (#4347) - Updated
argilla.list_datasetsfunctions to also work withFeedbackDatasets. (#4347)
Fixed
- Fixed error in
TextClassificationSettings.from_dictmethod in which thelabel_schemacreated was a list ofdictinstead of a list ofstr. (#4347) - Fixed total records on pagination component (#4424)
Removed
- Removed
draftauto save for annotation view (#4334)
- Python
Published by damianpumar over 2 years ago
argilla - v1.20.0
🔆 Release highlights
Responses and suggestions filters
We’ve added new filters in the Argilla UI to filter records within Feedback datasets based on response values and suggestions information. It is also possible to sort records based on suggestion scores. This is available for questions of the type: LabelQuestion, MultiLabelQuestion and RatingQuestion.
Utils module
Assign records
We added several methods to assign records to annotators via controlled overlap assign_records and assign_workspaces.
```python from argilla.client.feedback.utils import assign_records
assignments = assign_records( users=users, records=records, overlap=1, shuffle=True ) ```
```python from argilla.client.feedback.utils import assign_workspaces
assignments = assignworkspaces( assignments=assignments, workspacetype="individual" )
for username, records in assignments.items(): dataset = rg.FeedbackDataset( fields=fields, questions=questions, metadata=metadata, vectorsettings=vectorsettings, guidelines=guidelines ) dataset.addrecords(records) remotedataset = dataset.pushtoargilla(name="my_dataset", workspace=username) ```
Multi-Modal DataURLs for images, video and audio
Argilla supports basic handling of video, audio, and images within markdown fields, provided they are formatted in HTML. To facilitate this, we offer three functions: video_to_html, audio_to_html, and image_to_html. Note that performance differs per browser and database configuration.
```python from argilla.client.feedback.utils import audiotohtml, imagetohtml, videotohtml
Configure the FeedbackDataset
dsmultimodal = rg.FeedbackDataset( fields=[rg.TextField(name="content", usemarkdown=True, required=True)], questions=[rg.TextQuestion(name="description", title="Describe the content of the media:", usemarkdown=True, required=True)], )
Add the records
records = [ rg.FeedbackRecord(fields={"content": videotohtml("/content/snapshot.mp4")}), rg.FeedbackRecord(fields={"content": audiotohtml("/content/sea.wav")}), rg.FeedbackRecord(fields={"content": imagetohtml("/content/peacock.jpg")}), ] dsmultimodal.add_records(records)
Push the dataset to Argilla
dsmultimodal = dsmultimodal.pushtoargilla("multi-modal-basic", workspace="admin") ```
Token Highlights
You can also add custom highlights to the text by using create_token_highlights and a custom color map.
```python from argilla.client.feedback.utils import createtokenhighlights
tokens = ["This", "is", "a", "test"] weights = [0.1, 0.2, 0.3, 0.4] html = createtokenhighlights(tokens, weights, cmap=customRGB) # 'viridis' by default ```
1.20.0 Changelog
Added
- Added
GET /api/v1/datasets/:dataset_id/records/search/suggestions/optionsendpoint to return suggestion available options for searching. (#4260) - Added
metadata_propertiesto the__repr__method of theFeedbackDatasetandRemoteFeedbackDataset.(#4192). - Added
get_model_kwargs,get_trainer_kwargs,get_trainer_model,get_trainer_tokenizerandget_trainer-methods to theArgillaTrainerto improve interoperability across frameworks. (#4214). - Added additional formatting checks to the
ArgillaTrainerto allow for better interoperability ofdefaultsandformatting_funcusage. (#4214). - Added a warning to the
update_config-method ofArgillaTrainerto emphasize if thekwargswere updated correctly. (#4214). - Added
argilla.client.feedback.utilsmodule withhtml_utils(this mainly includesvideo/audio/image_to_htmlthat convert media to dataURL to be able to render them in tha Argilla UI andcreate_token_highlightsto highlight tokens in a custom way. Both work on TextQuestion and TextField with usemarkdown=True) andassignments(this mainly includes `assignrecordsto assign records according to a number of annotators and records, an overlap and the shuffle option; andassign_workspace` to assign and create if needed a workspace according to the record assignment). (#4121)
Fixed
- Fixed error in
ArgillaTrainer, with numerical labels, usingRatingQuestioninstead ofRankingQuestion(#4171) - Fixed error in
ArgillaTrainer, now we can train forextractive_question_answeringusing a validation sample (#4204) - Fixed error in
ArgillaTrainer, when training forsentence-similarityit didn't work with a list of values per record (#4211) - Fixed error in the unification strategy for
RankingQuestion(#4295) - Fixed
TextClassificationSettings.labels_schemaorder was not being preserved. Closes #3828 (#4332) - Fixed error when requesting non-existing API endpoints. Closes #4073 (#4325)
- Fixed error when passing
draftresponses to create records endpoint. (#4354)
Changed
- [breaking] Suggestions
agentfield only accepts now some specific characters and a limited length. (#4265) - [breaking] Suggestions
scorefield only accepts now float values in the range0to1. (#4266) - Updated
POST /api/v1/dataset/:dataset_id/records/searchendpoint to support optionalqueryattribute. (#4327) - Updated
POST /api/v1/dataset/:dataset_id/records/searchendpoint to supportfilterandsortattributes. (#4327) - Updated
POST /api/v1/me/datasets/:dataset_id/records/searchendpoint to support optionalqueryattribute. (#4270) - Updated
POST /api/v1/me/datasets/:dataset_id/records/searchendpoint to supportfilterandsortattributes. (#4270) - Changed the logging style while pulling and pushing
FeedbackDatasetto Argilla fromtqdmstyle torich. (#4267). Contributed by @zucchini-nlp. - Updated
push_to_argillato printreprof the pushedRemoteFeedbackDatasetafter push and changedshow_progressto True by default. (#4223) - Changed
modelsandtokenizerfor theArgillaTrainerto explicitly allow for changing them when needed. (#4214).
- Python
Published by davidberenstein1957 over 2 years ago
argilla - v1.19.0
🔆 Release highlights
🚨 Breaking changes
We have chosen to disable raining a ValueError during the FeedbackDataset.*_by_name(): FeedbackDataset.question_by_name(), FeedbackDataset.field_by_name() and FeedbackDataset.metadata_property_by_name. Instead, these methods will now return None when no match is found. This change is backwards compatible with previous versions of Argilla but might break your code if you are relying on the ValueError to be raised.
Similarity search
If you have included vectors and vector settings in your dataset, you can use the similarity search features within that dataset.
In the Argilla UI, you can find records that are similar to each other using the Find similar button at the top right corner of the record card. Here's how to do it:
In the SDK, you can do the same like this:
```python ds = rg.FeedbackDataset.fromargilla("mydataset", workspace="my_workspace")
using another record
similarrecords = ds.findsimilarrecords( vectorname="myvector", record=ds.records[0], maxresults=5 )
work with the resulting tuples
for record, score in similar_records: ... ```
You can also find records that are similar to a given text, but bear in mind that the dimensions of the resulting vector should be equal to that of the vector used in the dataset records:
python
similar_records = ds.find_similar_records(
vector_name="my_vector",
value=embedder_model.embeddings("My text is here")
# value=embedder_model.embeddings("My text is here").tolist() # for numpy arrays
)
Add vectors to your FeedbackDataset
You can now add vectors to your Feedback dataset and records to enable similarity search.
To do that, first, you need to add vector settings to your dataset:
python
dataset = rg.FeedbackDataset(
fields=[...],
questions=[....],
vector_settings=[
rg.VectorSettings(
name="my_vectors",
dimensions=768,
tite="My Vectors" #optional
)
]
)
Then, you can add vectors to your records where the key matches the name of your vector settings and the value is a List[float]:
python
record = rg.FeedbackRecord(
fields={...},
vectors={"my_vectors": [...]}
)
⚠️ For vector search in OpenSearch, the filtering applied is using a post_filter step, since there is a bug that makes queries fail using filtering + KNN from Argilla.
See https://github.com/opensearch-project/k-NN/issues/1286
[TODO: Add a link to the docs]
FeedbackDataset
We added a show_progress argument to from_huggingface() method to make the progress bar for the parsing records process optional.
RemoteFeedbackDataset
We have added additional support for the pull()-method of RemoteFeedbackDataset. It is now possible to pull a RemoteFeedbackDataset with a specific max_records-argument. In combination with the earlier introduced filter_by and sorty_by this allows for more fine-grained control over the records that are pulled from Argilla.
ArgillaTrainer
The ArgillaTrainer class has been updated to support additional features. Hugging Face models can now be shared to the Hugging Face Hub directly from the ArgillaTrainer.push_to_huggingface-method. Additionally, we have included filter_by, sort_by, and max_records arguments to the `ArgillaTrainer '-initialisation-method to allow for more fine-grained control over the records used for training.
```python from argilla import SortBy
trainer = ArgillaTrainer( dataset=dataset, task=task, framework="setfit", filterby={"responsestatus": ["submitted"]}, sortby=[SortBy(field="metadata.my-metadata", order="asc")], maxrecords=1000 ) ```
🎨 UI improvements
- We have changed the layout of the filters for a slimmer and more flexible component that will host more filter types in the future without being disruptive.
- We have fixed a small UI bug where larger svg-images were pushed out of the visible screen, leading to a bad user experience.
- There is sorting support based on
inserted_atandupdated_atdatetime fields.
1.19.0 Changelog
Added
- Added
POST /api/v1/datasets/:dataset_id/records/searchendpoint to search for records without user context, including responses by all users. (#4143) - Added
POST /api/v1/datasets/:dataset_id/vectors-settingsendpoint for creating vector settings for a dataset. (#3776) - Added
GET /api/v1/datasets/:dataset_id/vectors-settingsendpoint for listing the vectors settings for a dataset. (#3776) - Added
DELETE /api/v1/vectors-settings/:vector_settings_idendpoint for deleting a vector settings. (#3776) - Added
PATCH /api/v1/vectors-settings/:vector_settings_idendpoint for updating a vector settings. (#4092) - Added
GET /api/v1/records/:record_idendpoint to get a specific record. (#4039) - Added support to include vectors for
GET /api/v1/datasets/:dataset_id/recordsendpoint response usingincludequery param. (#4063) - Added support to include vectors for
GET /api/v1/me/datasets/:dataset_id/recordsendpoint response usingincludequery param. (#4063) - Added support to include vectors for
POST /api/v1/me/datasets/:dataset_id/records/searchendpoint response usingincludequery param. (#4063) - Added
show_progressargument tofrom_huggingface()method to make the progress bar for parsing records process optional.(#4132). - Added a progress bar for parsing records process to
from_huggingface()method withtrangeintqdm.(#4132). - Added to sort by
inserted_atorupdated_atfor datasets with no metadata. (4147) - Added
max_recordsargument topull()method forRemoteFeedbackDataset.(#4074) - Added functionality to push your models to the Hugging Face hub with
ArgillaTrainer.push_to_huggingface(#3976). Contributed by @Racso-3141. - Added
filter_byargument toArgillaTrainerto filter byresponse_status(#4120). - Added
sort_byargument toArgillaTrainerto sort bymetadata(#4120). - Added
max_recordsargument toArgillaTrainerto limit record used for training (#4120). - Added
add_vector_settingsmethod to local and remoteFeedbackDataset. (#4055) - Added
update_vectors_settingsmethod to local and remoteFeedbackDataset. (#4122) - Added
delete_vectors_settingsmethod to local and remoteFeedbackDataset. (#4130) - Added
vector_settings_by_namemethod to local and remoteFeedbackDataset. (#4055) - Added
find_similar_recordsmethod to local and remoteFeedbackDataset. (#4023) - Added
ARGILLA_SEARCH_ENGINEenvironment variable to configure the search engine to use. (#4019)
Changed
- [breaking] Remove support for Elasticsearch < 8.5 and OpenSearch < 2.4. (#4173)
- [breaking] Users working with OpenSearch engines must use version >=2.4 and set
ARGILLA_SEARCH_ENGINE=opensearch. (#4019 and #4111) - [breaking] Changed
FeedbackDataset.*_by_name()methods to returnNonewhen no match is found (#4101). - [breaking]
limitquery parameter forGET /api/v1/datasets/:dataset_id/recordsendpoint is now only accepting values greater or equal than1and less or equal than1000. (#4143) - [breaking]
limitquery parameter forGET /api/v1/me/datasets/:dataset_id/recordsendpoint is now only accepting values greater or equal than1and less or equal than1000. (#4143) - Update
GET /api/v1/datasets/:dataset_id/recordsendpoint to fetch record using the search engine. (#4142) - Update
GET /api/v1/me/datasets/:dataset_id/recordsendpoint to fetch record using the search engine. (#4142) - Update
POST /api/v1/datasets/:dataset_id/recordsendpoint to allow to create records withvectors(#4022) - Update
PATCH /api/v1/datasets/:dataset_idendpoint to allow updatingallow_extra_metadataattribute. (#4112) - Update
PATCH /api/v1/datasets/:dataset_id/recordsendpoint to allow to update records withvectors. (#4062) - Update
PATCH /api/v1/records/:record_idendpoint to allow to update record withvectors. (#4062) - Update
POST /api/v1/me/datasets/:dataset_id/records/searchendpoint to allow to search records with vectors. (#4019) - Update
BaseElasticAndOpenSearchEngine.index_recordsmethod to also index record vectors. (#4062) - Update
FeedbackDataset.__init__to allow passing a list of vector settings. (#4055) - Update
FeedbackDataset.push_to_argillato also push vector settings. (#4055) - Update
FeedbackDatasetRecordto support the creation of records with vectors. (#4043) - Using cosine similarity to compute similarity between vectors. (#4124)
Fixed
- Fixed svg images out of screen with too large images (#4047)
- Fixed creating records with responses from multiple users. Closes #3746 and #3808 (#4142)
- Fixed deleting or updating responses as an owner for annotators. (Commit 403a66d)
- Fixed passing user_id when getting records by id. (Commit 98c7927)
- Fixed non-basic tags serialized when pushing a dataset to the Hugging Face Hub. Closes #4089 (#4200)
Contributors
- @Racso-3141 Added a progress bar for parsing records process to
from_huggingface()method withtrangeintqdm.(#4132).
- Python
Published by davidberenstein1957 over 2 years ago
argilla - v1.18.0
🔆 Release highlights
💾 Add metadata properties to Feedback Datasets
You can now filter and sort records in Feedback Datasets in the UI and Python SDK using the metadata included in the records. To do that, you will first need to set up a MetadataProperty in your dataset:
```python
set up a dataset including metadata properties
dataset = rg.FeedbackDataset( fields=[ rg.TextField(name="prompt"), rg.TextField(name="response"), ], questions=[ rg.TextQuestion(name="question") ], metadataproperties=[ rg.TermsMetadataProperty(name="source"), rg.IntegerMetadataProperty(name="responselength", title="Response length") ] ) ```
Learn more about how to define metadata properties or adding or deleting metadata properties in existing datasets.
This will read the metadata in the records that match the name of the metadata property. Any other metadata present in the record not matching a metadata property will be saved but not available to use in the filtering and sorting features in the UI or SDK.
```python
create a record with metadata
record = rg.FeedbackRecord( fields={ "prompt": "Why can camels survive long without water?", "response": "Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time." }, metadata={"source": "wikipedia", "responselength": 105, "myhidden_metadata": "hidden metadata"} ) ```
Learn more about how to create records with metadata and how to add, modify or delete metadata from existing records.
🗃️ Filter and sort records using metadata in Feedback Datasets
In the Python SDK, you can filter and sort records based on the Metadata Properties that you set up for your dataset. You can combine multiple filters and sorts. Here is an example of how you could use them:
python
filtered_records = remote.filter_by(
metadata_filters=[
rg.IntegerMetadataFilter(
name="response_length",
ge=500, # optional: greater or equal to
le=1000 # optional: lower or equal to
),
rg.TermsMetadataFilter(
name="source",
values=["wikipedia", "wikihow"]
)
]
).sort_by(
[
rg.SortBy(
field="response_length",
order="desc" # for descending or "asc" for ascending
)
]
In the UI, simply use the Metadata and Sort components to filter and sort records like this:
https://github.com/argilla-io/argilla/assets/126158523/6a5a7984-425d-4f1a-b0f7-7cc2bb7e4a0a
Read more about filtering and sorting in Feedback Datasets.
⚠️ Breaking change using SQLite as backend in a docker deployment
From version 1.17.0 a new argilla os user is configured for the provided docker images. If you are using the docker deployment and you want to upload to this version from versions older than v1.17.0 (If you already updated from v1.17.0 this step was already applied - see Release Notes), you should change permissions to the SQLite db file, before upgrading the version. You can do it with the following action:
bash
docker exec --user root <argilla_server_container_id> /bin/bash -c 'chmod -R 777 "$ARGILLA_HOME_PATH"'
Note: You can find the docker container id by running:
bash
docker ps | grep -i argilla-server
bash
713973693fb7 argilla/argilla-server:v1.16.0 "/bin/bash start_arg…" 11 hours ago Up 7 minutes 0.0.0.0:6900->6900/tcp docker-argilla-1
Once the version is upgraded, we recommend to provided proper security access to this folder by setting the user and group to the new argilla user:
bash
docker exec --user root <argilla_server_container_id> /bin/bash -c 'chown -R argilla:argilla "$ARGILLA_HOME_PATH"'
1.18.0 Changelog
Added
- New
GET /api/v1/datasets/:dataset_id/metadata-propertiesendpoint for listing dataset metadata properties. (#3813) - New
POST /api/v1/datasets/:dataset_id/metadata-propertiesendpoint for creating dataset metadata properties. (#3813) - New
PATCH /api/v1/metadata-properties/:metadata_property_idendpoint allowing the update of a specific metadata property. (#3952) - New
DELETE /api/v1/metadata-properties/:metadata_property_idendpoint for deletion of a specific metadata property. (#3911) - New
GET /api/v1/metadata-properties/:metadata_property_id/metricsendpoint to compute metrics for a specific metadata property. (#3856) - New
PATCH /api/v1/records/:record_idendpoint to update a record. (#3920) - New
PATCH /api/v1/dataset/:dataset_id/recordsendpoint to bulk update the records of a dataset. (#3934) - Missing validations to
PATCH /api/v1/questions/:question_id. Nowtitleanddescriptionare using the same validations used to create questions. (#3967) - Added
TermsMetadataProperty,IntegerMetadataPropertyandFloatMetadataPropertyclasses allowing to define metadata properties for aFeedbackDataset. (#3818) - Added
metadata_filterstofilter_bymethod inRemoteFeedbackDatasetto filter based on metadata i.e.TermsMetadataFilter,IntegerMetadataFilter, andFloatMetadataFilter. (#3834) - Added a validation layer for both
metadata_propertiesandmetadata_filtersin their schemas and as part of theadd_recordsandfilter_bymethods, respectively. (#3860) - Added
sort_byquery parameter to listing records endpoints that allows to sort the records byinserted_at,updated_ator metadata property. (#3843) - Added
add_metadata_propertymethod to bothFeedbackDatasetandRemoteFeedbackDataset(i.e.FeedbackDatasetin Argilla). (#3900) - Added fields
inserted_atandupdated_atinRemoteResponseSchema. (#3822) - Added support for
sort_byforRemoteFeedbackDataseti.e. aFeedbackDatasetuploaded to Argilla. (#3925) - Added
metadata_propertiessupport for bothpush_to_huggingfaceandfrom_huggingface. (#3947) - Add support for update records (
metadata) from Python SDK. (#3946) - Added
delete_metadata_propertiesmethod to delete metadata properties. (#3932) - Added
update_metadata_propertiesmethod to updatemetadata_properties. (#3961) - Added automatic model card generation through
ArgillaTrainer.save(#3857) - Added
FeedbackDatasetTaskTemplateMixinfor pre-defined task templates. (#3969) - A maximum limit of 50 on the number of options a ranking question can accept. (#3975)
- New
last_activity_atfield toFeedbackDatasetexposing when the last activity for the associated dataset occurs. (#3992)
Changed
GET /api/v1/datasets/{dataset_id}/records,GET /api/v1/me/datasets/{dataset_id}/recordsandPOST /api/v1/me/datasets/{dataset_id}/records/searchendpoints to return thetotalnumber of records. (#3848, #3903)- Implemented
__len__method for filtered datasets to return the number of records matching the provided filters. (#3916) - Increase the default max result window for Elasticsearch created for Feedback datasets. (#3929)
- Force elastic index refresh after records creation. (#3929)
- Validate metadata fields for filtering and sorting in the Python SDK. (#3993)
- Using metadata property name instead of id for indexing data in search engine index. (#3994)
Fixed
- Fixed response schemas to allow
valuesto beNonei.e. when a record is discarded theresponse.valuesare set toNone. (#3926) - ## New Contributors
- @splevine made their first contribution in https://github.com/argilla-io/argilla/pull/3832
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.17.0...v1.18.0
- Python
Published by frascuchon over 2 years ago
argilla - v1.17.0
☀️ Highlights
This release comes with a lot of new goodies and quality improvements. We added model card support for the ArgillaTrainer, worked on the FeedbackDataset task templates and added timestamps to responses. We also fixed a lot of bugs and improved the overall quality of the codebase. Enjoy!
🚨 Breaking change in updating existing Hugging Face Spaces deployments
The quickstart image startup script was changed from from /start_quickstart.sh to /home/argilla/start_quickstart.sh, which might cause existing Hugging Face Spaces deployments to malfunction. A fix was added for the Argilla template space via this PR. Alternatively, you can just create a new deployment.
⚠️ Breaking change using SQLite as backend in a docker deployment
From version 1.17.0 a new argilla os user is configured for the provided docker images. If you are using the docker deployment and you want to upload to this version, you should do some actions once update your container and before working with Argilla. Execute the following command:
bash
docker exec --user root <argilla_server_container_id> /bin/bash -c 'chown -R argilla:argilla "$ARGILLA_HOME_PATH"'
This will change the permissions on the argilla home path, which allows it to work with new containers.
Note: You can find the docker container id by running:
bash
docker ps | grep -i argilla-server
bash
713973693fb7 argilla/argilla-server:v1.17.0 "/bin/bash start_arg…" 11 hours ago Up 7 minutes 0.0.0.0:6900->6900/tcp docker-argilla-1
💾 ArgillaTrainer Model Card Generation
The ArgillaTrainer now supports automatic model card generation. This means that you can now generate a model card with all the required info for Hugging Face and directly share these models to the hub, as you would expect within the Hugging Face ecosystem. See the docs for more info.
