semantic-outlier-removal
Code and data for SORE (ACL 2025), a semantic boilerplate remover.
Science Score: 54.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (12.3%) to scientific vocabulary
Keywords
Repository
Code and data for SORE (ACL 2025), a semantic boilerplate remover.
Basic Info
- Host: GitHub
- Owner: meakbiyik
- License: mit
- Default Branch: main
- Homepage: https://meakbiyik.com/sore
- Size: 12.7 KB
Statistics
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
- Releases: 0
Topics
Metadata Files
README.md
SORE: Semantic Outlier Removal with Embedding Models and LLMs
This repository will host the code and evaluation datasets for our paper "Semantic Outlier Removal with Embedding Models and LLMs", accepted at ACL 2025. It includes the implementation of our novel content extraction method, SORE, and the SORE-SMALL and SORE-LARGE datasets used for evaluation.
Please note: The code and datasets are not yet available in this repository but will be uploaded shortly to facilitate further research.
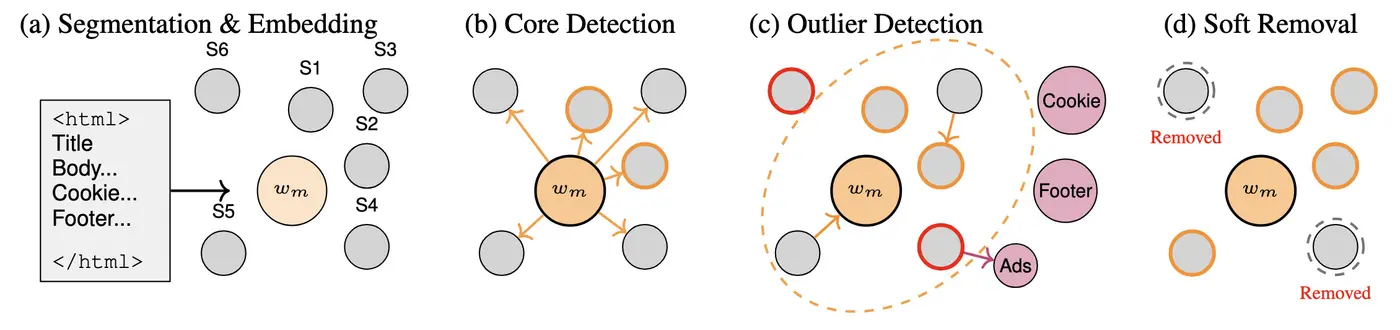
Overview
Modern NLP pipelines require robust methods to clean web documents, removing extraneous content like ads, navigation bars, and legal disclaimers while preserving the core message. Traditional methods that rely on HTML structure often struggle with diverse website layouts and multiple languages. While Large Language Models (LLMs) offer higher quality, they come with significant computational costs and latency, making them challenging for large-scale production systems.
To bridge this gap, we introduce SORE (Semantic Outlier Removal), a cost-effective and transparent system that leverages multilingual sentence embeddings to achieve near-LLM precision at a fraction of the cost. SORE works by: * Identifying core content using the document's metadata (e.g., title) as a semantic anchor. * Detecting outliers by flagging text segments that are either too semantically distant from the core content or too close to predefined categories of unwanted content (e.g., "ads," "legal disclaimers").
This approach is language-agnostic, scalable, and provides clear explanations for why content is removed, making it ideal for industrial applications.
In this repository, you will eventually find:
- Code: The production-ready implementation of the SORE algorithm and its evaluation scripts.
- SORE Datasets: The
SORE-SMALLandSORE-LARGEdatasets used in our experimental evaluation, complete with ground-truth main content for benchmarking extraction methods.
