https://github.com/abiyamakruf/dicoding-predictiveanalytics
Proyek pertama dicoding course machine learning terapan. Mendapatkan nilai 4/5.
Science Score: 36.0%
This score indicates how likely this project is to be science-related based on various indicators:
-
○CITATION.cff file
-
✓codemeta.json file
Found codemeta.json file -
○.zenodo.json file
-
✓DOI references
Found 2 DOI reference(s) in README -
✓Academic publication links
Links to: springer.com -
○Academic email domains
-
○Institutional organization owner
-
○JOSS paper metadata
-
○Scientific vocabulary similarity
Low similarity (4.9%) to scientific vocabulary
Repository
Proyek pertama dicoding course machine learning terapan. Mendapatkan nilai 4/5.
Basic Info
Statistics
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
- Releases: 0
Metadata Files
README.md
Laporan Proyek Machine Learning - Muhammad Abiya Makruf
Penilaian Proyek
Proyek ini berhasil mendapatkan bintang 4/5 pada submission dicoding course machine learning terapan.
Domain Proyek
Latar Belakang
Dalam dunia real estat dan penyewaan apartemen, menetapkan harga sewa yang akurat sangat penting baik bagi pemilik properti maupun penyewa. Penentuan harga yang tepat tidak hanya membantu pemilik properti untuk memaksimalkan pendapatan, tetapi juga membantu calon penyewa untuk menemukan tempat tinggal yang sesuai dengan anggaran mereka.
Mengapa masalah ini harus diselesaikan? - Menentukan harga sewa yang tepat adalah kunci untuk menghindari kerugian baik bagi pemilik properti maupun penyewa. - Memiliki sistem prediksi harga yang andal dapat meningkatkan efisiensi pasar penyewaan properti.
Referensi Terkait - Using machine learning algorithms for predicting real estate values in tourism centers - Predicting property prices with machine learning algorithms
Business Understanding
Problem Statements
- Bagaimana cara memprediksi harga sewa apartemen berdasarkan fitur-fitur seperti jumlah kamar mandi, kamar tidur, luas apartemen, dll?
- Fitur-fitur apa yang paling berpengaruh dalam menentukan harga sewa apartemen?
- Bagaimana meningkatkan akurasi prediksi harga sewa dengan menggunakan teknik machine learning?
Goals
- Membangun model machine learning yang dapat memprediksi harga sewa apartemen dengan akurasi tinggi.
- Mengidentifikasi fitur-fitur yang paling berpengaruh dalam menentukan harga sewa.
- Meningkatkan akurasi model prediksi melalui hyperparameter tuning dan teknik machine learning yang tepat.
Solution statements
- Menggunakan beberapa algoritma machine learning seperti KNN, Random Forest, dan AdaBoost untuk memprediksi harga sewa.
- Membandingkan performa model dan memilih model terbaik berdasarkan metrik evaluasi seperti Mean Squared Error (MSE).
Data Understanding
Dataset yang digunakan berasal dari UCI Machine Learning Repository. Dataset ini berisi informasi tentang apartemen yang disewakan, termasuk fitur-fitur seperti jumlah kamar mandi, kamar tidur, luas apartemen, dan harga sewa.
Dataset memiliki jumlah 10.000 baris dan 22 kolom.
| # | Column | Dtype | |-----|----------------|---------| | 0 | id | int64 | | 1 | category | object | | 2 | title | object | | 3 | body | object | | 4 | amenities | object | | 5 | bathrooms | float64 | | 6 | bedrooms | float64 | | 7 | currency | object | | 8 | fee | object | | 9 | hasphoto | object | | 10 | petsallowed | object | | 11 | price | int64 | | 12 | pricedisplay | object | | 13 | pricetype | object | | 14 | square_feet | int64 | | 15 | address | object | | 16 | cityname | object | | 17 | state | object | | 18 | latitude | float64 | | 19 | longitude | float64 | | 20 | source | object | | 21 | time | int64 |
Dataset mempunyai beberapa fitur yang terdapat missing value. | | Tipe Data | Jumlah Missing Value | |----------|----------|----------| |amenities|object|3549 |bathrooms|float64|34 |bedrooms|float64|7 |pets_allowed|bject|4163 |address|object|3327 |cityname|object|77 |state|object|77 |latitude|float64|10 |longitude|float64|10
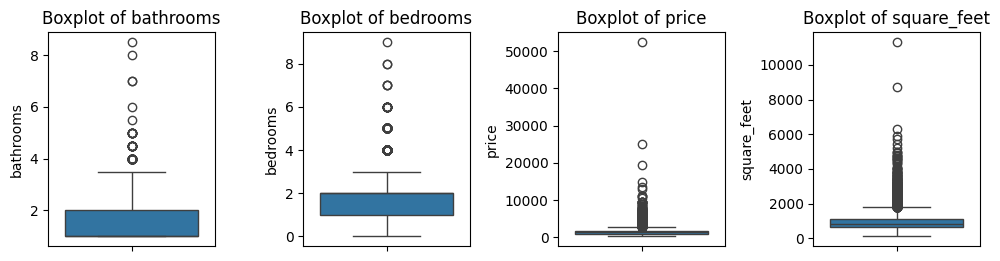
Dataset mempunyai nilai outliers pada fitur-fitur numerical. Fitur price dan square_feet memiliki jumlah outliers paling banyak.
