https://github.com/1587causalai/xtuner
An efficient, flexible and full-featured toolkit for fine-tuning LLM (InternLM2, Llama3, Phi3, Qwen, Mistral, ...)
Science Score: 10.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
○codemeta.json file
-
○.zenodo.json file
-
○DOI references
-
✓Academic publication links
Links to: arxiv.org -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (6.8%) to scientific vocabulary
Last synced: 9 months ago
·
JSON representation
Repository
An efficient, flexible and full-featured toolkit for fine-tuning LLM (InternLM2, Llama3, Phi3, Qwen, Mistral, ...)
Basic Info
- Host: GitHub
- Owner: 1587causalai
- License: apache-2.0
- Language: Python
- Default Branch: main
- Homepage: https://xtuner.readthedocs.io/zh-cn/latest/
- Size: 1.41 MB
Statistics
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
- Releases: 0
Fork of InternLM/xtuner
Created almost 2 years ago
· Last pushed almost 2 years ago
https://github.com/1587causalai/xtuner/blob/main/
## Speed Benchmark - Llama2 7B Training Speed
[](https://github.com/InternLM/xtuner/stargazers) [](https://github.com/InternLM/xtuner/blob/main/LICENSE) [](https://pypi.org/project/xtuner/) [](https://pypi.org/project/xtuner/) [](https://github.com/InternLM/xtuner/issues) [](https://github.com/InternLM/xtuner/issues) join us on [](https://cdn.vansin.top/internlm/xtuner.jpg) [](https://twitter.com/intern_lm) [](https://discord.gg/xa29JuW87d) Explore our models on [](https://huggingface.co/xtuner) [](https://www.modelscope.cn/organization/xtuner) [](https://openxlab.org.cn/usercenter/xtuner) [](https://www.wisemodel.cn/organization/xtuner) English | [](README_zh-CN.md)- Llama2 70B Training Speed ## News - **\[2024/07\]** Support [InternLM 2.5](xtuner/configs/internlm/internlm2_5_chat_7b/) models! - **\[2024/06\]** Support [DeepSeek V2](xtuner/configs/deepseek/deepseek_v2_chat/) models! **2x faster!** - **\[2024/04\]** [LLaVA-Phi-3-mini](https://huggingface.co/xtuner/llava-phi-3-mini-hf) is released! Click [here](xtuner/configs/llava/phi3_mini_4k_instruct_clip_vit_large_p14_336) for details! - **\[2024/04\]** [LLaVA-Llama-3-8B](https://huggingface.co/xtuner/llava-llama-3-8b) and [LLaVA-Llama-3-8B-v1.1](https://huggingface.co/xtuner/llava-llama-3-8b-v1_1) are released! Click [here](xtuner/configs/llava/llama3_8b_instruct_clip_vit_large_p14_336) for details! - **\[2024/04\]** Support [Llama 3](xtuner/configs/llama) models! - **\[2024/04\]** Support Sequence Parallel for enabling highly efficient and scalable LLM training with extremely long sequence lengths! \[[Usage](https://github.com/InternLM/xtuner/blob/docs/docs/zh_cn/acceleration/train_extreme_long_sequence.rst)\] \[[Speed Benchmark](https://github.com/InternLM/xtuner/blob/docs/docs/zh_cn/acceleration/benchmark.rst)\] - **\[2024/02\]** Support [Gemma](xtuner/configs/gemma) models! - **\[2024/02\]** Support [Qwen1.5](xtuner/configs/qwen/qwen1_5) models! - **\[2024/01\]** Support [InternLM2](xtuner/configs/internlm) models! The latest VLM [LLaVA-Internlm2-7B](https://huggingface.co/xtuner/llava-internlm2-7b) / [20B](https://huggingface.co/xtuner/llava-internlm2-20b) models are released, with impressive performance! - **\[2024/01\]** Support [DeepSeek-MoE](https://huggingface.co/deepseek-ai/deepseek-moe-16b-chat) models! 20GB GPU memory is enough for QLoRA fine-tuning, and 4x80GB for full-parameter fine-tuning. Click [here](xtuner/configs/deepseek/) for details! - **\[2023/12\]** Support multi-modal VLM pretraining and fine-tuning with [LLaVA-v1.5](https://github.com/haotian-liu/LLaVA) architecture! Click [here](xtuner/configs/llava/README.md) for details! - **\[2023/12\]** Support [Mixtral 8x7B](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) models! Click [here](xtuner/configs/mixtral/README.md) for details! - **\[2023/11\]** Support [ChatGLM3-6B](xtuner/configs/chatglm) model! - **\[2023/10\]** Support [MSAgent-Bench](https://modelscope.cn/datasets/damo/MSAgent-Bench) dataset, and the fine-tuned LLMs can be applied by [Lagent](https://github.com/InternLM/lagent)! - **\[2023/10\]** Optimize the data processing to accommodate `system` context. More information can be found on [Docs](docs/en/user_guides/dataset_format.md)! - **\[2023/09\]** Support [InternLM-20B](xtuner/configs/internlm) models! - **\[2023/09\]** Support [Baichuan2](xtuner/configs/baichuan) models! - **\[2023/08\]** XTuner is released, with multiple fine-tuned adapters on [Hugging Face](https://huggingface.co/xtuner). ## Introduction XTuner is an efficient, flexible and full-featured toolkit for fine-tuning large models. **Efficient** - Support LLM, VLM pre-training / fine-tuning on almost all GPUs. XTuner is capable of fine-tuning 7B LLM on a single 8GB GPU, as well as multi-node fine-tuning of models exceeding 70B. - Automatically dispatch high-performance operators such as FlashAttention and Triton kernels to increase training throughput. - Compatible with [DeepSpeed](https://github.com/microsoft/DeepSpeed) , easily utilizing a variety of ZeRO optimization techniques. **Flexible** - Support various LLMs ([InternLM](https://huggingface.co/internlm), [Mixtral-8x7B](https://huggingface.co/mistralai), [Llama 2](https://huggingface.co/meta-llama), [ChatGLM](https://huggingface.co/THUDM), [Qwen](https://huggingface.co/Qwen), [Baichuan](https://huggingface.co/baichuan-inc), ...). - Support VLM ([LLaVA](https://github.com/haotian-liu/LLaVA)). The performance of [LLaVA-InternLM2-20B](https://huggingface.co/xtuner/llava-internlm2-20b) is outstanding. - Well-designed data pipeline, accommodating datasets in any format, including but not