Science Score: 44.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
✓CITATION.cff file
Found CITATION.cff file -
✓codemeta.json file
Found codemeta.json file -
✓.zenodo.json file
Found .zenodo.json file -
○DOI references
-
○Academic publication links
-
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (3.8%) to scientific vocabulary
Repository
LLMs-from-scratch项目中文翻译
Basic Info
- Host: GitHub
- Owner: MLNLP-World
- License: other
- Language: Jupyter Notebook
- Default Branch: main
- Size: 51.3 MB
Statistics
- Stars: 1,230
- Watchers: 14
- Forks: 201
- Open Issues: 0
- Releases: 0
Metadata Files
README.md
 《从零构建大模型》
《从零构建大模型》



 项目动机
项目动机
原项目与地址:《LLMs-from-scratch》
本项目是对GitHub项目《LLMs-from-scratch》内容的中文翻译,包括详细的markdown 笔记和相关的jupyter 代码。翻译过程中,我们尽可能保持原意的准确性,同时对部分内容进行了语序和表达的优化,以更贴合中文学习者的阅读习惯。需要特别说明的是,原作者为该项目的主要贡献者,本汉化版本仅作为学习辅助资料,不对原内容进行修改或延伸。
由于个人能力有限,翻译中可能存在不完善之处,欢迎提出宝贵意见并多多包涵 希望通过这一翻译项目,更多中文学习者能够从中受益,也希望为国内社区的 LLM 学习和研究贡献一份力量。
本项目的特色: jupyter代码均有详细中文注释,帮助大家更快上手实践。 诸多的附加材料可以拓展知识
本项目所用徽章来自互联网,如侵犯了您的图片版权请联系我们删除,谢谢。
 课程简介
课程简介
提到大语言模型(LLMs),我们可能会将其视为独立于传统机器学习的领域,但实际上,LLMs 是机器学习的一个重要分支。在深度学习尚未广泛应用之前,机器学习在许多领域(如语音识别、自然语言处理、计算机视觉等)的作用相对有限,因为这些领域往往需要大量的专业知识来应对复杂的现实问题。然而,近几年深度学习的快速发展彻底改变了这一状况,使 LLMs 成为推动人工智能技术革命的关键力量。
原项目与地址:《LLMs-from-scratch》 https://github.com/rasbt/LLMs-from-scratch.git
在 《LLMs-from-scratch》项目中,不仅关注 LLMs 的基础构建,如 Transformer 架构、序列建模 等,还深入探索了 GPT、BERT 等深度学习模型 的底层实现。项目中的每一部分均配备详细的代码实现和学习资源,帮助学习者从零开始构建 LLMs,全面掌握其核心技术。
 课程资源
课程资源
- 英文原版地址:原版地址
- 教材网址:原版教材
- 汉化地址:https://github.com/MLNLP-World/LLMs-from-scratch-CN.git
此外,本门课程还有相应的代码实现。每章都有相应的jupyter记事本,提供模型的完整python代码,所有的资源都可在网上免费获取。
 原书Readme
原书Readme
从零构建大模型
这个仓库包含了开发、预训练和微调一个类似GPT的LLM(大语言模型)的代码,是《从零构建大模型》这本书的官方代码仓库,书籍链接:从零构建大模型。

在《从零构建大模型》这本书中,您将逐步了解大语言模型(LLMs)如何从内到外工作,自己动手编写代码,逐步构建一个LLM。在这本书中,我将通过清晰的文字、图示和示例,带您完成构建自己LLM的每一个阶段。