Variabel-variabel pada dataset adalah sebagai berikut:
- id = unique identifier of apartment
- category = category of classified
- title = title text of apartment
- body = body text of apartment
- amenities = like AC, basketball,cable, gym, internet access, pool, refrigerator etc.
- bathrooms = number of bathrooms
- bedrooms = number of bedrooms
- currency = price in current
- fee = fee
- has_photo = photo of apartment
- pets_allowed = what pets are allowed dogs/cats etc.
- price = rental price of apartment
- price_display = price converted into display for reader
- price_type = price in USD
- square_feet = size of the apartment
- address = where the apartment is located
- cityname = where the apartment is located
- state = where the apartment is located
- latitude = where the apartment is located
- longitude = where the apartment is located
- source = origin of classified
- time = when classified was created
Exploratory Data Analysis (EDA): - Membuat korelasi heatmap untuk melihat nilai korelasi antar fitur numerik.
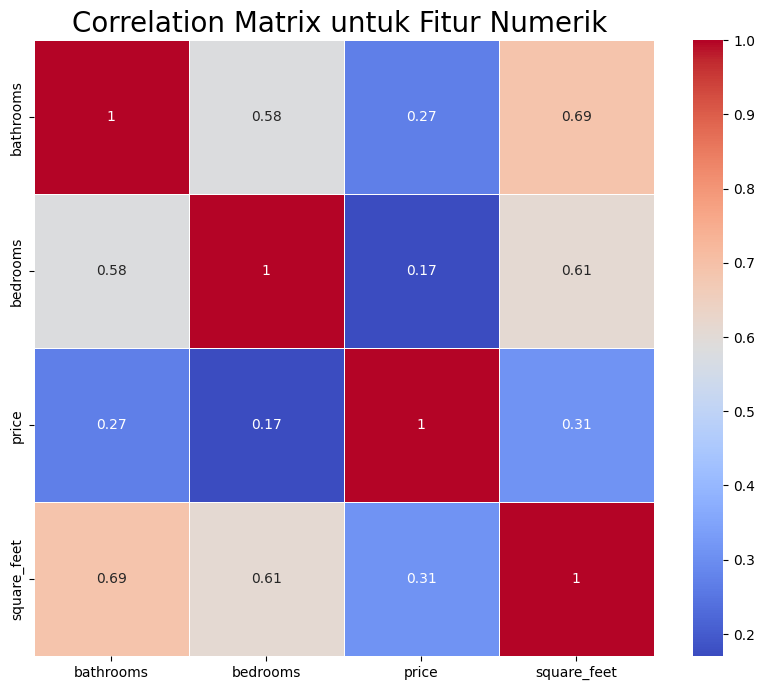
1. Hubungan antara Luas Bangunan dan Fitur Lain:
* Fitur square_feet (luas bangunan) memiliki hubungan yang cukup kuat dengan bathrooms dan bedrooms, yang menunjukkan bahwa luas bangunan adalah indikator penting dari ukuran dan fasilitas apartemen.
2. Harga Sewa:
* Korelasi antara harga sewa (price) dengan fitur lain (kamar mandi dan kamar tidur) relatif rendah. Ini menunjukkan bahwa harga sewa mungkin dipengaruhi oleh faktor-faktor lain seperti lokasi, fasilitas tambahan, atau kondisi pasar yang tidak tercakup dalam fitur yang dianalisis.
Membuat histogram untuk melihat persebaran data numerik.