limited to open-source and custom formats. - Support various training algorithms ([QLoRA](http://arxiv.org/abs/2305.14314), [LoRA](http://arxiv.org/abs/2106.09685), full-parameter fune-tune), allowing users to choose the most suitable solution for their requirements. **Full-featured** - Support continuous pre-training, instruction fine-tuning, and agent fine-tuning. - Support chatting with large models with pre-defined templates. - The output models can seamlessly integrate with deployment and server toolkit ([LMDeploy](https://github.com/InternLM/lmdeploy)), and large-scale evaluation toolkit ([OpenCompass](https://github.com/open-compass/opencompass), [VLMEvalKit](https://github.com/open-compass/VLMEvalKit)). ## Supports
## News - **\[2024/07\]** Support [InternLM 2.5](xtuner/configs/internlm/internlm2_5_chat_7b/) models! - **\[2024/06\]** Support [DeepSeek V2](xtuner/configs/deepseek/deepseek_v2_chat/) models! **2x faster!** - **\[2024/04\]** [LLaVA-Phi-3-mini](https://huggingface.co/xtuner/llava-phi-3-mini-hf) is released! Click [here](xtuner/configs/llava/phi3_mini_4k_instruct_clip_vit_large_p14_336) for details! - **\[2024/04\]** [LLaVA-Llama-3-8B](https://huggingface.co/xtuner/llava-llama-3-8b) and [LLaVA-Llama-3-8B-v1.1](https://huggingface.co/xtuner/llava-llama-3-8b-v1_1) are released! Click [here](xtuner/configs/llava/llama3_8b_instruct_clip_vit_large_p14_336) for details! - **\[2024/04\]** Support [Llama 3](xtuner/configs/llama) models! - **\[2024/04\]** Support Sequence Parallel for enabling highly efficient and scalable LLM training with extremely long sequence lengths! \[[Usage](https://github.com/InternLM/xtuner/blob/docs/docs/zh_cn/acceleration/train_extreme_long_sequence.rst)\] \[[Speed Benchmark](https://github.com/InternLM/xtuner/blob/docs/docs/zh_cn/acceleration/benchmark.rst)\] - **\[2024/02\]** Support [Gemma](xtuner/configs/gemma) models! - **\[2024/02\]** Support [Qwen1.5](xtuner/configs/qwen/qwen1_5) models! - **\[2024/01\]** Support [InternLM2](xtuner/configs/internlm) models! The latest VLM [LLaVA-Internlm2-7B](https://huggingface.co/xtuner/llava-internlm2-7b) / [20B](https://huggingface.co/xtuner/llava-internlm2-20b) models are released, with impressive performance! - **\[2024/01\]** Support [DeepSeek-MoE](https://huggingface.co/deepseek-ai/deepseek-moe-16b-chat) models! 20GB GPU memory is enough for QLoRA fine-tuning, and 4x80GB for full-parameter fine-tuning. Click [here](xtuner/configs/deepseek/) for details! - **\[2023/12\]** Support multi-modal VLM pretraining and fine-tuning with [LLaVA-v1.5](https://github.com/haotian-liu/LLaVA) architecture! Click [here](xtuner/configs/llava/README.md) for details! - **\[2023/12\]** Support [Mixtral 8x7B](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) models! Click [here](xtuner/configs/mixtral/README.md) for