```python modelcardkwargs = { "language": ["en", "es"], "license": "Apache-2.0", "modelid": "all-MiniLM-L6-v2", "datasetname": "argilla/emotion", "tags": ["nlp", "few-shot-learning", "argilla", "setfit"], "modelsummary": "Small summary of what the model does", "modeldescription": "An extended explanation of the model", "modeltype": "A 1.3B parameter embedding model fine-tuned on an awesome dataset", "finetunedfrom": "all-MiniLM-L6-v2", "repo": "https://github.com/..." "developers": "", "shared_by": "", }
trainer = ArgillaTrainer( dataset=dataset, task=task, framework="setfit", frameworkkwargs={"modelcardkwargs": modelcardkwargs} ) trainer.train(outputdir="my_model")
or get the card as str by calling the generate_model_card method
argillamodelcard = trainer.generatemodelcard("my_model") ```
🦮 FeedbackDataset Task Templates
The Argilla FeedbackDataset now supports a number of task templates that can be used to quickly create a dataset for specific tasks out of the box. This should help starting users get right into the action without having to worry about the dataset structure. We support basic tasks like Text Classification but also allow you to setup complex RAG-pipelines. See the docs for more info.
```python import argilla as rg
ds = rg.FeedbackDataset.fortextclassification( labels=["positive", "negative"], multilabel=False, usemarkdown=True, guidelines=None, ) ds
FeedbackDataset(
fields=[TextField(name="text", use_markdown=True)],
questions=[LabelQuestion(name="label", labels=["positive", "negative"])]
guidelines="",
)
```
⏱️ inserted_at and updated_at are added to responses
What are responses without timestamps? The RemoteResponseSchema now supports inserted_at and updated_at fields. This should help you to keep track of the time when a response was created and updated. Perfectly, for keeping track of annotator performance within your company.
1.17.0
Added
- Added fields
inserted_atandupdated_atinRemoteResponseSchema(#3822). - Added automatic model card generation through
ArgillaTrainer.save(#3857). - Added task templates to the
FeedbackDataset(#3973).
Changed
- Updated
Dockerfileto use multi stage build (#3221 and #3793). - Updated active learning for text classification notebooks to use the most recent small-text version (#3831).
- Changed argilla dataset name in the active learning for text classification notebooks to be consistent with the default names in the huggingface spaces (#3831).
- FeedbackDataset API methods have been aligned to be accessible through the several implementations (#3937).
- The
unify_responsessupport for remote datasets (#3937).
Fixed
- Fix field not shown in the order defined in the dataset settings. Closes #3959 (#3984)
- Updated active learning for text classification notebooks to pass ids of type int to
TextClassificationRecord(#3831). - Fixed record fields validation that was preventing from logging records with optional fields (i.e.
required=True) when the field value wasNone(#3846). - Always set
pretrained_model_name_or_pathattribute as string inArgillaTrainer(#3914). - The
inserted_atandupdated_atattributes are create using theutcnowfactory to avoid unexpected race conditions on timestamp creation (#3945) - Fixed
configure_dataset_settingswhen providing the workspace via the argworkspace(#3887). - Fixed saving of models trained with
ArgillaTrainerwith apeft_configparameter (#3795). - Fixed backwards compatibility on
from_huggingfacewhen loading aFeedbackDatasetfrom the Hugging Face Hub that was previously dumped using another version of Argilla, starting at 1.8.0, when it was first introduced (#3829). - Fixed
TrainingTaskForQuestionAnswering.__repr__(#3969) - Fixed potential dictionary key-errors in
TrainingTask.prepare_for_training_with_*-methods (#3969)
Deprecated
- Function
rg.configure_datasetis deprecated in favour ofrg.configure_dataset_settings. The former will be removed in version 1.19.0
New Contributors
- @osintalex made their first contribution in https://github.com/argilla-io/argilla/pull/3221
- @kursathalat made their first contribution in https://github.com/argilla-io/argilla/pull/3756
- @splevine made their first contribution in https://github.com/argilla-io/argilla/pull/3832
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.16.0...v1.17.0
- Python
Published by frascuchon over 2 years ago
argilla - v1.16.0
☀️ Highlights
This release comes with an auto save feature for the UI, an enhanced Argilla CLI app, new keyboard shortcuts for the annotation process in the Feedback Dataset and new integrations for the ArgillaTrainer.
💾 Auto save
Have you been writing a long corrected text in a TextField for a completion given by an LLM and you have refreshed the page before submitting it? Well, since this release you are covered! The Argilla UI will save every few seconds the responses given in the annotation form of a FeedbackDataset. Annotators can partially annotate one record and then come back to finish the annotation process without losing the previous work.
👨🏻💻 More operations directly from the Argilla CLI
The Argilla CLI has been updated to include an extensive list of new commands, from users and datasets management to training models all from the terminal!
⌨️ New keyboard shorcuts for the Feedback Dataset
Now, you can seamlessly navigate within the feedback form using just your keyboard. We've extended the functionality of these shortcuts to cover all types of available questions: Label, Multi-label, Ranking, Rating and Text
QnA, Chat Completion with OpenAI and Sentence Transformers model training now in the ArgillaTrainer
The ArgillaTrainer doesn't stop getting new features and improvements!
- A new
TrainingTaskhas been added for Question and Answering (QnA) - Use a
FeedbackDatasetfor fine-tuning an OpenAI model for Chat Completion - New integration with Sentence Transformers for fine-tuning a model for embedding generation
1.16.0
Added
- Added
ArgillaTrainerintegration with sentence-transformers, allowing fine tuning for sentence similarity (#3739) - Added
ArgillaTrainerintegration withTrainingTask.for_question_answering(#3740) - Added
Auto save recordto save automatically the current record that you are working on (#3541) - Added
ArgillaTrainerintegration with OpenAI, allowing fine tuning for chat completion (#3615) - Added
workspaces listcommand to list Argilla workspaces (#3594). - Added
datasets listcommand to list Argilla datasets (#3658). - Added
users createcommand to create users (#3667). - Added
whoamicommand to get current user (#3673). - Added
users deletecommand to delete users (#3671). - Added
users listcommand to list users (#3688). - Added
workspaces delete-usercommand to remove a user from a workspace (#3699). - Added
datasets listcommand to list Argilla datasets (#3658). - Added
users createcommand to create users (#3667). - Added
users deletecommand to delete users (#3671). - Added
workspaces createcommand to create an Argilla workspace (#3676). - Added
datasets push-to-hubcommand to push aFeedbackDatasetfrom Argilla into the HuggingFace Hub (#3685). - Added
infocommand to get info about the used Argilla client and server (#3707). - Added
datasets deletecommand to delete aFeedbackDatasetfrom Argilla (#3703). - Added
created_atandupdated_atproperties toRemoteFeedbackDatasetandFilteredRemoteFeedbackDataset(#3709). - Added handling
PermissionErrorwhen executing a command with a logged in user with not enough permissions (#3717). - Added
workspaces add-usercommand to add a user to workspace (#3712). - Added
workspace_idparam toGET /api/v1/me/datasetsendpoint (#3727). - Added
workspace_idarg tolist_datasetsin the Python SDK (#3727). - Added
argillascript that allows to execute Argilla CLI using theargillacommand (#3730). - Added
server_infofunction to check the Argilla server information (also accessible viarg.server_info) (#3772).
Changed
- Move
databasecommands underservergroup of commands (#3710) servercommands only included in the CLI app whenserverextra requirements are installed (#3710).- Updated
PUT /api/v1/responses/{response_id}to replacevaluesstored with receivedvaluesin request (#3711). - Display a
UserWarningwhen theuser_idinWorkspace.add_userandWorkspace.delete_useris the ID of an user with the owner role as they don't require explicit permissions (#3716). - Rename
taskssub-package tocli(#3723). - Changed
argilla databasecommand in the CLI to now be accessed viaargilla server database, to be deprecated in the upcoming release (#3754). - Changed
visible_options(of label and multi label selection questions) validation in the backend to check that the provided value is greater or equal than/to 3 and less or equal than/to the number of provided options (#3773).
Fixed
- Fixed
remove user modification in text component on clear answers(#3775) - Fixed
Highlight raw text field in dataset feedback task(#3731) - Fixed
Field title too long(#3734) - Fixed error messages when deleting a
DatasetForTextClassification(#3652) - Fixed
Pending queuepagination problems when during data annotation (#3677) - Fixed
visible_labelsdefault value to be 20 just whenvisible_labelsnot provided andlen(labels) > 20, otherwise it will either be the providedvisible_labelsvalue orNone, forLabelQuestionandMultiLabelQuestion(#3702). - Fixed
DatasetCardgeneration whenRemoteFeedbackDatasetcontains suggestions (#3718). - Add missing
draftstatus inResponseSchemaas now there can be responses withdraftstatus when annotating via the UI (#3749). - Searches when queried words are distributed along the record fields (#3759).
- Fixed Python 3.11 compatibility issue with
/api/datasetsendpoints due to theTaskTypeenum replacement in the endpoint URL (#3769).
As always, thanks to our amazing contributors
- @sdiazlor made their first contribution in https://github.com/argilla-io/argilla/pull/3384
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.15.1...v1.16.0
- Python
Published by gabrielmbmb almost 3 years ago
argilla - v1.16.0
1.16.0
Added
- Added
ArgillaTrainerintegration with sentence-transformers, allowing fine tuning for sentence similarity (#3739) - Added
ArgillaTrainerintegration withTrainingTask.for_question_answering(#3740) - Added
Auto save recordto save automatically the current record that you are working on (#3541) - Added
ArgillaTrainerintegration with OpenAI, allowing fine tuning for chat completion (#3615) - Added
workspaces listcommand to list Argilla workspaces (#3594). - Added
datasets listcommand to list Argilla datasets (#3658). - Added
users createcommand to create users (#3667). - Added
whoamicommand to get current user (#3673). - Added
users deletecommand to delete users (#3671). - Added
users listcommand to list users (#3688). - Added
workspaces delete-usercommand to remove a user from a workspace (#3699). - Added
datasets listcommand to list Argilla datasets (#3658). - Added
users createcommand to create users (#3667). - Added
users deletecommand to delete users (#3671). - Added
workspaces createcommand to create an Argilla workspace (#3676). - Added
datasets push-to-hubcommand to push aFeedbackDatasetfrom Argilla into the HuggingFace Hub (#3685). - Added
infocommand to get info about the used Argilla client and server (#3707). - Added
datasets deletecommand to delete aFeedbackDatasetfrom Argilla (#3703). - Added
created_atandupdated_atproperties toRemoteFeedbackDatasetandFilteredRemoteFeedbackDataset(#3709). - Added handling
PermissionErrorwhen executing a command with a logged in user with not enough permissions (#3717). - Added
workspaces add-usercommand to add a user to workspace (#3712). - Added
workspace_idparam toGET /api/v1/me/datasetsendpoint (#3727). - Added
workspace_idarg tolist_datasetsin the Python SDK (#3727). - Added
argillascript that allows to execute Argilla CLI using theargillacommand (#3730). - Added
server_infofunction to check the Argilla server information (also accessible viarg.server_info) (#3772).
Changed
- Move
databasecommands underservergroup of commands (#3710) servercommands only included in the CLI app whenserverextra requirements are installed (#3710).- Updated
PUT /api/v1/responses/{response_id}to replacevaluesstored with receivedvaluesin request (#3711). - Display a
UserWarningwhen theuser_idinWorkspace.add_userandWorkspace.delete_useris the ID of an user with the owner role as they don't require explicit permissions (#3716). - Rename
taskssub-package tocli(#3723). - Changed
argilla databasecommand in the CLI to now be accessed viaargilla server database, to be deprecated in the upcoming release (#3754). - Changed
visible_options(of label and multi label selection questions) validation in the backend to check that the provided value is greater or equal than/to 3 and less or equal than/to the number of provided options (#3773).
Fixed
- Fixed
remove user modification in text component on clear answers(#3775) - Fixed
Highlight raw text field in dataset feedback task(#3731) - Fixed
Field title too long(#3734) - Fixed error messages when deleting a
DatasetForTextClassification(#3652) - Fixed
Pending queuepagination problems when during data annotation (#3677) - Fixed
visible_labelsdefault value to be 20 just whenvisible_labelsnot provided andlen(labels) > 20, otherwise it will either be the providedvisible_labelsvalue orNone, forLabelQuestionandMultiLabelQuestion(#3702). - Fixed
DatasetCardgeneration whenRemoteFeedbackDatasetcontains suggestions (#3718). - Add missing
draftstatus inResponseSchemaas now there can be responses withdraftstatus when annotating via the UI (#3749). - Searches when queried words are distributed along the record fields (#3759).
- Fixed Python 3.11 compatibility issue with
/api/datasetsendpoints due to theTaskTypeenum replacement in the endpoint URL (#3769).
New Contributors
- @sdiazlor made their first contribution in https://github.com/argilla-io/argilla/pull/3384
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.15.1...v1.16.0
- Python
Published by frascuchon almost 3 years ago
argilla - v1.15.1
Changelog 1.15.1
Fixed
- Fixed
Text componenttext content sanitization behavior just for markdown to prevent disappear the text (#3738) - Fixed
Text componentnow you need to press Escape to exit the text area (#3733) - Fixed
SearchEnginewas creating the same number of primary shards and replica shards for eachFeedbackDataset(#3736).
- Python
Published by damianpumar almost 3 years ago
argilla - v1.15.0
🔆 Highlights
Argilla 1.15.0 comes with an enhanced FeedbackDataset settings page enabling the update of the dataset settings, an integration of the TRL package with the ArgillaTrainer, and continues adding improvements to the Python client for managing FeedbackDatasets.
⚙️ Update FeedbackDataset settings from the UI
FeedbackDataset settings page has been updated and now it allows to update the guidelines and some attributes of the fields and questions of the dataset. Did you misspell the title or description of a field or question? Well, you don't have to remove your dataset and create it again anymore! Just go to the settings page and fix it.
🤖 TRL integration with the ArgillaTrainer
The famous TRL package for training Transformers with Reinforcement Learning techniques has been integrated with the ArgillaTrainer, that comes with four new TrainingTask: SFT, Reward Modeling, PPO and DPO. Each training task expects a formatting function that will return the data in the expected format for training the model.
Check this 🆕 tutorial for training a Reward Model using the Argilla Trainer.
🐍 Filter FeedbackDataset and remove suggestions
In the 1.14.0 release we added many improvements for working with remote FeedbackDatasets. In this release, a new filter_by method has been added that allows to filter the records of a dataset from the Python client. For now, the records can be only filtered using the response_status, but we're planning adding more complex filters for the upcoming releases. In addition, new methods have been added allowing to remove the suggestions created for a record.
1.15.0
Added
- Added
Enable to update guidelines and dataset settings for Feedback Datasets directly in the UI(#3489) - Added
ArgillaTrainerintegration with TRL, allowing for easy supervised finetuning, reward modeling, direct preference optimization and proximal policy optimization (#3467) - Added
formatting_functoArgillaTrainerforFeedbackDatasetdatasets add a custom formatting for the data (#3599). - Added
loginfunction inargilla.client.loginto login into an Argilla server and store the credentials locally (#3582). - Added
logincommand to login into an Argilla server (#3600). - Added
logoutcommand to logout from an Argilla server (#3605). - Added
DELETE /api/v1/suggestions/{suggestion_id}endpoint to delete a suggestion given its ID (#3617). - Added
DELETE /api/v1/records/{record_id}/suggestionsendpoint to delete several suggestions linked to the same record given their IDs (#3617). - Added
response_statusparam toGET /api/v1/datasets/{dataset_id}/recordsto be able to filter byresponse_statusas previously included forGET /api/v1/me/datasets/{dataset_id}/records(#3613). - Added
listclassmethod toArgillaMixinto be used asFeedbackDataset.list(), also including theworkspaceto list from as arg (#3619). - Added
filter_bymethod inRemoteFeedbackDatasetto filter based onresponse_status(#3610). - Added
list_workspacesfunction (to be used asrg.list_workspaces, butWorkspace.listis preferred) to list all the workspaces from an user in Argilla (#3641). - Added
list_datasetsfunction (to be used asrg.list_datasets) to list theTextClassification,TokenClassification, andText2Textdatasets in Argilla (#3638). - Added
RemoteSuggestionSchemato manage suggestions in Argilla, including thedeletemethod to delete suggestios from Argilla viaDELETE /api/v1/suggestions/{suggestion_id}(#3651). - Added
delete_suggestionstoRemoteFeedbackRecordto remove suggestions from Argilla viaDELETE /api/v1/records/{record_id}/suggestions(#3651).
Changed
- Changed
Optional label for * mark for required question(#3608) - Updated
RemoteFeedbackDataset.delete_recordsto use batch delete records endpoint (#3580). - Included
allowed_for_rolesfor someRemoteFeedbackDataset,RemoteFeedbackRecords, andRemoteFeedbackRecordmethods that are only allowed for users with rolesownerandadmin(#3601). - Renamed
ArgillaToFromMixintoArgillaMixin(#3619). - Move
usersCLI app underdatabaseCLI app (#3593). - Move server
Enumclasses toargilla.server.enumsmodule (#3620).
Fixed
- Fixed
Filter by workspace in breadcrumbs(#3577) - Fixed
Filter by workspace in datasets table(#3604) - Fixed
Query search highlightfor Text2Text and TextClassification (#3621) - Fixed
RatingQuestion.valuesvalidation to raise aValidationErrorwhen values are out of range i.e. 1, 10.
Removed
- Removed
multi_task_text_token_classificationfromTaskTypeas not used (#3640). - Removed
argilla_idin favor ofidfromRemoteFeedbackDataset(#3663). - Removed
fetch_recordsfromRemoteFeedbackDatasetas now the records are lazily fetched from Argilla (#3663). - Removed
push_to_argillafromRemoteFeedbackDataset, as it just works when calling it through aFeedbackDatasetlocally, as now the updates of the remote datasets are automatically pushed to Argilla (#3663). - Removed
set_suggestionsin favor ofupdate(suggestions=...)for bothFeedbackRecordandRemoteFeedbackRecord, as all the updates of any "updateable" attribute of a record will go throughupdateinstead (#3663). - Remove unused
ownerattribute for client Dataset data model (#3665)
As always, thanks to our amazing contributors
- @peppinob-ol made their first contribution in https://github.com/argilla-io/argilla/pull/3472
- @eshwarhs made their first contribution in https://github.com/argilla-io/argilla/pull/3605
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.14.1...v1.15.0
- Python
Published by damianpumar almost 3 years ago
argilla - v1.14.1
Changelog 1.14.1
Fixed
- Fixed PostgreSQL database not being updated after
begin_nestedbecause of missingcommit(#3567).
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.14.0...v1.14.1
- Python
Published by gabrielmbmb almost 3 years ago
argilla - v1.14.0
🔆 Highlights
Argilla 1.14.0 comes packed with improvements to manage Feedback Datasets from the Python client. Here are the most important changes in this version:
Pushing and pulling a dataset
Pushing a dataset to Argilla will now create a RemoteFeedbackDataset in Argilla. To make changes to your dataset in Argilla you will need to make those updates to the remote dataset. You can do so by either using the dataset returned when using the push_to_argilla() method (as shown in the image above) or by loading the dataset like so:
```python
import argilla as rg
connect to Argilla
rg.init(apiurl="...", apikey="...")
get the existing dataset in Argilla
remotedataset = rg.FeedbackDataset.fromargilla(name="my-dataset", workspace="my-workspace")
add a list of FeedbackRecords to the dataset in Argilla
remotedataset.addrecords(...)
Alternatively, you can make a local copy of the dataset using the `pull()` method.
```python
local_dataset = remote_dataset.pull()
Note that any changes that you make to this local dataset will not affect the remote dataset in Argilla.
Adding and deleting records
How to add records to an existing dataset in Argilla was demonstrated in the first code snippet in the "Pushing and pulling a dataset" section. This is how you can delete a list of records using that same dataset:
python
records_to_delete = remote_dataset.records[0:5]
remote_dataset.delete_records(records_to_delete)
Or delete a single record:
python
record = remote_dataset.records[-1]
record.delete()
```
Add / update suggestions in existing records
To add and update suggestions in existing records, you can simply use the update() method. For example:
python
for record in remote_dataset.records:
record.update(suggestions=...)
`
Note that adding a suggestion to a question that already has one will overwrite the previous suggestion. To learn more about the format that the suggestions must follow, check our docs.
Delete a dataset
You can now easily delete datasets from the Python client. To do that, get the existing dataset like demonstrated in the first section and just use:
python
remote_dataset.delete()
`
Create users with workspace assignments
Now you can create a user and directly assign existing workspaces to grant them access.
python
user = rg.User.create(username="...", first_name="...", password="...", workspaces=["ws1", "ws2"])
`
Changelog 1.14.0
Added
- Added
PATCH /api/v1/fields/{field_id}endpoint to update the field title and markdown settings (#3421). - Added
PATCH /api/v1/datasets/{dataset_id}endpoint to update dataset name and guidelines (#3402). - Added
PATCH /api/v1/questions/{question_id}endpoint to update question title, description and some settings (depending on the type of question) (#3477). - Added
DELETE /api/v1/records/{record_id}endpoint to remove a record given its ID (#3337). - Added
pullmethod inRemoteFeedbackDataset(aFeedbackDatasetpushed to Argilla) to pull all the records from it and return it as a local copy as aFeedbackDataset(#3465). - Added
deletemethod inRemoteFeedbackDataset(aFeedbackDatasetpushed to Argilla) (#3512). - Added
delete_recordsmethod inRemoteFeedbackDataset, anddeletemethod inRemoteFeedbackRecordto delete records from Argilla (#3526).
Changed
- Improved efficiency of weak labeling when dataset contains vectors (#3444).
- Added
ArgillaDatasetMixinto detach the Argilla-related functionality from theFeedbackDataset(#3427) - Moved
FeedbackDataset-relatedpydantic.BaseModelschemas toargilla.client.feedback.schemasinstead, to be better structured and more scalable and maintainable (#3427) - Update CLI to use database async connection (#3450).
- Limit rating questions values to the positive range 1, 10.
- Updated
POST /api/usersendpoint to be able to provide a list of workspace names to which the user should be linked to (#3462). - Updated Python client
User.createmethod to be able to provide a list of workspace names to which the user should be linked to (#3462). - Updated
GET /api/v1/me/datasets/{dataset_id}/recordsendpoint to allow getting records matching one of the response statuses provided via query param (#3359). - Updated
POST /api/v1/me/datasets/{dataset_id}/recordsendpoint to allow searching records matching one of the response statuses provided via query param (#3359). - Updated
SearchEngine.searchmethod to allow searching records matching one of the response statuses provided (#3359). - After calling
FeedbackDataset.push_to_argilla, the methodsFeedbackDataset.add_recordsandFeedbackRecord.set_suggestionswill automatically call Argilla with no need of callingpush_to_argillaexplicitly (#3465). - Now calling
FeedbackDataset.push_to_huggingfacedumps theresponsesas aList[Dict[str, Any]]instead ofSequenceto make it more readable via 🤗datasets(#3539).
