Recent Releases of openrlbenchmark
openrlbenchmark - v0.2.0 `rliable` integration, offline mode, multi metrics
This release brings exciting new features. I am excited to share that openrlbenchmark now includes direct integration with https://github.com/google-research/rliable. The new release also supports offline mode and plotting with multi metrics.
rliable integration
python -m openrlbenchmark.rlops \
--filters '?we=openrlbenchmark&wpn=cleanrl&ceik=env_id&cen=exp_name&metric=charts/episodic_return' \
'ppo_continuous_action?tag=v1.0.0-27-gde3f410&cl=CleanRL PPO' \
--filters '?we=openrlbenchmark&wpn=baselines&ceik=env&cen=exp_name&metric=charts/episodic_return' \
'baselines-ppo2-mlp?cl=openai/baselines PPO2' \
--env-ids HalfCheetah-v2 Hopper-v2 Walker2d-v2 \
--env-ids HalfCheetah-v2 Hopper-v2 Walker2d-v2 \
--no-check-empty-runs \
--pc.ncols 3 \
--pc.ncols-legend 3 \
--rliable \
--rc.score_normalization_method maxmin \
--rc.normalized_score_threshold 1.0 \
--rc.sample_efficiency_plots \
--rc.sample_efficiency_and_walltime_efficiency_method Median \
--rc.performance_profile_plots \
--rc.aggregate_metrics_plots \
--rc.sample_efficiency_num_bootstrap_reps 10 \
--rc.performance_profile_num_bootstrap_reps 10 \
--rc.interval_estimates_num_bootstrap_reps 10 \
--output-filename compare \
--scan-history
now yields
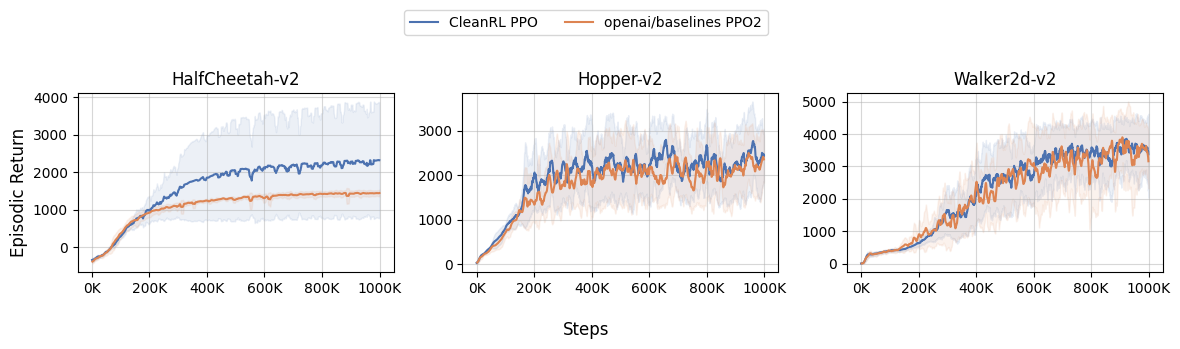
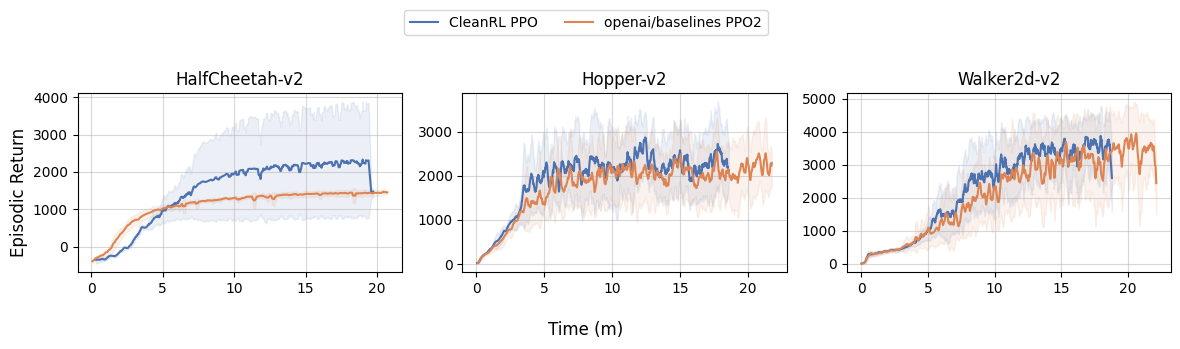
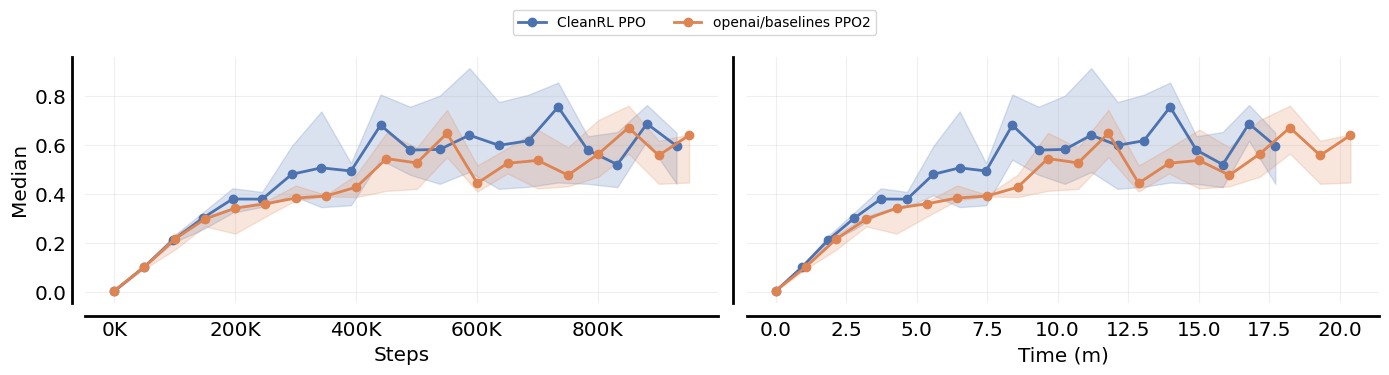
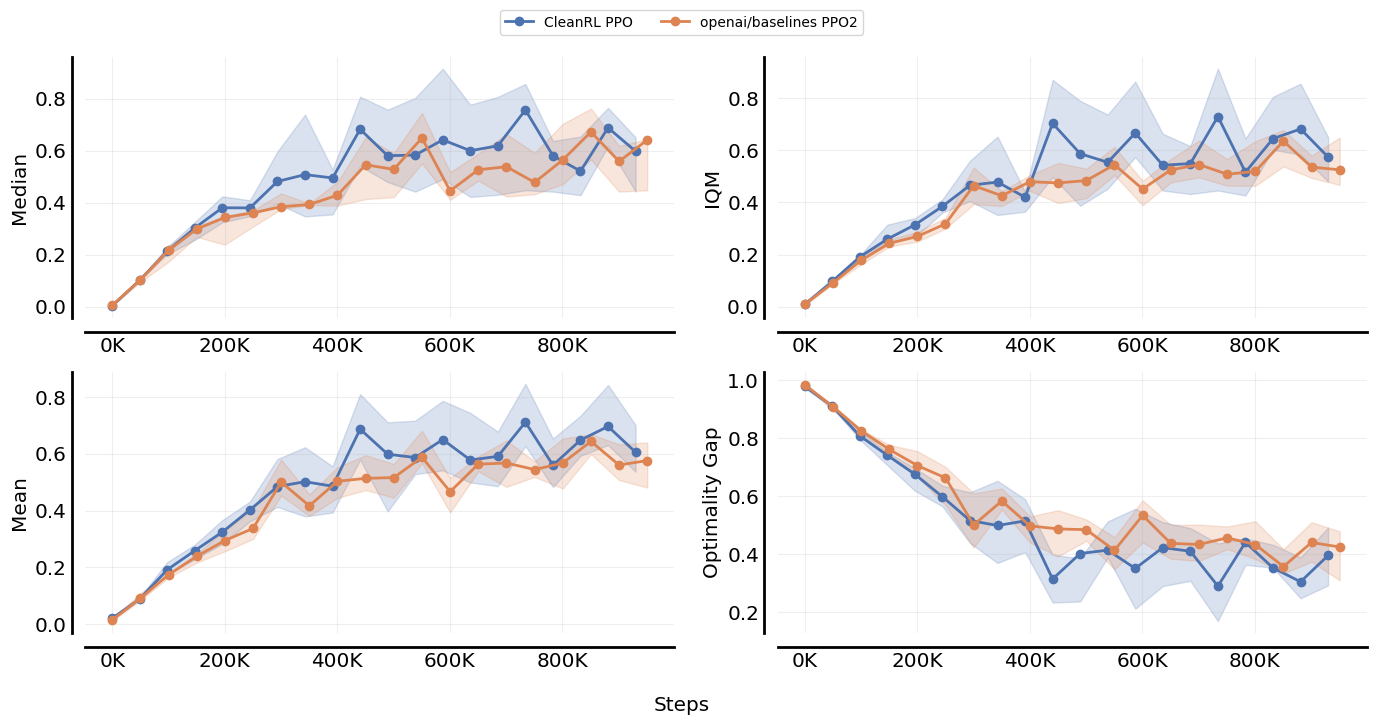
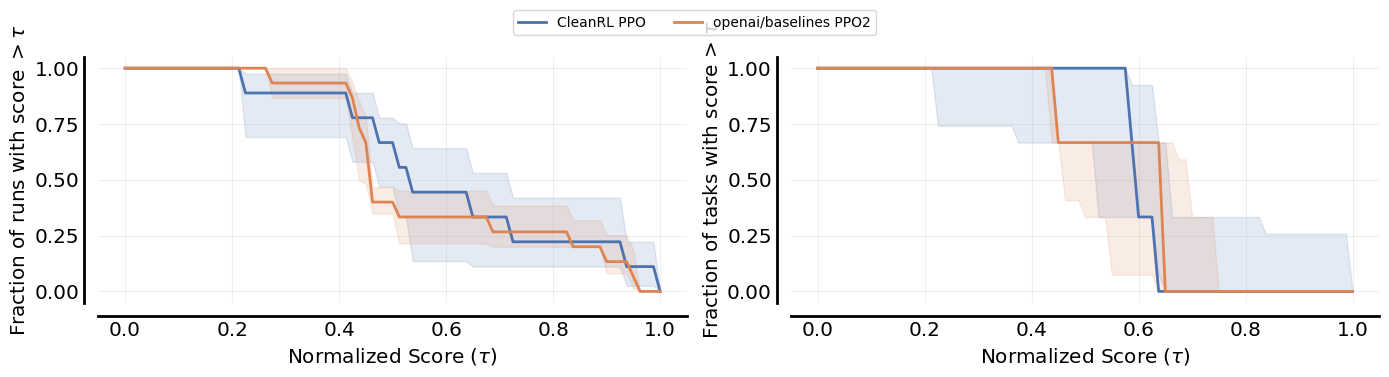

CC rliable contributors @agarwl @qgallouedec @DennisSoemers @lkevinzc.
Offline mode
We introduced an experimental offline mode. Sometimes even with caching --scan-history the script can still take a long time if there are too many environments or experiments. This is because we are still calling many wandb.Api().runs(..., filters) under the hood.
No worries though. When running with --scan-history, we also automatically build a local sqlite database to store the metadata of runs. Then, you can run python -m openrlbenchmark.rlops ... --scan-history --offline to generate the plots without having access to the internet. It should considerably speed up the plotting process as well. We are still working on improving the offline mode, so please let us know if you encounter any issues.