Abstract
Modern text processing pipelines demand robust methods to remove extraneous content while preserving a document's core message. Traditional approaches such as HTML boilerplate extraction or keyword filters often fail in multilingual settings and struggle with context-sensitive nuances, whereas Large Language Models (LLMs) offer improved quality at high computational cost. We introduce SORE (Semantic Outlier Removal), a cost-effective, transparent method that leverages multilingual sentence embeddings and approximate nearest-neighbor search to identify and excise unwanted text segments. By first identifying core content via metadata embedding and then flagging segments that either closely match predefined outlier groups or deviate significantly from the core, SORE achieves near-LLM extraction precision at a fraction of the cost. Experiments on HTML datasets demonstrate that SORE outperforms structural methods and yield high precision in diverse scenarios. Our system is currently deployed in production, processing millions of documents daily across multiple languages while maintaining both efficiency and accuracy. To facilitate further research, we will publicly release our implementation and evaluation datasets.
Citation
If you use our work, please consider citing our paper:
```bibtex @inproceedings{akbiyik2025sore, title={Semantic Outlier Removal with Embedding Models and LLMs}, author={Akbiyik, Eren and Almeida, Jo{~a}o and Melis, Rik and Sriram, Ritu and Petrescu, Viviana and Vilhj{\'a}lmsson, Vilhj{\'a}lmur}, booktitle={Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics}, year={2025}, publisher={Association for Computational Linguistics} }
Owner
- Name: M. Eren Akbiyik
- Login: meakbiyik
- Kind: user
- Company: ETH Zurich
- Repositories: 10
- Profile: https://github.com/meakbiyik
Data Science MSc at ETH Zurich
Citation (CITATION.cff)
cff-version: 1.2.0
message: "If you use this software, please cite it as below."
type: software
title: "Semantic Outlier Removal with Embedding Models and LLMs"
authors:
- family-names: "Akbiyik"
given-names: "Eren"
affiliation: "TripleLift"
- family-names: "Almeida"
given-names: "João"
affiliation: "TripleLift"
- family-names: "Melis"
given-names: "Rik"
affiliation: "TripleLift"
- family-names: "Sriram"
given-names: "Ritu"
affiliation: "TripleLift"
- family-names: "Petrescu"
given-names: "Viviana"
affiliation: "TripleLift"
- family-names: "Vilhjálmsson"
given-names: "Vilhjálmur"
affiliation: "TripleLift"
repository-code: "https://github.com/meakbiyik/sore"
url: "https://meakbiyik.com/sore/"
abstract: "Modern text processing pipelines demand robust methods to remove extraneous content while preserving a document's core message. Traditional approaches such as HTML boilerplate extraction or keyword filters often fail in multilingual settings and struggle with context-sensitive nuances, whereas Large Language Models (LLMs) offer improved quality at high computational cost. We introduce SORE (Semantic Outlier Removal), a cost-effective, transparent method that leverages multilingual sentence embeddings and approximate nearest-neighbor search to identify and excise unwanted text segments. By first identifying core content via metadata embedding and then flagging segments that either closely match predefined outlier groups or deviate significantly from the core, SORE achieves near-LLM extraction precision at a fraction of the cost." # [cite: 9, 10, 11, 12]
keywords:
- boilerplate-removal
- content-extraction
- semantic-similarity
- embedding-models
- outlier-detection
- nlp
preferred-citation:
type: conference-paper
title: "Semantic Outlier Removal with Embedding Models and LLMs"
authors:
- family-names: "Akbiyik"
given-names: "Eren"
affiliation: "TripleLift"
- family-names: "Almeida"
given-names: "João"
affiliation: "TripleLift"
- family-names: "Melis"
given-names: "Rik"
affiliation: "TripleLift"
- family-names: "Sriram"
given-names: "Ritu"
affiliation: "TripleLift"
- family-names: "Petrescu"
given-names: "Viviana"
affiliation: "TripleLift"
- family-names: "Vilhjálmsson"
given-names: "Vilhjálmur"
affiliation: "TripleLift"
collection-title: "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics"
year: 2025
publisher:
name: "Association for Computational Linguistics"
url: "https://arxiv.org/abs/2506.16644"
GitHub Events
Total
- Push event: 3
- Create event: 1
Last Year
- Push event: 3
- Create event: 1
Issues and Pull Requests
Last synced: 11 months ago