Fixed
- Fixed issue with
boolvalues anddefaultfrom Jinja2 while generating the HuggingFaceDatasetCardfromargilla_template.md(#3499). - Fixed
DatasetConfig.from_yamlwhich was failing when callingFeedbackDataset.from_huggingfaceas the UUIDs cannot be deserialized automatically byPyYAML, so UUIDs are neither dumped nor loaded anymore (#3502). - Fixed an issue that didn't allow the Argilla server to work behind a proxy (#3543).
TextClassificationSettingsandTokenClassificationSettingslabels are properly parsed to strings both in the Python client and in the backend endpoint (#3495).- Fixed
PUT /api/v1/datasets/{dataset_id}/publishto check whether at least one field and question hasrequired=True(#3511). - Fixed
FeedbackDataset.from_huggingfaceassuggestionswere being lost when there were noresponses(#3539). - Fixed
QuestionSchemaandFieldSchemanot validatingnameattribute (#3550).
Deprecated
- After calling
FeedbackDataset.push_to_argilla, callingpush_to_argillaagain won't do anything since the dataset is already pushed to Argilla (#3465). - After calling
FeedbackDataset.push_to_argilla, callingfetch_recordswon't do anything since the records are lazily fetched from Argilla (#3465). - After calling
FeedbackDataset.push_to_argilla, the Argilla ID is no longer stored in the attribute/propertyargilla_idbut inidinstead (#3465).
As always, thanks to our amazing contributors
- @plaguss made their first contribution in https://github.com/argilla-io/argilla/pull/3454
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.13.3...v1.14.0
- Python
Published by gabrielmbmb almost 3 years ago
argilla - v1.13.3
1.13.3
Fixed
- Fixed
ModuleNotFoundErrorcaused because theargilla.utils.telemetrymodule used in theArgillaTrainerwas importing an optional dependency not installed by default (#3471). - Fixed
ImportErrorcaused because theargilla.client.feedback.configmodule was importingpyyamloptional dependency not installed by default (#3471).
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.13.2...v1.13.3
- Python
Published by frascuchon almost 3 years ago
argilla - v1.13.0
🔆 Highlights
✨ Suggestions
You can now add suggestions to your Feedback datasets. This feature enhances the feedback collection process by providing machine-generated feedback to labelers that appears as pre-filled responses. In this way, they act as an aid for labelers' efficiency, who will only need to correct the responses that they don't agree with.
All question types in the Feedback task support suggestions, but you can only add one suggestion per question.
Learn more about this feature in our docs.
🗄️ List workspaces
We've added functionalities to list all the workspaces that a user has access to. From the Python client you will be able to list all workspaces of the current user using rg.Workspace.list() and in the UI you will be able to see the list of workspaces in the user settings page.
Read more in the docs.
🏋️♂️ Extended training support
We are extending the support we give to help preparing data from Feedback datasets to use during training. As part of this release we include strategies to unify responses to RankingQuestions and also provide a task mapping for text classification TrainingTaskMapping.for_text_classification.
Read more about how to use these methods to train models with Feedback collected in Argilla here.
Changelog 1.13.0
Added
- Added
GET /api/v1/users/{user_id}/workspacesendpoint to list the workspaces to which a user belongs (#3308 and #3343). - Added
HuggingFaceDatasetMixinfor internal usage, to detach theFeedbackDatasetintegrations from the class itself, and use Mixins instead (#3326). - Added
GET /api/v1/records/{record_id}/suggestionsAPI endpoint to get the list of suggestions for the responses associated to a record (#3304). - Added
POST /api/v1/records/{record_id}/suggestionsAPI endpoint to create a suggestion for a response associated to a record (#3304). - Added support for
RankingQuestionStrategy,RankingQuestionUnificationand the.for_text_classificationmethod for theTrainingTaskMapping(#3364) - Added
PUT /api/v1/records/{record_id}/suggestionsAPI endpoint to create or update a suggestion for a response associated to a record (#3304 & 3391). - Added
suggestionsattribute toFeedbackRecord, and allow adding and retrieving suggestions from the Python client (#3370) - Added
allowed_for_rolesPython decorator to check whether the current user has the required role to access the decorated function/method forUserandWorkspace(#3383) - Added API and Python Client support for workspace deletion (Closes #3260)
- Added
GET /api/v1/me/workspacesendpoint to list the workspaces of the current active user (#3390)
Changed
- Updated output payload for
GET /api/v1/datasets/{dataset_id}/records,GET /api/v1/me/datasets/{dataset_id}/records,POST /api/v1/me/datasets/{dataset_id}/records/searchendpoints to include the suggestions of the records based on the value of theincludequery parameter (#3304). - Updated
POST /api/v1/datasets/{dataset_id}/recordsinput payload to add suggestions (#3304). - The
POST /api/datasets/:dataset-id/:task/bulkendpoints don't create the dataset if does not exists (Closes #3244) - Added Telemetry support for
ArgillaTrainer(closes #3325) User.workspacesis no longer an attribute but a property, and is callinglist_user_workspacesto list all the workspace names for a given user ID (#3334)- Renamed
FeedbackDatasetConfigtoDatasetConfigand export/import from YAML as default instead of JSON (just used internally onpush_to_huggingfaceandfrom_huggingfacemethods ofFeedbackDataset) (#3326). - The protected metadata fields support other than textual info - existing datasets must be reindex. See docs for more detail (Closes #3332).
- Updated
Dockerfileparent image frompython:3.9.16-slimtopython:3.10.12-slim(#3425). - Updated
quickstart.Dockerfileparent image fromelasticsearch:8.5.3toargilla/argilla-server:${ARGILLA_VERSION}(#3425).
Removed
- Removed support to non-prefixed environment variables. All valid env vars start with
ARGILLA_(See #3392).
Fixed
- Fixed
GET /api/v1/me/datasets/{dataset_id}/recordsendpoint returning always the responses for the records even ifresponseswas not provided via theincludequery parameter (#3304). - Values for protected metadata fields are not truncated (Closes #3331).
- Big number ids are properly rendered in UI (Closes #3265)
- Fixed
ArgillaDatasetCardto include the values/labels for all the existing questions (#3366)
Deprecated
- Integer support for record id in text classification, token classification and text2text datasets.
As always, thanks to our amazing contributors
- @manijhariya made their first contribution in https://github.com/argilla-io/argilla/pull/3295
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.12.1...1.13.0
- Python
Published by frascuchon almost 3 years ago
argilla - v1.12.1
1.12.1
Fixed
- Using
rg.initwith defaultargillauser skips setting the default workspace if not available. (Closes #3340) - Resolved wrong import structure
ArgillaTrainerTrainingTaskMapping(Closes #3345) - Pin pydantic dependency to version < 2 (Closes 3348)
- Python
Published by frascuchon almost 3 years ago
argilla - v1.12.0
🔆 Highlights
New RankingQuestion in Feedback Task datasets
Now you will be able to include
RankingQuestions in your Feedback datasets. These are specially designed to gather feedback on labeler's preferences, by providing a set of options that labelers can order.
Here's how you can add a RankingQuestion to a FeedbackDataset:
python
dataset = FeedbackDataset(
fields=[
rg.TextField(name="prompt"),
rg.TextField(name="reply-1", title="Reply 1"),
rg.TextField(name="reply-2", title="Reply 2"),
rg.TextField(name="reply-3", title="Reply 3"),
],
questions=[
rg.RankingQuestion(
name="ranking",
title="Order replies based on your preference",
description="1 = best, 3 = worst. Ties are allowed.",
required=True,
values={"reply-1": "Reply 1", "reply-2": "Reply 2", "reply-3": "Reply 3"} # or ["reply-1", "reply-2", "reply-3"]
]
)
More info in our docs.
Extended training support
You can now format responses from RatingQuestion, LabelQuestion and MultiLabelQuestion for your preferred training framework using the prepare_for_training method.
Also, we've added support for spacy-transformers in our Argilla Trainer.
Here's an example code snippet: ```python import argilla.feedback as rg
dataset = rg.FeedbackDataset.fromhuggingface( repoid="argilla/stackoverflowfeedbackdemo" ) taskmapping = rg.TrainingTaskMapping.fortextclassification( text=dataset.fieldbyname("question"), label=dataset.questionbyname("tags") ) trainer = rg.ArgillaTrainer( dataset=dataset, taskmapping=taskmapping, framework="spacy-transformers", fetchrecords=False ) trainer.updateconfig(numtrainepochs=2) trainer.train(outputdir="myawesonemodel") ```` To learn more about how to use Argilla Trainer check our docs.
Changelog 1.12.0
Added
- Added
RankingQuestionSettingsclass allowing to create ranking questions in the API usingPOST /api/v1/datasets/{dataset_id}/questionsendpoint (#3232) - Added
RankingQuestionin the Python client to create ranking questions (#3275). - Added
Rankingcomponent in feedback task question form (#3177 & #3246). - Added
FeedbackDataset.prepare_for_trainingmethod for generaring a framework-specific dataset with the responses provided forRatingQuestion,LabelQuestionandMultiLabelQuestion(#3151). - Added
ArgillaSpaCyTransformersTrainerclass for supporting the training withspacy-transformers(#3256).
Changed
- All docker related files have been moved into the
dockerfolder (#3053). release.Dockerfilehave been renamed toDockerfile(#3133).- Updated
rg.loadfunction to raise aValueErrorwith a explanatory message for the cases in which the user tries to use the function to load aFeedbackDataset(#3289). - Updated
ArgillaSpaCyTrainerto allow re-usingtok2vec(#3256).
Fixed
- Check available workspaces on Argilla on
rg.set_workspace(Closes #3262)
New Contributors
- @garimau made their first contribution in https://github.com/argilla-io/argilla/pull/3255
- @adurante92 made their first contribution in https://github.com/argilla-io/argilla/pull/3242
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.11.0...v1.12.0
- Python
Published by gabrielmbmb about 3 years ago
argilla - v1.11.0
🔆 Highlights
New owner role and user update command
We've added a new user role, owner, that has permissions over all users, workspaces and datasets in Argilla (like the admin role in earlier versions). From this version, the admin role will only have permissions over datasets and users in workspaces assigned to them.
You can change a user from admin to owner using a simple CLI command: python -m argilla users update argilla --role owner.
Improved user and workspace management
You can now get lists of users and workspaces, create new ones and give users access to workspaces directly from the Python SDK. Note that only owners will have permissions for all these actions. Admins will be able to give users access to workspaces where they have access.
Metadata fields for Feedback records
You can now add metadata information to your records. This is useful to store information that's not needed for the labeling UI but important for downstream usage (e.g., prompt id, model IDs, etc.)
Changelog 1.11.0
Fixed
- Replaced
np.floatalias byfloatto avoidAttributeErrorwhen usingfind_label_errorsfunction withnumpy>=1.24.0(#3214). - Fixed
format_as("datasets")when no responses or optional respones inFeedbackRecord, to set their value to what 🤗 Datasets expects instead of justNone(#3224). - Fixed
push_to_huggingface()whengenerate_card=True(default behaviour), as we were passing a sample record to theArgillaDatasetCardclass, andUUIDs introduced in 1.10.0 (#3192), are not JSON-serializable (#3231). - Fixed
from_argillaandpush_to_argillato ensure consistency on both field and question re-construction, and to ensureUUIDs are properly serialized asstr, respectively (#3234).
Added
- Added
metadataattribute to theRecordof theFeedbackDataset(#3194) - New
users updatecommand to update the role for an existing user (#3188) - New
Workspaceclass to allow users manage their Argilla workspaces and the users assigned to those workspaces via the Python client (#3180) - Added
Userclass to let users manage their Argilla users via the Python client (#3169). - Added an option to display
tqdmprogress bar toFeedbackDataset.push_to_argillawhen looping over the records to upload (#3233).
Changed
- The role system now support three different roles
owner,adminandannotator(#3104) adminrole is scoped to workspace-level operations (#3115)- The
owneruser is created among the default pool of users in the quickstart, and the default user in the server has nowownerrole (#3248), reverting (#3188).
Deprecated
- As of Python 3.7 end-of-life (EOL) on 2023-06-27, Argilla will no longer support Python 3.7 (#3188). More information at https://peps.python.org/pep-0537/
As always, thanks to our amazing contributors!
- @damianpumar made their first contribution in https://github.com/argilla-io/argilla/pull/2950
- @MedAmine-SUDO made their first contribution in https://github.com/argilla-io/argilla/pull/3204
- @manulpatel made their first contribution in https://github.com/argilla-io/argilla/pull/3233
- Python
Published by alvarobartt about 3 years ago
argilla - v1.10.0
🔆 Highlights
Search records in Feedback Task
We've added a search bar in the Feedback Task UI so you can filter records based on specific words or phrases.
Extended markdown support
Annotation guidelines are now rendered as markdown text to make them easier to read and have a more flexible format.
Train button in Feedback Task
Admin users have access to a Train </> button in the Feedback Task UI with quick links to all the information needed to train a model with the feedback gathered in Argilla.
Changelog 1.10.0
Added
- Added search component for feedback datasets (#3138)
- Added markdown support for feedback dataset guidelines (#3153)
- Added Train button for feedback datasets (#3170)
Changed
- Updated
SearchEngineandPOST /api/v1/me/datasets/{dataset_id}/records/searchto return thetotalnumber of records matching the search query (#3166)
Fixed
- Replaced Enum for string value in URLs for client API calls (Closes #3149)
- Resolve breaking issue with
ArgillaSpanMarkerTrainerfor Named Entity Recognition withspan_markerv1.1.x onwards. - Move
ArgillaDatasetCardimport under@requires_versiondecorator, so that theImportErroronhuggingface_hubis handled properly (#3174) - Allow flow
FeedbackDataset.from_argilla->FeedbackDataset.push_to_argillaunder different dataset names and/or workspaces (#3192)
As always, thanks to our amazing contributors!
- @hjain5164 made their first contribution in https://github.com/argilla-io/argilla/pull/3146
- @Fancman made their first contribution in https://github.com/argilla-io/argilla/pull/3150
- @preetgami made their first contribution in https://github.com/argilla-io/argilla/pull/3196
Full Changelog: https://github.com/argilla-io/argilla/compare/v1.9.0...v1.10.0
- Python
Published by frascuchon about 3 years ago
argilla - v1.9.0
🔆 Highlights
New question types in Feedback Datasets
We've included two new question types in Feedback Datasets: LabelQuestion and MultiLabelQuestion. These are specially useful for applying one or multiple labels to a record, for example, for text classification tasks. In this new view, you can add multiple classification questions and even combine them with the other question types available in Feedback Datasets: RatingQuestion and TextQuestion.
Markdown support in Feedback Fields and Text Questions
You can now add the use_markdown=True tag to a TextField or a TextQuestion to have the UI render the text as markdown. You can use this to read and write code, tables or even add images.
Further improvements in Feedback Datasets
We continue to add improvements to our new Feedback Datasets:
- We've added checks to avoid having fields and questions with repeated names.
- Dataset cards generated using FeedbackDataset.push_to_huggingface(generate_card=True) now follow the official Hugging Face template.
Changelog 1.9.0
Added
- Added boolean
use_markdownproperty toTextFieldSettingsmodel (#3000) - Added boolean
use_markdownproperty toTextQuestionSettingsmodel (#3000). - Added new status
draftfor theResponsemodel (#3033) - Added
LabelSelectionQuestionSettingsclass allowing to create label selection (single-choice) questions in the API (#3005) - Added
MultiLabelSelectionQuestionSettingsclass allowing to create multi-label selection (multi-choice) questions in the API (#3010). - Added
POST /api/v1/me/datasets/{dataset_id}/records/searchendpoint (#3068). - Added new components in feedback task Question form: MultiLabel (#3064) and SingleLabel (#3016).
- Added docstrings to the
pydantic.BaseModels defined atargilla/client/feedback/schemas.py(#3137)
Changed
- Updated
GET /api/v1/me/datasets/:dataset_id/metricsoutput payload to include the count of responses withdraftstatus (#3033) - Database setup for unit tests. Now the unit tests use a different database than the one used by the local Argilla server (Closes #2987).
- Updated
alembicsetup to be able to autogenerate revision/migration scripts using SQLAlchemy metadata from Argilla server models (#3044) - Improved
DatasetCardgeneration onFeedbackDataset.push_to_huggingfacewhengenerate_card=True, following the official HuggingFace Hub template, but suited toFeedbackDatasets from Argilla (#3110)
Fixed
- Disallow
fieldsandquestionsinFeedbackDatasetwith the same name (#3126).
As always, thanks to our amazing contributors!
- @gitrock made their first contribution in https://github.com/argilla-io/argilla/pull/3091
- @ChadDa3mon made their first contribution in https://github.com/argilla-io/argilla/pull/3092
- Python
Published by gabrielmbmb about 3 years ago
argilla - v1.8.0
🔆 Highlights
New Feedback Task 🎉
Big welcome to our new
FeedbackDataset! This new type of dataset is designed to cover the specific needs of working with LLMs. Use this task to gather demonstration examples, human feedback, curate other datasets... Questions of different types can be combined so you can adapt your dataset to the specific needs of your project. Currently, it supports RatingQuestion and TextQuestion, but more question types will be added shortly in the coming releases.
In addition, these datasets support multiple annotations: all users with access to the dataset can give their responses.
The FeedbackDataset has an enhanced integration with the Hugging Face Hub, so that saving a dataset to the Hub or pushing a FeedbackDataset from the Hub directly to Argilla is seamless.
Check all the things you can do with Feedback Tasks in our docs
New LLM section in our docs
We've added a new section in our docs that covers: - Useful concepts around work with LLMs - How-to guides that cover all the functionalities of the new Feedback Task - End-to-end examples
More training integrations
We've added new frameworks for the ArgillaTrainer: ArgillaPeftTrainer for Text and Token Classification and ArgillaAutoTrainTrainer for Text Classification.
Changelog 1.8.0
Added
/api/v1/datasetsnew endpoint to list and create datasets ([#2615])./api/v1/datasets/{dataset_id}new endpoint to get and delete datasets ([#2615])./api/v1/datasets/{dataset_id}/publishnew endpoint to publish a dataset ([#2615])./api/v1/datasets/{dataset_id}/questionsnew endpoint to list and create dataset questions ([#2615])/api/v1/datasets/{dataset_id}/fieldsnew endpoint to list and create dataset fields ([#2615])/api/v1/datasets/{dataset_id}/questions/{question_id}new endpoint to delete a dataset questions ([#2615])/api/v1/datasets/{dataset_id}/fields/{field_id}new endpoint to delete a dataset field ([#2615])/api/v1/workspaces/{workspace_id}new endpoint to get workspaces by id ([#2615])/api/v1/responses/{response_id}new endpoint to update and delete a response ([#2615])/api/v1/datasets/{dataset_id}/recordsnew endpoint to create and list dataset records ([#2615])/api/v1/me/datasetsnew endpoint to list user visible datasets ([#2615])/api/v1/me/dataset/{dataset_id}/recordsnew endpoint to list dataset records with user responses ([#2615])/api/v1/me/datasets/{dataset_id}/metricsnew endpoint to get the dataset user metrics ([#2615])/api/v1/me/records/{record_id}/responsesnew endpoint to create record user responses ([#2615])- showing new feedback task datasets in datasets list ([#2719])
- new page for feedback task ([#2680])
- show feedback task metrics ([#2822])
- user can delete dataset in dataset settings page ([#2792])
- Support for
FeedbackDatasetin Python client (parent PR [#2615], and nested PRs: [#2949], [#2827], [#2943], [#2945], [#2962], and [#3003]) - Integration with the HuggingFace Hub ([#2949])
- Added
ArgillaPeftTrainerfor text and token classification #2854 - Added
predict_proba()method toArgillaSetFitTrainer - Added
ArgillaAutoTrainTrainerfor Text Classification #2664 - New
database revisionscommand showing database revisions info [#2615]: https://github.com/argilla-io/argilla/issues/2615
Fixes
- Avoid rendering html for invalid html strings in Text2text ([#2911]https://github.com/argilla-io/argilla/issues/2911)
Changed
- The
database migratecommand accepts a--revisionparam to provide specific revision id tokens_lengthmetrics function returns empty data (#3045)token_lengthmetrics function returns empty data (#3045)mention_lengthmetrics function returns empty data (#3045)entity_densitymetrics function returns empty data (#3045)
Deprecated
- Using argilla with python 3.7 runtime is deprecated and support will be removed from version 1.9.0 (#2902)
tokens_lengthmetrics function has been deprecated and will be removed in 1.10.0 (#3045)token_lengthmetrics function has been deprecated and will be removed in 1.10.0 (#3045)mention_lengthmetrics function has been deprecated and will be removed in 1.10.0 (#3045)entity_densitymetrics function has been deprecated and will be removed in 1.10.0 (#3045)
Removed
- Removed mention
density,tokens_lengthandchars_lengthmetrics from token classification metrics storage (#3045) - Removed token
char_start,char_end,tag, andscoremetrics from token classification metrics storage (#3045) - Removed tags-related metrics from token classification metrics storage (#3045)
As always, thanks to our amazing contributors!
- Fix image alignment on token classification by @cceyda in https://github.com/argilla-io/argilla/pull/2779
- Update cloud_providers.md by @chainyo in https://github.com/argilla-io/argilla/pull/2866
- Python
Published by frascuchon about 3 years ago
argilla - v1.7.0
🔆 Highlights
OpenAI fine-tuning support
Use your data in Argilla to fine-tune OpenAI models. You can do this by getting your data in the specific format through the prepare_for_training method or train directly using ArgillaTrainer.
Argilla Trainer improvements
We’ve added CLI support for Argilla Trainer and two new frameworks for training: OpenAI & SpanMarker.
Logging and loading enhancements
We’ve improved the speed and robustness of rg.log and rg.load methods.
typer CLI
A more user-friendly command line interface with typer that includes argument suggestions and colorful messages.