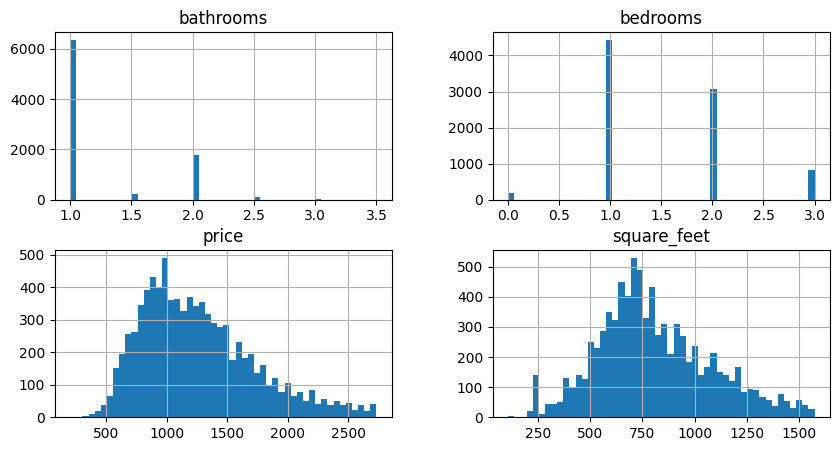
1. Bathrooms
* Mayoritas memiliki 1 kamar mandi. Terdapat rumah yang memiliki 1.5 dan 2.5 kamar mandi
* Kamar mandi seharusnya tidak berbentuk float sehingga akan dilakukan drop
2. Bedrooms
* Mayoritas memiliki 1 atau 2 kamar tidur.
3. Price
* Harga sewa apartemen tersebar dengan puncak sekitar 700-1000 USD. Distribusi harga menunjukkan pola normal dengan sedikit skew ke kanan.
4. Square_feet
* Luas apartemen bervariasi dengan puncak sekitar 500-800 kaki persegi. Distribusi luas juga menunjukkan pola normal dengan skew ke kanan.
Data Preparation
Teknik Data Preparation - Handling Missing Values: Mengimputasi atau menghapus nilai yang hilang pada dataset. - Removing Outliers: Menghapus data yang memiliki nilai outliers pada kolom tertentu. - Drop fitur yang tidak memberikan nilai tambahan. - Encoding Categorical Variables: Mengubah variabel kategorikal menjadi variabel numerik menggunakan teknik one-hot encoding. - Pembagian dataset untuk train-test (80:20). - Feature Scaling: Melakukan standarisasi pada fitur numerik untuk memastikan semua fitur berada dalam skala yang sama.
Proses Data Preparation
- Fitur yang memiliki jumlah missing value < 100 akan dilakukan drop.
- Fitur yang memiliki jumlah missing value > 1000 akan dilakukan imputasi.
- Outlier diatasi menggunakan IQR method.
- Fitur seperti id, latitude, longitude, dan time tidak memberikan nilai tambah sehingga dilakukan drop.
- Fitur seperti category, currency, fee, dan price_type memiliki nilai yang sama untuk keseluruhan dataset sehingga dilakukan drop.
- Categorical fitur dilakukan one-hot-encoding.
- Pembagian dataset train-test dengan skema 80:20.
| | Jumlah |
|----------|----------|
|Whole Dataset|8136
|Train|6508
|Test|1628
- Feature scaling menggunakan StandardScaler, digunakan pada data train dan data test.
Alasan Tahapan Data Preparation Dilakukan - Mengatasi missing values untuk menghindari masalah saat training model. - Removing outliers untuk meningkatkan akurasi model dengan menghilangkan data yang dapat mempengaruhi performa model. - Melakukan drop fitur yang tidak memberikan nilai tambah agar menghemat komputasi. - Encoding categorical variables untuk memungkinkan model machine learning memproses data. - Menggunakan metode 80:20 karena jumlah dataset tidak terlalu banyak sehingga porsi data train dan data test cukup seimbang. - Feature scaling untuk memastikan model tidak bias terhadap fitur dengan skala besar.
Modeling
Tahap Modeling
- Menyiapkan DataFrame untuk Analisis Masing-Masing Model
python models = pd.DataFrame(index=['train_mse', 'test_mse'], columns=['KNN', 'RandomForest', 'Boosting'])Memulai dengan menyiapkan DataFrame bernama models untuk menyimpan nilai Mean Squared Error (MSE) pada data latih dan uji untuk setiap model yang akan diuji, yaitu KNN, Random Forest, dan Boosting. - Melatih model KNN
python knn = KNeighborsRegressor(n_neighbors=10) knn.fit(X_train, y_train)Menggunakan algoritma K-Nearest Neighbors dengan parameter nneighbors=10. Model ini dilatih menggunakan data latih Xtrain dan y_train, dan nilai MSE pada data latih disimpan dalam DataFrame models. - Melatih model Random Forest
python RF = RandomForestRegressor(n_estimators=50, max_depth=16, random_state=55, n_jobs=-1) RF.fit(X_train, y_train)Menggunakan RandomForestRegressor dengan parameter nestimators=50, maxdepth=16, dan random_state=55 untuk memastikan hasil yang konsisten. Model ini dilatih dengan data yang sama dan nilai MSE pada data latih disimpan dalam DataFrame models. - Melatih model Ada Boost
python boosting = AdaBoostRegressor(learning_rate=0.05, random_state=55) boosting.fit(X_train, y_train)Menggunakan AdaBoostRegressor dengan parameter learningrate=0.05 dan randomstate=55. Model ini juga dilatih dengan data yang sama dan nilai MSE pada data latih disimpan dalam DataFrame models.