本书描述的训练和开发自己的小型功能性模型的方法,旨在教育用途,类似于用于创建大规模基础模型(如ChatGPT背后的模型)的方法。此外,本书还包括加载更大预训练模型权重进行微调的代码。
- 官方源代码仓库链接
- 汉化版本汉化仓库链接
- 出版商网站上的书籍链接
- Amazon.com上的书籍页面链接
- ISBN 9781633437166

要下载此仓库的副本,请点击下载ZIP按钮,或者在终端中执行以下命令:
bash
git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git
要下载此仓库汉化版本,请点击下载ZIP按钮,或者在终端中执行以下命令:
bash
git clone --depth 1 https://github.com/MLNLP-World/LLMs-from-scratch-CN.git
(如果您是从Manning网站下载的代码包,请访问官方代码仓库 https://github.com/rasbt/LLMs-from-scratch 获取最新的更新 或者汉化版本https://github.com/MLNLP-World/LLMs-from-scratch-CN.git)
目录
请注意,本文档是一个Markdown (.md) 文件。如果您是从Manning网站下载的代码包并在本地查看它,建议使用Markdown编辑器或预览器进行正确查看。如果您尚未安装Markdown编辑器,MarkText 是一个不错的免费选项。
您也可以通过浏览器访问GitHub上的代码仓库,或者汉化版浏览器会自动渲染Markdown。
<!-- -->
[!TIP] 如果您需要安装Python和Python包以及设置代码环境的指导,建议阅读README.md 文件,该文件位于setup目录中。
| 章节标题 | 主要代码(快速访问) | 所有代码及补充内容 | 翻译者 | 校对者 |
|---------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------|------------|------------|
| 安装建议 | - | - |  |
|  |
| 第1章:理解大型语言模型 | 无代码 | - | | |
| 第2章:处理文本数据 | - ch02.ipynb
|
| 第1章:理解大型语言模型 | 无代码 | - | | |
| 第2章:处理文本数据 | - ch02.ipynb
- dataloader.ipynb(总结)
- exercise-solutions.ipynb | ch02 | | |
| 第3章:编码注意力机制 | - ch03.ipynb
- multihead-attention.ipynb(总结)
- exercise-solutions.ipynb | ch03 | | |
| 第4章:从零开始实现 GPT 模型 | - ch04.ipynb
- gpt.py(总结)
- exercise-solutions.ipynb | ch04 | | |
| 第5章:在无标注数据上进行预训练 | - ch05.ipynb
- gpt_train.py(总结)
- gpt_generate.py(总结)
- exercise-solutions.ipynb | ch05 | |  |
| 第6章:进行文本分类的微调 | - ch06.ipynb
|
| 第6章:进行文本分类的微调 | - ch06.ipynb
- gptclassfinetune.py
- exercise-solutions.ipynb | ch06 | | |
| 第7章:进行遵循指令的微调 | - ch07.ipynb
- gptinstructionfinetuning.py(总结)
- ollama_evaluate.py(总结)
- exercise-solutions.ipynb | ch07 | | |
| 附录 A:PyTorch 简介 | - code-part1.ipynb
- code-part2.ipynb