Changelog 1.7.0
Added
- add
max_retriesandnum_threadsparameters torg.logto run data logging request concurrently with backoff retry policy. See #2458 and #2533 rg.loadacceptsinclude_vectorsandinclude_metricswhen loading data. Closes #2398- Added
settingsparam toprepare_for_training(#2689) - Added
prepare_for_trainingforopenai(#2658) - Added
ArgillaOpenAITrainer(#2659) - Added
ArgillaSpanMarkerTrainerfor Named Entity Recognition (#2693) - Added
ArgillaTrainerCLI support. Closes (#2809)
Changed
- Argilla quickstart image dependencies are externalized into
quickstart.requirements.txt. See #2666 - bulk endpoints will upsert data when record
idis present. Closes #2535 - moved from
clicktotyperCLI support. Closes (#2815) - Argilla server docker image is built with PostgreSQL support. Closes #2686
- The
rg.logcomputes all batches and raise an error for all failed batches. - The default batch size for
rg.logis now 100.
Fixed
argilla.trainingbugfixes and unification (#2665)- Resolved several small bugs in the
ArgillaTrainer.
Deprecated
- The
rg.log_asyncfunction is deprecated and will be removed in next minor release.
As always, thanks to out amazing contributors!
- docs: Fix broken links in README.md (#2759) by @stephantul
- Update how_to.ipynb by @chainyo
- Update logloadandpreparedata.ipynb by @ignacioct
- Python
Published by frascuchon about 3 years ago
argilla -
🔆 Highlights
User roles & settings page
We've introduced two user roles to help you manage your annotation team: admin and annotator. admin users can create, list and delete other users, workspaces and datasets. The annotator role is specifically designed for users who focus solely on annotating datasets.

We've also added a page to see your user's settings in the Argilla UI. To access it click on your user avatar at the top right corner and then select My settings.
Argilla Trainer
The new Argilla.training module deals with all data transformations and basic default configurations to train a model with annotations from Argilla using popular NLP frameworks. It currently supports spacy, setfit and transformers.
Additionally, admin users can access ready-made code snippets to copy-paste directly from the Argilla UI. Just go to the dataset you want to use, click the </> Train button in the top banner and select your preferred framework.

Learn more about Argilla.training in our docs.
Database support
Argilla will now create a default SQLite database to store users and workspaces. PostgreSQL is also officially supported. Simply set a custom value for the ARGILLA_DATABASE_URL environment variable pointing to your PostgreSQL instance.
Changelog 1.6.0
Added
ARGILLA_HOME_PATHnew environment variable (#2564).ARGILLA_DATABASE_URLnew environment variable (#2564).- Basic support for user roles with
adminandannotator(#2564). id,first_name,last_name,role,inserted_atandupdated_atnew user fields (#2564)./api/usersnew endpoint to list and create users (#2564)./api/users/{user_id}new endpoint to delete users (#2564)./api/workspacesnew endpoint to list and create workspaces (#2564)./api/workspaces/{workspace_id}/usersnew endpoint to list workspace users (#2564)./api/workspaces/{workspace_id}/users/{user_id}new endpoint to create and delete workspace users (#2564).argilla.tasks.users.migratenew task to migrate users from old YAML file to database (#2564).argilla.tasks.users.createnew task to create a user (#2564).argilla.tasks.users.create_defaultnew task to create a user with default credentials (#2564).argilla.tasks.database.migratenew task to execute database migrations (#2564).release.Dockerfileandquickstart.Dockerfilenow creates a defaultargilladatavolume to persist data (#2564).- Add user settings page. Closes #2496
- Added
Argilla.trainingmodule with support forspacy,setfit, andtransformers. Closes #2504
Fixes
- Now the
prepare_for_trainingmethod is working whenmulti_label=True. Closes #2606
Changed
ARGILLA_USERS_DB_FILEenvironment variable now it's only used to migrate users from YAML file to database (#2564).full_nameuser field is now deprecated andfirst_nameandlast_nameshould be used instead (#2564).passworduser field now requires a minimum of8and a maximum of100characters in size (#2564).quickstart.Dockerfileimage default users fromteamandargillatoadminandannotatorincluding new passwords and API keys (#2564).- Datasets to be managed only by users with
adminrole (#2564). - The list of rules is now accessible while metrics are computed. Closes#2117
- Style updates for weak labelling and adding feedback toast when delete rules. See #2626 and #2648
Removed
emailuser field (#2564).disableduser field (#2564).- Support for private workspaces (#2564).
ARGILLA_LOCAL_AUTH_DEFAULT_APIKEYandARGILLA_LOCAL_AUTH_DEFAULT_PASSWORDenvironment variables. Usepython -m argilla.tasks.users.create_defaultinstead (#2564).- The old headers for
API Keyandworkspacefrom python client - The default value for old
API Keyconstant. Closes #2251
As always, thanks to our amazing contributors!
- feat: add ArgillaSpaCyTrainer for both TokenClassification and TextClassification (#2604) by @alvarobartt
- Move dataset dump to train, ignored unnecessary imports, & remove requiredfields attribute (#2642) by @alvarobartt
- fix: update field name in metadata for image url (#2609) by @burtenshaw
- fix Install doc spell error by @PhilipMay
- fix: broken README.md link (#2616) by @alvarobartt
- Python
Published by frascuchon about 3 years ago
argilla -
1.5.1
Fixes
- Copying datasets between workspaces with proper owner/workspace info. Closes #2562
- Copy dataset with empty workspace to the default user workspace. See #2618
- Using elasticsearch config to request backend version. Closes #2311
- Remove sorting by score in labels. Closes #2622
Changed
- Update field name in metadata for image url. See #2609
- Python
Published by frascuchon over 3 years ago
argilla - v.1.5.0
🔆 Highlights
Dataset Settings page

We have added a Settings page for your datasets. From there, you will be able to manage your dataset. Currently, it is possible to add labels to your labeling schema and delete the dataset.
Add images to your records

You can pass a URL in the metadata field _image_url and the image will be rendered in the Argilla UI. You can use this in the Text Classification and the Token Classification tasks.
Non-searchable metadata fields
Apart from the _image_url field you can also pass other metadata fields that won't be used in queries or filters by adding an underscore at the start e.g. _my_field.
Load only what you need using rg.load
You can now specify the fields you want to load from your Argilla dataset. That way, you can avoid loading heavy vectors if you're using them for your annotations.
Two new tutorials (kudos @embonhomme & @burtenshaw)
Check out our new tutorials created by the community! - Compare the performance of two text classification models here - Multimodal bulk annotation here
Changelog
All notable changes to this project will be documented in this file. See standard-version for commit guidelines.
1.5.0 - 2023-03-21
Added
- Add the fields to retrieve when loading the data from argilla.
rg.loadtakes too long because of the vector field, even when users don't need it. Closes #2398 - Add new page and components for dataset settings. Closes #2442
- Add ability to show image in records (for TokenClassification and TextClassification) if an URL is passed in metadata with the key
_image_url - Non-searchable fields support in metadata. #2570
Changed
- Labels are now centralized in a specific vuex ORM called GlobalLabel Model, see https://github.com/argilla-io/argilla/issues/2210. This model is the same for TokenClassification and TextClassification (so both task have labels with color_id and shortcuts parameters in the vuex ORM)
- The shortcuts improvement for labels #2339 have been moved to the vuex ORM in dataset settings feature #2444
- Update "Define a labeling schema" section in docs.
- The record inputs are sorted alphabetically in UI by default. #2581
Fixes
- Allow URL to be clickable in Jupyter notebook again. Closes #2527
Removed
- Removing some data scan deprecated endpoints used by old clients. This change will break compatibility with client
<v1.3.0 - Stop using old scan deprecated endpoints in python client. This logic will break client compatibility with server version
<1.3.0 - Remove the previous way to add labels through the dataset page. Now labels can be added only through dataset settings page.
As always, thanks to our amazing contributors!
- Documentation update: tutorial for text classification models comparison (#2426) by @embonhomme
- Docs: fix little typo (#2522) by @anakin87
- Docs: Tutorial on image classification (#2420) by @burtenshaw
- Python
Published by frascuchon over 3 years ago
argilla - v1.4.0
🔆 Highlights
Enhanced annotation flow for all tasks
Improved bulk annotation and actions
A more stylish banner for available global actions. It includes an improved label selector to apply and remove labels in bulk.

We enhanced multi-label text classification annotations and now adding labels in bulk doesn't remove previous labels. This action will change the status of the records to Pending and you will need to validate the annotation to save the changes.
Learn more about bulk annotations and multi-level text classification annotations in our docs.
Clear and Reset actions
New actions to clear all annotations and reset changes. They can be used at the record level or as bulk actions.
Unvalidate and undiscard
Click the Validate or Discard buttons in a record to undo this action.
Optimized one-record view
Improved view for a single record to enable a more focused annotation experience.
Prepare for training for SparkNLP Text2Text
Extended support to prepare Text2Text datasets for training with SparkNLP.
Learn more in our docs.
Extended shortcuts for token classification (kudos @cceyda)
In token classification tasks that have 10+ options, labels get assigned QWERTY keys as shortcuts.
Changelog
All notable changes to this project will be documented in this file. See standard-version for commit guidelines.
1.4.0 (2023-03-09)
Features
configure_datasetaccepts a workspace as argument (#2503) (29c9ee3),- Add
active_clientfunction to main argilla module (#2387) (4e623d4), closes #2183 - Add text2text support for prepare for training spark nlp (#2466) (21efb83), closes #2465 #2482
- Allow passing workspace as client param for
rg.logorrg.load(#2425) (b3b897a), closes #2059 - Bulk annotation improvement (#2437) (3fce915), closes #2264
- Deprecate
chunk_sizein favor ofbatch_sizeforrg.log(#2455) (3ebea76), closes #2453 - Expose
batch_sizeparameter forrg.load(#2460) (e25be3e), closes #2454 #2434 - Extend shortcuts to include alphabet for token classification (#2339) (4a92b35)
Bug Fixes
- added flexible app redirect to docs page (#2428) (5600301), closes #2377
- added regex match to set workspace method (#2427) (d789fa1), closes [#2388]
- error when loading record with empty string query (#2429) (fc71c3b), closes #2400 #2303
- Remove extra-action dropdown state after navigation (#2479) (9328994), closes #2158
Documentation
- Add AutoTrain to readme (7199780)
- Add migration to label schema section (#2435) (d57a1e5), closes #2003 #2003
- Adds zero+few shot tutorial with SetFit (#2409) (6c679ad)
- Update readme with quickstart section and new links to guides (#2333) (91a77ad)
As always, thanks to our amazing contributors!
- Documentation update: adding missing n (#2362) by @Gnonpi
- feat: Extend shortcuts to include alphabet for token classification (#2339) by @cceyda
- Python
Published by frascuchon over 3 years ago
argilla - v1.3.1
1.3.1 (2023-02-24)
Bug Fixes
quickstart: change default api key for the argilla quickstart image (#2357) (bb14f3c)
Resolve errors found in
prepare_for_trainingduringautotrainintegration (https://github.com/argilla-io/argilla/pull/2411) Closes https://github.com/argilla-io/argilla/issues/2406 Closes https://github.com/argilla-io/argilla/issues/2407 Closes https://github.com/argilla-io/argilla/issues/2408 Closes https://github.com/argilla-io/argilla/issues/2405
Documentation
- Python
Published by frascuchon over 3 years ago
argilla - v1.3.0
🔆 Highlights
Keyword metric from Python client
Most important keywords in the dataset or a subset (using the query param) can be retrieved from Python. This can be useful for EDA and defining programmatic labeling rules:
python
from argilla.metrics.commons import keywords
summary = keywords(name="example-dataset")
summary.visualize() # will plot an histogram with results
summary.data # returns the raw result data
Prepare for training for SparkNLP and spaCy text-cat
Added a new framework sparknlp and extended the support for spacy including text classification datasets. Check out this section of the docs
Create train and test split with preparefortraining
You can pass train_size and test_size to prepare_for_training to get train-test splits. This is especially useful for spaCy. Check out this section of the docs
Better repr for Dataset and Rule (kudos @Ankush-Chander)
When using the Python client now you get a human-readable visualization of Dataset and Rule entities
Changelog
All notable changes to this project will be documented in this file. See standard-version for commit guidelines.
1.3.0 (2023-02-09)
Features
- better log error handling (#2245) (66e5cce), closes #2005
- Change view mode order in sidebar (#2215) (dff1ea1), closes #2214
- Client: Expose keywords dataset metrics (#2290) (a945c5e), closes #2135
- Client: relax client constraints for rules management (#2242) (6e749b7), closes #2048
- Create a multiple contextual help component (#2255) (a35fae2), closes #1926
- Include record event_timestamp (#2156) (3992b8f), closes #1911
- updated the
prepare_for_trainingmethods (#2225) (e53c201), closes #2154 #2132 #2122 #2045 #1697
Bug Fixes
- Client: formatting caused offset in prediction (#2241) (d65db5a)
- Client: Log remaining data when shutdown the dataset consumer (#2269) (d78963e), closes #2189
- validate predictions fails on text2text (#2271) (f68856e), closes #2252
Visual enhancements
- Fine tune menu record card (#2240) (62148e5), closes #2224
- Rely on box-shadow to provide the secondary underline (#2283) (d786171), closes #2282 #2282
Documentation
- Add deploy on Spaces buttons (#2293) (60164a0)
- fix typo in documentation (#2296) (ab8e85e)
- Improve deployment and quickstart docs and tutorials (#2201) (075bf94), closes #2162
- More spaces! (#2309) (f02eb60)
- Remove cut-off sentence in docs codeblock (#2287) (7e87f20)
- Rephrase
to know moreintoto learn morein Quickstart login page (#2305) (6082a26) - Replace leftover
rubrix.apikeywithargilla.apikey(#2286) (4871127), closes #2254 #2254 - Simplify token attributions code block (#2322) (4cb6ae1)
- Tutorial buttons (#2310) (d6e02de)
- Update colab guide (#2320) (e48a7cc)
- Update HF Spaces creation image (#2314) (e4b2a04)
As always, thanks to our amazing contributors!
- add repr method for Rule, Dataset. (#2148) by @Ankush-Chander
- opensearch docker compose file doesn't run (#2228) by @kayvane1
- Docs: fix typo in documentation (#2296) by @anakin87
- Python
Published by frascuchon over 3 years ago
argilla - v1.2.1
1.2.1 (2023-01-23)
Bug Fixes
- Allow non-alphanumeric characters for login (#2207) (629499a), closes #1879
- Client: Stop using
ujsonfor client actions (#2211) (920213e) - doc typos (#2203) (b353a30)
- Read statics with proper encoding (#2234) (92739bf), closes #2219
- Remove 3.9+ string methods (#2230) (4ed1ff0), closes #2192
- Remove argilla:stats in metadata filter (#2218) (a412b22), closes #2217, #2220
- Python
Published by frascuchon over 3 years ago
argilla - v1.2.0
1.2.0 (2023-01-12)
🔆 Highlights
Data labelling and curation with similarity search
Since 1.2.0 Argilla supports adding vectors to Argilla records which can then be used for finding the most similar records to a given one. This feature uses vector or semantic search combined with more traditional search (keyword and filter based).

View record info
You can now find all record details and fields which can be useful for bookmarking, copy/pasting, and making ES queries

View record timestamp
You can now see the timestamp associated with the record timestamp (event timestamp) which corresponds to the moment when the record was uploaded or a custom timestamp passed when logging the data (e.g., when the prediction was made when using it for monitoring)
Configure the base path of your Argilla UI (useful for proxies)
See: https://docs.argilla.io/en/latest/gettingstarted/installation/serverconfiguration.html#using-a-proxy
Features
- Allow to launch the argilla server in a different base_url (#2080) (63d624d), closes #1914 #1899
- Check es connection on startup with retries (#2141) (7a63bea)
- enable partial record update (#2118) (4ed0d95)
- Improve the
dataset_labelsmetric processing (#1978) (1c3235e), closes #1818 - Include record event_timestamp (#2156) (5b75ade), closes #1911
- Include record info view and remove metadata filter (#2079) (901d45a), closes #1927 #1849
- Raw records scan endpoint (#2102) (1b63d95)
- reuse the same
httpxasync client instance (#1958) (a70cb6c), closes #1886 - Search: Allow passing raw es query in search query (#2098) (0541798)
- set record timestamp by default (#1970) (309fd9f), closes #1892
- Similarity vector search (#1768) (#1998) (32958f4), closes #1757
- UI: remove mixins to hide scroll bar in drop down (#2000) (95ad9b8), closes #1928
Bug Fixes
- #1912 hide empty menu dropdown (#1981) (d90390b)
- Avoid manipulating DOM (#1895) (6939b28), closes #1765
- catch ImportError for telemetry module (#1989) (25513b7)
- Client: check url underscore only for hostnames (#2185) (ec5726a)
- client: prevent python client response json parse error (#2186) (5549ab0)
- Compute predicted properly for token classification REINDEXDATASETREF (a29a198), closes #1955
- Disable shortcuts for pagination when focus is on an input tag (#1995) (af07f3e), closes #1976
- Migration: Set dynamic to false for old indices (#2167) (15a18d7)
- Prevent show "No result" before data is loaded (#2014) (0799425), closes #1936
Documentation
- Add new tutorial about zeroshot sentiment analysis with GPT-3 (#2011) (d3c43ab)
- added additional explanation for datetime ranges (#2120) (c8c3dc9), closes #2119
- Adds Hugging Face Space deployment guide (#2109) (a7a47c4)
- changed DatasetForTextGeneration to DatasetForText2Text (#2090) (8cde28b), closes #2089
- Fix load docstring example (#2050) (7e2af7f), closes #1951
- fixed typo errors for terminology section (#2025) (1056736)
- include new OG image (#2017) (710ab3f)
- Include og image (#2016) (85442e4)
- Maintain menu position during navigation (#1935) (82c6e08), closes #1864
- New setfit tutorial (#2002) (43c66b2)
- Replace OG image (#2018) (894b273)
- Replace video with image (#1990) (359b637)
- reverted to correct apikey reference (#2136) (f32f2b8), closes #2074
As always, thanks to our amazing contributors!
- Add Azure deployment tutorial (#2124) by @burtenshaw
- Create training-textclassification-activelearning-with-GPU.ipynb (#2020) by @MoritzLaurer
- Python
Published by frascuchon over 3 years ago
argilla - v1.1.0
1.1.0 (2022-11-24)
Highlights
Add, update, and delete rules from a Dataset using the Python client
You can now manage rules programmatically and reflect them in Argilla Datasets so you can iterate on labeling rules from both Python and the UI. This is especially useful for leveraging linguistic resources (such as terminological lists) and making the rules available in the UI for domain experts to refine them.
```python
Read a file with keywords or phrases
labelingrulesdf = pd.readcsv("../../static/datasets/weaksupervisiontutorial/labeling_rules.csv")
Create rules
predefinedlabelingrules = [] for index, row in labelingrulesdf.iterrows(): predefinedlabelingrules.append( Rule(row["query"], row["label"]) )
Add the rules to the weaksupervisionyt dataset. The rules will be manageable from the UI
addrules(dataset="weaksupervisionyt", rules=predefinedlabeling_rules ```
You can find more info about this feature in the deep dive guide: https://docs.argilla.io/en/latest/guides/techniques/weak_supervision.html#3.-Building-and-analyzing-weak-labels
Sort by timestamp fields in the UI
Users can now sort the records by last_updated and other timestamp fields to improve the labeling and review processes
Features
- #1929 add warning about using wrong hostnames (#1930) (a3bc554)
- Add, delete and edit labeling rules from Python client (#1884) (d534a29), closes #1855
- Added more explicit error message regarding dataset name validation (#1933) (c25a225), closes #1931 #1918
- Allow sort records by eventtimestamp or lastupdated fields (#1924) (1c08c36), closes #1835
- Create a contextual help to support the user in the different dataset views (#1913) (8e3851e)
- Enable metadata length field config by environment variable (#1923) (0ff2de7), closes #1761
- Update error page (#1932) (caeb7d4), closes #1894
- Using new
top_k_mentionsmetrics instead ofentity_consistency(#1880) (42f702d), closes #1834
Bug Fixes
- Avoid closing the score filter when dragging the slider (#1822) (91a72c5), closes #1802
- Change method for Doc creation by spacy.Language (#1891) (6264983), closes #1890
- DAO: datasets dao filter datasets by tasks (#1934) (937b410)
- docker: Prevent wrong elastic server for wait-for-it (c6a10c7)
- Improve access to label list in Text Classification (#1916) (24729bd), closes #1804
- Improve explanation readability (#1815) (52c712e), closes #1774
- Monitoring: Serializable log middleware (#1908) (53a57f7)
- Move "Show less" button to the end of entities list (#1875) (6d796a4), closes #1779
- Remove "Help explain button" in Manage rule view (#1909) (8bc70b0), closes #1807
- Remove extra html when text is not highlighted (#1904) (7858dc5), closes #1758
- Remove extra type when highlighting the query in the text (#1863) (341c581), closes #1758
Documentation
- change iframe for mp4 (dfac8b2)
- corrected for iframe (935f586)
- Link key features (#1805) (#1809) (4c83604)
- resolved miss-direction and old naming in README.md (f45fe1e)
- Update README links linkedin and twitter (#1797) (2d4d03a)
As always, thanks to our amazing contributors!
- docs: Link key features (#1805) (#1809) by @chschroeder
- View Docs link in frontend header
users.vue(#1915) by @bengsoon - fix: Change method for Doc creation by spacy.Language (#1891) by @jamnicki
- Python
Published by frascuchon over 3 years ago
argilla - v0.18.0
0.18.0 (2022-10-05)
⚡ Highlights
Better validation of token classification records
When working with Token Classification records, there are very often misalignment problems between the entity spans and provided tokens. Before this release, it was difficult to understand and fix these errors because validation happened on the server side.
With this release, records are validated during instantiation, giving you a clear error message which can help you to fix/ignore problematic records.
For example, the following record: ```python import rubrix as rb
rb.TokenClassificationRecord( tokens=["I", "love", "Paris"], text="I love Paris!", prediction=[("LOC",7,13)] ) ``` Will give you the following error message:
python
ValueError: Following entity spans are not aligned with provided tokenization
Spans:
- [Paris!] defined in ...love Paris!
Tokens:
['I', 'love', 'Paris']
Delete records by query
Now it's possible to delete specific records, either by ids or by a query using Lucene's syntax. This is useful for clean up and better dataset maintenance:
```python import rubrix as rb
Delete by id
rb.delete_records(name="example-dataset", ids=[1,3,5])
Discard records by query
rb.deleterecords(name="example-dataset", query="metadata.code=33", discardonly=True) ```
New tutorials
We have two new tutorials!