Tahapan dan Parameter yang Digunakan
Pada tahap modeling, tiga algoritma berbeda digunakan untuk memprediksi harga sewa apartemen:
- K-Nearest Neighbors (KNN):
- Parameter: n_neighbors=10
- Deskripsi: Algoritma KNN mencari 10 tetangga terdekat untuk melakukan prediksi berdasarkan rata-rata nilai target dari tetangga tersebut.
- Random Forest:
- Parameter: nestimators=50, maxdepth=16, random_state=55
- Deskripsi: Random Forest adalah ensemble dari beberapa pohon keputusan yang dilatih pada subset data yang berbeda untuk meningkatkan akurasi prediksi dan mengurangi overfitting.
- AdaBoost:
- Parameter: learningrate=0.05, randomstate=55
- Deskripsi: AdaBoost adalah algoritma boosting yang meningkatkan akurasi prediksi dengan menggabungkan beberapa model sederhana (biasanya pohon keputusan dengan kedalaman 1) yang dilatih secara berurutan, dengan memberi bobot lebih pada kesalahan yang dibuat oleh model sebelumnya.
Kelebihan dan Kekurangan Setiap Algoritma - K-Nearest Neighbors (KNN): - Kelebihan: - Sederhana dan mudah diimplementasikan. - Tidak ada asumsi yang kuat tentang distribusi data. - Kekurangan: - Sensitif terhadap outliers dan noise. - Tidak skala dengan baik untuk dataset besar karena kompleksitas komputasi yang tinggi. - Random Forest: - Kelebihan: - Dapat menangani data yang kompleks dengan baik. - Robust terhadap overfitting karena menggunakan banyak pohon keputusan. - Dapat menangani missing values dan bekerja dengan baik pada dataset besar. - Kekurangan: - Interpretasi model lebih sulit dibandingkan dengan model sederhana. - Memerlukan lebih banyak sumber daya komputasi dan memori. - AdaBoost: - Kelebihan: - Dapat meningkatkan akurasi dengan menggabungkan beberapa model sederhana. - Fokus pada kesalahan sebelumnya meningkatkan performa model secara iteratif. - Kekurangan: - Rentan terhadap outliers karena memberi bobot tinggi pada kesalahan. - Kinerja menurun jika data sangat noisy.
Memilih Model Terbaik Sebagai Solusi
Berdasarkan evaluasi menggunakan nilai MSE pada data uji, model terbaik dipilih sebagai solusi. Misalnya, jika model Random Forest menunjukkan MSE terendah pada data uji dibandingkan dengan KNN dan AdaBoost, maka model Random Forest dipilih sebagai model terbaik.
Evaluation
Metrik Evaluasi - Mean Squared Error (MSE): Mengukur rata-rata kuadrat dari kesalahan prediksi. MSE yang lebih rendah menunjukkan performa model yang lebih baik.
Penjelasan Metrik
Mean Squared Error (MSE) adalah metrik umum yang digunakan untuk mengevaluasi akurasi model regresi. MSE didefinisikan sebagai berikut:
$$ \text{MSE} = \frac{1}{n} \sum{i=1}^{n} (yi - \hat{y}_i)^2 $$
di mana: - $yi$ adalah nilai aktual, - $\hat yi$ adalah nilai prediksi, - $n$ adalah jumlah sampel.
MSE memberikan penalti yang lebih besar untuk kesalahan yang lebih besar karena penggunaan kuadrat kesalahan. Nilai MSE yang lebih rendah menunjukkan performa model yang lebih baik.
Hasil Proyek
| | train | test | |----------|----------|----------| | KNN | 78.099856 | 97.804678 | | RF | 59.18405 | 93.696278 | | Boosting | 148.285221 | 156.19596 |
- KNN: Setelah melakukan hyperparameter tuning, model KNN memiliki nilai MSE 78.099856.