- DDP-script.py
- exercise-solutions.ipynb | appendix-A | |  |
| 附录 B:参考文献与进一步阅读 | 无代码 | - | | |
| 附录 C:习题解答 | 无代码 | - | | |
| 附录 D:在训练循环中加入附加功能 | - appendix-D.ipynb | appendix-D | | |
| 附录 E:使用 LoRA 进行参数高效微调 | - appendix-E.ipynb | appendix-E | | |
|
| 附录 B:参考文献与进一步阅读 | 无代码 | - | | |
| 附录 C:习题解答 | 无代码 | - | | |
| 附录 D:在训练循环中加入附加功能 | - appendix-D.ipynb | appendix-D | | |
| 附录 E:使用 LoRA 进行参数高效微调 | - appendix-E.ipynb | appendix-E | | |
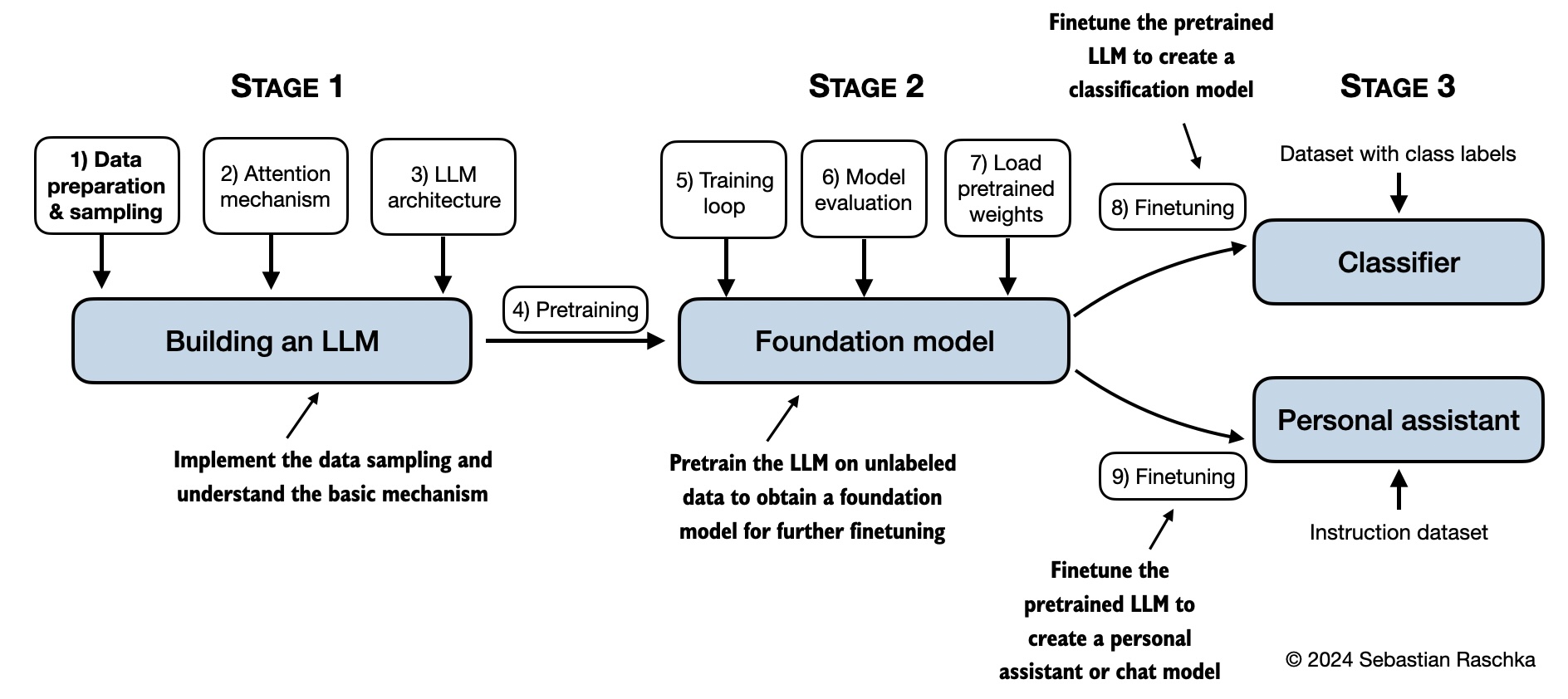
下图是本书内容的总结性思维导图。
额外材料
| 章节 | 附加资料 | 翻译者 | 校对者 |
|--------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------|
| 设置 | - Python 设置提示
- 安装本书中使用的 Python 包和库
- Docker 环境设置指南 | | |
| 第二章:处理文本数据 | - 从零开始实现字节对编码(BPE)分词器
- 比较不同字节对编码(BPE)实现
- 理解嵌入层和线性层的区别
- 用简单数字直观理解数据加载器 | | |
| 第三章:编码注意力机制 | - 比较高效的多头注意力实现
- 理解 PyTorch 缓冲区 | | |
| 第四章:从零开始实现 GPT 模型 | - FLOPS 性能分析 | | |
| 第五章:在未标注数据上进行预训练 | - 使用 Transformers 从 Hugging Face 模型库加载替代权重
- 在古腾堡计划数据集上预训练 GPT
- 为训练循环添加附加功能
- 优化预训练的超参数
- 构建与预训练 LLM 交互的用户界面
- 将 GPT 转换为 Llama
- 从零开始构建 Llama 3.2
- 内存高效的模型权重加载
- 扩展 Tiktoken BPE 分词器,添加新 Token | | |
| 第六章:用于分类的微调 | - 微调不同层并使用更大模型的额外实验
- 在 50k IMDB 电影评论数据集上微调不同模型
- 构建与 GPT 基于垃圾邮件分类器交互的用户界面 | | |
| 第七章:微调以跟随指令 | - 查找近重复项和创建被动语态条目的数据集工具
- 使用 OpenAI API 和 Ollama 评估指令响应
- 为指令微调生成数据集
- 改进指令微调数据集
- 使用 Llama 3.1 70B 和 Ollama 生成偏好数据集
- 用于 LLM 对齐的直接偏好优化(DPO)
- 构建与指令微调的 GPT 模型交互的用户界面 | | |
硬件要求
本书主要章节中的代码设计为能够在常规笔记本电脑上运行,并且不会占用过长时间,因此不需要专门的硬件。这种方式确保了广泛的读者群体能够参与其中。此外,如果有可用的 GPU,代码会自动使用它们。(更多建议请参考 setup 文档。)
问题、反馈和贡献
欢迎各种形式的反馈,最好通过 Manning 论坛 或 GitHub 讨论区 分享。如果你有任何问题或只是想与他人讨论想法,也请随时在论坛中发布。
请注意,由于本存储库包含与印刷书籍相对应的代码,因此目前无法接受扩展主要章节代码内容的贡献,因为这可能会导致与实体书籍的内容不一致。保持一致性有助于确保每个人的顺畅体验。
引用
如果你发现本书或代码对你的研究有帮助,请考虑引用它。
引用:
Raschka, Sebastian. Build A Large Language Model (From Scratch). Manning, 2024. ISBN: 978-1633437166.