Multi metrics
Experimental! API may change.
Thanks to @ffelten, we can now plot multi metrics in the same plot now.
shell
python -m openrlbenchmark.rlops_multi_metrics \
--filters '?we=openrlbenchmark&wpn=cleanrl&ceik=env_id&cen=exp_name&metrics=charts/episodic_return&metrics=charts/episodic_length&metrics=charts/SPS&metrics=losses/actor_loss&metrics=losses/qf1_values&metrics=losses/qf1_loss' \
'ddpg_continuous_action?tag=pr-371' \
'ddpg_continuous_action?tag=pr-299' \
'ddpg_continuous_action?tag=rlops-pilot' \
'ddpg_continuous_action_jax?tag=pr-371-jax' \
'ddpg_continuous_action_jax?tag=pr-298' \
--env-ids HalfCheetah-v2 Hopper-v2 Walker2d-v2 \
--no-check-empty-runs \
--pc.ncols 3 \
--pc.ncols-legend 2 \
--output-filename static/multi-metrics \
--scan-history --offline
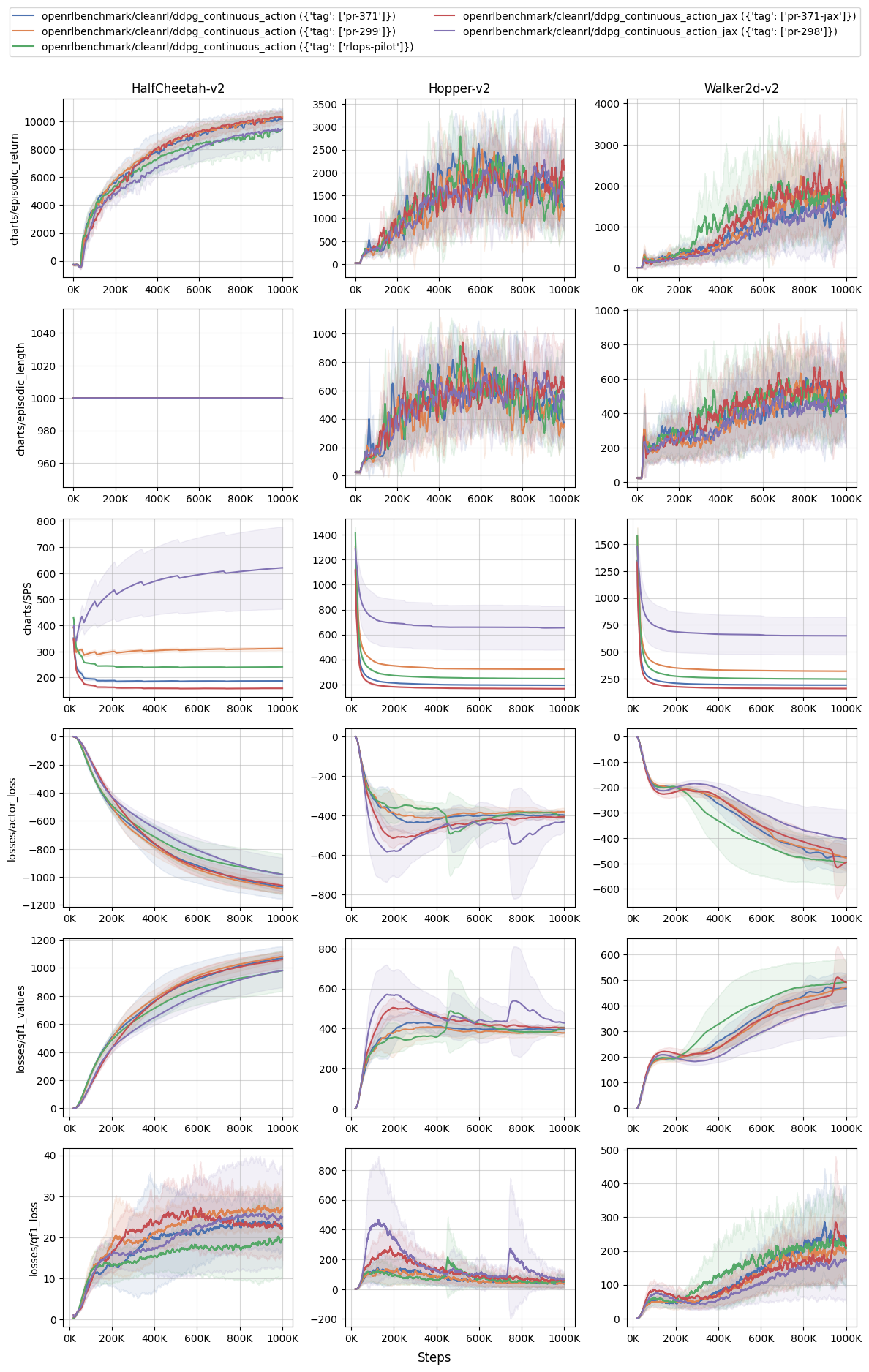
What's Changed
- Fix MuJoCo plots by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/4
- New plotting API by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/5
- Rlops API by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/6
- Glow up README by @qgallouedec in https://github.com/openrlbenchmark/openrlbenchmark/pull/8