- Random Forest: Model Random Forest menunjukkan performa yang lebih baik dibandingkan KNN dengan MSE yang lebih rendah yaitu 59.18405.
- AdaBoost: Model AdaBoost juga menunjukkan performa yang kompetitif dengan nilai MSE 148.285221.
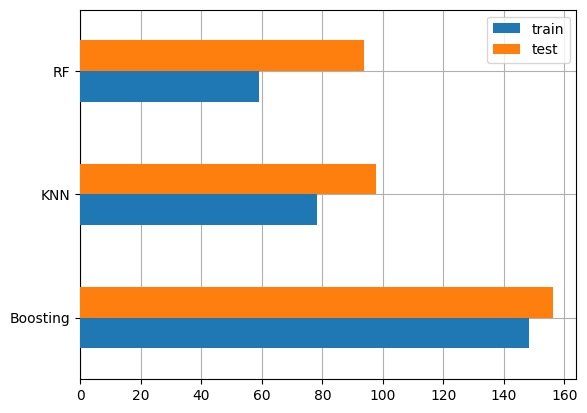
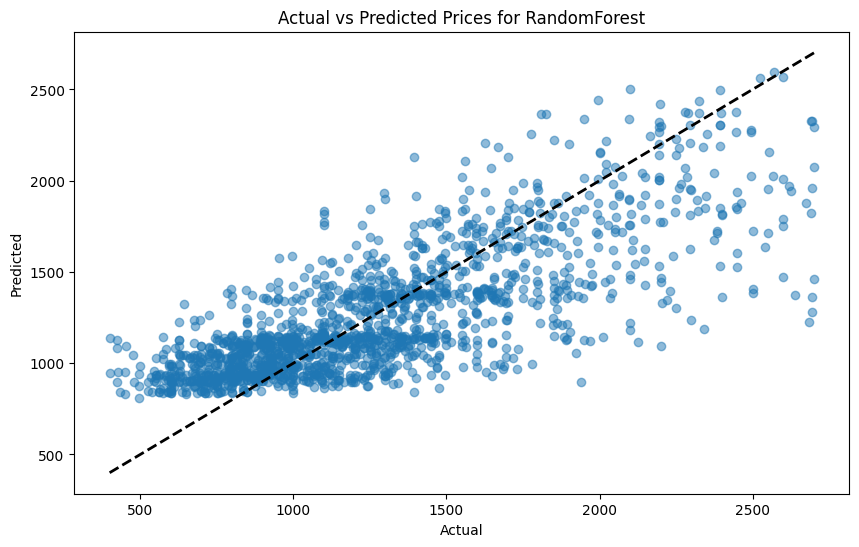
Model Terbaik
Berdasarkan hasil evaluasi, model Random Forest dipilih sebagai model terbaik karena memiliki MSE terendah pada data uji. Berikut adalah grafik untuk nilai aktual vs nilai prediksi menggunakan model random forest.
Evaluasi Terhadap Business Understanding - Menjawab Problem Statement: Model yang dibuat berhasil menjawab problem statement dengan memprediksi harga sewa apartemen berdasarkan fitur-fitur yang ada dan mengidentifikasi fitur-fitur yang paling berpengaruh. - Mencapai Goals: Model Random Forest dengan hyperparameter yang dioptimalkan berhasil mencapai tujuan untuk memberikan prediksi harga sewa yang akurat dan mengidentifikasi fitur penting. - Dampak dari Solution Statement: Penggunaan beberapa algoritma dan hyperparameter tuning memberikan dampak positif dengan meningkatkan akurasi prediksi dan memungkinkan pemilihan model terbaik. Solusi yang direncanakan memberikan hasil yang signifikan dalam mencapai tujuan proyek.
Kesimpulan
Melalui proses pemodelan dan evaluasi, telah berhasil membangun model yang akurat untuk memprediksi harga sewa apartemen dan mengidentifikasi fitur-fitur yang paling berpengaruh. Model Random Forest terbukti menjadi model terbaik dalam hal akurasi prediksi, dan hyperparameter tuning memainkan peran penting dalam meningkatkan performa model. Dampak dari solusi yang diimplementasikan sangat positif, memenuhi problem statement dan goals yang telah ditetapkan.
Owner
- Login: AbiyaMakruf
- Kind: user
- Location: Bandung, Indonesia
- Website: https://the-eventhorizon.com/
- Repositories: 2
- Profile: https://github.com/AbiyaMakruf
I am passionate about my work, highly organized, and a hard worker person
GitHub Events
Total
- Watch event: 5
- Fork event: 1
Last Year
- Watch event: 5
- Fork event: 1