BibTeX 条目:
@book{build-llms-from-scratch-book,
author = {Sebastian Raschka},
title = {Build A Large Language Model (From Scratch)},
publisher = {Manning},
year = {2024},
isbn = {978-1633437166},
url = {https://www.manning.com/books/build-a-large-language-model-from-scratch},
github = {https://github.com/rasbt/LLMs-from-scratch}
}
 贡献者
贡献者
Owner
- Name: MLNLP
- Login: MLNLP-World
- Kind: organization
- Website: https://space.bilibili.com/168887299
- Repositories: 13
- Profile: https://github.com/MLNLP-World
bring the AI community closer together and empower every junior leaner to achieve more.
Citation (CITATION.cff)
cff-version: 1.2.0
message: "If you use this book or its accompanying code, please cite it as follows."
title: "Build A Large Language Model (From Scratch), Published by Manning, ISBN 978-1633437166"
abstract: "This book provides a comprehensive, step-by-step guide to implementing a ChatGPT-like large language model from scratch in PyTorch."
date-released: 2024-09-12
authors:
- family-names: "Raschka"
given-names: "Sebastian"
license: "Apache-2.0"
url: "https://www.manning.com/books/build-a-large-language-model-from-scratch"
repository-code: "https://github.com/rasbt/LLMs-from-scratch"
keywords:
- large language models
- natural language processing
- artificial intelligence
- PyTorch
- machine learning
- deep learning
GitHub Events
Total
- Issues event: 2
- Watch event: 1,247
- Issue comment event: 2
- Member event: 2
- Push event: 19
- Public event: 1
- Pull request event: 11
- Fork event: 204
Last Year
- Issues event: 2
- Watch event: 1,247
- Issue comment event: 2
- Member event: 2
- Push event: 19
- Public event: 1
- Pull request event: 11
- Fork event: 204
Issues and Pull Requests
Last synced: 10 months ago
All Time
- Total issues: 1
- Total pull requests: 12
- Average time to close issues: about 20 hours
- Average time to close pull requests: about 23 hours
- Total issue authors: 1
- Total pull request authors: 2
- Average comments per issue: 2.0
- Average comments per pull request: 0.0
- Merged pull requests: 10
- Bot issues: 0
- Bot pull requests: 0
Past Year
- Issues: 1
- Pull requests: 12
- Average time to close issues: about 20 hours
- Average time to close pull requests: about 23 hours
- Issue authors: 1
- Pull request authors: 2
- Average comments per issue: 2.0
- Average comments per pull request: 0.0
- Merged pull requests: 10
- Bot issues: 0
- Bot pull requests: 0
Top Authors
Issue Authors
- fengyun99 (1)
Pull Request Authors
- GoatCsu (8)
- eecn (4)
Top Labels
Issue Labels
Pull Request Labels
Dependencies
- pytorch/pytorch 2.5.0-cuda12.4-cudnn9-runtime build
- requests *
- tqdm *
- transformers >=4.33.2
- thop *
- chainlit >=1.2.0
- blobfile >=3.0.0
- huggingface_hub >=0.24.7
- ipywidgets >=8.1.2
- safetensors >=0.4.4
- sentencepiece >=0.1.99
- pytest >=8.1.1 test
- transformers >=4.44.2 test
- scikit-learn >=1.3.0
- transformers >=4.33.2
- chainlit >=1.2.0
- openai >=1.30.3
- scikit-learn >=1.3.1
- tqdm >=4.65.0
- openai >=1.30.3
- tqdm >=4.65.0
- openai >=1.30.3
- tqdm >=4.65.0
- chainlit >=1.2.0
- jupyterlab >=4.0
- matplotlib >=3.7.1
- numpy >=1.25,<2.0
- pandas >=2.2.1
- psutil >=5.9.5
- tensorflow >=2.15.0
- tiktoken >=0.5.1
- torch >=2.0.1
- tqdm >=4.66.1