- Add MORL Baselines to README by @ffelten in https://github.com/openrlbenchmark/openrlbenchmark/pull/10
- Add rlops for plotting human normalized scores by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/11
- use tyro for argparse by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/12
- Various refactor and features by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/13
- Remove unused
tyro.conf.OmitSubcommandPrefixesconfig by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/16 - Refactor by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/21
- Create citation by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/17
- General rliable support by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/22
- [WIP] Multi metric support by @ffelten in https://github.com/openrlbenchmark/openrlbenchmark/pull/23
New Contributors
- @qgallouedec made their first contribution in https://github.com/openrlbenchmark/openrlbenchmark/pull/8
- @ffelten made their first contribution in https://github.com/openrlbenchmark/openrlbenchmark/pull/10
Full Changelog: https://github.com/openrlbenchmark/openrlbenchmark/compare/v0.0.1...v0.2.0
- Python
Published by vwxyzjn about 3 years ago
openrlbenchmark - v0.1.1b3 Better Table Printing
This release brings better table printing:
python -m openrlbenchmark.rlops \
--filters '?we=openrlbenchmark&wpn=baselines&ceik=env&cen=exp_name&metric=charts/episodic_return' 'baselines-ppo2-mlp' \
--filters '?we=openrlbenchmark&wpn=cleanrl&ceik=env_id&cen=exp_name&metric=charts/episodic_return' 'ppo_continuous_action?tag=v1.0.0-27-gde3f410' \
--filters '?we=openrlbenchmark&wpn=jaxrl&ceik=env_name&cen=algo&metric=training/return' 'sac' \
--env-ids HalfCheetah-v2 Walker2d-v2 Hopper-v2 InvertedPendulum-v2 Humanoid-v2 Pusher-v2 \
--check-empty-runs False \
--ncols 3 \
--ncols-legend 3 \
--output-filename compare \
--scan-history
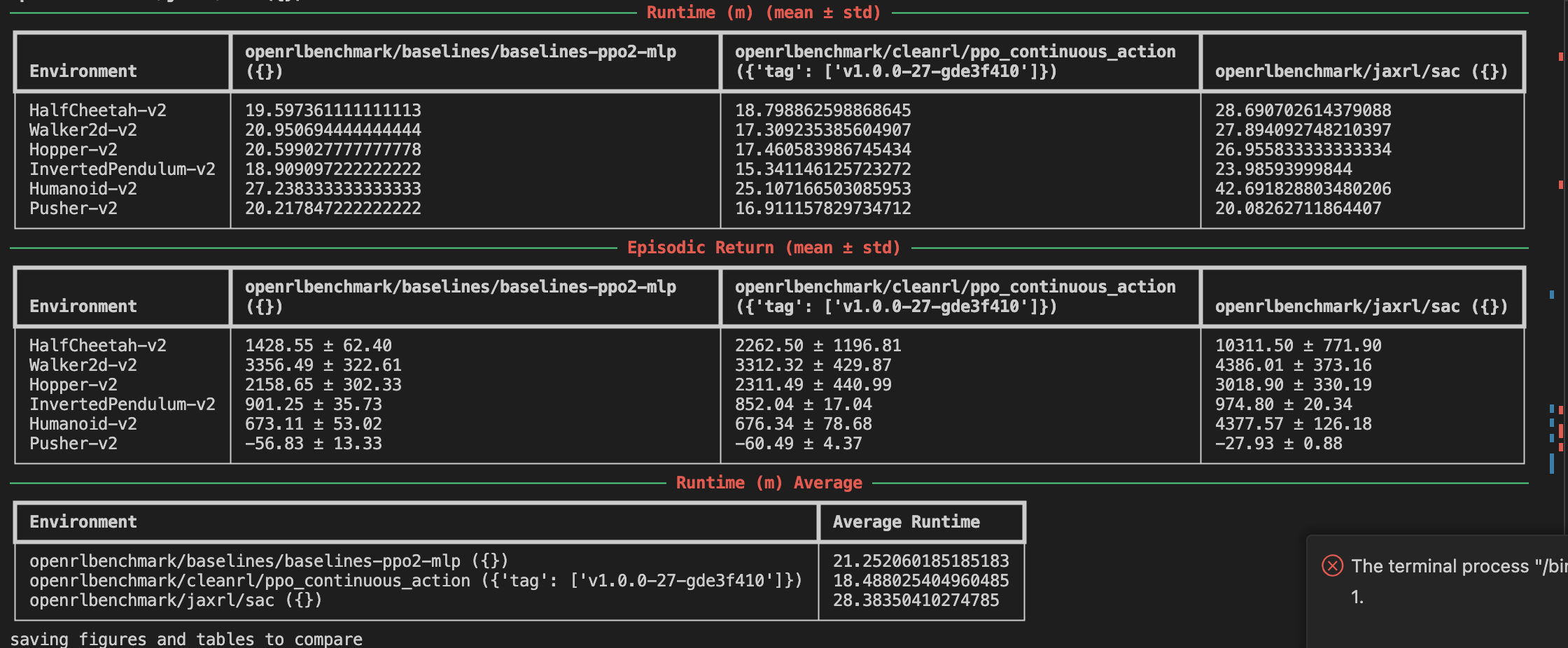
- Python
Published by vwxyzjn over 3 years ago
openrlbenchmark - v0.1.1b2 custom legend
What's Changed
The v0.1.1b2 supports customing the legend via the cl query string, customizing the figure labels with --xlabel and --ylabel. Additionally, the default line name in the legend now prefixes with the wandb project and entity. For example, a2c from SB3 will be prefixed with openrlbenchmark/sb3/a2c.