Few-shot classification with SetFit and a custom dataset: https://rubrix.readthedocs.io/en/stable/tutorials/few-shot-classification-with-setfit.html
Analyzing predictions with model explainability methods: https://rubrix.readthedocs.io/en/stable/tutorials/nlpmodelexplainability.html https://rubrix.readthedocs.io/en/stable/tutorials/few-shot-classification-with-setfit.html
Features
- API: provide a dict for record annotations/predictions (#1658) (12b0f83)
- Client: expose client extra headers in init function (#1715) (79f0529), closes #1706
- Client: improve httpx errors handling (#1662) (85da336)
- Client: validate token classification annotations in client (#1709) (936d1ca), closes #1579
- Datasets: delete records by query (#1721) (bc9685d), closes #1714 #1737
- Datasets: restrict dataset deletion only to creators and super-users (#1713) (c1bef9d), closes #1740
- Server: Add server telemetry (#1687) (d7cc006)
Bug Fixes
- 'MajorityVoter.score' when using multi-labels (#1678) (0b94c86), closes #1628
- Metadata limits: exclude subfields from mappings (#1700) (9f9650e), closes #1699
- Normalizes the UnauthorizationError for the API response (#1748) (6a68048)
- Search tag reset prior annotation (#1736) (dc0a17f), closes #1711
Visual enhancements
Documentation
- Add interpret tutorial with Transformers (#1728) (c3fa079), closes #1729
- Adds tutorial about custom few-shot classification with SetFit (#1739) (4f15ee6), closes #1741
- fixing the active learning tutorial with
small-text(#1726) (909efdf), closes #1693 - raise small-text version to 1.1.0 and adapt tutorial (#1744) (16f19b7), closes #1693
- Resolve many typos in documentation, comments and tutorials (#1701) (f05e1c1)
- using official token class. mapper since is compatible now (#1738) (e82fd13), closes #482
As always, thanks to our amazing contributors!
- refactor: accept flat text as input for token classification mapper (#1686) by @Ankush-Chander
- feat(Client): improve httpx errors handling (#1662) by @Ankush-Chander
- fix: 'MajorityVoter.score' when using multi-labels (#1678) by @dcfidalgo
- docs: raise small-text version to 1.1.0 and adapt tutorial (#1744) by @chschroeder
- refactor: Incompatible attribute type fixed (#1675) by @luca-digrazia
- docs: Resolve many typos in documentation, comments and tutorials (#1701) by @tomaarsen
- refactor: Collection of changes, primarily regarding test suite and its coverage (#1702) by @tomaarsen
- Python
Published by frascuchon over 3 years ago
argilla - v0.17.0
0.17.0 (2022-08-22)
⚡ Highlights
Preparing a training set in the spaCy DocBin format
prepare_for_training is a method that prepares a dataset for training. Before prepare_for_training prepared the data for easily training Hugginface Transformers.
Now, you can prepare your training data for spaCy NER pipelines, thanks to our great community contributor @ignacioct !
With the example below, you can export your Rubrix dataset into a Docbin, save it to disk, and then use it with the spacy train command.
```python import spacy import rubrix as rb
from datasets import load_dataset
Load annotated dataset from Rubrix
rbdataset = rb.load("nerdataset")
Loading an spaCy blank language model to create the Docbin, as it works faster
nlp = spacy.blank("en")
After this line, the file will be stored in disk
rbdataset.preparefortraining(framework="spacy", lang=nlp).todisk("train.spacy") ```
You can find a full example at: https://rubrix.readthedocs.io/en/v0.17.0/guides/cookbook.html#Train-a-spaCy-model-by-exporting-to-Docbin
Load large datasets using batches
Before this release, the rb.load method to read datasets from Python retrieved the full dataset. For large datasets, this could cause high memory consumption, network timeouts, and the inability to read datasets larger than the available memory.
Thanks to the awesome work by @maxserras. Now it's possible to optimize memory consumption and avoid network timeouts when working with large datasets. To that end, a simple batch-iteration over the whole database can be done employing the from_id parameter in the rb.load method.
An example of reading the first 1000 records and the next batch of up to 1000 records:
python
import rubrix as rb
dataset_batch_1 = rb.load(name="example-dataset", limit=1000)
dataset_batch_2 = rb.load(name="example-dataset", limit=1000, id_from=dataset_batch_1[-1].id)
The reference to the rb.load method can be found at: https://rubrix.readthedocs.io/en/v0.17.0/reference/python/python_client.html#rubrix.load
Larger pagination sizes for faster bulk review and annotation
Using filters and search for data annotation and review, some users are able to filter and quickly review dozens of records in one go. To serve those users, it's now possible to see and bulk annotate 50 and 100 records in each page.

Copy record text to clipboard
Sometimes is useful to copy the text in records to use inspect it or process it with another application. Now, this is possible thanks to the feature request by our great community member and contributor @Ankush-Chander !

Better error logging for generic errors
Thanks to work done by @Ankush-Chander and @frascuchon we now have more meaningful messages for generic server errors!
Features
- Add new pagination size ranges (#1667) (5b4f1f2), closes #1578
- Allow
rb.loadfetch records in batches passing thefrom_idargument (3e6344a) - Copy to clipboard the record text (#1625) (d634a7b), closes #1616
- Error Logging: send error detail in response for generic server errors (#1648) (ad17631)
- Listeners: allow using query params in the condition through search parameter (#1627) (a0a245d), closes #1622
prepare_for_trainingsupports spacy (#1635) (8587808)
Bug Fixes
- Client: reusing the inner
httpxclient (#1640) (854a972), closes #1646 - docker-compose.yaml: default volume and disable disk threshold (#1656) (05ae688), closes #1275
- Encode rule name in Weak Labeling API requests (#1649) (4634df8), closes #1645
- handle stream api connection errors gracefully (#1636) (a106ec4), closes #1559
- Update progress bar when refreshing after adding new records (#1666) (7e0d915), closes #1590
Documentation
- Add Slack support link in README's get started (#1688) (bef010c)
- Adding Elasticsearch persistence to docker compose section (#1643) (ecdc854)
- spacy
DocBincookbook (#1642) (bb98278), closes #420
Visual enhancements
- Small visual adjustments for Text2Text record card (#1632) (9c87cf1), closes #1138
- Improve card spacing (#1638) (fd4016a), closes #1624
You can see all work included in the release here
- fix: Update progress bar when refreshing after adding new records (#1666) by @leiyre
- chore: configure miniconda for readthedocs builder by @frascuchon
- style: Small visual adjustments for Text2Text record card (#1632) by @leiyre
- feat: Copy to clipboard the record text (#1625) by @leiyre
- docs: Add Slack support link in README's get started (#1688) by @dvsrepo
- chore: update version by @frascuchon
- feat: Add new pagination size ranges (#1667) by @leiyre
- fix: handle stream api connection errors gracefully (#1636) by @Ankush-Chander
- feat: allow
rb.loadfetch records in batches passing thefrom_idargument by @maxserras - fix(Client): reusing the inner
httpxclient (#1640) by @frascuchon - feat(Error Logging): send error detail in response for generic server errors (#1648) by @frascuchon
- docs: spacy
DocBincookbook (#1642) by @ignacioct - feat: preparefortraining supports spacy (#1635) by @frascuchon
- style: Improve card spacing (#1638) by @leiyre
- docs: Adding Elasticsearch persistence to docker compose section (#1643) by @maxserras
- chore: remove old rubrix client class (#1639) by @frascuchon
- feat(Listeners): allow using query params in the condition through search parameter (#1627) by @frascuchon
- doc: show metric graphs in documentation (#1669) by @leiyre
- fix(docker-compose.yaml): default volume and disable disk threshold (#1656) by @frascuchon
- fix: Encode rule name in Weak Labeling API requests (#1649) by @leiyre
- Python
Published by frascuchon almost 4 years ago
argilla - v0.16.1
0.16.1 (2022-07-22)
Bug Fixes
- 'WeakMultiLabels.summary' and 'show_records' after extending the weak label matrix (#1633) (3cb4c07), closes #1631
- Display metadata in Text2Text dataset (#1626) (0089e0a), closes #1623
- Show predicted OK/KO when predictions exist (#1620) (ef66e9c), closes #1619
Documentation
You can see all work included in the release here
- fix: 'WeakMultiLabels.summary' and 'show_records' after extending the weak label matrix (#1633) by @dcfidalgo
- fix: Display metadata in Text2Text dataset (#1626) by @leiyre
- chore: set version by @dcfidalgo
- docs: Fix typo in Getting Started -> Concepts (#1618) by @dcfidalgo
- fix: Show predicted OK/KO when predictions exist (#1620) by @leiyre
- Python
Published by frascuchon almost 4 years ago
argilla -
0.16.0 (2022-07-08)
Highlights
👂 Listeners: enable more interactive workflows between client and server
Listeners enable you to define functions that get executed under certain conditions when something changes in a dataset. There are many use cases for this: monitoring annotation jobs, monitoring model predictions, enabling active learning workflows, and many more.
You can find the Python API reference docs here: https://rubrix.readthedocs.io/en/stable/reference/python/python_listeners.html#python-listeners
We will be documenting these use cases with practical examples, but for this release, we've included a new tutorial for using this with active learning: https://rubrix.readthedocs.io/en/stable/tutorials/activelearningwithsmalltext.html. This tutorial includes the following listener function, which implements the active learning loop:
```python from rubrix.listeners import listener from sklearn.metrics import accuracy_score
Define some helper variables
LABEL2INT = trec["train"].features["label-coarse"].str2int ACCURACIES = []
Set up the active learning loop with the listener decorator
@listener( dataset=DATASETNAME, query="status:Validated AND metadata.batchid:{batchid}", condition=lambda search: search.total==NUMSAMPLES, executionintervalinseconds=3, batchid=0 ) def activelearningloop(records, ctx):
# 1. Update active learner
print(f"Updating with batch_id {ctx.query_params['batch_id']} ...")
y = np.array([LABEL2INT(rec.annotation) for rec in records])
# initial update
if ctx.query_params["batch_id"] == 0:
indices = np.array([rec.id for rec in records])
active_learner.initialize_data(indices, y)
# update with the prior queried indices
else:
active_learner.update(y)
print("Done!")
# 2. Query active learner
print("Querying new data points ...")
queried_indices = active_learner.query(num_samples=NUM_SAMPLES)
ctx.query_params["batch_id"] += 1
new_records = [
rb.TextClassificationRecord(
text=trec["train"]["text"][idx],
metadata={"batch_id": ctx.query_params["batch_id"]},
id=idx,
)
for idx in queried_indices
]
# 3. Log the batch to Rubrix
rb.log(new_records, DATASET_NAME)
# 4. Evaluate current classifier on the test set
print("Evaluating current classifier ...")
accuracy = accuracy_score(
dataset_test.y,
active_learner.classifier.predict(dataset_test),
)
ACCURACIES.append(accuracy)
print("Done!")
print("Waiting for annotations ...")
```
📖 New docs!
https://rubrix.readthedocs.io/

🧱 extend_matrix: Weak label augmentation using embeddings
This release includes an exciting feature to augment the coverage of your weak labels using embeddings. You can find a practical tutorial here: https://rubrix.readthedocs.io/en/stable/tutorials/extendweaklabelswithembeddings.html
Features
- #1561: standardize icons (#1565) (15254e7), closes #1561
- #1602: new rubrix dataset listeners (#1507, #1586, #1583, #1596) (65747ab), closes #1602
- Add 'extend_matrix' to the WeakMultiLabel class (#1577) (cf89311)
- Improve from datasets (#1567) (2b0d607)
- token-class: adjust token spans spaces (#1599) (0fb3576)
Bug Fixes
- #1264: discard first space after a token (#1591) (eff0ac5), closes #1264
- #1545: highlight words with accents (#1550) (c42e77b), closes #1545
- #1548: access datasets for superusers when workspace is not provided (#1572, #1608) (0b04bc8), closes #1548
- #1551: don't show error traces for EntityNotFoundError's (#1569) (04e101c), closes #1551
- #1557: allow text editing when clicking the "edit" button (#1558) (e751414), closes #1557
- #1574: search highlighting for a single dot (#1592) (53474a1), closes #1574
- #1575: show predicted ok/ko in Text Classifier explore mode (#1576) (ada87c0), closes #1575
- compatibility with new dataset version (#1566) (ac26e30)
Documentation
- #1512: change theme to furo (#1564, #1604) (98869d2), closes #1512
- add 'how to prepare your data for training' to basics (#1589) (a21bcf3)
- add active learning with small text and listener tutorial (#1585, #1609) (d59573f), closes #1601 #421
- Add MajorityVoter to references + Add comments about multi-label support of the label models (#1582) (ab481c7)
- add pip version and dockertag as parameter in the build process (#1560) (73a31e2)
You can see all work included in the release here
- chore(docs): remove by @frascuchon
- docs: add active learning with small text and listener tutorial (#1585, #1609) by @dcfidalgo
- docs(#1512): change theme to furo (#1564, #1604) by @frascuchon
- chore: set version by @frascuchon
- feat(token-class): adjust token spans spaces (#1599) by @frascuchon
- feat(#1602): new rubrix dataset listeners (#1507, #1586, #1583, #1596) by @frascuchon
- docs: add 'how to prepare your data for training' to basics (#1589) by @dcfidalgo
- test: configure numpy to disable multi threading (#1593) by @frascuchon
- docs: Add MajorityVoter to references + Add comments about multi-label support of the label models (#1582) by @dcfidalgo
- feat(#1561): standardize icons (#1565) by @leiyre
- Feat: Improve from datasets (#1567) by @dcfidalgo
- feat: Add 'extend_matrix' to the WeakMultiLabel class (#1577) by @dcfidalgo
- docs: add pip version and dockertag as parameter in the build process (#1560) by @frascuchon
- refactor: remove
wordsreferences in searches (#1571) by @frascuchon - ci: check conda env cache (#1570) by @frascuchon
- fix(#1264): discard first space after a token (#1591) by @frascuchon
- ci(package): regenerate view snapshot (#1600) by @frascuchon
- fix(#1574): search highlighting for a single dot (#1592) by @leiyre
- fix(#1575): show predicted ok/ko in Text Classifier explore mode (#1576) by @leiyre
- fix(#1548): access datasets for superusers when workspace is not provided (#1572, #1608) by @frascuchon
- fix(#1551): don't show error traces for EntityNotFoundError's (#1569) by @frascuchon
- fix: compatibility with new dataset version (#1566) by @dcfidalgo
- fix(#1557): allow text editing when clicking the "edit" button (#1558) by @leiyre
- fix(#1545): highlight words with accents (#1550) by @leiyre
- Python
Published by frascuchon almost 4 years ago
argilla - v0.15.0
0.15.0 (2022-06-08)
🔆 Highlights
🏷️ Configure datasets with a labeling scheme
You can now predefine and change the label schema of your datasets. This is useful for fixing a set of labels for you and your annotation teams.
```python import rubrix as rb
Define labeling schema
settings = rb.TextClassificationSettings(label_schema=["A", "B", "C"])
Apply seetings to a new or already existing dataset
rb.configuredataset(name="mydataset", settings=settings)
Logging to the newly created dataset triggers the validation checks
rb.log(rb.TextClassificationRecord(text="text", annotation="D"), "my_dataset")
BadRequestApiError: Rubrix server returned an error with http status: 400
```
Read the docs: https://rubrix.readthedocs.io/en/stable/guides/dataset_settings.html
🧱 Weak label matrix augmentation using embeddings
You can now use an augmentation technique inspired by https://github.com/HazyResearch/epoxy to augment the coverage of your rules using embeddings (e.g., sentence transformers). This is useful for improving the recall of your labeling rules.
Read the tutorial: https://rubrix.readthedocs.io/en/stable/tutorials/extendweaklabelswithembeddings.html
🏛️ Tutorial Gallery
Tutorials are now organized into different categories and with a new gallery design!
Read the docs: https://rubrix.readthedocs.io/en/stable/tutorials/introductory.html
🏁 Basics guide
This is the first version of the basics guide. This guide will show you how to perform the most basic actions with Rubrix, such as uploading data or data annotation.
Read the docs: https://rubrix.readthedocs.io/en/stable/getting_started/basics.html
Features
- #1134: Allow extending the weak label matrix with embeddings (#1487) (4d54994), closes #1134
- #1432: configure datasets with a label schema (21e48c0), closes #1432
- #1446: copy icon position in datasets list (#1448) (7c9fa52), closes #1446
- #1460: include text hyphenation (#1469) (ec23b2d), closes #1460
- #1463: change icon position in table header (#1473) (5172324), closes #1463
- #1467: include animation delay for last progress bar track (#1462) (c772b74), closes #1467
- configuraton: add elasticsearch ca_cert path variable (#1502) (f0eda12)
- UI: improve access to actions in metadata and sort dropdowns (#1510) (8d33090), closes #1435
Bug Fixes
- #1522: dates metadata fields accessible for sorting (#1529) (a576ceb), closes #1522
- #1527: check agents instead labels for
predictedcomputation (#1528) (2f2ee2e), closes #1527 - #1532: correct domain for filter score histogram (#1540) (7478d6c), closes #1532
- #1533: restrict highlighted fields (3a8b8a9), closes #1533
- #1534: fix progress in the metrics sidebar when page is refreshed (#1536) (1b572c4)
- #1539: checkbox behavior with value 0 (#1541) (7a0ab63), closes #1539
- metrics: compute f1 for text classification (#1530) (147d38a)
- search: highlight only textual input fields (8b83a82), closes #1538 #1544
New contributors
@RafaelBod made his first contribution in https://github.com/recognai/rubrix/pull/1413
- Python
Published by frascuchon about 4 years ago
argilla -
0.14.2 (2022-05-31)
Bug Fixes
- #1514: allow ent score
Noneand change default value to 0.0 (#1521) (0a02c70), closes #1514 - #1516: restore read-only to copied dataset (#1520) (5b9cf0e), closes #1516
- #1517: stop background task when something happens to main thread (#1519) (0304f40), closes #1517
- #1518: disable global actions checkbox when no data was found (#1525) (bf35e72), closes #1518
- UI: remove selected metadata fields for sortable fields dropdown (#1513) (bb9482b)
- Python
Published by frascuchon about 4 years ago
argilla -
0.14.1 (2022-05-20)
Bug Fixes
- #1447: change agent when validating records with annotation but default status (#1480) (126e6f4), closes #1447
- #1472: hide scrollbar in scrollable components (#1490) (b056e4e), closes #1472
- #1483: close global actions "Annotate as" selector after deselect records checkbox (#1485) (a88f8cb)
- #1503: Count filter values when loading a dataset with a route query (#1506) (43be9b8), closes #1503
- documentation: fix user management guide (#1511) (63f7bee), closes #1501
- filters: sort filter values by count (#1488) (0987167), closes #1484
- Python
Published by frascuchon about 4 years ago
argilla - 🎉 0.14.0
0.14.0 (2022-05-10)
Async version of rb.log
You can now use the parameter background in the rb.log method to log records without blocking the main process. The main use case is monitoring production pipelines to do prediction monitoring. Here's an example with BentoML (you can find the full example in the updated Monitoring guide):
```python from bentoml import BentoService, api, artifacts, env from bentoml.adapters import JsonInput from bentoml.frameworks.spacy import SpacyModelArtifact
import rubrix as rb
import spacy
nlp = spacy.load("encoreweb_sm")
@env(inferpippackages=True) @artifacts([SpacyModelArtifact("nlp")]) class SpacyNERService(BentoService):
@api(input=JsonInput(), batch=True)
def predict(self, parsed_json_list):
result, rb_records = ([], [])
for index, parsed_json in enumerate(parsed_json_list):
doc = self.artifacts.nlp(parsed_json["text"])
prediction = [{"entity": ent.text, "label": ent.label_} for ent in doc.ents]
rb_records.append(
rb.TokenClassificationRecord(
text=doc.text,
tokens=[t.text for t in doc],
prediction=[
(ent.label_, ent.start_char, ent.end_char) for ent in doc.ents
],
)
)
result.append(prediction)
rb.log(
name="monitor-for-spacy-ner",
records=rb_records,
tags={"framework": "bentoml"},
background=True,
verbose=False
) # By using the background=True, the model latency won't be affected
return result
```
Confidence scores in Token Classification (NER)
To store entity predictions you can attach a score using the last position of the entity tuple (label, char_start, char_end, score). Let's see an example:
```python import rubrix as rb
text = "Rubrix is a data science tool"
record = rb.TokenClassificationRecord( text=text, tokens=text.split(" "), prediction=[("PRODUCT", 0, 6, 0.99)] )
rb.log(record, "nerwithscores") ``` Then, in the web application, you and your team can use the score filter to find potentially problematic entities, like in the screenshot below:

If you want to see this in action, check this blog post by David Berenstein:
https://www.rubrix.ml/blog/concise-concepts-rubrix/
Rule metrics sidebar
We have a fresh new sidebar for the weak labeling mode, where you can see your overall rule metrics as you define new rules.
This sidebar should help you quickly understand your progress:

See the updated user guide here: https://rubrix.readthedocs.io/en/v0.14.0/reference/webapp/define_rules.html
Features
- #1132: introduce async/background version of rb.log (#1391) (900307e), closes #1132
- #1247: label models predict method returns DatasetForTextClassification (#1442) (42ca1be), closes #1247
- #1379: show prediction score in NER (#1389) (0bdccd2), closes #1379 #1451
- #961: rules metrics in sidebar (#1377) (261f53a), closes #961 #1408
- home: improve table actions and styles (#1384) (f09746e), closes #1355 #1333
Bug Fixes
- #1407: fix visualization in 1024px viewport (#1420) (46f8d4d), closes #1441
- #1458: token classifier visualization in Safari (#1459) (01cc492), closes #1458
- Python
Published by frascuchon about 4 years ago
argilla -
0.13.3 (2022-04-27)
Bug Fixes
- #1248: allow multiple label attributions in UI (#1424) (a9f8363), closes #1248
- #1409: filtering by metadata with value list (#1415) (7aca061), closes #1409
- #1410: apply dataset name pattern to user name (#1411) (2087c21), closes #1410
- #1428: support cleanlab v2 (#1436) (d189ddb), closes #1428
- TokenClassification: display characters between tokens words (#1418) (a08cd7b), closes #1414 #1383
- Python
Published by frascuchon about 4 years ago
argilla - v0.13.2
0.13.2 (2022-04-12)
Bug Fixes
- #1265: persist pagination size after query (#1358) (49ca243), closes #1265
- #1367: remove record text from metadata modal (#1385) (1782724), closes #1367
- #1368: long list of entities in Token Classifier (#1388) (829269f), closes #1368 #1393
- #1387: improve metadata distinct values computation (be9f68f), closes #1387
- install: remove loguru dependency (#1372) (9e52414), closes #1331 #1305
- search: compute dataset schema properly for advanced query dsl (#1380) (f71ab91)
- visualization: force break word in selectors (#1406) (5ac1950)
- Python
Published by frascuchon about 4 years ago
argilla - v0.13.1
0.13.1 (2022-04-01)
Bug Fixes
- #1244: compute capitalness based on python methods (#1359 #1371) (218f099), closes #1244
- #1362: using active api method instead instance (#1363) (bcf446d), closes #1362
- #1365: create rules with regex queries (#1369) (c2afc9c), closes #1365
- Python
Published by frascuchon about 4 years ago
argilla - 🚀 v0.13.0
0.13.0 (2022-03-30)
🗂 Multilabel weak supervision
You can now build multilabel text classification datasets using query-based rules
If you want to get started, check out this tutorial.
https://user-images.githubusercontent.com/1107111/160930404-7b909f1e-b871-4e4c-b1c8-ea9eabfcad21.mp4
🤗 Reading Hugging Face datasets from the Hub
You can now read ANY text classification, NER, or text2text dataset directly from the Hub and load it into Rubrix.