details! - **\[2023/11\]** Support [ChatGLM3-6B](xtuner/configs/chatglm) model! - **\[2023/10\]** Support [MSAgent-Bench](https://modelscope.cn/datasets/damo/MSAgent-Bench) dataset, and the fine-tuned LLMs can be applied by [Lagent](https://github.com/InternLM/lagent)! - **\[2023/10\]** Optimize the data processing to accommodate `system` context. More information can be found on [Docs](docs/en/user_guides/dataset_format.md)! - **\[2023/09\]** Support [InternLM-20B](xtuner/configs/internlm) models! - **\[2023/09\]** Support [Baichuan2](xtuner/configs/baichuan) models! - **\[2023/08\]** XTuner is released, with multiple fine-tuned adapters on [Hugging Face](https://huggingface.co/xtuner). ## Introduction XTuner is an efficient, flexible and full-featured toolkit for fine-tuning large models. **Efficient** - Support LLM, VLM pre-training / fine-tuning on almost all GPUs. XTuner is capable of fine-tuning 7B LLM on a single 8GB GPU, as well as multi-node fine-tuning of models exceeding 70B. - Automatically dispatch high-performance operators such as FlashAttention and Triton kernels to increase training throughput. - Compatible with [DeepSpeed](https://github.com/microsoft/DeepSpeed) , easily utilizing a variety of ZeRO optimization techniques. **Flexible** - Support various LLMs ([InternLM](https://huggingface.co/internlm), [Mixtral-8x7B](https://huggingface.co/mistralai), [Llama 2](https://huggingface.co/meta-llama), [ChatGLM](https://huggingface.co/THUDM), [Qwen](https://huggingface.co/Qwen), [Baichuan](https://huggingface.co/baichuan-inc), ...). - Support VLM ([LLaVA](https://github.com/haotian-liu/LLaVA)). The performance of [LLaVA-InternLM2-20B](https://huggingface.co/xtuner/llava-internlm2-20b) is outstanding. - Well-designed data pipeline, accommodating datasets in any format, including but not limited to open-source and custom formats. - Support various training algorithms ([QLoRA](http://arxiv.org/abs/2305.14314), [LoRA](http://arxiv.org/abs/2106.09685), full-parameter fune-tune), allowing users to choose the most suitable solution for their requirements. **Full-featured** - Support continuous pre-training, instruction fine-tuning, and agent fine-tuning. - Support chatting with large models with pre-defined templates. - The output models can seamlessly integrate with deployment and server toolkit ([LMDeploy](https://github.com/InternLM/lmdeploy)), and large-scale evaluation toolkit ([OpenCompass](https://github.com/open-compass/opencompass), [VLMEvalKit](https://github.com/open-compass/VLMEvalKit)). ## Supports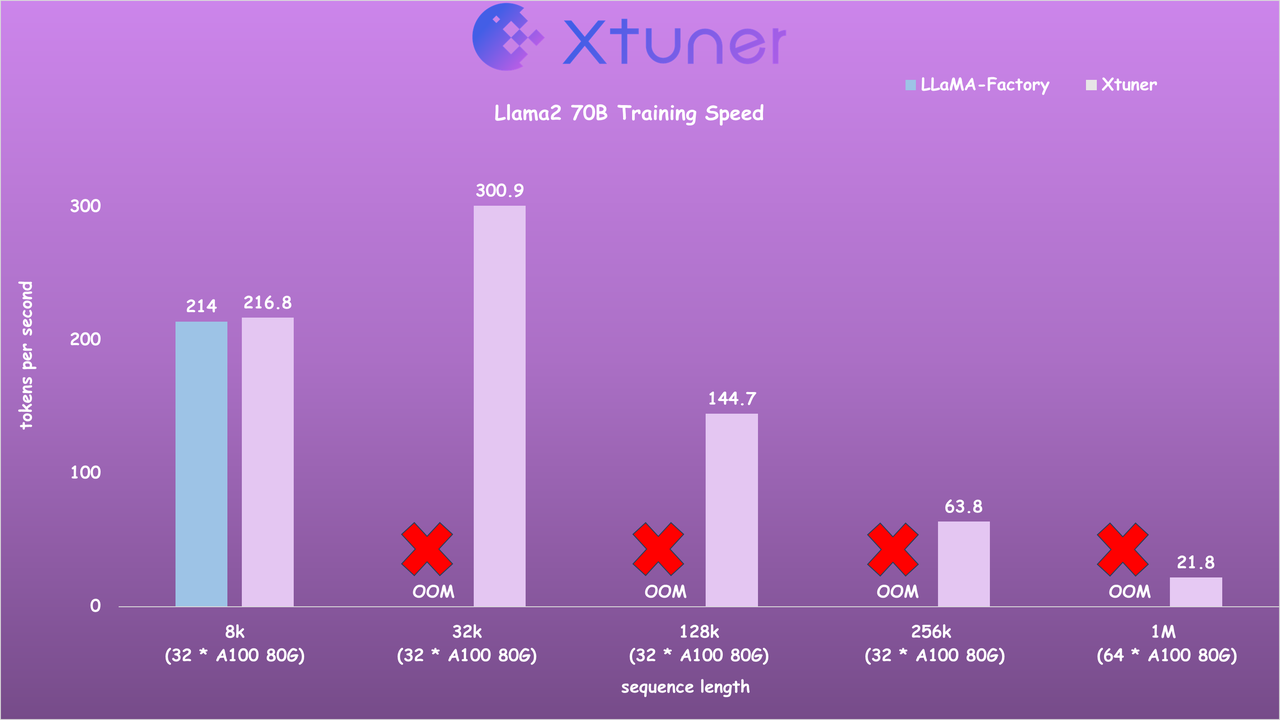
| Models | SFT Datasets | Data Pipelines | Algorithms |
Owner
- Name: Heyang Gong
- Login: 1587causalai
- Kind: user
- Repositories: 1
- Profile: https://github.com/1587causalai
1587causalai