python -m openrlbenchmark.rlops \
--filters '?we=openrlbenchmark&wpn=sb3&ceik=env&cen=algo&metric=rollout/ep_rew_mean' \
'a2c' \
'ddpg' \
'ppo_lstm?cl=PPO w/ LSTM' \
'sac' \
'td3' \
'ppo' \
'trpo' \
--filters '?we=openrlbenchmark&wpn=cleanrl&ceik=env_id&cen=exp_name&metric=charts/episodic_return' \
'sac_continuous_action?tag=rlops-pilot&cl=SAC' \
--env-ids HalfCheetahBulletEnv-v0 \
--ncols 1 \
--ncols-legend 2 \
--xlabel 'Training Steps' \
--ylabel 'Episodic Return' \
--output-filename compare
generates
| cleanrl vs. Stable Baselines 3 | cleanrl vs. Stable Baselines 3 (Time) |
|:----------------------------------:|:----------------------------------------:|
|  |
|  |
|
- Glow up README by @qgallouedec in https://github.com/openrlbenchmark/openrlbenchmark/pull/8
New Contributors
- @qgallouedec made their first contribution in https://github.com/openrlbenchmark/openrlbenchmark/pull/8
Full Changelog: https://github.com/openrlbenchmark/openrlbenchmark/compare/v0.1.1b0...v0.1.1b2
- Python
Published by vwxyzjn over 3 years ago
openrlbenchmark - 🔥 v0.1.1b0 Beta Release
Excited to announce our first beta release of openrlbenchmark, a tool to help you grab metrics from popular RL libraries, such as SB3, CleanRL, baselines, Tianshou, etc.
Here is an example snippet. You can open it at ![]()
bash
pip install openrlbenchmark
python -m openrlbenchmark.rlops \
--filters '?we=openrlbenchmark&wpn=sb3&ceik=env&cen=algo&metric=rollout/ep_rew_mean' \
'a2c' \
'ddpg' \
'ppo_lstm' \
'sac' \
'td3' \
'ppo' \
'trpo' \
--filters '?we=openrlbenchmark&wpn=cleanrl&ceik=env_id&cen=exp_name&metric=charts/episodic_return' \
'sac_continuous_action?tag=rlops-pilot' \
--env-ids HalfCheetahBulletEnv-v0 \
--ncols 1 \
--ncols-legend 2 \
--output-filename compare.png \
--report
which generates

What happened?
The idea is to use filters-like syntax to grab the metrics of interest. Here, we created multiple filters. The first string in the first filter is '?we=openrlbenchmark&wpn=sb3&ceik=env&cen=algo&metric=rollout/ep_rew_mean', which is a query string that specifies the following:
we: the W&B entity namewpn: the W&B project nameceik: the custom key for the environment idcen: the custom key for the experiment namemetric: the metric we are interested in
So we are fetching metrics from https://wandb.ai/openrlbenchmark/sb3. The environment id is stored in the env key, and the experiment name is stored in the algo key. The metric we are interested in is rollout/ep_rew_mean.
Similarly, we are fetching metrics from https://wandb.ai/openrlbenchmark/cleanrl. The environment id is stored in the env_id key, and the experiment name is stored in the exp_name key. The metric we are interested in is charts/episodic_return.
More docs and examples
See more examples and docs at https://github.com/openrlbenchmark/openrlbenchmark
Notably, https://github.com/openrlbenchmark/openrlbenchmark#currently-supported-libraries has the list of supported libraries, and below are some examples of the plots.


More info
Please check out the following links for more info.
- 💾 GitHub Repo: source code and more docs.
- 📜 Design docs: our motivation and vision.
- 🔗 Open RL Benchmark reports: W&B reports with tracked Atari, MuJoCo experiments from SB3, CleanRL, and others.
What's going on right now?
This is a project we are slowly working on. There is no specific timeline or roadmap, but if you want to get involved. Feel free to reach out to me or open an issue. We are looking for volunteers to help us with the following:
- Add experiments from other libraries
- Run more experiments from currently supported libraries
- Documentation and designing standards
- Download the tensorboard metrics from the tracked experiments and load them locally to save time
- Python
Published by vwxyzjn over 3 years ago
openrlbenchmark - Initial v0.0.1 release
What's Changed
- [WIP] Prototype plotting utility by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/2
- Plot by @vwxyzjn in https://github.com/openrlbenchmark/openrlbenchmark/pull/3
New Contributors
- @vwxyzjn made their first contribution in https://github.com/openrlbenchmark/openrlbenchmark/pull/2
Full Changelog: https://github.com/openrlbenchmark/openrlbenchmark/commits/v0.0.1
- Python
Published by vwxyzjn over 3 years ago