To understand how Rubrix datasets work check out this guide.

👥 Redesigned team workspaces
Organizing teams and datasets is a key Rubrix feature. After several rounds of feedback with early users, we've completely redesigned the user experience. Let us know what you think.

You can get started and configure users and workspaces following this guide
🔎 Guide for the query language and model
We have included a new in-depth guide about the Lucene-based query language and data model used for search, weak labeling, loading subsets of data, and metrics.
Features
- #1119: users without personal datasets (#1282) (555d41d), closes #1119 #1318 #1317 #1323 #1324
- #1130: cleanup rb namespace by refactoring client API (#1160) (a0fdd8e), closes #1130
- #1144: weak supervision for multilabel datasets (#1166) (fd95bae), closes #1144 #1190 #1237 #1233 #1326
- datasets: simplify load flow from hf datasets with no rb format (#1234) (a6da1cd), closes #1327
- #1180: show Rubrix version in the webapp (#1243) (8c71ad9), closes #1180 #1350 #1349
- #1225: prepare tokenclass dataset for hf training (#1231) (ae5e7cd), closes #1225
- #950: using record search_keywords for highlighting (#1235) (47616bf), closes #950 #1278 #1316 #1315
- #981: add majority voter with multi label support (#1228) (8052aa8), closes #981
- Introduce a 'text' argument for the TextClassificationRecord (#1246) (bb7d93e)
Bug Fixes
- #1347: allow tooltip record overlapping in Token Classifier (#1352) (87174d3), closes #1347
- #1103: remove "Error Distribution" from metrics (#1255) (b9bb5b4), closes #1103
- #1149: fix vulnerable dependencies (node-sass) (#1263) (7f8c1d1), closes #1149
- #1211: fix score scale (#1261) (8a72281), closes #1211
- #1238: show prediction labels when annotating rule (#1239) (0321b88), closes #1238
- #1241, #1245: show new line char in metrics plot & increase mentions in entity consistency (#1257) (38930cb), closes #1241 #1245
- #1311: small defects about hover style (#1313) (442703c), closes #1311
- #1320: render car return in Token Classifier (#1328) (b7f1b7b), closes #1320
- #1335: force line break in rules summary (#1336) (2d77a76), closes #1335
- #1337: number of records in the overall annotated coverage (#1338) (d384713), closes #1337
- #1339: metrics and status not updated when the query is refreshed (#1340) (6fc0a58), closes #1339
- #984: manage super user workspaces (#1268) (9b24921), closes #984 #1288 #1290
- datasets: prevent error when no annotated records found in dataset (#1284) (c20028f)
- install: make starlette an optional dependency (#1295) (32afb3d)
- NER: create record annotation from tags (also in from_datasets) (#1283) (adcf1b1)
- rules: store single-label rules with a comp. format for old versions (#1334) (eb310d3)
- Python
Published by frascuchon over 4 years ago
argilla - v0.12.0
0.12.0 (2022-03-08)
Features
- #1029: improve server api logging (#1148) (d4a121a), closes #1029 #1224
- #1183: token classification fine-tuning (#1199) (2cdd30b), closes #1183
- #1192: disable ssl verify for elasticsearch http client (#1193) (631a729), closes #1192
- #950: include search keywords as part of record results (#1201) (2dd5853), closes #950
- #970: header redesign (#1185) (fa9c639), closes #970 #1218 #1214 #1223
- Implement 'preparefortraining' for text classification datasets (#1209) (f7fd59c)
Bug Fixes
- Python
Published by frascuchon over 4 years ago
argilla - 🎉 v0.10.0
0.10.0 (2022-02-12)
Now you can use filters in the Define Rules mode (weak labeling). These filters are useful for seeing the impact of rules on specific dataset subpopulations/subsets (e.g., with certain metadata fields, annotated records, etc.):

Features
- #1061: unify records results title (#1111) (54ebb15), closes #1061
- #982: show filters in labelling rules view (#1038) (7ff677b), closes #982
Bug Fixes
- #1054: reduce collapsable area. Optimize for annotation (#1106) (48024ba), closes #1054
- #1054: remove old scroll padlock button (a1d6444), closes #1054
- #1094: remove computed record fields returned in API results (#1095) (cd61d1e), closes #1094
- #831: Remove sort field when only one is applied (#1116) (36b276b), closes #831
- convert pd.NaT to
Noneforevent_timestamp(#1105) (21e78e4)
- Python
Published by frascuchon over 4 years ago
argilla - 🚀 v0.11.0
0.11.0 (2022-02-19)
Highlights
Introducing rb.Dataset* and 🤗 Hub integration
The Dataset classes are lightweight containers for Rubrix records. These classes facilitate importing from and exporting to different formats (e.g., pandas.DataFrame, datasets.Dataset) as well as sharing and versioning Rubrix datasets using the Hugging Face Hub.
With this release, Rubrix users and teams can use the Hugging Face Hub to share and read both public and private Rubrix datasets for TextClassification, TokenClassification, and Text2Text datasets. This opens up a whole new world of possibilities for data reproducibility and sharing. Let's see an example:
```python import rubrix as rb from datasets import load_datasets
👧🏻 🏷️ Leire has labeled a text classification dataset using a local Rubrix instance
datasetrb = rb.load("textclassificationds", aspandas=False)
👧🏻 exports a Rubrix Dataset to a hf Dataset
datasetds = datasetrb.to_datasets()
👧🏻 🚀 Leire shares the labelled dataset with the world
datasetds.pushtohub("textclassification_ds")
👨 John downloads the dataset from the Hugging Face Hub
datasetds = loaddataset("leire/textclassificationds", split="train")
👨 reads in dataset
datasetrb = rb.readdatasets(dataset_ds, task="TextClassification")
👨 🏷️ logs the dataset and continues labeling with his own Rubrix instance
rb.log(datasetrb, "johntextclassificationds") ```
You can read more at https://rubrix.readthedocs.io/en/stable/guides/datasets.html
For each record type, there’s a corresponding Dataset class called DatasetFor<RecordType>. You can look up their API in the reference section.
Improving NER UI and UX
The UI for Token Classification has been completely redesigned to provide a better user experience for exploration and annotation. This is the first of a set of changes focusing on annotation productivity for token classification.

Features
- #1051: keep predictions labels when annotating (#1077) (f1824ba), closes #1051
- #1063: Token Classifier fine tuning content selection (#1084) (9e14d05), closes #1063
- #1127: raise startup app error from es connection error (#1145) (7e7e9d8), closes #1127
- #422: introducing the rb.Dataset* classes (#1109) (b5bbca6), closes #422
- #821: token classifier show predictions in explore view (#1009) (6ba6764), closes #821
- #951: new "not covered records by rules" filter (#991) (0649f2a), closes #951 #1156
Bug Fixes
- #1140: fix/make client models more consistent (#1147) (926bb16), closes #1140
- client: parse unauthorized api error properly (#1164) (1a5a08d)
- search: prevent metrics computation breaks searches (#1175) (9f2adc9)
- Python
Published by frascuchon over 4 years ago
argilla - v0.9.0
🎉 0.9.0 (2022-02-02)
- Improve logging
- Small improvements to the labelling module and weak labeling mode
- Better setup documentation (
python -m rubrix)
Features
- #932: label models now modify the prediction_agent when calling LabelModel.predict (#1049) (4a024ee), closes #932
- #953: add additional metrics to
LabelModel.scoremethod (#979) (2887907), closes #953 - #955: add default for
rulesin WeakLabels (#976) (34389d3), closes #955 #1011
Bug Fixes
- #1045: calculate overall precision from overall correct/incorrect in rules (#1086) (1c76d81), closes #1045 #1087
- #1053: metadata modal position (#1068) (09b88cc), closes #1053 #1053
- #1054: optimize Long records (#1080) (fdd797a), closes #1054
- #1067: fix rule definition link when no labels are defined (#1069) (eb958bf), closes #1067
- #1081: prevent add records of different task (#1085) (5296e52), closes #1081 #1081
- #924: parse new error format in UI (#1082) (f26c79c), closes #924
- Python
Published by frascuchon over 4 years ago
argilla - v0.8.2
0.8.2 (2022-01-31)
Features
- #1036: remove prediction ok/ko in labelling rules (#1037) (672b852), closes #1036
- #735: add warning when agent but no prediction/annotation is provided (#987) (ba88c34), closes #735
Bug Fixes
- #1008: set the event_timestamp when annotating (#1024) (c24fdad), closes #1008
- #1015: manage emojis in Token Classification records (#1016) (8b570fb), closes #1015
- #1023: handle elasticsearch connection problems on server startup (#1030) (e8c8d86), closes #1023
- #1027: Improve client models by reordering fields + forbidding extra args (#1032) (6c1ae7f), closes #1027
- #1028: Add videos to Monitoring tutorial (#1033) (6ff3326), closes #1028
- #1050: generalizes entity span validation (#1055) (37207bc), closes #1050
- #1058: sort by % data in rules list (#1062) (9735f22), closes #1058
- #1065: 'B' tag for beginning tokens (#1066) (a5ed329), closes #1065
- cleanlab: set cleanlab n_jobs=1 as default (#1059) (189cbcb)
- Python
Published by frascuchon over 4 years ago
argilla - v0.8.1
0.8.1 (2022-01-20)
Bug Fixes
- #1002: Show 0 records overall metrics when no rules defined (#1013) (a8a5c79), closes #1002 #1002
- Breadcrumbs: copy workspace from the breadcrumbs when dataset loading has errors #1003 (33e372d), closes #844
- statics: handle 404 errors for static files (#1006) (f4b656a)
- #800: limit number of metadata fields (#993) (bb6b76b), closes #800
- #905: copy dataset with rules (#948) (8597b83), closes #905
- #974: display the dropdown in the last record of the scroll (#986) (e5f8d53), closes #974
- #977: Remove redirection when accessing login (#996) (b3fe2cb), closes #977
- Python
Published by frascuchon over 4 years ago
argilla -
0.8.1-alpha.2 (2022-01-20)
Bug Fixes
- #1002: Show 0 records overall metrics when no rules defined (#1007) (a890e17), closes #1002 #1002
- Breadcrumbs: copy workspace from the breadcrumbs when dataset loading has errors #1003 (33e372d), closes #844
- statics: handle 404 errors for static files (#1006) (f4b656a)
- Python
Published by frascuchon over 4 years ago
argilla - v0.8.1-alpha.0
0.8.1-alpha.0 (2022-01-19)
Bug Fixes
- #800: compute common aggregations one by one (#990) (8cf420a), closes #800
- #800: limit number of metadata fields (#993) (bb6b76b), closes #800
- #905: copy dataset with rules (#948) (8597b83), closes #905
- #974: display the dropdown in the last record of the scroll (#986) (e5f8d53), closes #974
- #977: Remove redirection when accessing login (#996) (b3fe2cb), closes #977
- Python
Published by frascuchon over 4 years ago
argilla - v0.8.0: Weak labeling for text classification
Introducing interactive Weak labeling (Define rules mode) 🚀
We are glad to introduce the most important feature to date: now it's possible to iterate on labeling queries directly in the UI with initial support for multi-class text classification. Multilabel and token classification support is coming soon.
See the video for the recommended workflow:
https://user-images.githubusercontent.com/1107111/149346471-93cbd7ee-96a2-451a-8f5e-f9e26b246407.mp4
Check the updated tutorial: https://rubrix.readthedocs.io/en/master/tutorials/weak-supervision-with-rubrix.html
What's changed
- [WeakSupervision] Change load_rules import path in guide and tutorial (#939)
- fix links to new web app reference (#936)
- Bugfixes/avoid infinite loop when dataset loading (#934)
- show nan instead of 0 for precision in summary (#930)
- fix(api): include_metrics param only for search endponts (#929)
- [Documentation] Update title page video for docs (#928)
- update skweak tutorial (#922)
- [Documentation] Updating the web app docu (#827)
- publish python package to test.pypi for master and releases branches (#927)
- [WeakLabels] Align WeakLabels.summary() with web app (#925)
- UI: show rules without precision properly (#919)
- chore(build): build docker images for release branches (#921)
- Docs: Updates readme front video (#923)
- Docs: Updates weak supervision resources (#920)
- feat(rules): compute total & ann. coverage before label selection (#916)
- fix(rules): compute annotated coverage when no label properly (#915)
- Tutorial: Human-in-the-loop weak supervision with skweak (#869)
- UI: include affected #records to overall coverage/ann. coverage metrics (#914)
- fix lint build (#913)
- UI: manage precision and rules without annotation coverage (#909)
- fix(#876): process 400 response detail properly (#889)
- feat(rules): allow compute partial query rule metrics (#907)
- fix(security): providing default workspace should pass check (#911)
- UI: reset filters from define rules view (#908)
- UI: Show number of created rules in rules management view (#910)
- UI: drop access to rule name field (#904)
- fix(rules): prevent lost rules with dataset updates (#892)
- fix(datasets): process owner as part of dataset id (#870)
- (UI) Rules summary metrics format (#888)
- UI: Improve code snippet for empty workspace (#886)
- fix(UI): Remove case sensitive when filtering labels (#882)
- Docs: Updates Flair zeroshot tutorial (#887)
- removing wrong video (#885)
- Update readme (#883)
- fix(UI) Metrics value by default if no metric (#875)
- feat(metrics): add token level metrics for token classification from client (#849)
- UI: New rule metrics layout (#861)
- chore: expose load_rules from base module (#866)
- Docs: Regenerates graphs metrics guide (#865)
- updating loss video (#864)
- Docs: Update weak supervision guide (#863)
- Update README.md (#862)
- Fix: Link loss tutorial (#859)
- Docs: Improve loss tutorial (#858)
- Docs: Improve AL and ws tutorials (#857)
- chore(ci): Include component testing configuration (#839)
- fix/loss video updated (#853)
- Docs: Weak supervision guide update (#855)
- chore(app): upgrade lint dependencies (#841)
- feat: weak supervision mode (#814)
- Docs: Review hf tutorial (#852)
- fix: error link to workspace home (#845)
- fix(metrics): compute token length for each token (#850)
- add streaming (#851)
- fix(rules): prevent division by 0 for overall metrics (#848)
- small change
- [Tutorials] Update media structure, remove TLDR heading (#847)
- Updating videos and images for sentiment classification tutorial (#846)
- fix(rules): prevent division by zero (#843)
- new folder and videos for model loss tutorial (#805)
- feat(token class): add metrics at token level (#838)
- new folder and images for active learning tutorial (#796)
- [Tutorials] Typo fix in find label errors tutorial (#842)
- [Tutorials] Add the new findlabelerrors tutorial (#833)
- [Rule] Modify the client API to the server's weak supervision feature (#840)
- [LabelModel] Improve Snorkel to not modify the passed in WeakLabels object (#836)
- feat (search): allow to filtering record metrics fields in search (#837)
- fix(ui): remove workspace home from code snippet api url (#834)
- ui: Hide validate button for binary cases in Text classifier (#830)
- fix print message (#829)
- feat: Include workspace in url path (#820)
- fix(ui): align records and global action layouts #825
- fix(ui): Show labels as selected after validate (#826)
- feat(labeling rule): implements api endpoint to fetch a single rule (#817)
- [LabelErrors] Add findlabelerrors method (#775)
- fix(ui): Fix styles in Safari (#815)
- docs: Add contributors to readme (#822)
- add missing rubrix import (#819)
- new folder and images for spacy tutorial (#794)
- feat(labeling rules): allow edition for rule label and description (#813)
- refactor(labeling rules): optional label for rule metrics (#811)
- Fix token alignment on CreationTokenClassificationRecord (#812)
- feat(server): add overall dataset labeling rules metrics (#807)
- feat(labeling rules): add coverage for annotated records (#806)
- fix(ui): Unique ID for scroll state to avoid same state for different dataset records (#809)
- new folder and images for zeroshot ner tutorial (#804)
- new folder and images for zeroshot data annotation tutorial (#803)
- fix(log): check multi-label integrity without search aggregations (#802)
- updated images, added folder for fastapi tutorial (#801)
- added folder for weak supervision tutorial (#795)
- feat(weak supervision): client labeling rules from server (#799)
- feat(server): labeling rule metrics (#790)
- fix/edit zero-shot tutorial (#774)
- fix/edited fastapi tutorial (#773)
- Fix/edit ner flair tutorial (#766)
- Fix/edit weaksupervision tutorial (#759)
- fix(ui): Little changes in fonts (#793)
- fix(ui): Allow open dataset in new tab from datasets list (#792)
- feat(server): rubrix namespaces for elasticsearch indices (#789)
- fix(ui): Show annotation after global validation (#786)
- remove reload arg launching server using python (#787)
- updated readme with
condainstall instruction (#788) - fix(ui): Hide scroller component when loading or paginate (#784)
- fix(ui): allow remove metadata filter from record metadata modal (#772)
- fix(ui): Token Classifier: validate record without annotation or prediction (#782)
- Fix/edit active learning tutorial (#760)
- Docs:minor changes to loss tutorial (#778)
- Fix/edit model loss tutorial (#767)
- fix(server): missing deprecated dep (#777)
- fix(ui): Global validate for records without annotation or prediction (#746)
- Fix/edit spacy tutorial (#758)
- Fix/edit labeling tutorial (#750)
- fix(server) - misaligned entity mentions on CreationTokenClassificationRecord (#771)
- [Requirements] Require python>=3.7 (#770)
- [Labeling] Add FlyingSquid label model (#755)
- Update README.md (#769)
- Adds Flair example to guide (#762)
- docs: Updates huggingface examples and adds monitor for Flair (#761)
- feat(search): show boolean values in metadata (#753)
- feat(server): allow handle labeling rules for datasets from API (#744)
- fix(imports): import monitoring with spacy<3.0 fails (#754)
- [UI] new fonts families (#751)
- fix(scroll): using new scroll component (#710)
- fix(ui): filter "validatable" records for global action validate button (#741)
- feat(monitor): flair ner auto-monitor (#738)
New Contributors
- @sugatoray made their first contribution
- @ruanchaves made their first contribution
- Python
Published by frascuchon over 4 years ago
argilla - v0.8.0-alpha.1
- Bugfixes/avoid infinite loop when dataset loading (#934)
- show nan instead of 0 for precision in summary (#930)
- fix(api): include_metrics param only for search endponts (#929)
- [Documentation] Update title page video for docs (#928)
- update skweak tutorial (#922)
- [Documentation] Updating the web app docu (#827)
- revert test.pypi publish
- publish python package to test.pypi for master and releases branches (#927)
- [WeakLabels] Align WeakLabels.summary() with web app (#925)
- UI: show rules without precision properly (#919)
- chore(build): build docker images for release branches (#921)
- Docs: Updates readme front video (#923)
- Docs: Updates weak supervision resources (#920)
- feat(rules): compute total & ann. coverage before label selection (#916)
- fix(rules): compute annotated coverage when no label properly (#915)
- Tutorial: Human-in-the-loop weak supervision with skweak (#869)
- UI: include affected #records to overall coverage/ann. coverage metrics (#914)
- fix lint build (#913)
- UI: manage precision and rules without annotation coverage (#909)
- fix(#876): process 400 response detail properly (#889)
- feat(rules): allow compute partial query rule metrics (#907)
- fix(security): providing default workspace should pass check (#911)
- UI: reset filters from define rules view (#908)
- UI: Show number of created rules in rules management view (#910)
- UI: drop access to rule name field (#904)
- fix(rules): prevent lost rules with dataset updates (#892)
- fix(datasets): process owner as part of dataset id (#870)
- (UI) Rules summary metrics format (#888)
- UI: Improve code snippet for empty workspace (#886)
- fix(UI): Remove case sensitive when filtering labels (#882)
- Docs: Updates Flair zeroshot tutorial (#887)
- removing wrong video (#885)
- Update readme (#883)
- fix(UI) Metrics value by default if no metric (#875)
- feat(metrics): add token level metrics for token classification from client (#849)
- UI: New rule metrics layout (#861)
- chore: expose load_rules from base module (#866)
- Docs: Regenerates graphs metrics guide (#865)
- updating loss video (#864)
- Docs: Update weak supervision guide (#863)
- Update README.md (#862)
- Fix: Link loss tutorial (#859)
- Docs: Improve loss tutorial (#858)
- Docs: Improve AL and ws tutorials (#857)
- chore(ci): Include component testing configuration (#839)
- fix/loss video updated (#853)
- Docs: Weak supervision guide update (#855)
- chore(app): upgrade lint dependencies (#841)
- feat: weak supervision mode (#814)
- Docs: Review hf tutorial (#852)
- fix: error link to workspace home (#845)
- fix(metrics): compute token length for each token (#850)
- chore: improve dockerignore files
- add streaming (#851)
- fix(rules): prevent division by 0 for overall metrics (#848)
- small change
- [Tutorials] Update media structure, remove TLDR heading (#847)
- Updating videos and images for sentiment classification tutorial (#846)
- fix(rules): prevent division by zero (#843)
- new folder and videos for model loss tutorial (#805)
- feat(token class): add metrics at token level (#838)
- new folder and images for active learning tutorial (#796)
- [Tutorials] Typo fix in find label errors tutorial (#842)
- [Tutorials] Add the new findlabelerrors tutorial (#833)
- [Rule] Modify the client API to the server's weak supervision feature (#840)
- [LabelModel] Improve Snorkel to not modify the passed in WeakLabels object (#836)
- feat (search): allow to filtering record metrics fields in search (#837)
- fix(ui): remove workspace home from code snippet api url (#834)
- ui: Hide validate button for binary cases in Text classifier (#830)
- fix print message (#829)
- feat: Include workspace in url path (#820)
- fix(ui): align records and global action layouts #825
- fix(ui): Show labels as selected after validate (#826)
- feat(labeling rule): implements api endpoint to fetch a single rule (#817)
- [LabelErrors] Add findlabelerrors method (#775)
- fix(ui): Fix styles in Safari (#815)
- docs: Add contributors to readme (#822)
- add missing rubrix import (#819)
- new folder and images for spacy tutorial (#794)
- feat(labeling rules): allow edition for rule label and description (#813)
- refactor(labeling rules): optional label for rule metrics (#811)
- Fix token alignment on CreationTokenClassificationRecord (#812)
- feat(server): add overall dataset labeling rules metrics (#807)
- feat(labeling rules): add coverage for annotated records (#806)
- fix(ui): Unique ID for scroll state to avoid same state for different dataset records (#809)
- new folder and images for zeroshot ner tutorial (#804)
- new folder and images for zeroshot data annotation tutorial (#803)
- fix(log): check multi-label integrity without search aggregations (#802)
- updated images, added folder for fastapi tutorial (#801)
- added folder for weak supervision tutorial (#795)
- feat(weak supervision): client labeling rules from server (#799)
- feat(server): labeling rule metrics (#790)
- fix/edit zero-shot tutorial (#774)
- fix/edited fastapi tutorial (#773)
- Fix/edit ner flair tutorial (#766)
- Fix/edit weaksupervision tutorial (#759)
- fix(ui): Little changes in fonts (#793)
- fix(ui): Allow open dataset in new tab from datasets list (#792)
- feat(server): rubrix namespaces for elasticsearch indices (#789)
- fix(ui): Show annotation after global validation (#786)
- remove reload arg launching server using python (#787)
- updated readme with
condainstall instruction (#788) - fix(ui): Hide scroller component when loading or paginate (#784)
- fix(ui): allow remove metadata filter from record metadata modal (#772)
- fix(ui): Token Classifier: validate record without annotation or prediction (#782)
- Fix/edit active learning tutorial (#760)
- Docs:minor changes to loss tutorial (#778)
- Fix/edit model loss tutorial (#767)
- fix(server): missing deprecated dep (#777)
- fix(ui): Global validate for records without annotation or prediction (#746)
- Fix/edit spacy tutorial (#758)
- Fix/edit labeling tutorial (#750)
- fix(server) - misaligned entity mentions on CreationTokenClassificationRecord (#771)
- [Requirements] Require python>=3.7 (#770)
- [Labeling] Add FlyingSquid label model (#755)
- Update README.md (#769)
- Adds Flair example to guide (#762)
- docs: Updates huggingface examples and adds monitor for Flair (#761)
- feat(search): show boolean values in metadata (#753)
- feat(server): allow handle labeling rules for datasets from API (#744)
- fix(imports): import monitoring with spacy<3.0 fails (#754)
- [UI] new fonts families (#751)
- fix(scroll): using new scroll component (#710)
- fix(ui): filter "validatable" records for global action validate button (#741)
- feat(monitor): flair ner auto-monitor (#738)
Full Changelog: https://github.com/recognai/rubrix/compare/v0.7.0...v0.8.0-alpha.0
- Python
Published by frascuchon over 4 years ago
argilla - v0.7.0: Rubrix Workspaces, Weak supervision, Text classification UX, Metrics
🔆 Highlights
Rubrix Workspaces
Rubrix Workspaces enable you to organize your data collection and monitoring workflows much more flexibly than before. Workspaces can be project-based (for separating the work across different projects), team-based (for organizing the work across teams), model-based (for organizing data collection and monitoring on a per-model or model group basis), or anything you can think about. A workspace is a Rubrix “space” where users can collaborate, both using the Webapp and the Python client. There are two types of workspace:
Team workspace: Where one or several users have read/write access.
User workspace: Every user gets its own user workspace. This workspace is the default workspace when users log in and log and load data with the Python client. The name of this workspace corresponds to the username.
Additionally, you can still use tags and metadata to structure datasets inside a workspace.
The setup should be pretty straight forward, you can find all details here: https://rubrix.readthedocs.io/en/stable/getting_started/user-management.html.
From the Python library side, to know how to log and load data from different workspaces, check the Python client API docs: https://rubrix.readthedocs.io/en/stable/reference/python/python_client.html

Weak Supervision
- Implementation of the first built-in Label Model (Snorkel): https://rubrix.readthedocs.io/en/stable/guides/weak-supervision.html#Built-in-label-models
- New tutorial using weak supervision for news classification: https://rubrix.readthedocs.io/en/stable/tutorials/weak-supervision-with-rubrix.html
- Example using Weasel for training a downstream classifier directly with weak labels using PyTorch and Hugging Face transformers: https://rubrix.readthedocs.io/en/stable/guides/weak-supervision.html#Joint-Model-with-Weasel
The API docs for the weak supervision model can be found here: https://rubrix.readthedocs.io/en/stable/reference/python/python_labeling.html#python-labeling
Improved UX for text classification annotation
Refined the annotation module for text classification, especially for text classification with a high number of labels

Rubrix Metrics
Increased the support for Rubrix Metrics, check this guide for more information: https://rubrix.readthedocs.io/en/stable/guides/metrics.html
- Support for queries to compute metrics for dataset slices
- Support for F1 in Token Classification
- Support for common metrics across tasks (string length)
- Support for Token classification predictions (model outputs) and annotations (training data)
💻 Upgrading
To use this new release, do not forget to run:
Update the client library:
bash
pip install -U rubrix
If you are using Docker:
bash
docker-compose pull
docker-compose up
If you are using the python server:
bash
pip install -U rubrix[server]
What's Changed
- Refactor: Move
RubrixClientout of init (#563) by David Fidalgo - Remove dynamic metadata, move it to
setup.cfg(#562) by David Fidalgo - fix tab titles of our docs (#561) by David Fidalgo
- [UI] Token classifier: Arrow styles are broken in Firefox (#576) by leiyre
- Fix:
rb.loadfor ids with mixed types (#577) by David Fidalgo - fix the build process (#583) by David Fidalgo
- fix: limit agent length (#585) by Francisco Aranda
- refactor(client): moves asgi module to rubrix.monitoring (#584) by Francisco Aranda
- fix(client): clear client cache after delete dataset (#580) by Francisco Aranda
- fixes(server): avoid mix single and multi label records for text-class (#582) by Francisco Aranda
- fix: assert tokens and text have content (#598) by Francisco Aranda
- tests: include basic tests for server.security module (#593) by Alex Jakubko
- [Docs] Make building the docs faster (#599) by David Fidalgo
- feat(client): compute metrics with query filter (#600) by Francisco Aranda
- refactor(server): normalizes token classification metrics (#602) by Francisco Aranda
- bugfixes(metrics): prevent index out of range for tokenclass metrics (#608) by Francisco Aranda
- feat(metrics): use stacked bar for entity consistency (#607) by Francisco Aranda
- fix(UI): Mention values in Stats sidebar sort when updating (#613) by leiyre
- Add tqdm to
rb.log(#609) by David Fidalgo - feat(metrics): include mention length metrics at char level (#615) by Francisco Aranda
- fix(monitoring): support old zeroshot versions (#614) by Francisco Aranda
- fix: enable nested fields in search dsl (#587) by Francisco Aranda
- hotfix: fix test for build ci by Francisco Aranda
- Typo fix in 05-active_learning.ipynb (#619) by Sebastian Raschka
- feat(metrics): annotated mentions metrics (#618) by Francisco Aranda
- [UI] Text classifier: annotation task interaction enhancement (#611) by leiyre
- docs: Introduce monitoring guide (#625) by Daniel Vila Suero
- docs: review monitoring guide (#626) by Daniel Vila Suero
- refactor: rename teams to workspaces (#622) by Francisco Aranda
- docs: update monitoring guide (#631) by Daniel Vila Suero
- fix(client): Adds verbose kwarg to rb.log (#632) by David Fidalgo
- [stats] Keywords in stats re-sort when query is updated (#639) by leiyre
- hotfix(server): wrong email user validation regex by Francisco Aranda
- Introduce LabelModel and Snorkel implementation (#624) by David Fidalgo
- refactor(UI): normalize multi-label dataset access (#635) by Francisco Aranda
- [QA] text classification labels (#636) by leiyre
- fix(metrix): empty metrics visualization (#642) by Francisco Aranda
- Add F1 metrics to token classification task (#640) by David Fidalgo
- fix(doc): prevent 'Mixed Content:...' error (#645) by Francisco Aranda
- NoRecordsFoundError when rb.load results in empty list in WeakLabels (#641) by David Fidalgo
- [UI styles] QA annotation buttons styles (#654) by leiyre
- refactor(metrics): module shortcut for compute_for and enum def (#651) by Francisco Aranda
- hotfix(user): empty workspaces list checks to default workspace by Francisco Aranda
- format doc strings according to the google style + small improvements (#656) by David Fidalgo
- fix(search): prevent ignore 0s for aggregation result keys (#655) by Francisco Aranda
- feat(server): accepts workspace as http header (#659) by Francisco Aranda
- refactor(user): bypass ws for super users (#660) by Francisco Aranda
- feat(server): common task metrics (#657) by Francisco Aranda
- feat(client): user workspace management from client (#661) by Francisco Aranda
- feat(UI): select user workspace (#662) by Francisco Aranda
- UI: Add hover effect on selected label in Text Classification (#663) by leiyre
- UI: Button-icon active state improvement (#664) by leiyre
- [BUG] Annotation agent is user.username (#666) by leiyre
- by default do not pass on Y_dev when fitting (#670) by David Fidalgo
- Docs: Adds weak supervision tutorial (#672) by Daniel Vila Suero
- [Client] Add metrics parameter to all client models (#671) by David Fidalgo
- [UI] QA: button active state color duration (#675) by leiyre
- [bug] Sticky top-bar glitch when scrolling (#674) by leiyre
- fix(docs): .rubrix_* -> .rubrix* (#680) by Francisco Aranda
- fix(server): metadata keys with empty meta will be omitted (#678) by Francisco Aranda
- docs: fix small typo in ws tuto (#684) by Daniel Vila Suero
- feat(client): dataset copy with workspace param (#683) by Francisco Aranda
- [UI] Limit pagination in UI (#668) by leiyre
- fix(server): single label annotation validator (#687) by Francisco Aranda
- fix(app): read all dataset labels for annotation (#688) by Francisco Aranda
- [UI] Message for empty home (datasets list) (#691) by leiyre
- [UI] Fix: Text classifier explore record width (#696) by leiyre
- [Labeling] Throw error when encountering duplicated rule names (#693) by David Fidalgo
- [UI] Fix: Text Classification annotation record width (#699) by leiyre
- [Metrics] Normalize F1 metrics for Text-/TokenClassification (#694) by David Fidalgo
- fix link for models (#703) by Leire Rosado
- [Docs] First attempt to devise a testing workflow for the tutorials (#649) by David Fidalgo
- docs: Updates metrics guide (#647) by Daniel Vila Suero
- [UI] "Validate" button align left in Text classification and Token classification (#707) by leiyre
- feat(metrics): improve common dataset metrics #709 by Francisco Aranda
- [Docs] Add WeaSEL example to weak supervision guide (#578) by David Fidalgo
- [UI] Workspaces QA (#697) by leiyre
- small typo/grammar fixes for the weak supervision guide by dcfidalgo
- Fix/loss tutorial (#714) by Leire Rosado
- Fix/spacy_transformers (#711) by Leire Rosado
- fix(ui): refresh dataset before initalize it (#721) by Francisco Aranda
- [UI] Fix: Refresh button mantains pagination configuration (#715) by leiyre
- remove kglab tutorial (#720) by David Fidalgo
- fix(ui): refresh aggregations to paginated dataset (#722) by Francisco Aranda
- fix(ui): preserving the annotate/explore state on browser refresh (#724) by Francisco Aranda
- docs: Adds User and Workspaces management guide (#726) by Daniel Vila Suero
New Contributors
- @rasbt made their first contribution in https://github.com/recognai/rubrix/pull/619
- @leireropl made their first contribution in https://github.com/recognai/rubrix/pull/703
Full Changelog: https://github.com/recognai/rubrix/compare/v0.6.2...v0.7.0
- Python
Published by frascuchon over 4 years ago
argilla - v0.7.0-alpha.1
What's Changed
- Refactor: Move
RubrixClientout of init (#563) by David Fidalgo - Remove dynamic metadata, move it to
setup.cfg(#562) by David Fidalgo - fix tab titles of our docs (#561) by David Fidalgo
- [UI] Token classifier: Arrow styles are broken in Firefox (#576) by leiyre
- Fix:
rb.loadfor ids with mixed types (#577) by David Fidalgo - fix the build process (#583) by David Fidalgo
- fix: limit agent length (#585) by Francisco Aranda
- refactor(client): moves asgi module to rubrix.monitoring (#584) by Francisco Aranda
- fix(client): clear client cache after delete dataset (#580) by Francisco Aranda
- fixes(server): avoid mix single and multi label records for text-class (#582) by Francisco Aranda
- fix: assert tokens and text have content (#598) by Francisco Aranda
- tests: include basic tests for server.security module (#593) by Alex Jakubko
- [Docs] Make building the docs faster (#599) by David Fidalgo
- feat(client): compute metrics with query filter (#600) by Francisco Aranda
- refactor(server): normalizes token classification metrics (#602) by Francisco Aranda
- bugfixes(metrics): prevent index out of range for tokenclass metrics (#608) by Francisco Aranda
- feat(metrics): use stacked bar for entity consistency (#607) by Francisco Aranda
- fix(UI): Mention values in Stats sidebar sort when updating (#613) by leiyre
- Add tqdm to
rb.log(#609) by David Fidalgo - feat(metrics): include mention length metrics at char level (#615) by Francisco Aranda
- fix(monitoring): support old zeroshot versions (#614) by Francisco Aranda
- fix: enable nested fields in search dsl (#587) by Francisco Aranda
- hotfix: fix test for build ci by Francisco Aranda
- Typo fix in 05-active_learning.ipynb (#619) by Sebastian Raschka
- feat(metrics): annotated mentions metrics (#618) by Francisco Aranda
- [UI] Text classifier: annotation task interaction enhancement (#611) by leiyre
- docs: Introduce monitoring guide (#625) by Daniel Vila Suero
- docs: review monitoring guide (#626) by Daniel Vila Suero
- refactor: rename teams to workspaces (#622) by Francisco Aranda
- docs: update monitoring guide (#631) by Daniel Vila Suero
- fix(client): Adds verbose kwarg to rb.log (#632) by David Fidalgo
- [stats] Keywords in stats re-sort when query is updated (#639) by leiyre
- hotfix(server): wrong email user validation regex by Francisco Aranda
- Introduce LabelModel and Snorkel implementation (#624) by David Fidalgo
- refactor(UI): normalize multi-label dataset access (#635) by Francisco Aranda
- [QA] text classification labels (#636) by leiyre
- fix(metrix): empty metrics visualization (#642) by Francisco Aranda
- Add F1 metrics to token classification task (#640) by David Fidalgo
- fix(doc): prevent 'Mixed Content:...' error (#645) by Francisco Aranda
- NoRecordsFoundError when rb.load results in empty list in WeakLabels (#641) by David Fidalgo
- [UI styles] QA annotation buttons styles (#654) by leiyre
- refactor(metrics): module shortcut for compute_for and enum def (#651) by Francisco Aranda
- hotfix(user): empty workspaces list checks to default workspace by Francisco Aranda
- format doc strings according to the google style + small improvements (#656) by David Fidalgo
- fix(search): prevent ignore 0s for aggregation result keys (#655) by Francisco Aranda
- feat(server): accepts workspace as http header (#659) by Francisco Aranda
- refactor(user): bypass ws for super users (#660) by Francisco Aranda
- feat(server): common task metrics (#657) by Francisco Aranda
- feat(client): user workspace management from client (#661) by Francisco Aranda
- feat(UI): select user workspace (#662) by Francisco Aranda
- UI: Add hover effect on selected label in Text Classification (#663) by leiyre
- UI: Button-icon active state improvement (#664) by leiyre
- [BUG] Annotation agent is user.username (#666) by leiyre
- by default do not pass on Y_dev when fitting (#670) by David Fidalgo
- Docs: Adds weak supervision tutorial (#672) by Daniel Vila Suero
- [Client] Add metrics parameter to all client models (#671) by David Fidalgo
- [UI] QA: button active state color duration (#675) by leiyre
- [bug] Sticky top-bar glitch when scrolling (#674) by leiyre
- fix(docs): .rubrix_* -> .rubrix* (#680) by Francisco Aranda
- fix(server): metadata keys with empty meta will be omitted (#678) by Francisco Aranda
- docs: fix small typo in ws tuto (#684) by Daniel Vila Suero
- feat(client): dataset copy with workspace param (#683) by Francisco Aranda
- [UI] Limit pagination in UI (#668) by leiyre
- fix(server): single label annotation validator (#687) by Francisco Aranda
- fix(app): read all dataset labels for annotation (#688) by Francisco Aranda
- [UI] Message for empty home (datasets list) (#691) by leiyre
- [UI] Fix: Text classifier explore record width (#696) by leiyre
- [Labeling] Throw error when encountering duplicated rule names (#693) by David Fidalgo
- [UI] Fix: Text Classification annotation record width (#699) by leiyre
- [Metrics] Normalize F1 metrics for Text-/TokenClassification (#694) by David Fidalgo
- fix link for models (#703) by Leire Rosado
- [Docs] First attempt to devise a testing workflow for the tutorials (#649) by David Fidalgo
- docs: Updates metrics guide (#647) by Daniel Vila Suero
- [UI] "Validate" button align left in Text classification and Token classification (#707) by leiyre
- feat(metrics): improve common dataset metrics #709 by Francisco Aranda
- [Docs] Add WeaSEL example to weak supervision guide (#578) by David Fidalgo
- [UI] Workspaces QA (#697) by leiyre
- small typo/grammar fixes for the weak supervision guide by dcfidalgo
- Fix/loss tutorial (#714) by Leire Rosado
- Fix/spacy_transformers (#711) by Leire Rosado
- fix(ui): refresh dataset before initalize it (#721) by Francisco Aranda
- [UI] Fix: Refresh button mantains pagination configuration (#715) by leiyre
- remove kglab tutorial (#720) by David Fidalgo
- fix(ui): refresh aggregations to paginated dataset (#722) by Francisco Aranda
- fix(ui): preserving the annotate/explore state on browser refresh (#724) by Francisco Aranda
- docs: Adds User and Workspaces management guide (#726) by Daniel Vila Suero
New Contributors
- @rasbt made their first contribution in https://github.com/recognai/rubrix/pull/619
- @leireropl made their first contribution in https://github.com/recognai/rubrix/pull/703
Full Changelog: https://github.com/recognai/rubrix/compare/v0.6.2...v0.7.0-alpha.1
- Python
Published by frascuchon over 4 years ago
argilla - v0.7.0-alpha.0
What's Changed
- Refactor: Move
RubrixClientout of init (#563) by David Fidalgo - Remove dynamic metadata, move it to
setup.cfg(#562) by David Fidalgo - fix tab titles of our docs (#561) by David Fidalgo
- [UI] Token classifier: Arrow styles are broken in Firefox (#576) by leiyre
- Fix:
rb.loadfor ids with mixed types (#577) by David Fidalgo - fix the build process (#583) by David Fidalgo
- fix: limit agent length (#585) by Francisco Aranda
- refactor(client): moves asgi module to rubrix.monitoring (#584) by Francisco Aranda
- fix(client): clear client cache after delete dataset (#580) by Francisco Aranda
- fixes(server): avoid mix single and multi label records for text-class (#582) by Francisco Aranda
- fix: assert tokens and text have content (#598) by Francisco Aranda
- tests: include basic tests for server.security module (#593) by Alex Jakubko
- [Docs] Make building the docs faster (#599) by David Fidalgo
- feat(client): compute metrics with query filter (#600) by Francisco Aranda
- refactor(server): normalizes token classification metrics (#602) by Francisco Aranda
- bugfixes(metrics): prevent index out of range for tokenclass metrics (#608) by Francisco Aranda
- feat(metrics): use stacked bar for entity consistency (#607) by Francisco Aranda
- fix(UI): Mention values in Stats sidebar sort when updating (#613) by leiyre
- Add tqdm to
rb.log(#609) by David Fidalgo - feat(metrics): include mention length metrics at char level (#615) by Francisco Aranda
- fix(monitoring): support old zeroshot versions (#614) by Francisco Aranda
- fix: enable nested fields in search dsl (#587) by Francisco Aranda
- hotfix: fix test for build ci by Francisco Aranda
- Typo fix in 05-active_learning.ipynb (#619) by Sebastian Raschka
- feat(metrics): annotated mentions metrics (#618) by Francisco Aranda
- [UI] Text classifier: annotation task interaction enhancement (#611) by leiyre
- docs: Introduce monitoring guide (#625) by Daniel Vila Suero
- docs: review monitoring guide (#626) by Daniel Vila Suero
- refactor: rename teams to workspaces (#622) by Francisco Aranda
- docs: update monitoring guide (#631) by Daniel Vila Suero
- fix(client): Adds verbose kwarg to rb.log (#632) by David Fidalgo
- [stats] Keywords in stats re-sort when query is updated (#639) by leiyre
- hotfix(server): wrong email user validation regex by Francisco Aranda
- Introduce LabelModel and Snorkel implementation (#624) by David Fidalgo
- refactor(UI): normalize multi-label dataset access (#635) by Francisco Aranda
- [QA] text classification labels (#636) by leiyre
- fix(metrix): empty metrics visualization (#642) by Francisco Aranda
- Add F1 metrics to token classification task (#640) by David Fidalgo
- fix(doc): prevent 'Mixed Content:...' error (#645) by Francisco Aranda
- NoRecordsFoundError when rb.load results in empty list in WeakLabels (#641) by David Fidalgo
- [UI styles] QA annotation buttons styles (#654) by leiyre
- refactor(metrics): module shortcut for compute_for and enum def (#651) by Francisco Aranda
- hotfix(user): empty workspaces list checks to default workspace by Francisco Aranda
- format doc strings according to the google style + small improvements (#656) by David Fidalgo
- fix(search): prevent ignore 0s for aggregation result keys (#655) by Francisco Aranda
- feat(server): accepts workspace as http header (#659) by Francisco Aranda
- refactor(user): bypass ws for super users (#660) by Francisco Aranda
- feat(server): common task metrics (#657) by Francisco Aranda
- feat(client): user workspace management from client (#661) by Francisco Aranda
- feat(UI): select user workspace (#662) by Francisco Aranda
- UI: Add hover effect on selected label in Text Classification (#663) by leiyre
- UI: Button-icon active state improvement (#664) by leiyre
- [BUG] Annotation agent is user.username (#666) by leiyre
- by default do not pass on Y_dev when fitting (#670) by David Fidalgo
- Docs: Adds weak supervision tutorial (#672) by Daniel Vila Suero
- [Client] Add metrics parameter to all client models (#671) by David Fidalgo
- [UI] QA: button active state color duration (#675) by leiyre
- [bug] Sticky top-bar glitch when scrolling (#674) by leiyre
- fix(docs): .rubrix_* -> .rubrix* (#680) by Francisco Aranda
- fix(server): metadata keys with empty meta will be omitted (#678) by Francisco Aranda
- docs: fix small typo in ws tuto (#684) by Daniel Vila Suero
- feat(client): dataset copy with workspace param (#683) by Francisco Aranda
- [UI] Limit pagination in UI (#668) by leiyre
- fix(server): single label annotation validator (#687) by Francisco Aranda
- fix(app): read all dataset labels for annotation (#688) by Francisco Aranda
- [UI] Message for empty home (datasets list) (#691) by leiyre
- [UI] Fix: Text classifier explore record width (#696) by leiyre
- [Labeling] Throw error when encountering duplicated rule names (#693) by David Fidalgo
- [UI] Fix: Text Classification annotation record width (#699) by leiyre
- [Metrics] Normalize F1 metrics for Text-/TokenClassification (#694) by David Fidalgo
- fix link for models (#703) by Leire Rosado
- [Docs] First attempt to devise a testing workflow for the tutorials (#649) by David Fidalgo
- docs: Updates metrics guide (#647) by Daniel Vila Suero
- [UI] "Validate" button align left in Text classification and Token classification (#707) by leiyre
- feat(metrics): improve common dataset metrics #709 by Francisco Aranda
- [Docs] Add WeaSEL example to weak supervision guide (#578) by David Fidalgo
- [UI] Workspaces QA (#697) by leiyre
- small typo/grammar fixes for the weak supervision guide by dcfidalgo
- Fix/loss tutorial (#714) by Leire Rosado
- Fix/spacy_transformers (#711) by Leire Rosado
- fix(ui): refresh dataset before initalize it (#721) by Francisco Aranda
- [UI] Fix: Refresh button mantains pagination configuration (#715) by leiyre
- remove kglab tutorial (#720) by David Fidalgo
- fix(ui): refresh aggregations to paginated dataset (#722) by Francisco Aranda
- fix(ui): preserving the annotate/explore state on browser refresh (#724) by Francisco Aranda
- docs: Adds User and Workspaces management guide (#726) by Daniel Vila Suero
New Contributors
- @rasbt made their first contribution in https://github.com/recognai/rubrix/pull/619
- @leireropl made their first contribution in https://github.com/recognai/rubrix/pull/703
Full Changelog: https://github.com/recognai/rubrix/compare/v0.6.2...v0.7.0-alpha.0
- Python
Published by frascuchon over 4 years ago
argilla - v0.6.2
What's Changed
- fix(server): metadata keys with empty meta will be omitted by @frascuchon in https://github.com/recognai/rubrix/pull/678
- fix(docs): .rubrix_* -> .rubrix* by @frascuchon in https://github.com/recognai/rubrix/pull/680
- fix(server): single label annotation validator by @frascuchon in https://github.com/recognai/rubrix/pull/687
Full Changelog: https://github.com/recognai/rubrix/compare/v0.6.1...v0.6.2
- Python
Published by frascuchon over 4 years ago
argilla - v0.6.2-alpha.0
What's Changed
- fix(server): metadata keys with empty meta will be omitted by @frascuchon in https://github.com/recognai/rubrix/pull/678
- fix(docs): .rubrix_* -> .rubrix* by @frascuchon in https://github.com/recognai/rubrix/pull/680
- fix(server): single label annotation validator by @frascuchon in https://github.com/recognai/rubrix/pull/687
Full Changelog: https://github.com/recognai/rubrix/compare/v0.6.1...v0.6.2-alpha.0
- Python
Published by frascuchon over 4 years ago
argilla - v0.6.1
What's Changed
- [UI] Token classifier: Arrow styles are broken in Firefox (#576)
- Fix: rb.load for ids with mixed types (#577)
- fix: limit agent length (#585)
- fix(client): clear client cache after delete dataset (#580)
- fixes(server): avoid mix single and multi label records for text-class
- fix: assert tokens and text have content (#598)
- bugfixes(metrics): prevent index out of range for tokenclass metrics
- fix(UI): Mention values in Stats sidebar sort when updating (#613)
- fix: enable nested fields in search dsl (#587)
- [stats] Keywords in stats re-sort when query is updated (#639)
- fix(metrix): empty metrics visualization (#642)
- fix(search): prevent ignore 0s for aggregation result keys (#655)
Full Changelog: https://github.com/recognai/rubrix/compare/v0.6.0...v0.6.1-alpha.0
- Python
Published by frascuchon over 4 years ago
argilla - v0.6.1-alpha.0
What's Changed
- [UI] Token classifier: Arrow styles are broken in Firefox (#576)
- Fix: rb.load for ids with mixed types (#577)
- fix: limit agent length (#585)
- fix(client): clear client cache after delete dataset (#580)
- fixes(server): avoid mix single and multi label records for text-class (
- fix: assert tokens and text have content (#598)
- bugfixes(metrics): prevent index out of range for tokenclass metrics (#…
- fix(UI): Mention values in Stats sidebar sort when updating (#613)
- fix: enable nested fields in search dsl (#587)
- [stats] Keywords in stats re-sort when query is updated (#639)
- fix(metrix): empty metrics visualization (#642)
- fix(search): prevent ignore 0s for aggregation result keys (#655)
Full Changelog: https://github.com/recognai/rubrix/compare/v0.6.0...v0.6.1-alpha.0
- Python
Published by frascuchon over 4 years ago
argilla - v.0.6.0: Text2Text, better UX/UI, Weak supervision and Metrics
🔆 Highlights
Improved UX/UI for Text2Text tasks
Largely improved user experience and UI for text2text tasks.
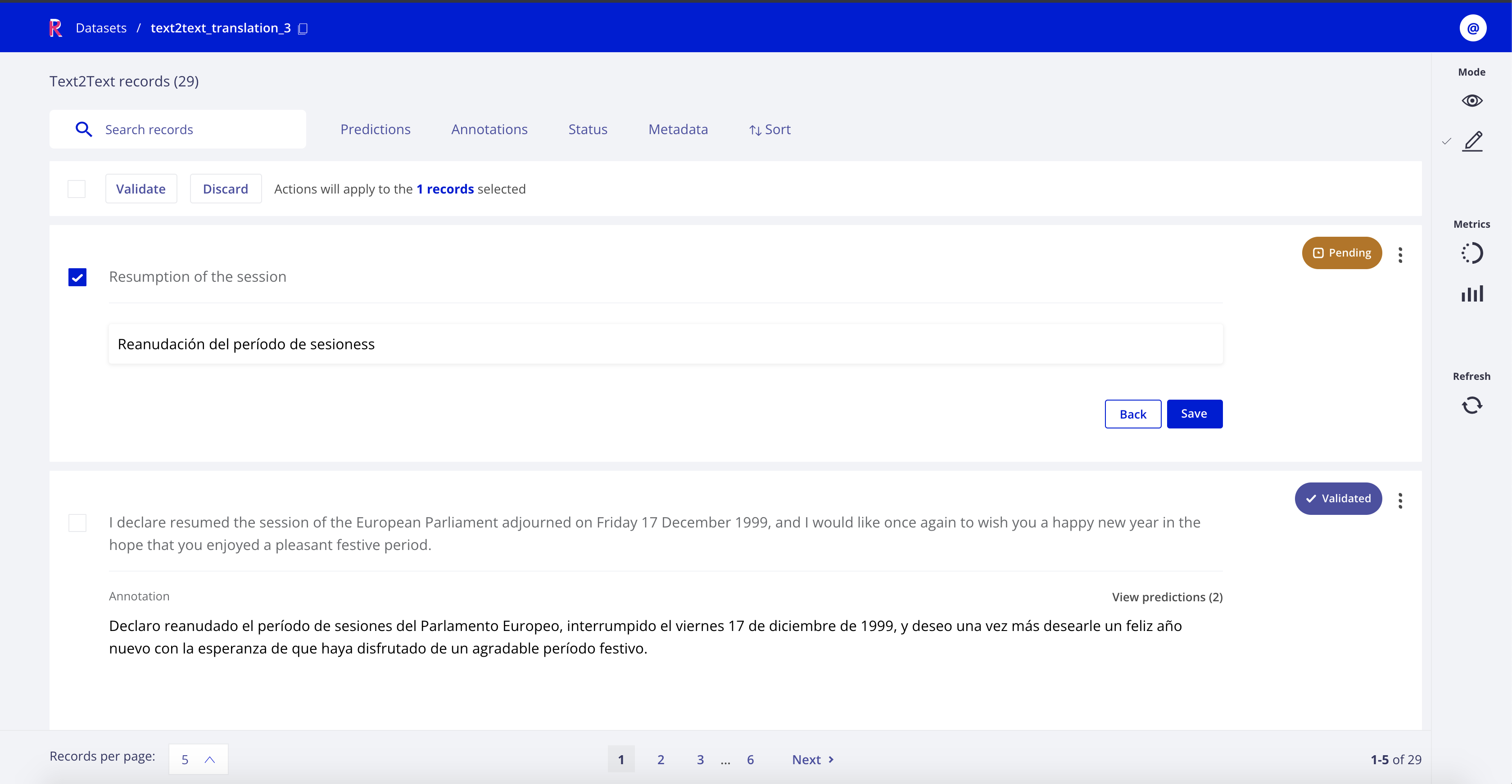
Weak Supervision [Experimental]
Added initial support for leveraging weak supervision for text classification, check this guide to get started: https://rubrix.readthedocs.io/en/stable/guides/weak-supervision.html
Metrics [Experimental]
Introduced Rubrix Metrics, a new feature for fine-grained analysis of token classification models, inspired by recent works on fine-grained model and dataset evaluation like Explainaboard.
Guide: https://rubrix.readthedocs.io/en/stable/guides/metrics.html API reference: https://rubrix.readthedocs.io/en/stable/reference/python/python_metrics.html
What's Changed
- feat(UI): new text2text UI by @leiyre in https://github.com/recognai/rubrix/pull/378
- svg generate-icons template by @leiyre in https://github.com/recognai/rubrix/pull/379
- fix(ui): apply text2text review suggestions by @leiyre in https://github.com/recognai/rubrix/pull/380
- refactor(UI): show filters options under each filter by @leiyre in https://github.com/recognai/rubrix/pull/381
- fix(ui): show metadata filters by @frascuchon in https://github.com/recognai/rubrix/pull/382
- fix(UI): better Text2Text edition behaviour by @leiyre in https://github.com/recognai/rubrix/pull/383
- feat(UI): format quantities locale dependant by @leiyre in https://github.com/recognai/rubrix/pull/384
- chore(UI): change sort arrows styles and search icon position by @leiyre in https://github.com/recognai/rubrix/pull/387
- Bugfix: Convert None to "None" for prediction/annotation agents by @dcfidalgo in https://github.com/recognai/rubrix/pull/386
- Restructure README by @dvsrepo in https://github.com/recognai/rubrix/pull/389
- Feat: score per entity by @dcfidalgo in https://github.com/recognai/rubrix/pull/385
- refactor(UI): Better Text2Text annotation experience (EXPERIMENTAL) by @leiyre in https://github.com/recognai/rubrix/pull/393
- fix(UI): highlight predicted label using predicted_as info by @leiyre in https://github.com/recognai/rubrix/pull/390
- refactor(UI): revise styles for Text2Text task by @leiyre in https://github.com/recognai/rubrix/pull/396
- refactor(UI): Text2Text task ui revision by @leiyre in https://github.com/recognai/rubrix/pull/400
- fix(UI): apply local format to percentage by @leiyre in https://github.com/recognai/rubrix/pull/397
- fix(UI): Text2Text - prevent edition in exploration mode by @leiyre in https://github.com/recognai/rubrix/pull/406
- refactor(UI): set pagination as fixed footer by @leiyre in https://github.com/recognai/rubrix/pull/405
- feat(UI): new search sticky bar design by @leiyre in https://github.com/recognai/rubrix/pull/417
- fix(server): delete dataset with refresh flag enabled by @frascuchon in https://github.com/recognai/rubrix/pull/418
- feat(server): detect nested metadata fields by @frascuchon in https://github.com/recognai/rubrix/pull/409
- [Docs] Remove first tutorial by @dcfidalgo in https://github.com/recognai/rubrix/pull/425
- Add pre-commit hooks by @krishnajalan in https://github.com/recognai/rubrix/pull/426
- feat(server): configure dataset metrics by @frascuchon in https://github.com/recognai/rubrix/pull/412
- fix(UI): allow records with empty annotations for text classification by @leiyre in https://github.com/recognai/rubrix/pull/430
- fix(server): Limit search pagination to 10000 by @krishnajalan in https://github.com/recognai/rubrix/pull/435
- feat(UI): keep global state in filters by @frascuchon in https://github.com/recognai/rubrix/pull/441
- [UI] experimental tag for Text2Text by @leiyre in https://github.com/recognai/rubrix/pull/440
- Introduce custom SDK by @dcfidalgo in https://github.com/recognai/rubrix/pull/413
- docs: improve zeroshot ner tutorial by @dvsrepo in https://github.com/recognai/rubrix/pull/445
- docs: fix rubrix setup section by @dvsrepo in https://github.com/recognai/rubrix/pull/447
- docs: Readme review by @dvsrepo in https://github.com/recognai/rubrix/pull/448
- docs: Enhance tutorial fine-tuning by @dvsrepo in https://github.com/recognai/rubrix/pull/449
- Fix the doctest format in the examples by @dcfidalgo in https://github.com/recognai/rubrix/pull/450
- feat(UI): filters area improvement by @leiyre in https://github.com/recognai/rubrix/pull/433
- Adding usage examples to docstrings in record models by @issam9 in https://github.com/recognai/rubrix/pull/446
- fix(server): disable metrics calculation for search by @frascuchon in https://github.com/recognai/rubrix/pull/460
- Implement TokenClassification part of the custom SDK by @dcfidalgo in https://github.com/recognai/rubrix/pull/452
- fix(server): conditional metric results generation by @frascuchon in https://github.com/recognai/rubrix/pull/463
- fix(UI): annotation animation for Text Classification by @leiyre in https://github.com/recognai/rubrix/pull/438
- fix(UI): Text2Text Review by @leiyre in https://github.com/recognai/rubrix/pull/456
- fix(UI): restore vuex action for Global Actions by @leiyre in https://github.com/recognai/rubrix/pull/458
- fix(UI): new filters area QA by @leiyre in https://github.com/recognai/rubrix/pull/462
- fix(UI): allow entity annotation for NER by @frascuchon in https://github.com/recognai/rubrix/pull/464
- fix(UI): validate the model prediction when no annotation by @leiyre in https://github.com/recognai/rubrix/pull/465
- Add docs on how to training/inference with flair text/token-classification model by @sakares in https://github.com/recognai/rubrix/pull/442
- Allow disabling ES index template creation by environment var by @torkashvand in https://github.com/recognai/rubrix/pull/469
- feat(server): generate automatic task dataset metrics endpoints by @frascuchon in https://github.com/recognai/rubrix/pull/468
- chore(CI): codecov config only for CI builds by @frascuchon in https://github.com/recognai/rubrix/pull/472
- refactor(client): remove old sdk files by @frascuchon in https://github.com/recognai/rubrix/pull/470
- [Docs] small tutorial improvements by @dcfidalgo in https://github.com/recognai/rubrix/pull/476
- feat(server): allows filtering by user team in API by @frascuchon in https://github.com/recognai/rubrix/pull/392
- Fix hyperlink to Stanzs by @Danielto1404 in https://github.com/recognai/rubrix/pull/480
- Fix: Enable to create new label in the Text Classification task by @leiyre in https://github.com/recognai/rubrix/pull/481
- [UI] Records cards standardization by @leiyre in https://github.com/recognai/rubrix/pull/483
- Docs: Add selectra tutorial by @dvsrepo in https://github.com/recognai/rubrix/pull/485
- fix(UI): update loca record status before send backend request by @frascuchon in https://github.com/recognai/rubrix/pull/487
- Review zero-shot tutorial by @dvsrepo in https://github.com/recognai/rubrix/pull/488
- refactor(server):simplify datasets integrations by @frascuchon in https://github.com/recognai/rubrix/pull/489
- refactor(UI): new right sidebar by @leiyre in https://github.com/recognai/rubrix/pull/490
- fix(server): parameterize task for dataset operations by @frascuchon in https://github.com/recognai/rubrix/pull/493
- fix(server): prevent index template recreation for records index by @frascuchon in https://github.com/recognai/rubrix/pull/497
- fix:(UI): Implement feedback for new sidebar by @leiyre in https://github.com/recognai/rubrix/pull/498
- feat(server): per-tast predefined metrics by @frascuchon in https://github.com/recognai/rubrix/pull/491
- fix(server): better default params for token classification metrics by @frascuchon in https://github.com/recognai/rubrix/pull/500
- Change dictionary key in RubrixLogHTTPMiddleware from probabilities into scores by @iakhil in https://github.com/recognai/rubrix/pull/501
- feat(UI): new search box behaviour by @leiyre in https://github.com/recognai/rubrix/pull/505
- feat(UI): allow copy to clipboard dataset names by @leiyre in https://github.com/recognai/rubrix/pull/504
- fix(UI): annotate from global actions for text classification should overrides labels by @leiyre in https://github.com/recognai/rubrix/pull/507
- Feat: Enhance
rubrix.loadby @dcfidalgo in https://github.com/recognai/rubrix/pull/513 - chore(UI): review styles for modals by @leiyre in https://github.com/recognai/rubrix/pull/514
- feat(UI): record cards standardization by @leiyre in https://github.com/recognai/rubrix/pull/508
- refactor: sentence length -> tokens length metric by @frascuchon in https://github.com/recognai/rubrix/pull/515
- [UI] Fix: Remove annotatedas or predictedas filters in Text2Text by @leiyre in https://github.com/recognai/rubrix/pull/517
- fix(UI): enable shortcut pagination only for global body focus by @leiyre in https://github.com/recognai/rubrix/pull/518
- fix(ci): 'Pagination' is defined but never used by @leiyre in https://github.com/recognai/rubrix/pull/522
- fix(UI): tooltip styles & replace copy-url icon by @leiyre in https://github.com/recognai/rubrix/pull/520
- fix(UI): review styles for records cards by @leiyre in https://github.com/recognai/rubrix/pull/519
- feat(client): support auto-monitor for spaCy and text-class transformers by @frascuchon in https://github.com/recognai/rubrix/pull/506
- feat(UI): reset record status for single text classification by @frascuchon in https://github.com/recognai/rubrix/pull/527
- feat(client): using task metrics by @frascuchon in https://github.com/recognai/rubrix/pull/516
- Fix: Client to SDK, token classification model by @dcfidalgo in https://github.com/recognai/rubrix/pull/524
- refactor: remove query_inputs alias for text-classification by @frascuchon in https://github.com/recognai/rubrix/pull/528
- fix(server): validated records for single text-class must include annotations by @frascuchon in https://github.com/recognai/rubrix/pull/530
- [UI] Cards Standardization QA 3 by @leiyre in https://github.com/recognai/rubrix/pull/536
- fix(UI): Text2Text remove Validate button in edit mode by @leiyre in https://github.com/recognai/rubrix/pull/539
- fix(server): include record timestamp to monitors by @frascuchon in https://github.com/recognai/rubrix/pull/535
- feat(UI): better API error messages handling by @frascuchon in https://github.com/recognai/rubrix/pull/531
- feat(server): remove partial update by @frascuchon in https://github.com/recognai/rubrix/pull/533
- Added Automatic Logging using middleware notebook (recognai#427) by @Aymane11 in https://github.com/recognai/rubrix/pull/532
- feat(UI): remove annotation info completely by @frascuchon in https://github.com/recognai/rubrix/pull/540
- fix(UI): review styles for global record cards by @leiyre in https://github.com/recognai/rubrix/pull/541
- Feat: weak supervision by @dcfidalgo in https://github.com/recognai/rubrix/pull/503
- feat(UI): disable "Validate" with records without prediction & annotation by @leiyre in https://github.com/recognai/rubrix/pull/543
- feat: review client metrics by @frascuchon in https://github.com/recognai/rubrix/pull/544
- feat(client): add zero-shot classifier monitor by @frascuchon in https://github.com/recognai/rubrix/pull/538
- fix(UI): show annotation by default in annotation view for Text2Text by @leiyre in https://github.com/recognai/rubrix/pull/547
- feat(UI): hide "Validate" for records without prediction and annotation by @leiyre in https://github.com/recognai/rubrix/pull/550
- [UI] Fix: set record height in Text Classifier explore view by @leiyre in https://github.com/recognai/rubrix/pull/555
- fix(client): monitor coroutine definition by @frascuchon in https://github.com/recognai/rubrix/pull/558
- docs: review http monitoring tutorial by @dvsrepo in https://github.com/recognai/rubrix/pull/560
- docs(metrics): add missing dependencies info by @frascuchon in https://github.com/recognai/rubrix/pull/559
🥳 New Contributors
- @krishnajalan made their first contribution in https://github.com/recognai/rubrix/pull/426
- @issam9 made their first contribution in https://github.com/recognai/rubrix/pull/446
- @sakares made their first contribution in https://github.com/recognai/rubrix/pull/442
- @torkashvand made their first contribution in https://github.com/recognai/rubrix/pull/469
- @Danielto1404 made their first contribution in https://github.com/recognai/rubrix/pull/480
- @iakhil made their first contribution in https://github.com/recognai/rubrix/pull/501
- @Aymane11 made their first contribution in https://github.com/recognai/rubrix/pull/532
Full Changelog: https://github.com/recognai/rubrix/compare/v0.5.0...v0.6.0
- Python
Published by frascuchon over 4 years ago